Cycle-Consistent Inverse GAN for Text-to-Image Synthesis
ABSTRACT
本文研究了一个开放的文本到图像合成的研究任务,用于从文本描述中自动生成或操作图像。目前流行的方法主要是以文本作为GAN生成的条件,针对文本引导的图像生成和操作任务训练不同的模型。在本文中,我们针对文本到图像的生成和文本引导的图像操作任务,提出了一种新的周期一致性逆GAN Cycle-consistent Inverse GAN (CI-GAN) 统一框架。具体来说,我们首先训练一个没有文本输入的GAN模型,旨在生成多样性和质量都很高的图像。然后我们学习一个GAN反演模型 GAN inversion model,将图像转换回GAN潜在空间,获得每幅图像的倒排潜码 inverted latent codes,在这里我们引入循环一致性训练 cycle-consistency training,学习更健壮和一致的倒排潜码。通过学习文本表示和潜在代码之间的相似性模型,我们进一步揭示了训练好的GAN模型的潜在空间语义 latent space semantics。在文本引导优化模块中,我们通过 优化倒排潜在代码 生成 具有期望语义属性 的图像。在Recipe1M和CUB数据集上的大量实验验证了我们提出的框架的有效性。
1 INTRODUCTION
文本到图像的合成[6,20,21,26,35–37,42]旨在生成具有与输入文本描述相对应的语义内容的图像,通常基于生成对抗网络(GANs)方法。它有各种潜在的应用,比如视觉内容设计和艺术生成。然而,文本到图像的合成是一项具有挑战性的跨模态任务,因为我们需要解释隐藏在文本中的语义属性,生成多样性高、质量好的图像。
关于文本到图像生成的主流作品[6,15,38,42]主要基于StackGAN [37]构建其框架,可以逐步生成高分辨率图像。具体来说,StackGAN模型叠加了多个生成器和鉴别器,可以先生成具有粗糙形状和颜色属性的初始低分辨率图像,然后将初始图像细化为高分辨率图像。为了提高文本描述和生成的图像之间的语义对应性,Xu等人提出了AttnGAN [35]通过预处理一个注意相似度来发现图像和文本之间的属性对齐。然而,GAN模型的配对文本图像训练限制了模型表示的多样性,因为我们只有有限的文本和图像组合,生成的图像由相应的真实图像和文本对进行正则化。此外,很难使用上述框架只更改一个属性,而在生成的图像中保留其他与文本无关的属性,因此我们需要训练一个额外的模块来完成基于文本的图像操作任务[16]。
基于样式style-based的生成器体系结构的出现,如Style- GAN [13,14],极大地提高了生成图像的真实感、质量和多样性。具体来说,StyleGAN提出了将输入噪声映射到另一个潜在空间W,这一点已经通过验证,可以产生更加松散的语义表示。为了揭示空间W中的潜在码与合成图像之间的关系,我们需要知道空间W的分布,找到相应的图像潜在码。为此,许多研究工作采用GAN反演技术 GAN inversion technique [1,27,40]将图像反演回空间W,得到反演的潜在码 inverted latent codes.
在这篇论文中,我们提出了一个新的周期一致性逆GAN框架 Cycle-consistent Inverse GAN (CI-GAN),在这个框架中,我们将GAN反演方法融入到文本到图像的合成任务中。在技术上,我们首先训练GAN反转编码器 GAN inversion encoder 将图像映射到训练好的StyleGAN的 潜在空间W,这样我们就可以得到给定数据集的真实图像的反转潜在代码。为了使原始的和反向的潜在代码相同并遵循相同的分布,我们引入循环一致性损失 cycle consistency loss 来应用于GAN反向训练过程,因为获得与原始代码相似的反向潜在代码对于我们后续的生成过程至关重要。
我们假设StyleGAN学到 空间W 分解目标图像数据集的语义属性。例如,在图1的底部一行,当我们想更改鸟类图像的腹部颜色时,其余的语义属性,如鸟类形状、姿势和羽毛颜色将保持不变,只有鸟类腹部颜色从橙色更改为黑色。空间W的消纠缠 disentanglement 允许我们在对潜在代码进行优化的基础上生成各种属性的图像。为了从文本描述中生成图像,我们学习了文本表示和倒排潜代码之间的相似性模型,这样潜代码就可以优化为具有所需的语义属性。我们将优化后的潜在代码输入训练好的StyleGAN生成器,实现文本到图像的生成任务。除了文本到图像的生成任务,我们提出的CI-GAN还可以通过在原始图像和由优化的潜在代码重构的图像之间施加额外的感知损失来用于基于文本的图像操作任务。
图1:常规架构与我们提出的文本到图像生成框架的比较。目前存在的作品主要采用文本特征条件GAN结构,文本和图像的有限组合会影响生成的多样性。在采用解耦学习方案的同时,我们首先训练一个没有文本的GAN模型,然后发现训练后的GAN的潜在空间W的语义。我们允许文本表示与潜代码匹配,这样我们就可以通过改变潜代码来控制合成图像的语义属性。
我们的贡献可以概括为:
- 我们提出了一种结合GAN inversion和循环一致性训练GAN inversion and cycle consistency training的文本图像合成GAN新方法。统一框架可以用于文本到图像的生成和基于文本的图像操作任务。
- 我们采用改进的GAN反演方法,结合循环一致性训练,将真实图像反演到GAN潜在空间,得到图像的潜在码。
- 我们揭开了潜在代码的语义,根据它我们可以生成与文本描述相对应的高质量图像。
我们在两个野外公共数据集上评估了我们提出的框架CI-GAN,即Recipe1M和CUB数据集。我们进行了广泛的实验来分析CI-GAN的功效。最后,我们给出了我们提出的方法的定量和定性结果以及生成图像的可视化。
2 RELATED WORK
2.1 Text-Based Image Generation
在本节中,我们回顾了两类基于文本的图像生成,即基于文本的图像生成和基于文本的图像处理。从文本中生成图像是一项具有挑战性的任务,因为我们需要关联跨模态信息[5,30,32]。为了控制文本和生成的图像之间的对应关系,一些流行的文本到图像的生成工作[6,15,42]预处理了一个深度注意多模态相似模型(DAMSM) [35],该模型用作对生成图像语义的监管。具体来说,Cheng等[6]提出使用细化模块来返回更完整的字幕集,可以为图像的生成提供更多的语义信息。朱等。[42]使用内存写入门来细化初始图像,生成高质量的图像。王等[31]和朱等[38]旨在从烹饪食谱中生成食物图像。
对于基于文本的图像操作任务,它要求模型只更改某些部分或属性,并在输入图像上保留其他与文本无关的属性。Li等[16]提出了一个模块,将文本和生成的图像结合起来,共同校正细节,从而可以纠正不匹配的属性。Dong等人[8]使用编码器-解码器架构,以原始图像和文本描述作为输入,输出经过处理的图像,由鉴别器监督。
然而,现有的文本到图像生成作品由于使用配对文本和图像进行GAN训练,所以生成的图像多样性有限。此外,上述体系结构采用多阶段细化[35,37]来提高生成图像的分辨率,因此生成分辨率更高的图像比较繁琐。相比之下,我们提出的方法使用StyleGAN2 [14]模型作为生成器主干,在训练GAN时不使用配对文本输入,保证了生成图像的质量和多样性。
2.2 GAN Inversion
由于GAN缺乏推理能力,潜在空间中的操作只能应用于生成的图像,而不能应用于任何给定的真实图像。GAN反转是操纵真实图像的常用方法[3,19,41]。GAN反转的目的是将给定的图像反演到一个预处理后的GAN模型的潜在空间中,得到反转的潜在代码,使生成器可以从反转的潜在代码中忠实地重建图像。GAN反演作为一种连接图像和GAN潜在空间的新技术,使预处理后的GAN模型可以用于各种图像生成应用,如图像编辑[34]。
GAN倒转方法主要有两种。第一种是基于学习的GAN倒排方法[19,41],它对编码器进行典型的训练以生成潜在代码。GAN发生器将在训练编码器的过程中固定。第二种方法是基于优化的。这种方法通常通过优化潜码来重建原始图像,这种方法要么基于梯度下降[40],要么基于其他迭代算法[12]。一些作品[4,33,40]试图将这两种思想结合起来,其中GAN反转编码器产生的潜在代码作为优化步骤的初始化,因为很难从单个GAN反转编码器获得基于反转潜在代码的完美重建图像。Zhu等人[40]提出了基于真实图像而不是虚假图像来训练编码器,从而使训练好的编码器更好地适应真实场景。他们还采用鉴别器来与GAN倒转编码器竞争,这样他们也可以从模型中涉及到语义的知识。Abdal等。[2]在StyleGAN潜在空间中结合空间掩码来学习输入随机噪声和潜在代码。Gu等。[9]使用多级潜在代码在生成器的某个中间层生成特征映射,然后用自适应信道重要性组合它们来恢复输入图像。
在我们的工作中,我们结合了基于学习和基于优化的方法来寻找具有期望属性的潜在代码。GAN反演的现有工作主要集中在人脸图像数据集[33,40],而我们针对的是两个更具挑战性的野外数据集,Recipe1M数据集包含多种混合成分的熟食图像,CUB数据集包含各种姿势、形状、颜色和背景的鸟类。我们提出的方法与现有工作的不同之处在于我们使用了循环一致性训练方法,不仅在图像域上应用正则化,而且在潜在空间域上也应用正则化。因此,与人脸数据集相比,我们的框架也可以在更复杂的场景中获得满意的反转结果,比如野外的食物和鸟类图像。
3 METHOD
我们提出的循环一致性逆GAN (CI-GAN)可以应用于基于文本的图像生成和操作任务。培训管道如图2所示,
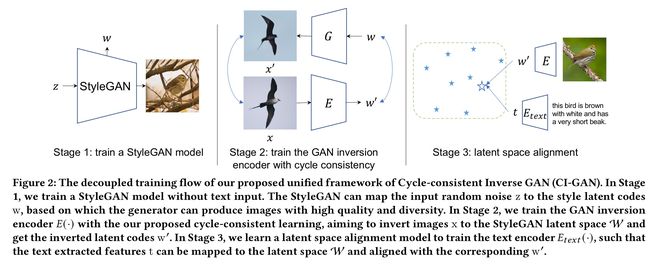
可以总结为三个阶段的训练过程:
- 阶段1。我们训练一个没有文本输入的StyleGAN模型。StyleGAN模型可以将 随机噪声空间Z 映射到 风格潜在空间W style latent space,这已经被证明更加不纠结disentangled于各种图像属性。
- 阶段2。我们建议使用周期一致性训练来学习GAN倒相编码器,这样我们就可以倒转真实图片 并获得对应的潜在code w’。
- 阶段3。我们学习了一个 潜在空间对齐模型 来对齐 文本特征t 有着 与之对应的倒潜代码w‘,在这里我们训练文本编码器Etext(·)。
在推理阶段,我们展示了图3中的演示。对于文本到图像的生成任务,我们随机采样一个w′作为初始w‘,基于这个,GAN模型只能生成具有随机语义属性的图像。因此,我们将初始w′和从trained Etext(·)中提取的 文本特征t 输入到潜在空间对齐模型中,w′将朝着t的方向优化。对于基于文本的图像操作任务,我们使用原始真实图像中的倒排潜代码作为初始w‘。当我们优化w‘时,我们在原始图像和生成的图像之间应用一个额外的感知损失,以在生成的图像上保留一些与文本无关的属性。
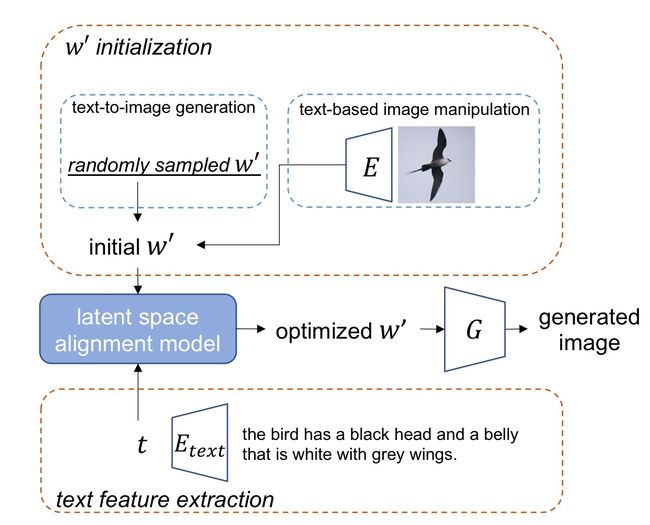
图3:我们提出的框架CI- GAN的测试流程。我们首先根据目标任务获得初始w′。在这里,我们随机抽取一个w′用于文本到图像的生成任务,并使用原始图像中的反向潜在代码进行基于文本的图像操作任务。初始w’和提取的文本特征t 被 送入 latent space alignment model ,在这里 w’朝着t方向优化。优化后的 w’ 将会送入 Style-GAN generator 生成图像。
3.1 GAN Inversion Encoder反转编码器
典型GAN模型的目标是从随机噪声输入中生成高质量的图像,可以表示为
GAN反演研究将生成的图像映射回潜码z‘,使z’可以接近原始输入z,从z′重建的图像可以与真实图像相同。
最近提出的StyleGAN [13,14]使用多层感知器(MLP)将初始潜在空间Z映射到另一个潜在空间W,其中采用映射的潜在码w ∈ W来合成图像。事实证明,该模型可以在W [13,24]空间学习到更多的消纠缠disentangled语义,因为我们的目的是发现潜在代码的语义,所以我们选择StyleGAN2 [14]的空间W进行实验分析。
对于GAN反演任务,训练编码器E(·)是一种实用的解决方案[33,40],它以图像为输入,输出与原始w对齐的w′。为了让来自w′的重建图像具有与原始图像相同的语义信息,我们用像素损失和感知损失[11]来训练编码器E(·)。请注意,为了训练E(·),我们使用真实图像x作为输入,试图使编码器更加适用于真实图像操作。从技术上讲,感知损失通过对齐 真实图像x 和 重建图像 x′=G(E(x)) 之间 提取的VGG [25] 特征 来 正则化重建图像的语义。像素损失和感知损失可以表述为

其中||· ||2表示l2距离,F(·)和E(·)分别表示VGG特征提取模型和GAN反转编码器。
3.2 Cycle-Consistent Constraint
然而,像素损失和感知损失只在图像域上给出正则化,我们还需要在潜在空间域上应用一致的约束,使得倒潜码w′可以与w匹配,且潜在码可以操作和解释。具体来说,我们建议在GAN inversion学习过程中使用循环一致性训练cycle consistency training。我们在 倒码w′和从w’生成的图像上都 采用对抗性损失。
生成图像上的对抗性损失可以确保重建图像x′足够逼真,其中我们涉及鉴别器来与编码器E(·)竞争。对抗性训练方法还有助于推动 倒码w′ 更好地适应生成器的语义知识,可以表示为

其中D(·)表示GAN的鉴别器。
此外,我们还介绍了在 倒码 上应用对抗性损失,使原始潜码w和 倒潜码w′=E(G(w)) 遵循相同的分布。因此,这有助于我们修改w′并更好地获得我们想要的属性的图像。这可以表示为
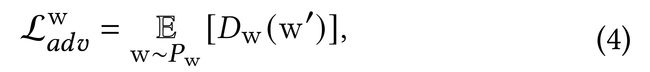
我们还强制w和倒码w′=E(G(w))相同。GAN倒转编码器的整个训练目标可以给出为

3.3 Text Encoder by Latent Space Alignment
3.3基于潜空间对齐的文本编码器
利用所学习的GAN反演模型,我们可以得到每幅真实图像的初始反潜码w′。为了根据文本描述控制生成的图像,我们使用 潜在空间对齐,发现显式文本语义和隐式空间W之间的关系。具体来说,我们采用配对的文本描述和相应图像转换后的w′ 进行相似性学习。我们首先使用一个单层的LSTM Etext(·)来获得 给定文本描述的特征t ,它的维度与w’的维数相同。这里我们的目标是学习文本特征表示t,并将其映射到与空间W相同的特征空间,因此StyleGAN模型可以学习消纠缠空间W,将t与w对齐可以使文本编码器更好地捕捉文本描述中的有用语义。
我们利用 InfoNCE 损失[18]来学习(t,w′)的相似关系。原始InfoNCE 损失用于分类任务,通过类概率优化模型,当我们试图揭示成对关系时,我们很难直接使用InfoNCE损失。因此,我们将 l2距离 结合到InfoNCE损失中,其公式为 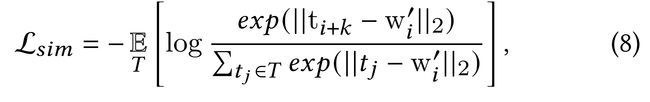
其中T表示 mini-batch 中的所有文本表示形式,i 表示训练批次中的一个示例索引,索引 k 表示一个非0 数。ti+k表示wi’的不配对样本。 我们的目标是最小化配对t和w‘之间的 l2距离,同时最大化未配对实例之间的距离。我们没有选择余弦损失等成对pair-wise损失函数来优化相似模型的原因是成对损失在迭代中只考虑每个样本的一对,这没有建立成对之间的关系。而在InfoNCE损失中,我们可以对所有的正负对进行采样并一起优化,从而获得更好的匹配性能。
3.4 Inference with Text-Guided Optimization
3.4文本引导优化的推理
在这个模块中,我们为文本到图像的生成和基于文本的图像操作任务优化了初始倒潜码w′。为了解释给定文本描述中的语义属性,我们将w′推向文本表示t的方向。对于图像操作任务,我们在原始图像和来自优化后w’的生成图像 上 应用 一个 额外感知损失,以保留原始形状的文本无关语义属性。
优化过程可以给出为
![]() 其中x表示原始图像。请注意,后一项是感知损失,将在图像处理任务中计算,而对于文本到图像的生成任务,我们只使用l2损失。
其中x表示原始图像。请注意,后一项是感知损失,将在图像处理任务中计算,而对于文本到图像的生成任务,我们只使用l2损失。
4 EXPERIMENTS
4.1 Datasets and Evaluation Metrics
我们用两个具有挑战性的数据集来评估我们提出的框架:Recipe1M [23]和CUB [29]数据集。Recipe1M数据集是一个具有很大多样性的公共食物数据集,它对各种类别的食物图像都有复杂而细粒度的细节。有238999对图像配方进行训练,51119对进行验证,51303对进行测试。我们只使用配对的配料来生成食物图像。CUB数据集广泛用于文本到图像的生成任务,它总共包含200个类和11788幅图像。有8855张和2933张图片用于训练和测试。对于CUB数据集中的每个鸟类图像,都有10个英文文本描述。
我们使用初始得分(IS) [22]和弗雷谢特初始距离(FID) [10]的量化评估指标。具体来说,IS通过预训练的Inception-V3网络计算条件分布和预测图像标签边缘分布之间的Kullback-Leibler (KL)散度[25]。更高的IS表明该模型可以生成更加多样和逼真的图像。但是,IS在一些文本到图像的情况下可能无法反映生成的图像质量[17]。因此,我们也使用FID进行评估,它更加稳健,符合人类的定性评估[26]。FID计算预训练的Inception-V3网络的特征空间中真实图像和生成图像的分布之间的Fré chet初始距离[25]。
4.2 Implementation Details
我们提出的统一框架是基于StyleGAN2- Ada [12]实现的。如表1所示,我们发现我们提出的CI-GAN与传统的文本特征条件StyleGAN2模型相比,可以获得最佳的IS和FID。我们还从经验上观察了标签条件下的StyleGAN2比无条件StyleGAN2可以获得更好的性能。我们用![]() 来优化模型,其中我们按照[40]中的设置来设置部分损失权重。我们按照[40]构建GAN反转编码器 GAN inversion encoder,由8个ResNet块组成。在Recipe1M数据集中,我们只以成分ingredient作为输入来生成食物图像,因为直观的成分具有丰富的语义属性。在CUB数据集里,我们在训练时为每幅图像随机抽取一个描述性句子。请注意,当我们进行基于文本的图像操作任务时,我们首先将原始图像转换为潜在代码w′,并用等式(9)优化w′。当我们进行文本到图像的生成任务时,我们首先随机抽取一个潜在的代码w′并用方程(9)优化w′而不使用感知损失。
来优化模型,其中我们按照[40]中的设置来设置部分损失权重。我们按照[40]构建GAN反转编码器 GAN inversion encoder,由8个ResNet块组成。在Recipe1M数据集中,我们只以成分ingredient作为输入来生成食物图像,因为直观的成分具有丰富的语义属性。在CUB数据集里,我们在训练时为每幅图像随机抽取一个描述性句子。请注意,当我们进行基于文本的图像操作任务时,我们首先将原始图像转换为潜在代码w′,并用等式(9)优化w′。当我们进行文本到图像的生成任务时,我们首先随机抽取一个潜在的代码w′并用方程(9)优化w′而不使用感知损失。
4.3 定量结果
我们将我们提出的框架与各种最先进的文本到图像合成框架进行了比较。
我们在表2中展示了Recipe1M数据集上的定量评估结果。R2GAN [39]是生成64 × 64低分辨率图像的 naive baseline,通过线性插值进一步调整到256 × 256。StackGAN++ [37]引入了多个生成器和用于高分辨率图像生成的鉴别器。CookGAN [38]是Recipe1M数据集内最先进的文本到图像的生成框架,它是基于StackGAN++架构的扩展。CookGAN和StackGAN++的区别主要在于CookGAN采用了注意机制来改善条件食谱特性。我们的方法大大优于以前的所有方法,特别是我们在IS和FID中分别比CookGAN获得了超过10%和30%的改进。 这说明所提出的CI-GAN框架能够以更好的文本图像语义一致性合成更真实的食物图像。
当我们转移到CUB数据集时,我们在表3中显示了结果。CUB数据集已经广泛用于一般的文本到图像的生成任务。我们还可以观察到,我们提出的CI-GAN可以在整个IS和FID中取得最好的效果,分别为5.68和5.41。以往的大部分作品,如AttnGAN [35]、MirrorGAN [20]和RiFeGAN [6],都是利用配有注意机制的条件GAN结构来改善GAN的表示,进一步提升生成性能。DALL-E [21]是最新提出的基于变压器的文本到图像生成器,他们使用外部大规模数据集来训练生成模型。由于他们使用zero-shot learning,在那里他们没有在CUB数据集上训练他们的模型,因此他们的结果相对较差。然而我们的方法可以用一种新颖的基于反向GAN思想的架构来优于现有的结果,这对于文本到图像的生成任务是有效的。具体来说,我们在不使用外部大规模数据集的情况下训练我们的模型,我们只使用一个简单的LSTM学习潜在空间对齐模型中的潜在代码和文本表示之间的相似性。它表明了我们适应InfoNCE 损失的有效性,并解开了disentanglement 我们所学习的文本表示。
4.4 定性结果
文本到图像的生成。Recipe1M和CUB数据集上生成图像的可视化分别如图4和5所示,其中部分生成的图像取自[26]和[38]。食物图像生成需要对复杂成分进行详细的解释。在图4中,我们显示了三种食物的生成结果。我们分别使用烹饪说明和配料作为条件输入来显示CookGAN结果。我们的方法只使用成分信息作为输入文本描述,而我们提出的框架作品生成的图像可以产生大部分与文本相关的视觉内容,质量很高。例如,在第二行中,输入的内容包含胡萝卜,我们生成的图像具有与胡萝卜相似的形状和颜色。但是,很难清楚地生成所有的配料颗粒,这在最后一行可以观察到,在给定文本输入的情况下,我们的模型几乎不能生成除柿子椒以外的各种配料。一般来说,我们提出的框架比其他方法可以生成与食材语义属性更匹配的食物图像。在图5中,我们在CUB dataset中显示结果。我们可以看到,我们提出的方法不仅可以生成与给定文本输入相对应的图像,而且可以合成多样性高的真实感图像。相比之下,现有的许多作品都受到生成质量和语义解释不正确的限制。


图像操纵。在图6中,我们显示了CUB dataset中的一些操作结果。具体来说,我们主要替换一些颜色属性,这些属性可以在我们的操纵图像中很容易观察到。比如在最上面一排,我们改变了树冠和腹部的颜色,同时保持棕色的翅膀。我们可以看到在操纵的结果中只有腹部的颜色发生了变化,而翅膀的颜色保持为棕色。但是,很难像最下面一行那样,在操作后获得完美的语义属性保存,比如形状和姿势。主要有两个原因。一个原因是我们无法得到与原始图像相同的反演结果,然后在w′优化过程中模型丢失了部分原始语义信息。另一个原因是StyleGAN的潜在空间W仍然与一些语义属性纠缠在一起[33],这意味着当我们更改部分属性时,其余属性也会受到影响。我们把改善空间W留给以后的工作更好的理清思路。

4.5消融研究
text-conditioned GAN 与CI-GAN的比较。在表1中,我们比较了常规文本条件GAN和我们提出的基于CUB数据集的CI-GAN的文本到图像的生成性能。具体来说,我们对LSTM文本特征和预训练BERT [7]特征的不同GAN条件输入进行了实验。我们可以发现,以直接文本特征为输入的条件GAN在IS和FID上没有最好的结果,而提出的CI-GAN可以得到更好的结果。这表明使用文本特征作为输入会影响GAN的生成性能,因为有限的成对文本图像组合会限制生成图像的多样性。我们还展示了图7中的定性比较。我们的方法生成的图像与文本描述更好地对齐,而文本特征条件GAN模型生成的图像可能没有足够的多样性。此外,一些从text-conditioned GAN 生成的图像,例如图7中第三行的图像无法与文本输入正确匹配。

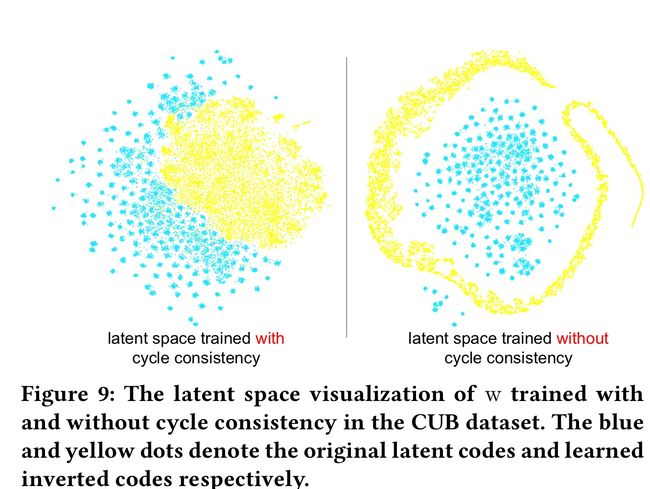
GAN inversion models with and without cycle-consistency training 有周期一致性训练和没有周期一致性训练的GAN反演模型。为了比较我们提出的框架作品在有周期一致性训练和没有周期一致性训练的情况下的差异,我们首先在图8中展示了GAN的反转结果。我们发现没有周期一致性损失的GAN inversion模型可能无法保留原始语义属性(例如第三列)和对象姿态信息(例如第二列)。我们通过t-SNE [28]进一步分析了潜码的分布,如图9所示。具有循环一致性训练的反向潜码与原始潜码有重叠和相似的分布。而未经循环一致性训练的倒码分布与原始潜码分布不匹配。这种 misalignment 进一步影响了文本到图像的生成性能,因为潜在空间对齐模型是基于学习到的倒潜代码进行训练的。例如,在图7的第一行中,从没有循环一致性训练的模型生成的鸟图像无法解释给定文本描述的棕色属性。

5 DISCUSSION
文本条件GAN体系结构已经广泛应用于文本到图像的生成任务中。我们研究了表1中不同GAN结构的影响,发现使用成对文本图像数据进行GAN训练会降低生成质量和多样性。而提出的无配对文本特征输入的CI-GAN可以获得更好的结果。通过训练有素的StyleGAN,我们可以更新潜在空间W中的倒潜码w′以获得期望的输出。但是,采用的StyleGAN的潜在空间可能与各种语义属性不够纠缠,以至于模型很难只更改生产图像的一个属性而同时保留其他与文本无关的属性。这为以后的改进留下了一定的空间。
使用StyleGAN作为文本到图像生成的骨干网络的另一个好处是,StyleGAN有很好的生成高分辨率图像的能力。因此,未来我们可以很容易地扩展我们提出的框架来生成更高分辨率的图像,比如1024 × 1024。在这里我们只生成256 × 256大小的图像来与现有的作品进行比较。
6 总结
在本文中,我们针对text-to-image generation and text-guided image manipulation tasks任务,提出了一种新的Cycle- consistent Inverse GAN (CI-GAN)统一框架,在野外两个具有挑战性的数据集上,我们首次将GAN inversion的思想融入到图像生成任务中。具体来说,我们首先训练一个没有条件文本输入的StyleGAN模型,这样模型就可以生成多样性高、质量好的图像。然后我们通过我们提出的cycle consistency training学习GAN inversion model,将图像转换回GAN潜在空间,得到inverted latent codes。为了生成具有我们想要的语义属性的图像,我们进一步发现GAN潜在空间的语义。我们学习了文本表示和潜在代码之间的相似性模型。采用学习到的相似度模型对文本到图像生成和图像操作任务的潜在代码进行优化。我们在Recipe1M和CUB数据集上进行了广泛的实验和分析,说明了我们提出的框架的优越性能。