yolo系列学习(入门经过)
1、端到端训练的具体含义是什么(一个loss function搞定训练,只需关注输入端和输出端)
相关学习资料:
1、千赞博客(YOLOv3,内附有v1,v2链接):yolo系列之yolo v3【深度解析】_木盏-CSDN博客_yolov3
2、 知乎江大白大佬(对新手快速了解很友好,但知识有一点点没覆盖到):
- yolov5:深入浅出Yolo系列之Yolov5核心基础知识完整讲解 - 知乎
- v3-x的: 深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎
(有对应的视频讲解,跟博客内容基本一致,喜欢视频学习的可以到知乎上搜索)
3. yolov4相关的边缘技术(数据增强之类的,有些还比较详细,可以拓展一下):
想读懂YOLOV4,你需要先了解下列技术(一) - 知乎
4、B站子豪兄(v1-v3,讲的非常透):
- yolov1(包括算法讲解,论文精读,可选集,里面的作者介绍之类的讲解我也很喜欢):【精读AI论文】YOLO V1目标检测,看我就够了_哔哩哔哩_bilibili
- yolov2:【精读AI论文】YOLO V2目标检测算法_哔哩哔哩_bilibili
- yolov3:【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现)_哔哩哔哩_bilibili
5、 论文在这些博客里面基本都有链接
6. 本文的内容可能比较零散,还没整理,想具体了解Yolo可以看上面的博客或者我的其他文章
二、yolov5模型重写
1、yolov5训练复现
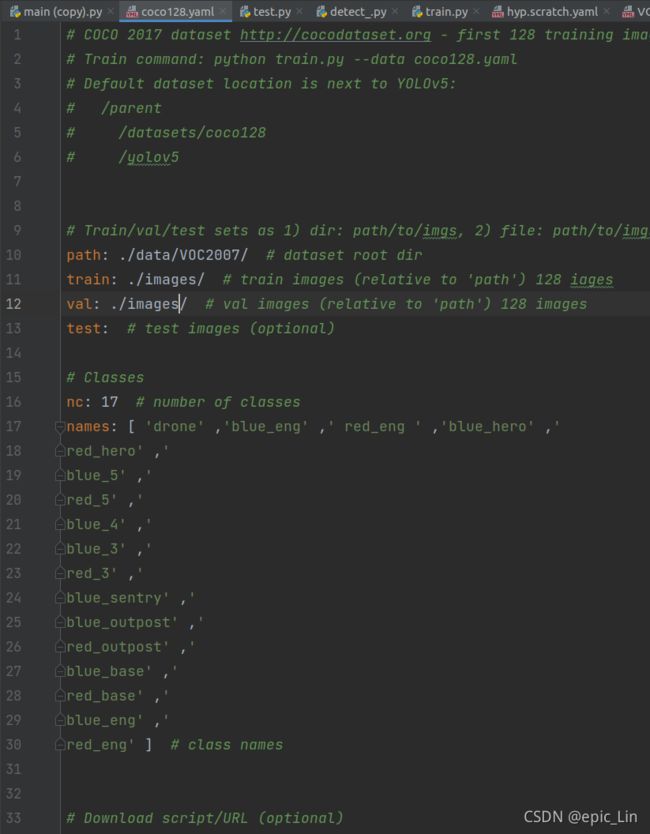
数据集配置文件coco128里面改了训练集的路径到自己的训练集,好像图片集可以直接连接到标签。(那如果标签文件夹改个名字呢,还能找到吗,它们之间是怎么联系的呢)这里验证集有点小问题,必须用images这个名字,换val什么之类的找不到测试集图片,后面看看怎么解决
最后训练了17个epoch左右就收敛的差不多了,
2、读yolov5代码
(1)从detect, parse_opt开始:
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
#FILE = Path(__file__).resolve()
return opt
#2021.10.31最新代码
weights:训练的权重
source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
output:网络预测之后的图片/视频的保存路径
img-size:网络输入图片大小
conf-thres:置信度阈值
iou-thres:做nms的iou阈值
device:设置设备
view-img:是否展示预测之后的图片/视频,默认False
save-txt:是否将预测的框坐标以txt文件形式保存,默认False
classes:设置只保留某一部分类别,形如0或者0 2 3
agnostic-nms:进行nms是否也去除不同类别之间的框,默认False(NMS是去除重叠比较大的同类的框,这个参数可能是去除不同类别的)
augment:推理的时候进行多尺度,翻转等操作(TTA)推理
update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
(2)从头开始,各种定义
default是默认的参数,即使不写上去也会执行;action='store_true是写上去这个名字比如--view-img就为true;nargs='+'是可以输入多个参数(filter by class: --class 0, or --class 0 2 3)
FILE = Path(__file__).resolve()Path----可以进行调用的PurePath子类

为啥Path()里面放__file__,
path().resolve:将路径设置为绝对路径,解析路径上的所有符号链接,并将其规范化(例如在Windows下将斜杠转换为反斜杠)。
ROOT得到YOLOv5根路径:
ROOT = FILE.parents[0] # YOLOv5 root directory添加ROOT到系统路径:
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH

ROOT = Path(os.path.relpath(ROOT, Path.cwd())) os.path.relpath是求相对路径的(把绝对路径转化成相对路径,前面那个相对于后面那个的相对路径):,【python3学习笔记】os.path.relpath(path[, start])_Murphy.AI 的文章-CSDN博客
Path.cwd()获取当前路径,防止路径在ROOT前面,把这个补到后面weights等文件的路径中
(3)run函数:
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
imgsz=640, # inference size (pixels)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):iou_thres:NMS IOU threshold
max_det=1000---------最大检测数量
visualize: --------可视化功能
project:结果保存在runs/detect中
name:文件名称'exp'
exist_ok:existing project/name ok, do not increment
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)opt.imgsz这行是前面放参数的时候 ,default=[640],长度是1,调整成2
上面这几行要干嘛就没看懂了(这个是在代码最后面文章)
save_img = not nosave and not source.endswith('.txt')同时满足nosave和后缀(.txt)都not(为什么source以.txt结尾img就不保存)
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
isnumeric():如果输入中只有数字字符则返回True
lower():字符串转小写
source中全是数字,或者以.txt结尾,或者以这些网络开头就True
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir这里exist_ok的意思好像是要不要覆盖,但不太确定
increment_path是创造文件夹并且返回路径
这里是创造保存预测框的路径,save_txt是True就保存在exp/'labels',False就保存在exp
Path(project)是运行结果保存的路径,在参数里面定义,Path()方法就是YOLO里面用的多的路径规范方法,就不纠结了,有时间研究一下
mkdir:在给定路径上创建一个新目录(parents=True什么意思,exist_ok=True什么意思又忘了)
如果save_txt=False,就创建save_dir,那上面就已经increment_path就已经创建save_dir并返回路径了,下面怎么再mkdir save_dir,还有save_txt=False是什么参数True呢,也就是说这执行的是什么功能
# Initialize
set_logging()
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
set_logging():
有机会select_device()是什么内容一定要去看一下,是推理时候选择设备的原理是什么
w = str(weights[0] if isinstance(weights, list) else weights)
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes) # check weights have acceptable suffix
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaultsisinstance函数:
dsfPython isinstance() 函数_小白_努力-CSDN博客
如果weights是列表就返回第一个元素,如果不是列表就直接返回,然后转成str。这里是weights可以写多个
suffix():最后一个组件的最后后缀(如果有的话)
这里classify=False不知道是干啥的,suffix是weights的后缀,suffixs是可供查找的后缀名
if pt:
model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
if classify: # second-stage classifier
modelc = load_classifier(name='resnet50', n=2) # initialize
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval()
elif onnx:
if dnn:
check_requirements(('opencv-python>=4.5.4',))
net = cv2.dnn.readNetFromONNX(w)
else:
check_requirements(('onnx', 'onnxruntime-gpu' if torch.has_cuda else 'onnxruntime'))
import onnxruntime
session = onnxruntime.InferenceSession(w, None)
else: # TensorFlow models
check_requirements(('tensorflow>=2.4.1',))
import tensorflow as tf
if pb: # https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
def wrap_frozen_graph(gd, inputs, outputs):
x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped import
return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs),
tf.nest.map_structure(x.graph.as_graph_element, outputs))
graph_def = tf.Graph().as_graph_def()
graph_def.ParseFromString(open(w, 'rb').read())
frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0")
elif saved_model:
model = tf.keras.models.load_model(w)
elif tflite:
interpreter = tf.lite.Interpreter(model_path=w) # load TFLite model
interpreter.allocate_tensors() # allocate
input_details = interpreter.get_input_details() # inputs
output_details = interpreter.get_output_details() # outputs
int8 = input_details[0]['dtype'] == np.uint8 # is TFLite quantized uint8 model
imgsz = check_img_size(imgsz, s=stride) # check image sizepd, saved_model, tflite都是TensorFlow models
tflite:tensorflow 19: tflite 概念理解_yuanlulu的博客 -CSDN博客_tflite
这里是五种类型的权重分别执行什么代码,以后回来看
不过.pt可以先关注一下:
if pt:
model = torch.jit.load(w) if 'torchscipt' in w else attempt_load(weights, map_location=device)
stride = int(model.stride.max())
names = model.module.names if hasattr(model, 'module') else model.names
i if half:
model.half()
if classify:
modelc = load_classifier(name='resnet50', n=2)
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']这里代码没打完,有时间再看一下
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bscheck_imshow():检测环境是否支持图像显示
cudnn.benchmark = True:
在推理时使用torch.backends.cudnn.benchmark = true,可以让内置的 cuDNN 的 auto-tuner 自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。
一般来讲,应该遵循以下准则:
①. 如果网络的输入数据维度或类型上变化不大,设置 torch.backends.cudnn.benchmark = true 可以增加运行效率;
②. 如果网络的输入数据在每次 iteration 都变化的话,会导致 cnDNN 每次都会去寻找一遍最优配置,这样反而会降低运行效率。
所以,推理视频流时,应保证每个摄像头传递给算法的图片一样大小。
LoadStreams:
auto=pt,如果是pt就执行auto(虽然也不知道auto是干啥用的)
打开webcam之后这里dataset只得到一张图片,这跟stride=32有冲突吗,还有这里两种情况的e 代码
# Run inference
if pt and device.type != 'cpu':
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.parameters()))) # run once
dt, seen = [0.0, 0.0, 0.0], 0
for path, img, im0s, vid_cap in dataset:
t1 = time_sync()
if onnx:
img = img.astype('float32')
else:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1torch.zeros(1,3,*imgsz)是创建一个作为试验的四维张量,不过*imgsz是怎么把长宽导进去的
next是迭代器,把model的参数一个一个推出来,调试后可以看到next(model.parameters())的形状是[32,3,6,6],为什么这里的参数是这个形状,还有为什么要放这种形状的输入进去,这个网络的图像大小是6*6吗???
img = img[None] 可以让图片张量直接增加一个维度
如果是Pt就向前run一次看能不能跑通
for 里面的im0s是什么用,下面记得注意一下
这里vid_cap是None,也就是说如果放进去mp4,循环可以跑出来的东西会多一维
if pt:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(img, augment=augment, visualize=visualize)[0]
elif onnx:
if dnn:
net.setInput(img)
pred = torch.tensor(net.forward())
else:
pred = torch.tensor(session.run([session.get_outputs()[0].name], {session.get_inputs()[0].name: img}))
else: # tensorflow model (tflite, pb, saved_model)
imn = img.permute(0, 2, 3, 1).cpu().numpy() # image in numpy
if pb:
pred = frozen_func(x=tf.constant(imn)).numpy()
elif saved_model:
pred = model(imn, training=False).numpy()
elif tflite:
if int8:
scale, zero_point = input_details[0]['quantization']
imn = (imn / scale + zero_point).astype(np.uint8) # de-scale
interpreter.set_tensor(input_details[0]['index'], imn)
interpreter.invoke()
pred = interpreter.get_tensor(output_details[0]['index'])
if int8:
scale, zero_point = output_details[0]['quantization']
pred = (pred.astype(np.float32) - zero_point) * scale # re-scale
pred[..., 0] *= imgsz[1] # x
pred[..., 1] *= imgsz[0] # y
pred[..., 2] *= imgsz[1] # w
pred[..., 3] *= imgsz[0] # h
pred = torch.tensor(pred)
t3 = time_sync()
dt[1] += t3 - t2visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
Path(path).stem,stem是拿出最后的部分,去掉后缀。
path={str}'/home/robot/yolov5-master/yolov5/data/images/bus.jpg'
Path(path)={PosixPath}/home/robot/yolov5-master/yolov5/data/images/bus.jpg
Path(path).stem='bus'
save_dir / Path(path).stem = {PosixPath}/runs/detect/exp10/bus
visualize = increment_path(save_dir / Path(path).stem, mkdir=True)=/runs/detect/exp10/bus
如果visualize=True就创建文件并且返回路径
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3augment,这个参数的操作有时间了解一下
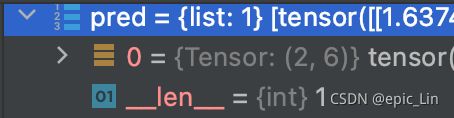
pred ---- Tensor(1,18900,85)
经过NMS之后变成了
# Second-stage classifier (optional)
if classify:
pred = apply_classifier(pred, modelc, img, im0s)classify是干啥用的??
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
det是预测的结果,len(det)是预测的数量
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
scale_coords是把det[ : , :4](coords(xyxy))从img.shape[2: ]变成im0.shape(这里det[ : , :4]是xyxy的格式吗?)
for c in det[:, -1].unique():
det[ : ,-1]是什么意思,看好像操作之后值都变了,虽然变成Tensor(3,),这里-1的理解是这段代码的关键unique()函数是去掉张量中重复的部分
det[ : ,-1] = tensor([0.,0.,67.])
det[ : ,-1] = tensor([0.,67.])
det[ : ,-1] == c的神奇功能:

for *xyxy, conf, cls in reversed(det):
这里挺奇怪的,*xyxy怎么拿东西出来的,det里面唯一有用的值也就是data里面的Tensor(5,6)了,但是这跟拿出来的*xyxy,没什么关系,det是这样的:
 xyxy=(*xyxy,)拿出来后:(根本没什么关系)
xyxy=(*xyxy,)拿出来后:(根本没什么关系)

new
(1)annotator
im0 = annotator.result()
annotator具体的功能没看,好像是什么注释器
2.1 hyp.scratch.yaml 超参数设置
在data文件夹中的hyp中

上面这些参数默认就好,没什么改动的必要。
lr:学习率,在训练过程中会依次下降,初始学习率在第一行内容中。余弦退火就是为了动态降低学习率。
momentum:动量,一般为0.95左右
weight_decay:权重衰减,防止权重更新幅度过大,过拟合。(这个技术也是一直没时间看)
warmup:热身,让模型先热热身,熟悉熟悉数据,学习率要小,相当于只是去看看,还没正式训练呢,学习率太高说不定就学跑偏了。
2.2 train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return optrect是指要不要做矩形训练,例如448*448给修改成448*w这样一个尺寸,默认是不做。resume是指是否继续上次的训练,这是一个日志文件,在训练后会有一个last.py,是保存的权重文件。
如果只有一个类别,singgle-cls可以改成store-false,默认就是True了。如果是多类别的,这里要写store_true(nargs='?'是什么意思,还有const=True)
最后一个workers,windows系统一定要指定为0,指定其他的会百分百报错。windows和pytorch没有很好地兼容。(这个有待考证)
2.2.1 训练流程
pt文件保存了best和last两种,best是使用了4个指标对模型参数做了评估,得分是:
sum([0.0, 0.0, 0.1, 0.9]*[精确度, 召回率, [email protected], [email protected]:0.95]
所以主要还是根据mAP值。
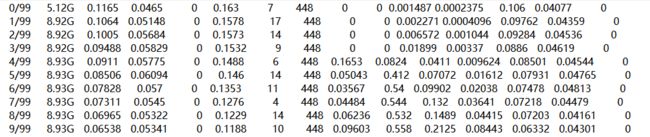
yolov5的日志文件做的非常好 ,在runs文件夹下记录了每一次迭代的结果,进入其中一次查看。

有权重文件,有tensorboard需要的events文件,有记录的超参数。还有标签的分布情况。有记录的精度和召回率情况,还有对其中几个batch的预测结果。在results文件中,记录了各个指标,其中有精度和召回率等。(召回率是什么东西)