利用神经网络实现手写字识别
神经网络介绍
神经网络即多层感知机
如果不知道感知机的可以看博主之前的文章感知机及Python实现
神经网络实现及手写字识别
关于数据集:
- 从http://yann.lecun.com/exdb/mnist/下载,下载后将文件解压
- 将
main函数中的path改为下载文件的存储路径即可
如果对数据集有问题,可以私信博主
关于实现:
- 基于
pytorch实现,包括神经网络的构建,激活函数的选择 - 归一化使用了像素值
/255的方式实现,可以尝试用别的方式进行归一化处理
import numpy as np
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
class Data:
'''
this class is about data module
'''
def __init__(self):
self.start_loc_image=16 # the start location of image data
self.start_loc_label=8 # the start location of label data
self.num_pixel=28*28 # the number of pixels
self.choice={
'train-image':'train-images.idx3-ubyte','train-label':'train-labels.idx1-ubyte',
'test-image':'t10k-images.idx3-ubyte','test-label':'t10k-labels.idx1-ubyte'} # the specific file name
def get(self,path,train_test='',image_label=''):
'''
get the data from the file whose path is "path"
:param path: the saving path of given files, default is "./file/"
:param train_test: the data category("train" or "test")
:param image_label: the data information("image" or "label")
:return: the data you want
'''
if train_test not in ['train','test'] or image_label not in ['image','label']:raise NameError(
'please check you spelling,"train_test" can be "train/test", "image_label" can be "image/label"')
ch=train_test+'-'+image_label
data=[]
if image_label=='image':
print('loading images ...')
with open(path+self.choice[ch],'rb',) as f:
file=f.read()
for i in range(self.start_loc_image,file.__len__(),self.num_pixel):
item=[]
pixel=file[i:i+self.num_pixel].hex()
for p in range(0,pixel.__len__(),2):
item.append(int(pixel[p:p+2],16)) # decode -> get the pixel information from original file
data.append(self.transform2image(item))
f.close()
elif image_label=='label':
print('load labels ...')
with open(path+self.choice[ch],'rb',) as f:
file=f.read()
for i in range(self.start_loc_label,file.__len__()):
data.append(file[i]) # decode -> get the label from original file
f.close()
return data
def transform2image(self,data:list):
'''
transform pixel point to image
:param data: the original 1D pixel points
:return: transformed image(28*28)
'''
assert data.__len__()==784
import numpy as np
return np.reshape(data,(28,-1))
def transfer_tensor(self,data):
'''
transfer data to tensor format
:param data: the original input data
:return: transferred data
'''
return torch.tensor(data)
def normalize(self,data,maximum=255):
'''
normalize the data with maximum
:param data: the input data
:param maximum: the maximum of pixel(is 255)
:return: normalized data
'''
return torch.div(data,maximum)
class Network(nn.Module):
'''
this class is about neural network
'''
def __init__(self,in_dim,n_hidden,out_dim):
'''
define the network
:param in_dim: the input dimension
:param n_hidden: the hidden layer dimension
:param out_dim: the output dimension
'''
### about network
super(Network, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim,n_hidden))
self.layer2 = nn.Sequential(nn.Linear(n_hidden,out_dim))
### other parameter
self.size_pixel=28*28 # the size of pixed of each picture
### learning rate
self.learning_rate=0.001
### optimizer
self.optimizer=optim.SGD(self.parameters(),lr=self.learning_rate)
def forward(self,data):
'''
forward the input data
:param data: the data you want to train
:return: the output or predicted value
'''
hidden=F.relu(self.layer1(data))
out=F.sigmoid(self.layer2(hidden))
return out
def accuracy(self,act,pre):
'''
calculate the accuracy
:param act: actual value
:param pre: predicted value
:return: accuracy
'''
assert act.__len__()==pre.__len__()
return round((act==pre).sum().item()/act.__len__(),3)
def pre_process(self,feature,label):
'''
pre processing
:param feature: feature
:param label: label
:return: preprocessed feature and label
'''
### transform to the format of tensor
feature=dat.transfer_tensor(feature)
feature=dat.normalize(feature)
feature=feature.view(-1,self.size_pixel)
label=dat.transfer_tensor(label)
return feature,torch.tensor(label,dtype=torch.int64)
def per_train(self,epoch,feature,label,validation=0.2,batch=50,verbose=True,num_view=50):
'''
train neural network
:param epoch: training times
:param feature: feature
:param label: label
:param validation: for using evaluation
:param batch: batch size
:param verbose: whether view the training process or not
:param num_view: view via training "num_view" times
:return: none
'''
assert feature.__len__()==label.__len__()
print('training neural network ...')
fea,lab=self.pre_process(feature,label)
len_train=int(feature.__len__()*(1-validation))
data_train,label_train=fea[:len_train+1],lab[:len_train+1]
data_train=[data_train[i:i+batch]for i in range(0,len_train,batch)]
label_train=[label_train[i:i+batch]for i in range(0,len_train,batch)]
data_val,label_val=fea[len_train:],lab[len_train:]
for e in range(epoch+1):
self.train()
loss_tmp=[]
for img,lab in zip(data_train,label_train):
pre=self(img)
loss_train=nn.CrossEntropyLoss()(pre,lab)
loss_tmp.append(loss_train)
loss_train.backward()
self.optimizer.step()
self.optimizer.zero_grad()
if verbose and e>0 and e%num_view==0:
self.eval()
pre=self(data_val)
loss_val=nn.CrossEntropyLoss()(pre,label_val)
_,pre_view=pre.max(1)
acc=self.accuracy(label_val,pre_view)
print('epoch: '+str(e)+'/'+str(epoch)+' --> training loss:',loss_train.item(),'validation loss:',
loss_val.item(),'validation accuracy:',acc)
def set_seed(seed):
'''
set random seed in order that result can be replayed
:param seed: random seed
:return: none
'''
import random
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
np.random.seed(seed)
random.seed(seed)
Seed=0
Size_pixel= 28*28
Hidden=200
Output=10
set_seed(Seed)
if __name__ == '__main__':
### set some necessary parameters
path='./file/' # the path of saved file
### initialize necessary class
dat=Data() # for data related
net=Network(Size_pixel,Hidden,Output) # build network
### load image and label of training data and testing data
# train_image=dat.get(path,'train','image')
# train_label=dat.get(path,'train','label')
test_image=dat.get(path,'test','image')
test_label=dat.get(path,'test','label')
### train network
epoch=1000 # training times
net.per_train(epoch,test_image,test_label)
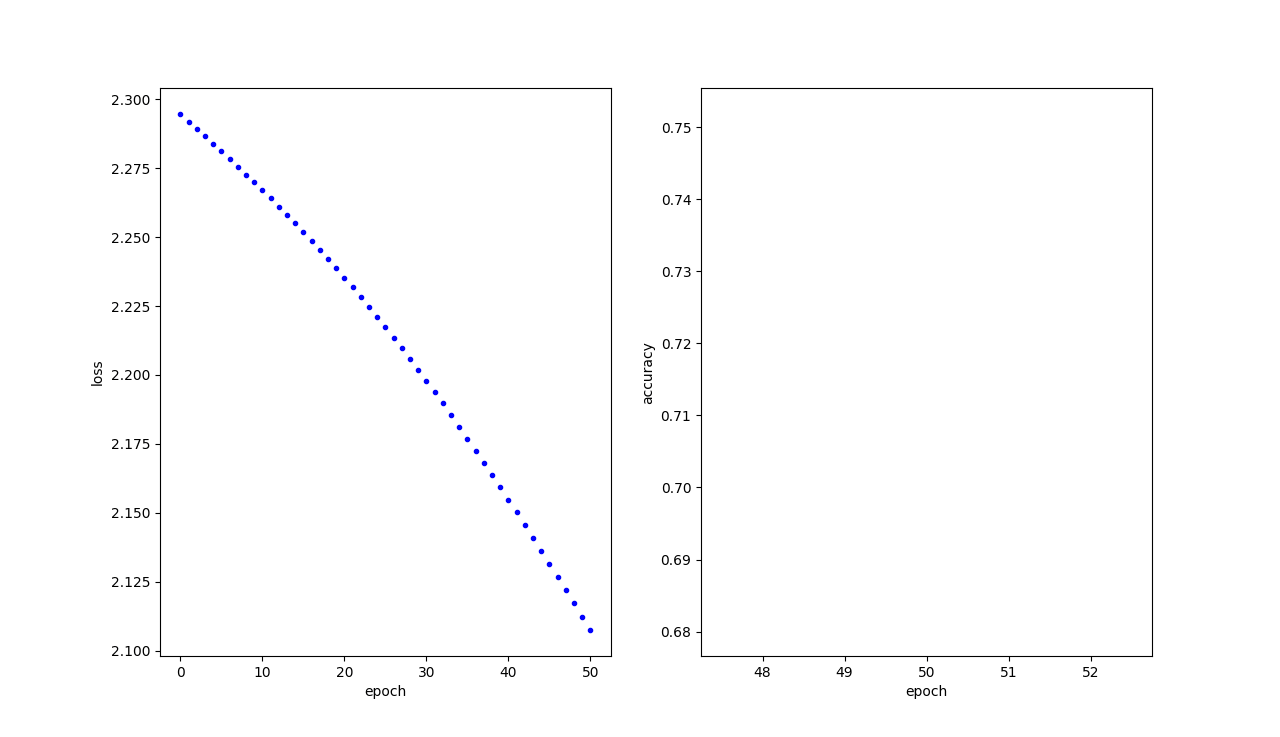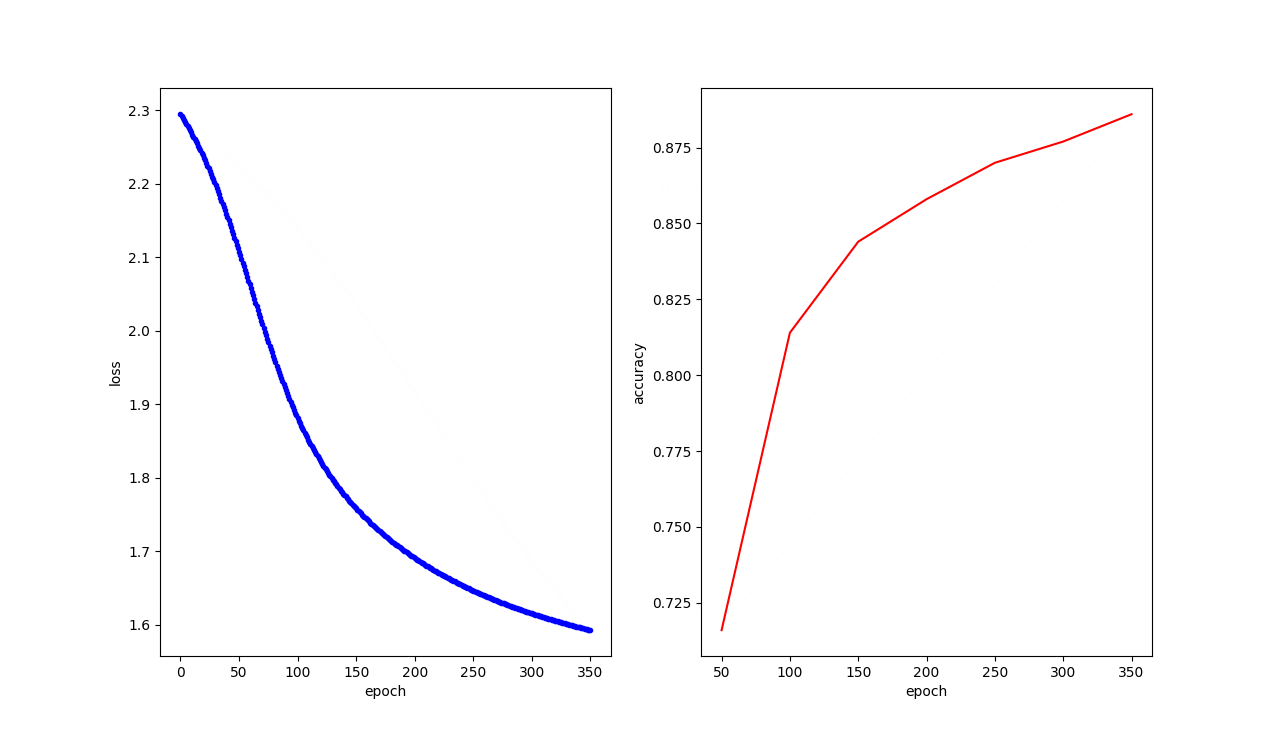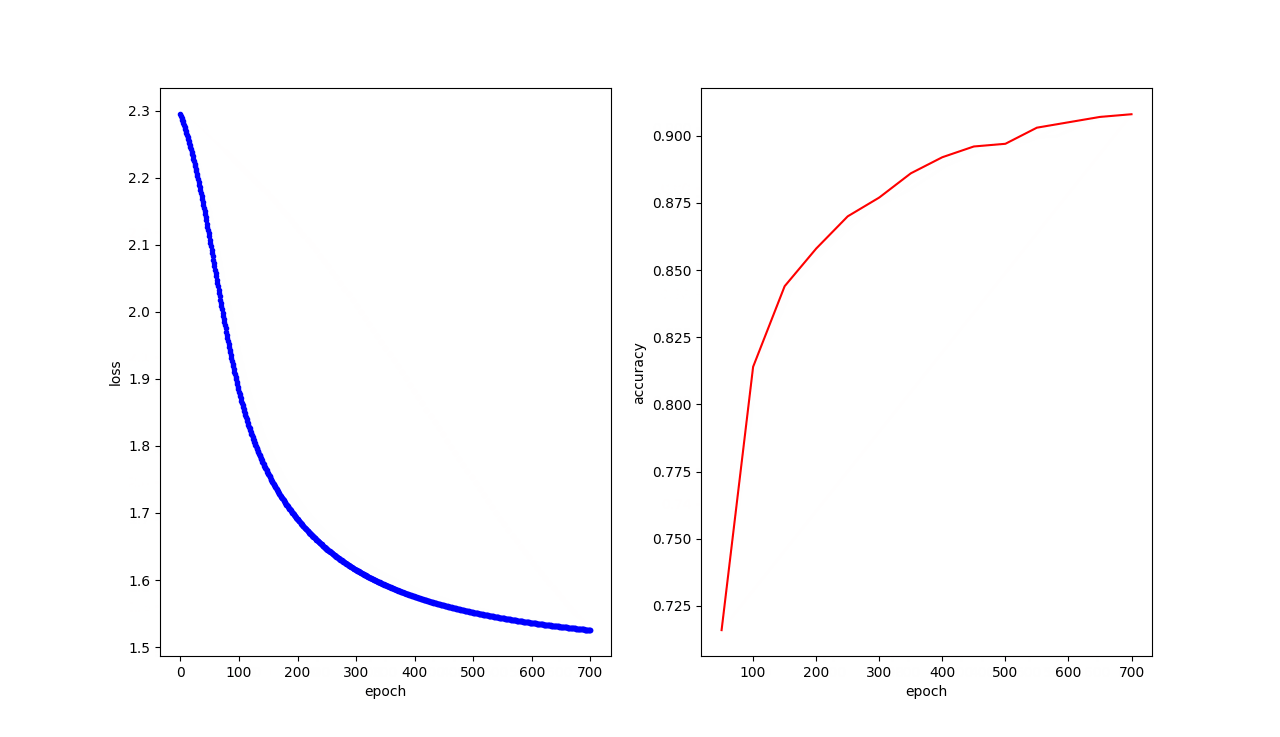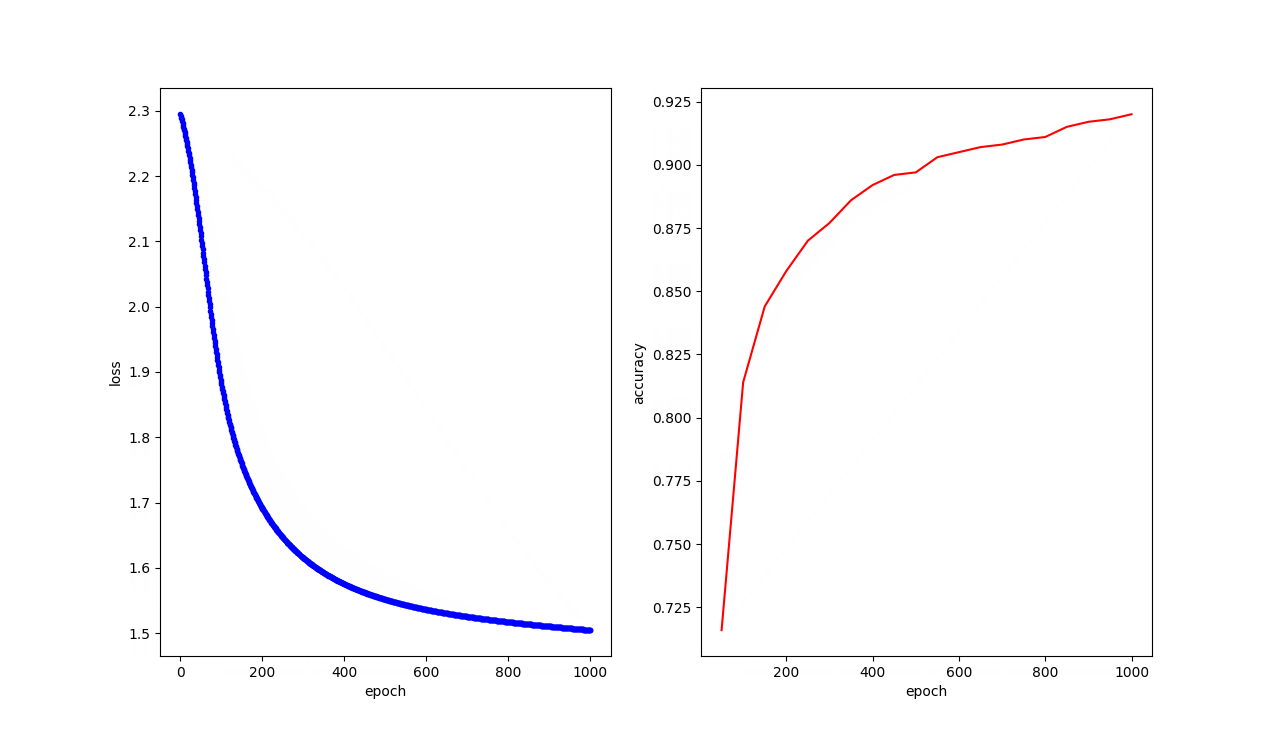
结果展示
可以看到随着训练次数的增加,预测手写字的准确率也越来越高
运行结果
loading images ...
load labels ...
training neural network ...
epoch: 50/1000 --> training loss: 2.1074414253234863 validation loss: 2.1338484287261963 validation accuracy: 0.716
epoch: 100/1000 --> training loss: 1.8810529708862305 validation loss: 1.9262853860855103 validation accuracy: 0.814
epoch: 150/1000 --> training loss: 1.7580647468566895 validation loss: 1.811558723449707 validation accuracy: 0.844
epoch: 200/1000 --> training loss: 1.6905272006988525 validation loss: 1.7511157989501953 validation accuracy: 0.858
epoch: 250/1000 --> training loss: 1.6461492776870728 validation loss: 1.7131295204162598 validation accuracy: 0.87
epoch: 300/1000 --> training loss: 1.6150131225585938 validation loss: 1.6869707107543945 validation accuracy: 0.877
epoch: 350/1000 --> training loss: 1.5923327207565308 validation loss: 1.6678192615509033 validation accuracy: 0.886
epoch: 400/1000 --> training loss: 1.5752110481262207 validation loss: 1.653057336807251 validation accuracy: 0.892
epoch: 450/1000 --> training loss: 1.5620046854019165 validation loss: 1.6411659717559814 validation accuracy: 0.896
epoch: 500/1000 --> training loss: 1.5515371561050415 validation loss: 1.6312130689620972 validation accuracy: 0.897
epoch: 550/1000 --> training loss: 1.5430898666381836 validation loss: 1.6226950883865356 validation accuracy: 0.903
epoch: 600/1000 --> training loss: 1.5360981225967407 validation loss: 1.615297794342041 validation accuracy: 0.905
epoch: 650/1000 --> training loss: 1.5302610397338867 validation loss: 1.608830451965332 validation accuracy: 0.907
epoch: 700/1000 --> training loss: 1.5252583026885986 validation loss: 1.603135108947754 validation accuracy: 0.908
epoch: 750/1000 --> training loss: 1.5209182500839233 validation loss: 1.5980955362319946 validation accuracy: 0.91
epoch: 800/1000 --> training loss: 1.5170769691467285 validation loss: 1.5936044454574585 validation accuracy: 0.911
epoch: 850/1000 --> training loss: 1.513597846031189 validation loss: 1.5895581245422363 validation accuracy: 0.915
epoch: 900/1000 --> training loss: 1.5103877782821655 validation loss: 1.5858769416809082 validation accuracy: 0.917
epoch: 950/1000 --> training loss: 1.5073943138122559 validation loss: 1.5824891328811646 validation accuracy: 0.918
epoch: 1000/1000 --> training loss: 1.5045477151870728 validation loss: 1.5793448686599731 validation accuracy: 0.92
效果展示