大数据2--hive--hive介绍
第一章 Hive介绍
1.1hive概述
1.1.1 hive的简介
HIve是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQK查询功能。其本质是将SQL转换为MapReduce/Spark的任务进行运算,底层由HDFS来提供数据的存储,说白了,hive可以理解为一个将SQL转换为MapReduce/spark任务的工具。
1.1.2 HIve的特点:
-
可扩展性: Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
-
延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
-
容错性:良好的容错性,节点出现问题,SQL仍可以完成执行。
1.2 hive架构
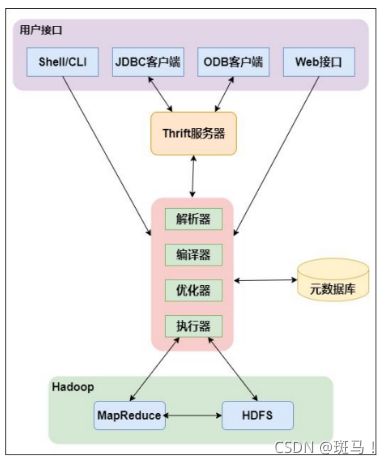
用户接口:包括CLI,JDBC/ODBC,WebGui
元数据存储:通常是存在关系数据块例如mysql/derby中。Hive将元数据存储在数据库中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表),表的数据所在目录等。
解释器,编辑器,优化器,执行器:完成HIve查询语句从词法分析,语法分析,编译,优化以及查询计划的生成,生成的查询计划存储在HDFS中,并在随后被MapReduce调用执行。
1.3 HIve计算引擎
目前Hive支持MapReduce, Tez和Spark三种计算引擎。
1.3.1 MR计算引擎
Map 在读取数据时,先将数据拆分成若干数据,并读取到 Map 方法中被处理。数 据在输出的时候,被分成若干分区并写入内存缓存(buffer)中,内存缓存被数 据填充到一定程度会溢出到磁盘并排序,当 Map 执行完后会将一个机器上输出的 临时文件进行归并存入到 HDFS 中。当 Reduce 启动时,会启动一个线程去读取 Map 输出的数据,并写入到启动 Reduce 机器的内存中,在数据溢出到磁盘时会对数据进行再次排序。当读取数据完成后 会将临时文件进行合并,作为 Reduce 函数的数据源。
1.3.2 Tez计算引擎
Tez是进行大规模数据处理且支持DAG作业的计算框架,它直接源于MapReduce框架,除了能够支持MapReduce特性,还支持新的作业形式,并允许不同类型的作业能够在一个集群中运行。
1.3.3 Spark计算引擎
Spark是专门为大规模数据处理而设计的快速,通用支持DAG(有向无环图)作业的计算引擎,类似于Hadoop MapReduce的通用并行框架,可用来构建大型的,低延迟的数据分析应用程序。
1.4 Hive数据抽样
当数据规模不断膨胀的时候,我们需要找到一个数据的子集来加快数据分析效率。因此我们就需要通过筛选和分析数据集进行模式和趋势识别。目前来说,有三种方式来进行抽样:随机抽样,桶表抽样,块抽样。
1.4.1随机抽样
使用rand()函数进行随机抽样,limit关键字限制抽样返回的数据,其中rand()函数前的distribute和sort关键字可以保证数据在mapper和reducer阶段是随机分布的。
案例1:
select * from table_name
where col = xxx
distribute by rand() sort by rand()
limit num;
案例2:使用order关键字:
select * from table_name
where col = xxx
order by rand()
limit num;
对比:在千万级数据中进行随机抽样,order by方式耗时更长。
1.4.2 块抽样
关键字:tablesample() 函数。
1)tablesample(n percent) 根据hive表数据的大小按照比例抽取数据,并保存到新的hive表中。eg: select * from xxx tablesample(10 percent)
2)tablesample(nM)指定抽样数据的大小,单位为M。
eg:select * from xxx tablesample(20M)
3)tablesample(n rows)指定抽样数据的行数。
eg: select * from xxx tablesample(100 rows)
1.4.3 桶表抽样
关键词:tablesample(bucket x out of y [on colname]).其中x是要抽样的桶编号,桶编号从1开始,colname表示抽样的列,y表示桶的数量。
eg: select * from table tablesample(bucket 1 out of 10 on rand())
1.5 Hive存储压缩
HIve存储格式
1.5.1行式存储和列式存储
Hive支持的存储格式主要有:TextFile(行式存储),SequenceFile(行式存储),ORC(列式存储),Parquet(列式存储)。
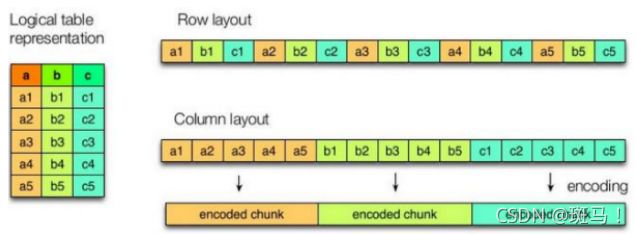
行存储的特点:查询满足条件的一整行数据的时候,列存储需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中其中一个值,其余值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点:因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能够大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的压缩算法。
1.5.2 TextFile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2 使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive 不会对数 据进行切分,从而无法对数据进行并行操作。
1.5.3 ORC格式
Orc(Optimized row Columnar).可以看到每个Orc文件由一个或者多个Strip组成,每个Strip的大小是250MB,这个Strip实际相当于RowGroup概念。每个Strip由三部分组成,分别是Index Data, Row Data, Stripe Footer.
1.5.4 Parquet格式
Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该 文件的数据和元数据,因此 Parquet 格式文件是自解析的。 通常情况下,在存储 Parquet 数据的时候会按照 Block 大小设置行组的大小,由 于一般情况下每一个 Mapper 任务处理数据的最小单位是一个 Block,这样可以 把每一个行组由一个 Mapper 任务处理,增大任务执行并行度
Hive压缩
1.5.5 压缩
1)数据压缩比结论:
ORC > Parquet > textFile
2)存储文件的查询效率比较:
ORC > TextFile > Parquet
3)创建一个Snappy压缩的ORC存储方式:
row format delimited fields terminated by ‘\t’ stored as orc tblproperties(“orc.compress” = “snappy”);
1.6 Hive和数据库的比较
1)查询语言
专门针对Hive设计了类SQL的查询语言HQL。
2)数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多少写多少的。因此Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的,而数据库中的数据通常是需要经常修改的。
3)执行延迟
Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致Hive延迟高的因素是MapReduce框架。由于MapReduce本身具有较高的延迟,因此,在利用MapReduce执行Hive查询的时候,也会有较高的延迟。
4)数据规模
由于Hive建立在集群上并且可以利用MapReduce进行并行计算,因此可以支持很大规模的数据,对应地,数据库可以支持的数据规模较小。