Spark sql的简单使用
目录
- 加载依赖
- spark sql简单入门
- Spark sql简单应用
-
- 应用配置
- 读取文件
-
- 读取文本文件并展示数据
- show()将数据完全显示
- 读取json文件
- 读取jdbc文件
- 读取压缩格式的文件
- 将数据以压缩格式存储
-
- parquet或者orc格式存储
- 读取数据注册成视图并写SQL
-
- 直接写sql
- 类sql的模式
- 写出文件到别的路径
- RDD和DF的相互转换
-
- RDD转换成DF
- DF转换成RDD
- DF中函数的使用
-
- where
- filter
- select
- 聚合函数的位置(agg)
- join
- 直接写sql
加载依赖
依赖这个东西,只要注意几个依赖之间的相互关系能够匹配的上就行了,这里需要在idea里面写sql,只需要加上一个spark_sql的依赖就行了
这里的2.11是Scala的版本,如果本地也有Scala,要注意互相之间依赖的关联,如果不太清楚,直接去maven的官网去搜就可了maven官网

spark sql简单入门
sparksql实际上就是把写出来的sql语法加载成RDD,交到集群中去运行;spark sql可以很好的集成hive,在里面也可以写hivesql,spark core中提供的数据结构是RDD,spark sql提供的数据结构是DataFrame,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格;DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表。
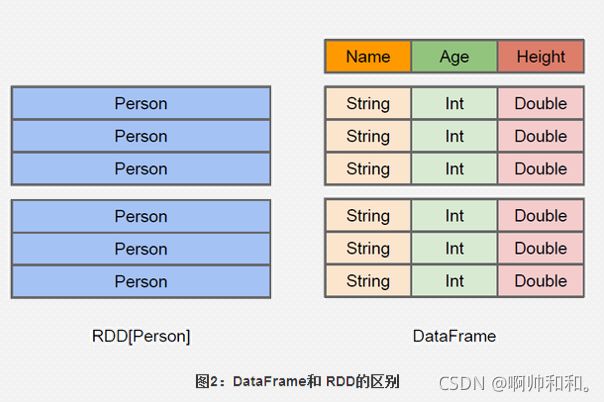
Spark sql简单应用
应用配置
这里的SparkSession是Spark2.0入口,SparkContext是1.0入口
/**
* SparkSession 是Spark2.0的新入口
*/
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("Demo1SparkSession")
//设置spark sql产生shuffle后默认的分区数 => 并行度
// 默认是200,也就是说,这里如果不修改,默认有200个reduce
.config("spark.sql.shuffle.partitions", 3)
.getOrCreate()
读取文件
读取文本文件并展示数据
这里读取的不管是csv文件还是txt文件,默认都是csv读取,不过这里要手动指定列头
展示数据这里用到的是show(),不过默认只显示20条,需要显示多要自己加参数
//不管是txt还是csv格式,这里默认都是以csv读取
spark
.read
//这里要手动指定列名,不然列头是_c0,_c1,_c2这样的格式
.schema("id Int,name String,age Int,gender String,clazz String")
.csv("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt")
.show()
show()将数据完全显示
假如我们这里的数据非常长

不能被显示完全,就需要在show()中加一个参数
show(false)即可

读取json文件
//读取json数据
spark
.read
// .format("json")
// .load("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\一份json数据.json")
.json("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\一份json数据.json")
.show()
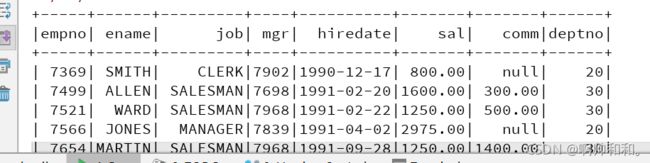
读取jdbc文件
假设我们这里不知道该如何使用,可以从官网中一步步读取




这里面就包含了各个参数的作用,以及示例代码

//jdbc读取MySQL数据
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://master:3306/test1")
.option("dbtable", "emp")
.option("user", "xxxx")
.option("password", "xxxxxx")
.load()
.show()
读取压缩格式的文件
//读取压缩格式的文件
spark
.read
.format("orc")
.load("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\Spark\\data\\parquet")
.show()
将数据以压缩格式存储
parquet或者orc格式存储
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://master:3306/test1")
.option("dbtable", "emp")
.option("user", "xxxx")
.option("password", "xxxxxx")
.load()
.write
.parquet("spark/data/parquet")
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://master:3306/test1")
.option("dbtable", "emp")
.option("user", "xxxx")
.option("password", "xxxxxx")
.load()
.write
.mode(SaveMode.Overwrite)
.orc("spark/data/parquet")
读取数据注册成视图并写SQL
我们可以看到,sparksql可以读取csv、json、jdbc的数据源,并且可以在自身的DatFrame中使用类SQL语言和HiveSQL
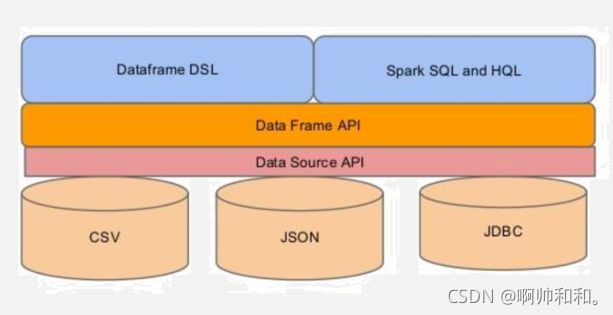
直接写sql
val stuDF: DataFrame = spark
.read
//这里要手动指定列名,不然列头是_c0,_c1,_c2这样的格式
.schema("id Int,name String,age Int,gender String,clazz String")
.csv("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt")
//直接将DataFrame注册成临时视图view
stuDF.createOrReplaceTempView("stu")
spark.sql("select * from stu where age>23").show()

类sql的模式
//类sql的方式,介于sql和代码中间的API
stuDF.where("age > 23")
.select("name","id","clazz")
.show()

写出文件到别的路径
//统计班级人数
//需要写出文件到别的地方,就需要write
stuDF.groupBy("clazz")
.count()
.write
//保存的时候可以指定保存的方式
//Overwrite 覆盖
//Append 追加
.mode(SaveMode.Overwrite)
.save("spark/data/clazz_cnt")
RDD和DF的相互转换
RDD转换成DF
如果是RDD读取文本文件的数据,比如是学生表的数据,有id,name,age这样的字段,建议将学生信息写成一个样例类,再存入RDD,再转换成DF
//这里通过RDD的方式构建DF,推荐使用样例类来做
val sc: SparkContext = spark.sparkContext
val stuRDD: RDD[String] = sc.textFile("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt")
val stuRDDMap: RDD[Student] = stuRDD.map(
stu => {
val strings: Array[String] = stu.split(",")
val id: String = strings(0)
val name: String = strings(1)
val age: String = strings(2)
val gender: String = strings(3)
val clazz: String = strings(4)
Student(id, name, age, gender, clazz)
}
)
//导入隐式转换
import spark.implicits._
val sDF: DataFrame = stuRDDMap.toDF()
sDF.show()
val ssDF: DataFrame = stuRDD.toDF()
ssDF.show(false)
}
case class Student(id: String, name: String, age: String, gender: String, clazz: String)
不进行这样操作的话,读取到的数据会是这样的:
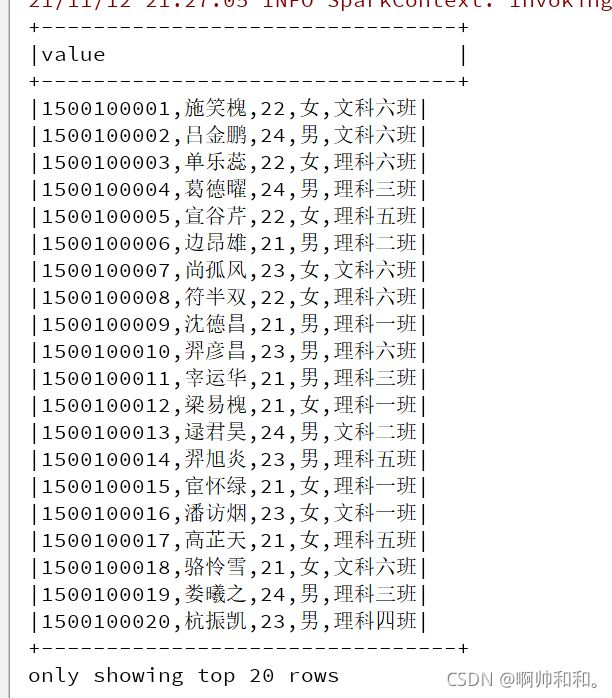
转换成样例类进行读取的话是这样的:这样更方便对数据进行操作

DF转换成RDD
val rdd: RDD[Row] = sDF.rdd
rdd.foreach(
rdd=>{
val id: String = rdd.getAs[String]("id")
val name: String = rdd.getAs[String](1)
println(s"$id,$name")
}
)

rdd.map(rdd=>{
val id: String = rdd.getAs[String]("id")
val name: String = rdd.getAs[String]("name")
(id,name)
}).foreach(println)

DF中函数的使用
导入数据表的时候记得指定字段
val spark: SparkSession = SparkSession
.builder()
.config("spark.sql.shuffle.partitions", 2)
.master("local")
.appName("Demo3DFAPI")
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 导入所有的sql函数
import org.apache.spark.sql.functions._
val stuDF: DataFrame = spark
.read
.schema("id Int,name String,age Int,gender String,clazz String")
.csv("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt")
where
推荐使用列表达式的形式
//字符串表达式
stuDF.where("age > 21").show()
//列表达式
stuDF.where($"age" > 21).show()
filter
//filter函数
stuDF.filter(stu=>{
val id: Int = stu.getAs[Int]("id")
if (id < 1500100007){
true
}
else {
false
}
})
.show()
select
stuDF.select( $"id" ,$"name",$"age" + 100 as "new_age").show()
聚合函数的位置(agg)
这里面在分组之后,要将聚合函数放进agg中才可以使用
//统计每个班不同性别的人数(直接统计人数)
stuDF.groupBy($"clazz",$"gender")
.agg(count($"gender")).show()
stuDF.groupBy($"clazz",$"gender")
.agg(countDistinct($"gender")).show()
join
//join
//默认时inner join 可以指定关联的方式
//关联字段一样时
stuDF.join(scoDF,"id").show()
//关联字段不一样时
stuDF.join(scoDF,$"id"===$"sid","left").show()
直接写sql
//直接写sql
stuDF.createTempView("students")
spark.sql(
"""
|select
| clazz
| ,count(distinct id)
|from students
|group by clazz
""".stripMargin).show()
感谢阅读,我是啊帅和和,一位大数据专业大四学生,祝你快乐。