中文MNIST数据集的图像分类(准确度99.93%)
数据集
链接:
Chinese MNIST | KaggleChinese numbers handwritten characters imageshttps://www.kaggle.com/gpreda/chinese-mnist
简介:
中国版的 MNIST 数据集是在纽卡斯尔大学的一个项目框架中收集的数据。一百名中国公民参与了数据收集工作。 每个参与者用标准的黑色墨水笔在一张桌子上写下所有 15 个数字,在一张白色 A4 纸上画出了 15 个指定区域。 这个过程对每个参与者重复 10 次。 每张纸都以 300x300 像素的分辨率扫描。结果返回一个包含 15000 个图像的数据集,每个图像代表一组 15 个字符中的一个字符。
代码
引入相关类库
natsort是一个用于排序的类库,为什么这么多的排序不用,偏偏使用这个,因为它的排序规则与Windows的文件排序规则一致!因为csv里面的标签与图片是分离的,所以需要自己先找到办法,把图片和标签正确对应起来。
!pip install natsort #排序规则与Windows的文件排序规则一致import pandas as pd
import numpy as np
import sys
import os
import tensorflow as tf
from pathlib import Path
import sklearn
from sklearn.model_selection import train_test_split
from tensorflow import keras
import warnings
from natsort import ns, natsorted
warnings.filterwarnings('ignore')读入数据 & 排序
csv文件的排序处理
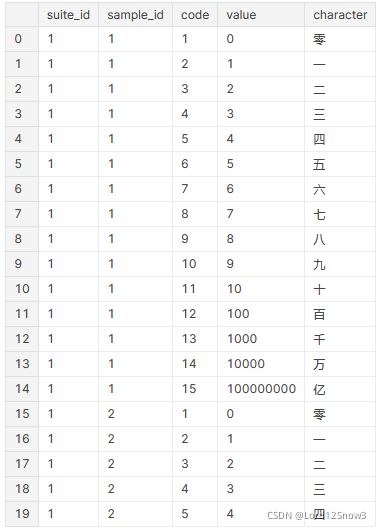
把csv文件,按照 'suite_id', 'sample_id', 'code' 先后进行升序排列,得到的就有规律的排列情况,将会与后面的图片排序,一一对应。
data_df = pd.read_csv('../input/chinese-mnist/chinese_mnist.csv') #读入csv文件
data_df.sort_values(by=['suite_id','sample_id','code'], ascending=True, inplace=True)
#按照 'suite_id', 'sample_id', 'code' 先后进行升序排列
data_df = data_df.reset_index(drop=True) #使索引按照新的排序排列,并丢弃旧的索引
data_df[:20] #显示前20行显示前20行
图片的排序处理
接下来对图片按照Window的排序规则进行排序
image_dir = Path('../input/chinese-mnist/data/data') #获取图片的根目录
image_paths = list(image_dir.glob('*.jpg')) #获取所有图片的位置
image_paths = natsorted(image_paths, alg=ns.PATH) #按照windows的规则排序
image_paths = pd.Series(image_paths, name='Image_path').astype(str) #拼接成csv文件
image_paths[:20] #展示前20行展示前20行

从csv文件中取得标签,与图片的位置拼接成新的csv文件。
labels = data_df['code'].astype(str) #需要转成字符串类型,不然会报错
image_df = pd.concat([image_paths, labels], axis=1) #拼接标签与图片的位置
image_df.rename(columns={'code': 'Label'}, inplace=True) #对列名重命名
image_df[:20] #展示前20行
展示前20行

分割训练集和测试集
shuffle_df = image_df.sample(frac=1) #对数据集进行打乱,fac=1表示100%
image_train = shuffle_df[:13500] #取前13500行作为训练数据集
image_test = shuffle_df[13500:] #取后面的行作为测试数据集
把数据集装入迭代器 & 数据的归一化处理
#训练集和验证集
train_generator = keras.preprocessing.image.ImageDataGenerator(
#数据的归一化处理,用了这个不能再用rescale,会重复
preprocessing_function=keras.applications.resnet50.preprocess_input,
#数据增强
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
#把训练集分成训练集和验证集
validation_split=0.11
)
#测试集
test_generator = keras.preprocessing.image.ImageDataGenerator(
preprocessing_function=keras.applications.resnet50.preprocess_input,
)#训练集
train_images = train_generator.flow_from_dataframe(
dataframe=image_train,
x_col='Image_path',
y_col='Label',
target_size=(64, 64),
batch_size=128,
shuffle=True,
subset='training',
)
#验证集
valid_images = train_generator.flow_from_dataframe(
dataframe=image_train,
x_col='Image_path',
y_col='Label',
target_size=(64, 64),
batch_size=128,
shuffle=True,
subset='validation',
)
#测试集
test_images = train_generator.flow_from_dataframe(
dataframe=image_test,
x_col='Image_path',
y_col='Label',
target_size=(64, 64),
batch_size=128,
shuffle=True,
)
控制台的输出

引入预训练模型
#使用tf.keras调用ResNet50预训练模型
pretrained_model = keras.applications.ResNet50(
include_top=False,
#不包含最后的输出层,因为默认的输出参数是2000,需要改成自己想要的输出类数
weights='imagenet', #模型的预训练权重参数,使用imagenet
input_shape=(64,64,3), #定义输入的图片维度
pooling='avg', #平均池化
)
# pretrained_model.trainable = False
#不对ResNet50预训练模型进行训练,只训练自己新加入的全连接层。
#模型的连接
model = keras.models.Sequential([
pretrained_model,
keras.layers.Dense(256, activation='relu'),
keras.layers.BatchNormalization(),
# keras.layers.Dropout(0.2),
# keras.layers.Dense(128, activation='relu'),
# keras.layers.BatchNormalization(),
keras.layers.Dense(15, activation='softmax'),
])
#模型编译,交叉熵,优化器选adam,标尺用准确率
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 输出模型概况
model.summary()
训练与评估模型性能
#提前停止训练,避免过拟合
early_stopping = keras.callbacks.EarlyStopping(
patience=15,
restore_best_weights=True
)
#训练不动时,使用退火,降低学习率,以进一步拟合模型
reduce_lr_plateau = keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=3,
verbose=1,
)训练
history = model.fit(
train_images,
epochs=1000,
callbacks=[early_stopping, reduce_lr_plateau],
validation_data=valid_images,
)
Epoch 1/1000
2021-09-29 10:45:36.536914: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-09-29 10:45:37.340665: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-09-29 10:45:37.437637: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
94/94 [==============================] - 92s 863ms/step - loss: 0.8411 - accuracy: 0.7481 - val_loss: 11.5625 - val_accuracy: 0.3785
Epoch 2/1000
94/94 [==============================] - 27s 286ms/step - loss: 0.0916 - accuracy: 0.9702 - val_loss: 3.1282 - val_accuracy: 0.5832
Epoch 3/1000
94/94 [==============================] - 26s 279ms/step - loss: 0.0662 - accuracy: 0.9812 - val_loss: 0.3096 - val_accuracy: 0.9286
Epoch 4/1000
94/94 [==============================] - 26s 275ms/step - loss: 0.0506 - accuracy: 0.9841 - val_loss: 9.4715 - val_accuracy: 0.1852
Epoch 5/1000
94/94 [==============================] - 26s 280ms/step - loss: 0.0497 - accuracy: 0.9868 - val_loss: 2.9237 - val_accuracy: 0.5825
Epoch 6/1000
94/94 [==============================] - 27s 286ms/step - loss: 0.0448 - accuracy: 0.9870 - val_loss: 2.7974 - val_accuracy: 0.5178
Epoch 00006: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257.
Epoch 7/1000
94/94 [==============================] - 27s 284ms/step - loss: 0.0235 - accuracy: 0.9932 - val_loss: 0.1191 - val_accuracy: 0.9717
Epoch 8/1000
94/94 [==============================] - 26s 278ms/step - loss: 0.0140 - accuracy: 0.9969 - val_loss: 0.0553 - val_accuracy: 0.9838
Epoch 9/1000
94/94 [==============================] - 26s 273ms/step - loss: 0.0129 - accuracy: 0.9959 - val_loss: 0.0237 - val_accuracy: 0.9926
Epoch 10/1000
94/94 [==============================] - 27s 284ms/step - loss: 0.0113 - accuracy: 0.9980 - val_loss: 0.0458 - val_accuracy: 0.9892
Epoch 11/1000
94/94 [==============================] - 26s 281ms/step - loss: 0.0079 - accuracy: 0.9977 - val_loss: 0.0879 - val_accuracy: 0.9758
Epoch 12/1000
94/94 [==============================] - 27s 282ms/step - loss: 0.0168 - accuracy: 0.9949 - val_loss: 0.0421 - val_accuracy: 0.9892
Epoch 00012: ReduceLROnPlateau reducing learning rate to 0.0002500000118743628.
Epoch 13/1000
94/94 [==============================] - 26s 278ms/step - loss: 0.0104 - accuracy: 0.9972 - val_loss: 0.0211 - val_accuracy: 0.9966
Epoch 14/1000
94/94 [==============================] - 26s 274ms/step - loss: 0.0091 - accuracy: 0.9982 - val_loss: 0.0177 - val_accuracy: 0.9973
Epoch 15/1000
94/94 [==============================] - 27s 281ms/step - loss: 0.0074 - accuracy: 0.9978 - val_loss: 0.0217 - val_accuracy: 0.9960
Epoch 16/1000
94/94 [==============================] - 26s 277ms/step - loss: 0.0061 - accuracy: 0.9988 - val_loss: 0.0189 - val_accuracy: 0.9966
Epoch 17/1000
94/94 [==============================] - 26s 279ms/step - loss: 0.0044 - accuracy: 0.9993 - val_loss: 0.0256 - val_accuracy: 0.9953
Epoch 00017: ReduceLROnPlateau reducing learning rate to 0.0001250000059371814.
Epoch 18/1000
94/94 [==============================] - 26s 279ms/step - loss: 0.0092 - accuracy: 0.9975 - val_loss: 0.0179 - val_accuracy: 0.9980
Epoch 19/1000
94/94 [==============================] - 26s 275ms/step - loss: 0.0044 - accuracy: 0.9985 - val_loss: 0.0267 - val_accuracy: 0.9960
Epoch 20/1000
94/94 [==============================] - 27s 285ms/step - loss: 0.0024 - accuracy: 0.9994 - val_loss: 0.0123 - val_accuracy: 0.9993
Epoch 21/1000
94/94 [==============================] - 26s 279ms/step - loss: 0.0036 - accuracy: 0.9985 - val_loss: 0.0124 - val_accuracy: 0.9987
Epoch 22/1000
94/94 [==============================] - 27s 282ms/step - loss: 0.0049 - accuracy: 0.9989 - val_loss: 0.0152 - val_accuracy: 0.9987
Epoch 23/1000
94/94 [==============================] - 26s 276ms/step - loss: 0.0040 - accuracy: 0.9989 - val_loss: 0.0163 - val_accuracy: 0.9980
Epoch 00023: ReduceLROnPlateau reducing learning rate to 6.25000029685907e-05.
Epoch 24/1000
94/94 [==============================] - 26s 275ms/step - loss: 0.0025 - accuracy: 0.9996 - val_loss: 0.0132 - val_accuracy: 0.9987
Epoch 25/1000
94/94 [==============================] - 26s 281ms/step - loss: 0.0013 - accuracy: 0.9998 - val_loss: 0.0167 - val_accuracy: 0.9973
Epoch 26/1000
94/94 [==============================] - 26s 281ms/step - loss: 0.0050 - accuracy: 0.9987 - val_loss: 0.0138 - val_accuracy: 0.9993
Epoch 00026: ReduceLROnPlateau reducing learning rate to 3.125000148429535e-05.
Epoch 27/1000
94/94 [==============================] - 27s 282ms/step - loss: 0.0016 - accuracy: 0.9997 - val_loss: 0.0131 - val_accuracy: 0.9993
Epoch 28/1000
94/94 [==============================] - 27s 283ms/step - loss: 0.0029 - accuracy: 0.9988 - val_loss: 0.0113 - val_accuracy: 0.9993
Epoch 29/1000
94/94 [==============================] - 26s 275ms/step - loss: 0.0015 - accuracy: 0.9996 - val_loss: 0.0158 - val_accuracy: 0.9980
Epoch 30/1000
94/94 [==============================] - 27s 283ms/step - loss: 9.5298e-04 - accuracy: 0.9999 - val_loss: 0.0135 - val_accuracy: 0.9987
Epoch 31/1000
94/94 [==============================] - 27s 282ms/step - loss: 0.0025 - accuracy: 0.9994 - val_loss: 0.0140 - val_accuracy: 0.9987
Epoch 00031: ReduceLROnPlateau reducing learning rate to 1.5625000742147677e-05.
Epoch 32/1000
94/94 [==============================] - 27s 285ms/step - loss: 0.0035 - accuracy: 0.9989 - val_loss: 0.0136 - val_accuracy: 0.9987
Epoch 33/1000
94/94 [==============================] - 26s 281ms/step - loss: 0.0013 - accuracy: 0.9998 - val_loss: 0.0155 - val_accuracy: 0.9987
Epoch 34/1000
94/94 [==============================] - 27s 283ms/step - loss: 0.0020 - accuracy: 0.9995 - val_loss: 0.0115 - val_accuracy: 0.9993
Epoch 00034: ReduceLROnPlateau reducing learning rate to 7.812500371073838e-06.
Epoch 35/1000
94/94 [==============================] - 26s 275ms/step - loss: 0.0020 - accuracy: 0.9997 - val_loss: 0.0141 - val_accuracy: 0.9993
Epoch 36/1000
94/94 [==============================] - 27s 283ms/step - loss: 0.0015 - accuracy: 0.9998 - val_loss: 0.0119 - val_accuracy: 0.9993
Epoch 37/1000
94/94 [==============================] - 27s 284ms/step - loss: 0.0022 - accuracy: 0.9992 - val_loss: 0.0141 - val_accuracy: 0.9987
Epoch 00037: ReduceLROnPlateau reducing learning rate to 3.906250185536919e-06.
Epoch 38/1000
94/94 [==============================] - 27s 283ms/step - loss: 0.0023 - accuracy: 0.9993 - val_loss: 0.0142 - val_accuracy: 0.9987
Epoch 39/1000
94/94 [==============================] - 27s 284ms/step - loss: 0.0012 - accuracy: 0.9998 - val_loss: 0.0127 - val_accuracy: 0.9993
Epoch 40/1000
94/94 [==============================] - 26s 280ms/step - loss: 0.0028 - accuracy: 0.9992 - val_loss: 0.0146 - val_accuracy: 0.9980
Epoch 00040: ReduceLROnPlateau reducing learning rate to 1.9531250927684596e-06.
Epoch 41/1000
94/94 [==============================] - 26s 281ms/step - loss: 0.0028 - accuracy: 0.9996 - val_loss: 0.0143 - val_accuracy: 0.9987
Epoch 42/1000
94/94 [==============================] - 27s 285ms/step - loss: 0.0027 - accuracy: 0.9994 - val_loss: 0.0138 - val_accuracy: 0.9980
Epoch 43/1000
94/94 [==============================] - 26s 282ms/step - loss: 0.0025 - accuracy: 0.9992 - val_loss: 0.0128 - val_accuracy: 0.9993
Epoch 00043: ReduceLROnPlateau reducing learning rate to 9.765625463842298e-07.
模型评估
model.evaluate(test_images)12/12 [==============================] - 9s 790ms/step - loss: 0.0229 - accuracy: 0.9953
[0.022892117500305176, 0.9953333139419556]