关于深度学习理论和架构的最新综述(part3)
关于深度学习理论和架构的最新综述-part3
- 递归神经网络(RNN)
-
- 介绍
- 长短期记忆(LSTM)
- 门控循环单元(GRU)
- 卷积LSTM(ConvLSTM)
- RNN架构的变体及其应用
- 基于注意力的RNN模型
- RNN申请
- 自动编码器(AE)和限制玻尔兹曼机(RBM)
-
- 回顾自动编码器(AE)
- 变分自动编码器(VAE)
- 裂脑自动编码器
- AE的应用
- 审查RBM
- 生成对抗网络(GAN)
-
- GAN综述
- GAN的应用
-
- 用于图像处理的GAN
- 用于语音和音频处理的GAN
- 用于医疗信息处理的GAN
- 其他应用
- 深度强化学习(DRL)
-
- 对DRL的评论
- Q学习
- DRL的最新趋势及其应用
递归神经网络(RNN)
介绍
人类的思想具有持久性;人类不会抛弃任何东西,并在一秒钟内从头开始思考。当您阅读本文时,您可以基于对先前单词或句子的理解来理解每个单词或句子。传统的神经网络方法,包括DNN和CNN,都无法解决这类问题。由于以下原因,标准神经网络和CNN无能为力。首先,这些方法仅处理固定大小的矢量作为输入(例如,图像或视频帧)并产生固定大小的矢量作为输出(例如,不同类别的概率)。其次,那些模型以固定数量的计算步骤(例如,模型中的层数)操作。 RNN是唯一的,因为它们允许随着时间的推移在一系列向量上进行操作。 Hopfield Newark在1982年引入了这个概念,但这个想法很快就在1974年描述1。图形表示如图28所示。
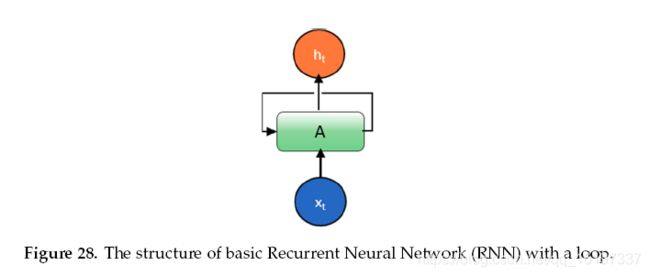
约旦和埃尔曼已经提出了不同版本的RNN 2 ’ 3。 在Elman中,该架构使用隐藏层的输出作为输入以及隐藏层的正常输入4。 另一方面,输出单元的输出用作Jordan网络中隐藏层输入的输入[^130]。 相比之下,Jordan使用输出单元输出的输入和隐藏层的输入。 数学表达为:
Elman network2:
h t = σ h ( w h x t + u t h t − 1 + b t ) y t = σ y ( w h h t + b y ) h_t = \sigma_h(w_h x_t + u_t h_{t-1} + b_t) \\ y_t = \sigma_y(w_h h_t + b_y) ht=σh(whxt+utht−1+bt)yt=σy(whht+by)
Jordan network3:
h t = σ h ( w h x t + u t y t − 1 + b t ) y t = σ y ( w h h t + b y ) h_t = \sigma_h(w_h x_t + u_t y_{t-1} + b_t) \\ y_t = \sigma_y(w_h h_t + b_y) ht=σh(whxt+utyt−1+bt)yt=σy(whht+by)
其中 x t x_t xt是输入向量, h t h_t ht是隐藏层向量, y t y_t yt是输出向量, w w w和 u u u是权重矩阵, b b b是偏置向量。
循环允许信息从网络的一个步骤传递到下一个步骤。 可以将循环神经网络视为同一网络的多个副本,每个网络将消息传递给后继者。 下面的图表显示了如果我们展开循环会发生什么。
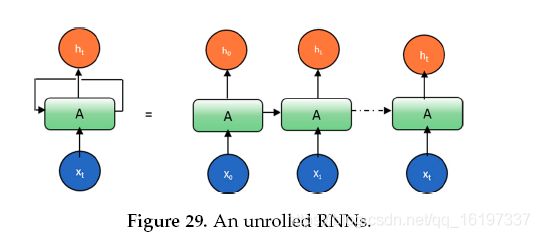
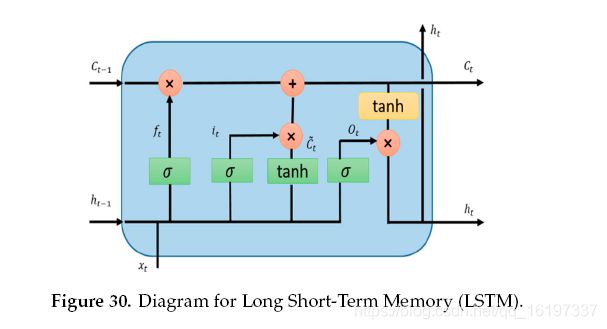
RNN方法的主要问题是存在消失的梯度问题。 这是第一次,Hochreiter等人5解决了这个问题。 在1993年实施并评估了由1000个后续层组成的深度RNN以解决深度学习任务6。 在过去的几十年中,已经提出了几种解决方案来解决RNN方法的消失梯度问题。 这个问题的两种可能有效的解决方案是首先剪切梯度并在规范太大时缩放梯度,其次,创建更好的RNN模型。 Felix A.等人介绍了其中一个更好的模型。 在2000年命名为长期短期记忆(LSTM)7 ’ 8。 从LSTM开始,在过去几年中提出了不同的先进方法,这些方法将在以下章节中进行解释。 LSTM的图表如图30所示。
RNN接近允许输入,输出或最一般情况下的序列。例如,用于文本挖掘的DL,在文本数据上构建深度学习模型需要表示基本文本单元和单词。神经网络结构,可以分层次地捕获文本的顺序性质。在大多数情况下,RNN或递归神经网络用于语言理解9。在语言建模中,它试图根据之前的单词预测下一个单词或一组单词或一些单词句子10。 RNN是具有环路的网络,允许信息持续存在。另一个例子:RNN能够将先前的信息连接到当前任务:使用先前的视频帧,理解现在并尝试生成未来的帧11。
长短期记忆(LSTM)
LSTM的关键思想是单元状态,水平线贯穿图31的顶部.LSTM将信息移除或添加到称为门的单元状态:输入门( i t i_t it),忘记门( f t f_t ft)和输出门( o t o_t ot) )可以定义为:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) C ~ t = t a n h ( ( W C ⋅ [ h C − 1 , x t ] + b C ) C t = f t ∗ C t − 1 + i t ∗ C ~ t O t = σ ( W O ⋅ [ h t − 1 , x t ] + b O ) h t = O t ∗ t a n h ( C t ) f_t = \sigma (W_f \cdot [h_{t-1},x_t] + b_f) \\ i_t = \sigma (W_i \cdot [h_{t-1},x_t] + b_i) \\ \widetilde{C}_t = tan h((W_C \cdot [h_{C-1},x_t] + b_C) \\ C_t = f_t * C_{t-1} +i_t * \widetilde{C}_t \\ O_t = \sigma(W_O \cdot [h_{t-1},x_t] + b_O) \\ h_t = O_t * tan h(C_t) ft=σ(Wf⋅[ht−1,xt]+bf)it=σ(Wi⋅[ht−1,xt]+bi)C t=tanh((WC⋅[hC−1,xt]+bC)Ct=ft∗Ct−1+it∗C tOt=σ(WO⋅[ht−1,xt]+bO)ht=Ot∗tanh(Ct)
LSTM模型在时间信息处理中很受欢迎。 大多数包含LSTM模型的论文都有一些微小的差异。 其中一些将在下一节中讨论。 Gers和Schimidhuber在2000年提出了一种略有修改的网络连接与窥视孔连接7。 窥视孔的概念包含在该模型中的几乎所有门控中。

门控循环单元(GRU)
GRU也来自LSTMs,变异略多12。 GRU现在在社区中很受欢迎,他们正在使用循环网络。 受欢迎的主要原因是模型的计算成本和简单性,如图31所示。在拓扑,计算成本和复杂性方面,GRU是比标准LSTM更轻的RNN方法版本12。 该技术将遗忘和输入门组合成单个更新门,并将单元状态和隐藏状态以及一些其他变化合并。 更简单的GRU模型越来越受欢迎。 数学上GRU可以用以下等式表示:
z t = σ ( W z ⋅ [ h t − 1 , x t ] ) r t = σ ( W r ⋅ [ h t − 1 , x t ] ) h ~ t = t a n h ( W ⋅ [ r t ∗ h t − 1 , x t ] ) h t = ( 1 − z t ) ∗ h t − 1 + z t ∗ h ~ t z_t = \sigma (W_z \cdot [h_{t-1},x_t]) \\ r_t = \sigma (W_r \cdot [h_{t-1},x_t]) \\ \widetilde{h}_t = tan h(W \cdot [r_t * h_{t-1},x_t])\\ h_t = (1-z_t) * h_{t-1} +z_t * \widetilde{h}_t zt=σ(Wz⋅[ht−1,xt])rt=σ(Wr⋅[ht−1,xt])h t=tanh(W⋅[rt∗ht−1,xt])ht=(1−zt)∗ht−1+zt∗h t
问题是哪一个最好?根据不同的实证研究,没有明确的证据表明获胜者。但是,GRU需要较少的网络参数,这使得模型更快。另一方面,如果你有足够的数据和计算能力,LSTM可以提供更好的性能13。有一个名为Deep LSTM的变体LSTM 14。另一种变体是一种有点不同的方法,称为A clockwork RNN 15。对不同版本的RNN方法进行了重要的实证评估,包括Greff等人在2015年16的LSTM和最后的结论是所有的LSTM变体都差不多16。对数千种RNN架构进行了另一项实证评估,包括LSTM,GRU等,在某些任务中发现了一些比LSTM更好的17。
卷积LSTM(ConvLSTM)
完全连接(FC)LSTM和短FC-LSTM模型的问题是处理时空数据及其在输入到状态和状态到状态事务中的完全连接的使用,其中没有编码空间信息。 ConvLSTM的内部门是3D张量,其中最后两个维度是空间维度(行和列)。 ConvLSTM根据输入和其本地邻居的过去状态确定网格中某个单元的未来状态,这可以通过状态到状态或输入到状态转换中的卷积运算来实现,如图32。
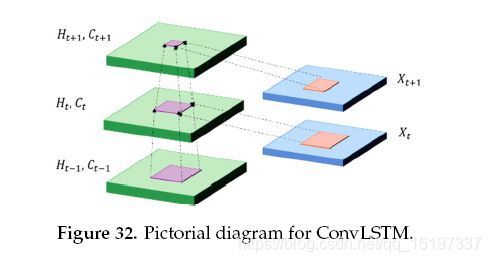
ConvLSTM通过视频数据集为时态数据分析提供了良好的性能11。 数学上ConvLSTM表示如下,其中 ∗ \ast ∗ 表示卷积运算, ∘ \circ ∘ 表示Hadamard积:
i t = σ ( w x i ⋅ X t + w h i ∗ H t − 1 + w h i ∘ C t − 1 + b i ) f t = σ ( w x f ⋅ X t + w h f ∗ H t − 1 + w h f ∘ C t − 1 + b f ) C ~ t = t a n h ( w x C ⋅ X t + w h C ∗ H t − 1 + b C ) C t = f t ∘ C t − 1 + i t ∗ C ~ t o t = σ ( w x o ⋅ X t + w h o ∗ H t − 1 + w h o ∘ C t − + b o ) h t = o t ∘ t a n h ( C t ) i_t = \sigma(w_{xi} \cdot \mathcal X_t + w_{hi} \ast \mathcal H_{t-1} + w_{hi} \circ \mathcal C_{t-1} +b_i) \\ f_t = \sigma(w_{xf} \cdot \mathcal X_t + w_{hf} \ast \mathcal H_{t-1} +w_{hf} \circ \mathcal C_{t-1} +b_f) \\ \widetilde C_t = tan h(w_{xC} \cdot \mathcal X_t + w_{hC} \ast \mathcal H_{t-1} +b_C) \\ C_t = f_t \circ C_{t-1} + i_t \ast \widetilde C_t \\ o_t = \sigma(w_{xo} \cdot \mathcal X_t + w_{ho} \ast \mathcal H_{t-1} +w_{ho} \circ \mathcal C_t- +b_o) \\ h_t = o_t \circ tan h(C_t) it=σ(wxi⋅Xt+whi∗Ht−1+whi∘Ct−1+bi)ft=σ(wxf⋅Xt+whf∗Ht−1+whf∘Ct−1+bf)C t=tanh(wxC⋅Xt+whC∗Ht−1+bC)Ct=ft∘Ct−1+it∗C tot=σ(wxo⋅Xt+who∗Ht−1+who∘Ct−+bo)ht=ot∘tanh(Ct)
RNN架构的变体及其应用
为了将注意机制与RNN结合,Word2Vec在大多数情况下用于单词或句子编码。 Word2vec是一种功能强大的字嵌入技术,具有来自原始文本输入的2层预测NN。这种方法用于不同的应用领域,包括无监督的单词学习,不同单词之间的关系学习,基于相似性抽象单词的更高意义的能力,句子建模,语言理解等等。在过去几年中,已经提出了不同的其他字嵌入方法,用于解决困难的任务并提供最先进的性能,包括机器翻译和语言建模,图像和视频字幕以及时间序列数据分析18 ’ 19 ’ 20。
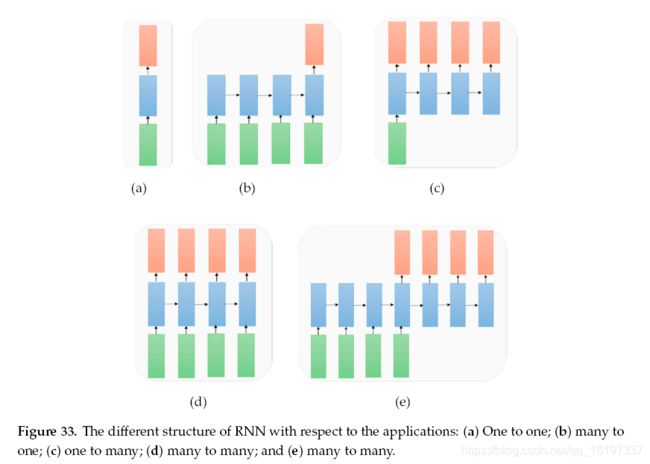
从应用的角度来看,RNN可以解决需要不同RNN架构的不同类型的问题,如图33所示。在图33中,输入向量表示为绿色,RNN状态用蓝色表示,橙色表示输出向量。这些结构可以描述为:
一对一:图33a所示的没有RNN的分类的标准模式(例如,图像分类问题)。
多对一:输入序列和单个输出(例如,情感分析,其中输入是一组句子或单词,输出是正或负表达),如图33b所示。
一对多:系统接受输入并产生一系列输出(图像字幕问题:输入是单个图像,输出是一组带有上下文的字),如图33c所示。
多对多:输入和输出的序列(例如,机器翻译:机器从英语中获取一系列单词并转换为法语单词序列),如图33d所示。
多对多:序列到序列学习(例如,视频分类问题,其中我们将视频帧作为输入并且希望标记图33e所示的视频的每个帧。
基于注意力的RNN模型
已经使用RNN方法提出了不同的基于注意力的模型。 Xu等人提出了自动学习描述图像内容的RNN的第一个倡议。在2015年21。基于双态注意的RNN被提出用于有效时间序列预测22。另一个困难的任务是使用GRU的视觉问答(VQA),其中输入是图像和关于图像的自然语言问题,任务是提供准确的自然语言答案。输出以图像和文本输入为条件。 CNN用于对图像进行编码,并且实现RNN以对句子进行编码23。另一个出色的概念是谷歌发布的Pixel Recurrent Neural Networks(Pixel RNN)。这种方法为图像完成任务提供了最先进的性能24。提出了一种称为残余RNN的新模型,其中RNN在深度循环网络中引入了有效的残余连接25。
RNN申请
RNN(包括LSTM和GRU)应用于Tensor处理26。使用RNN技术的自然语言处理,包括LSTM和GRU 27 ’ 28。基于多语言识别系统的卷积RNN已于2017年提出29。使用RNN的时间序列数据分析30。最近,TimeNet被提出基于预训练的深度RNN用于时间序列分类(TSC)31。语音和音频处理,包括用于大规模声学建模的LSTM 32 ’ 33。使用卷积RNN进行声音事件预测34。使用卷积GRU进行音频标记35。使用RNN 36提出了早期心力衰竭检测。
RNN用于跟踪和监测:数据驱动的交通预测系统是使用图形卷积RNN(GCRNN)37提出的。提出了一种基于LSTM的网络流量预测系统,该系统采用基于神经网络的模型38。双向深度RNN应用于驾驶员动作预测39。使用RNN的车辆轨迹预测40。使用具有词袋的RNN进行动作识别41。使用LSTM进行网络安全的收集异常检测42。
自动编码器(AE)和限制玻尔兹曼机(RBM)
本节将讨论自动编码器43中的一种无监督深度学习方法(例如,变分自动编码器(VAE)44,去噪AE 45,稀疏AE 46,叠加去噪AE 47 ,Split-Brain AE 48)。本章末尾还讨论了不同AE的应用。
回顾自动编码器(AE)
AE是一种深度神经网络方法,用于无监督的特征学习,具有高效的数据编码和解码。自动编码器的主要目的是学习和表示(编码)输入数据,通常用于数据维数降低,压缩,融合等等。这种自动编码器技术由两部分组成:编码器和解码器。在编码阶段,输入样本通常在具有构造特征表示的较低维特征空间中映射。可以重复该方法直到达到期望的特征尺寸空间。而在解码阶段,我们通过反向处理从较低维度特征重新生成实际特征。具有编码和解码阶段的自动编码器的概念图如图34所示。
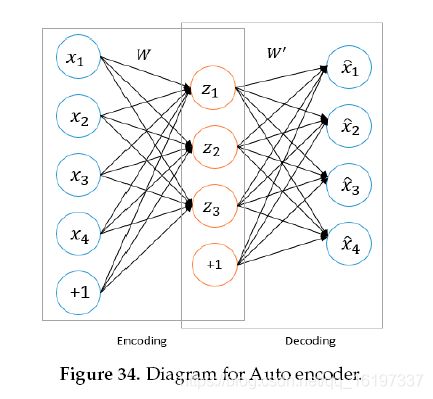
编码器和解码器的转换可用 ∅ \varnothing ∅和 φ \varphi φ表示, ∅ : X → F \varnothing : \mathcal X \rightarrow \mathcal F ∅:X→F 和 φ : F → X \varphi : \mathcal F \rightarrow \mathcal X φ:F→X
∅ , φ = a r g m i n ∅ , φ ∥ X − ( ∅ , φ ) X ∥ 2 \varnothing , \varphi = argmin_{\varnothing , \varphi} \| X-(\varnothing , \varphi)X \| ^2 ∅,φ=argmin∅,φ∥X−(∅,φ)X∥2
如果我们考虑一个带有一个隐藏层的简单自动编码器,其中输入是 x ∈ R d = X x \in \mathbf R^d= \mathcal X x∈Rd=X,它被映射到 ∈ R d = X \in \mathbf R^d= \mathcal X ∈Rd=X,那么它可以表示如下:
z = σ 1 ( W x + b ) z = \sigma_1(Wx+b) z=σ1(Wx+b)
其中 W W W是权重矩阵, b b b是偏差。 σ 1 \sigma_1 σ1表示元素激活函数,例如S形或整流线性单元(RLU)。 让我们考虑将 z z z再次映射或重构到 x ′ x' x′上, x ′ x' x′是 x x x的相同维度。 重建可以表示为
x ′ = σ 2 ( W ′ z + b ′ ) x' = \sigma_2(W'z+b') x′=σ2(W′z+b′)
训练该模型以最小化重建误差,其被定义为如下的损失函数
L ( x , x ′ ) = ∥ x − x ′ ∥ 2 = ∥ x − σ 2 ( W ′ ( σ 1 ( W x + b ) ) + b ′ ) ∥ 2 \mathcal L(x,x') = \| x -x'\| ^2 = \| x-\sigma_2(W'(\sigma_1(Wx+b))+b')\|^2 L(x,x′)=∥x−x′∥2=∥x−σ2(W′(σ1(Wx+b))+b′)∥2
通常, F F F的特征空间具有比输入特征空间 X X X更低的尺寸,其可以被视为输入样本的压缩表示。在多层自动编码器的情况下,在编码和解码阶段将根据需要重复相同的操作。通过使用多个隐藏层扩展编码器和解码器来构造深度自动编码器。对于更深的AE模型,梯度消失问题仍然是一个大问题:梯度变得太小,因为它通过AE模型的许多层返回。以下各节将讨论不同的高级AE模型。
变分自动编码器(VAE)
使用简单的生成对抗网络(GAN)存在一些局限性,这在第7节中讨论。首先,使用GAN从输入噪声生成图像。如果有人想要生成特定图像,则难以随机选择特定特征(噪声)以产生期望的图像。它需要搜索整个发行版。其次,GAN区分“真实”和“虚假”对象。例如,如果你想生成一只狗,那么狗就必须看起来像狗一样。因此,它产生相同风格的图像,风格看起来像狗,但如果我们密切观察那么它并不完全。然而,提出VAE来克服基本GAN的这些限制,其中潜在向量空间用于表示遵循单位高斯分布的图像44 ’ 49。 VAE的概念图如图35所示。

在这个模型中,有两个损失,一个是平均误差,它决定了网络重建图像的效果,以及潜在的损失(Kullback-Leibler(KL)divergence),它决定了潜在的接近程度。 变量匹配是单位高斯分布。 例如,假设 x x x是输入,隐藏表示是 z z z。 参数(权重和偏差)是 θ \theta θ。 为了重建相位,输入是 z z z,期望的输出是 x x x。 参数(权重和偏差)是 ϕ \phi ϕ。 因此,我们可以将编码器分别表示为 q θ ( z ∣ x ) q_{\theta}(z|x) qθ(z∣x)和解码器 p ϕ ( x ∣ z ) p_\phi(x|z) pϕ(x∣z)。 网络和潜在空间的损失函数可表示为
l i ( θ , ϕ ) = − E z ∼ q θ ( z ∣ x i ) [ l o g p ϕ ( x i ∣ z ) + K L ( q θ ( z ∣ x i ) ∣ p ( z ) ) ] l_i(\theta,\phi) = -E_{z \sim q_\theta(z|x_i)}[log p_\phi(x_i|z)+KL(q_\theta(z|x_i)|p(z))] li(θ,ϕ)=−Ez∼qθ(z∣xi)[logpϕ(xi∣z)+KL(qθ(z∣xi)∣p(z))]
裂脑自动编码器
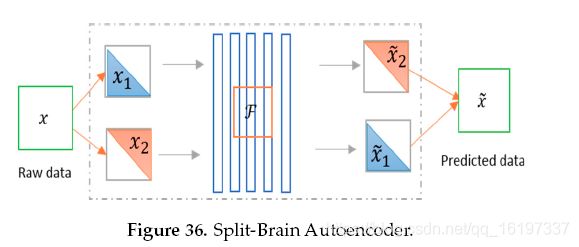
最近,Split-Brain AE由Berkeley AI Research(BAIR)实验室提出,该实验室是用于无监督表示学习的传统自动编码器的架构修改。 在这种架构中,网络被分成不相交的子网,其中两个网络试图预测整个图像的特征表示48。 下图36显示了分裂脑自动编码器的概念。
AE的应用
AE应用于生物信息学[^136] ’ 50和网络安全51。我们可以将AE应用于无监督特征提取,然后应用Winner Take All(WTA)来聚类这些样本以生成标签52。在过去十年中,AE已经被用作编码和解码技术,或者用于其他深度学习方法,包括CNN,DNN,RNN和RL。然而,这里有一些最近发表的其他方法49 ’ 53。
审查RBM
受限制的玻尔兹曼机(RBM)是另一种无监督的深度学习方法。训练阶段可以使用称为受限玻尔兹曼机器的双层网络建模54,其中随机二进制像素使用对称加权连接连接到随机二进制特征检测器。 RBM是一种基于能量的无向生成模型,它使用一层隐藏变量来模拟可见变量的分布。隐藏变量和可见变量之间相互作用的无向模型用于确保似然项对隐含变量的后验的贡献是近似因子的,这极大地促进了推理55。 RBM的概念图如图37所示。

基于nergy的模型意味着通过能量函数定义感兴趣变量的概率分布。 能量函数由一组可观察变量 V = { v i } V = \{v_i \} V={ vi}和一组隐藏变量 = { h i } = \{h_i\} ={ hi}组成,其中i是可见层中的节点,j是隐藏层中的节点。 它在某种意义上受到限制,即没有可见 - 隐藏或隐藏 - 隐藏的连接。 对应于RBM可见单位的值,因为它们的状态被观察到; 特征检测器对应于隐藏单元。 可见和隐藏单元的联合配置 ( v , h ) (v,h) (v,h)具有能量(Hopfield,1982),由下式给出:
E ( v , h ) = − ∑ i a i v i − ∑ j b j h j − ∑ i ∑ j v i w i , j h j E(v,h) = - \sum_i a_i v_i - \sum_j b_j h_j - \sum_i \sum_j v_i w_{i,j} h_j E(v,h)=−i∑aivi−j∑bjhj−i∑j∑viwi,jhj
其中 v i h j v_i h_j vihj是可见单元 i i i和隐藏单元j的二进制状态, a i a_i ai, b j b_j bj是它们的偏差, w i j w_{ij} wij是它们之间的权重。 网络通过此能量函数为可能的可见对和隐藏向量分配概率:
p ( v , h ) = 1 Z e − E ( v , h ) p(v,h) = \frac{1}{Z} e^{-E(v,h)} p(v,h)=Z1e−E(v,h)
其中分区函数 Z Z Z是通过对可见和隐藏向量的所有可能对求和来给出的:
Z = ∑ v , h e − E ( v , h ) Z= \sum_{v,h} e^{-E(v,h)} Z=v,h∑e−E(v,h)
网络分配给可见矢量 v v v的概率是通过对所有可能的隐藏矢量求和来给出的:
p ( v ) = 1 Z ∑ h e − E ( v , h ) p(v) = \frac{1}{Z} \sum_h e^{-E(v,h)} p(v)=Z1h∑e−E(v,h)
通过调整权重和偏差来提高网络分配给训练样本的概率,以降低该样本的能量,并提高其他样本的能量,特别是那些能量较低的样本,因此对分区功能有很大贡献。训练矢量相对于重量的对数概率的导数非常简单。
∂ l o g p ( v ) ∂ w i j = ⟨ v i h i ⟩ d a t a − ⟨ v i h i ⟩ m o d e l ′ \frac{\partial log p(v)}{\partial w_{ij}} = \langle v_i h_i \rangle _{data} -\langle v_i h_i \rangle _{model'} ∂wij∂logp(v)=⟨vihi⟩data−⟨vihi⟩model′
其中尖括号用于表示由下面的下标指定的分布下的期望值。这导致了一个简单的学习规则,用于在训练数据的对数概率中执行随机最速上升:
w i j = ε ( ⟨ v i h i ⟩ d a t a − ⟨ v i h i ⟩ m o d e l ) ′ w_{ij} = \varepsilon( \langle v_i h_i \rangle _{data} -\langle v_i h_i \rangle _{model})_{'} wij=ε(⟨vihi⟩data−⟨vihi⟩model)′
其中 ε \varepsilon ε是学习率。给定随机选择的训练图像 v v v,每个隐藏单元的二进制状态 h j h_j hj, j j j以概率设置为1
p ( h j = 1 ∣ v ) = σ ( b j + ∑ i v i w i j ) p(h_j=1|v) = \sigma(b_j + \sum_i v_i w_{ij}) p(hj=1∣v)=σ(bj+i∑viwij)
其中 σ ( x ) \sigma(x) σ(x)是逻辑sigmoid函数 1 / ( 1 + e − x ) 1/(1+e^{-x}) 1/(1+e−x), v i h j v_i h_j vihj则是无偏样本。因为在RBM中可见单元之间没有直接连接,所以在给定隐藏向量的情况下,也很容易得到可见单元状态的无偏样本
p ( h j = 1 ∣ h ) = σ ( a i + ∑ j h j w i j ) p(h_j=1|h) = \sigma(a_i + \sum_j h_j w_{ij}) p(hj=1∣h)=σ(ai+j∑hjwij)
获得无偏见的 ⟨ v i h i ⟩ m o d e l \langle v_i h_i \rangle _{model} ⟨vihi⟩model样本要困难得多。它可以通过从可见单元的任何随机状态开始并长时间执行交替的吉布斯采样来完成。交替吉布斯采样的单次迭代包括使用等式(55)并行更新所有隐藏单元,然后使用以下等式(56)并行更新所有可见单元。在Hinton(2002)中提出了一种更快的学习过程。这首先将可见单位的状态设置为训练向量。然后使用等式(55)并行计算隐藏单元的二进制状态。一旦为隐藏单元选择了二进制状态,则通过用等式(56)给出的概率将每个 v i v_i vi设置为1来产生重建。然后给出重量的变化
Δ w i j = ε ( ⟨ v i h i ⟩ d a t a − ⟨ v i h i ⟩ r e c o n ) \Delta w_{ij} = \varepsilon (\langle v_i h_i \rangle _{data} - \langle v_i h_i \rangle _{recon}) Δwij=ε(⟨vihi⟩data−⟨vihi⟩recon)
使用单个单位的状态而不是成对产品的相同学习规则的简化版本用于偏见56。该方法主要用于以无监督的方式预训练神经网络以生成初始权重。基于这种方法提出了一种称为深度信念网络(DBN)的最流行的深度学习方法。显示了RBM和DBN用于数据编码,新闻聚类,图像分割和网络安全的应用程序的一些示例,详细信息请参见参考文献57 ’ 58 ’ 59 ’ 60。
生成对抗网络(GAN)
在本章开头,我们从Yann LeCun引用,GAN是过去十年在深度学习(神经网络)领域提出的最佳概念。
GAN综述
机器学习中的生成模型的概念在很长一段时间之前开始用于具有条件概率密度函数的数据建模。通常,这种类型的模型被认为是具有观察和目标(标签)值的联合概率分布的概率模型。然而,我们之前没有看到这种生成模型的巨大成功。最近,基于深度学习的生成模型已经变得流行并且在不同的应用领域中显示出巨大的成功。
深度学习是一种数据驱动技术,随着输入样本数量的增加,其表现更好。由于这个原因,使用来自大量非标签数据集的可重用特征表示进行学习已经成为一个活跃的研究领域。我们在介绍中提到计算机视觉具有不同的任务,分割,分类和检测,这需要大量的标记数据。已经尝试通过生成类似的样本来解决该问题
用生成模型。
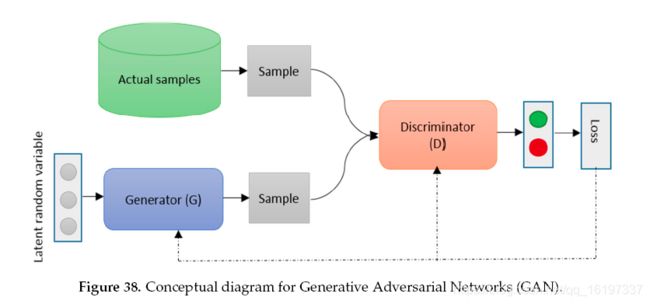
生成性对抗网络(GAN)是Goodfellow最近在2014年发明的深度学习方法.GAN为最大似然估计技术提供了另一种方法。 GAN是一种无监督的深度学习方法,其中两个神经网络在零和游戏中相互竞争。在图像生成问题的情况下,生成器以高斯噪声开始以生成图像,并且鉴别器确定生成的图像有多好。该过程一直持续到发电机的输出变得接近实际输入样本。根据图38,可以认为鉴别器(D)和发生器(G)两个玩家玩 V ( D , G ) V(D,G) V(D,G)函数的最小 - 最大游戏,根据本文可以表达如下[^33] ’ 61 。
min G max D V ( D , G ) = E x ∼ P d a t a ( x ) [ l o g ( D ( x ) ) ] + E z ∼ P d a t a ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D,G) = \mathbf E_{x \sim P_{data}(x)} [log(D(x))]+\mathbf E_{z \sim P_{data}(z)} [log(1-D(G(z)))] GminDmaxV(D,G)=Ex∼Pdata(x)[log(D(x))]+Ez∼Pdata(z)[log(1−D(G(z)))]
在实践中,该等式可能无法在早期阶段为学习G(从随机高斯噪声开始)提供足够的梯度。 在早期阶段,D可以拒绝样本,因为它们与训练样本相比明显不同。 在这种情况下, l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))将饱和。 我们可以训练G来最大化 l o g ( G ( z ) ) log(G(z)) log(G(z))目标函数,而不是训练G以最小化 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z))),该目标函数在学习期间的早期阶段提供更好的梯度。 但是,在第一版训练期间,收敛存在一些局限性。 在开始状态下,GAN对以下问题有一些限制:
- 缺乏启发式成本函数(像素方式近似意味着平方误差(MSE))
- 训练不稳定(有时可能因为产生无意义的输出)
GAN领域的研究一直在进行,提出了许多改进版本62。 GAN能够为应用生成逼真的图像,例如内部或工业设计的可视化,鞋子,包和衣物。 GAN还广泛用于游戏开发和人工视频生成领域63。 GAN有两个不同的DL区域,它们属于半监督和无监督。这些领域的一些研究侧重于GAN架构的拓扑结构,以改进功能和培训方法。深度卷积GAN(DCGAN)是2015年提出的基于卷积的GAN方法64。与无监督的对应物相比,这种半监督方法已经显示出有希望的结果。 DCGAN的再生结果如下图所示22。根据64中的文章,图39显示了在一次训练通过数据集之后生成的卧室图像的输出。本节中包含的大多数数据都是通过实验生成的。从理论上讲,该模型可以学习记住训练样例,但这在实验上不太可能,因为我们用较小的学习率训练和使用SGD进行小批量训练。我们意识到没有先前的经验证据表明对SGD的记忆和较小的学习率64。

图40表示在五个训练时期之后生成的卧室图像。 似乎有证据表明,在多个样本(例如某些床的踢脚板)上通过重复的噪声纹理进行视觉不合适。

在图40中,根据64中的文章,顶行在Z中的一系列九个随机点之间进行插值,并且表明学习空间具有平滑过渡。 在每张图片中,空间似乎都像卧室。 在第6排,你看到一个没有窗户的房间慢慢变成一个有巨大窗户的房间。 在第10行中,您可以看到电视正在慢慢转变为窗口。 下面的图41显示了潜在空间矢量的有效应用。 通过首先执行加法和减法操作,然后进行解码,可以将潜在空间矢量转换为意义输出。 图41根据64中的文章,显示一个男人戴着眼镜减去一个男人并添加一个女人,这导致一个女人戴着眼镜。

根据64中的文章,图42显示了从左侧看向右侧的四个平均样本样本创建的转向量。通过沿着该随机样本轴添加插值,可以可靠地变换姿势。已经为GAN提出了一些有趣的应用程序。例如,利用改进的GAN结构生成自然室内场景。这些GAN学习表面法线,并与Wang和Gupta 65的Style GAN结合使用。在该实现中,作者考虑了名为(S2-GAN)的GAN的样式和结构,其生成表面法线贴图。这是GAN的改进版本。 2016年,提出了一个名为InfoGAN的GAN信息理论扩展。 infoGAN可以完全无人监督的方式学习更好的表示。实验结果表明,无监督的InfoGAN与完全监督学习方法的表征学习相竞争66。
2016年,Im等人67提出了另一种新架构。 其中经常性概念包括在训练期间的对抗性网络中。陈等人 68提出了Info GAN(iGAN),它允许在自然图像流形上交互地进行图像处理。 2017年提出了使用条件对抗网络进行图像到图像的翻译。另一种改进版的GAN命名为耦合生成对抗网络(CoGAN),是多域图像的学习联合分布。现有方法不需要训练集中不同域中相应图像的元组69。双向生成性对抗网络(BiGANs是通过逆特征映射学习的,并且表明所得到的学习特征表示对于辅助监督的鉴别任务是有用的,与当前的非监督和自我监督的特征学习方法相竞争70。

最近,谷歌提出了扩展版本的GAN,称为边界均衡生成对抗网络(BEGAN),具有简单但强大的架构71。 BEGAN拥有更好的训练程序,快速稳定的收敛。均衡的概念有助于平衡鉴别器与发电机的功率。此外,它可以平衡图像多样性和视觉质量之间的权衡71。另一项类似的工作称为Wasserstein GAN(WGAN)算法,与传统的GAN相比显示出显着的优势72。与传统的GAN相比,WGAN有两大优势。首先,WGAN有意义地将损耗度量与发生器的收敛和样本质量相关联。其次,WGAN改善了优化过程的稳定性。
WGAN的改进版本提出了一种新的裁剪技术,它惩罚评论家关于其输入的梯度的法线73。基于生成模型提出了一种有前途的架构,其中图像用未经训练的DNN表示,这为DNN提供了更好理解和可视化的机会74。还引入了生成模型的对抗性实例75。基于能源的GAN由Yann LeCun在2016年从Facebook提出76。对于GAN而言,训练过程很困难,Manifold Matching GAN(MMGAN)提出了更好的训练过程,该过程在三个不同的数据集上进行了实验,实验结果清楚地证明了MMGAN对其他模型的功效77。用于地理统计模拟和反演的GAN采用有效的训练方法78。
概率GAN(PGAN)是一种具有修正目标函数的新型GAN。这种方法背后的主要思想是将概率模型(高斯混合模型)整合到支持似然而不是分类的GAN框架中79。具有贝叶斯网络模型的GAN 80。变分自动编码是一种流行的深度学习方法,它采用对抗变分贝叶斯(AVB)训练,有助于建立VAE和GAN之间的主要联系81。基于通用前馈神经网络82提出的f-GAN。基于马尔可夫模型的GAN用于纹理合成83。另一种基于双随机MCMC方法的生成模型84。具有多发生器的GAN 85是一种无监督的GAN,能够学习像素级域适应,在像素空间中从一个域转换到另一个域吗?这种方法针对几种无监督的域自适应技术提供了最先进的性能,并且具有较大的余量86。提出了一种名为Schema Network的新网络,它是一种面向对象的生成物理模拟器,能够通过各种原因解开事件推理的多种原因,从而实现从数据环境动态中学习的目标87。有一项有趣的研究是用GAN进行的,即生成对抗文本到图像合成。在本文中,为GAN公式提出了新的深度架构,可以对图像进行文本描述,并根据输入产生逼真的图像。这是使用字符级文本编码器和类条件GAN进行基于文本的图像合成的有效技术。在鸟类和花卉数据集上首先评估GAN,然后在MS COCO数据集[^40]上评估图像的一般文本。
GAN的应用
此学习算法已应用于以下各节中讨论的不同应用程序域:
用于图像处理的GAN
GAN用于使用超分辨率方法生成照片般逼真的图像88。 GAN用于半隐式和弱监督方法的语义分割89。文本条件辅助分类器GAN(TAC-GAN),用于从文本描述生成或合成图像90。多样式的生成网络(MSG-Net),它以快速的速度保留基于优化的方法的功能。该网络匹配多个尺度的图像样式,并将计算负担放入训练中91。大多数时候,视觉系统都会遇到雨,雪和雾。最近使用GAN提出了单个图像去除系统92。
用于语音和音频处理的GAN
使用生成分层神经网络模型的端到端对话系统93。此外,GAN已经用于语音分析领域。最近,GAN用于语音增强,称为SEGAN,它结合了进一步的以语音为中心的设计,以逐步提高性能94。 GAN用于符号域和音乐生成,与Melody RNN相当95。
用于医疗信息处理的GAN
用于医学想象和医学信息处理的GAN [^136],用于使用Wasserstein距离和感知损失进行医学图像去噪的GAN 96。 GAN还可以用于条件性GAN(cGAN)的脑肿瘤分割97。使用称为Segan 98的GAN提出了一般的医学图像分割方法。在深度学习革命之前,压缩传感是最热门的话题之一。然而,Deep GAN用于自动化MRI的压缩感知99。此外,由于隐私问题,电子健康记录(EHR)仅限于或不像其他数据集一样公开可用,因此GAN也可用于健康记录处理。 GAN应用于合成EHR数据,可以降低风险100。使用Recurrent GAN(RGAN)和Recurrent Conditional GAN(RCGAN)生成时间序列数据101。 LOGAN包括用于检测过度拟合和识别输入的生成和判别模型的组合。该技术已经与最先进的GAN技术进行了比较,包括GAN,DCGAN,BEGAN以及DCGAN与VAE的组合102。
其他应用
一种称为贝叶斯条件GAN(BC-GAN)的新方法,可以从确定性输入生成样本。这只是一个带有贝叶斯框架的GAN,可以处理有监督的,半监督的和无监督的学习问题103 ’ 104。在机器学习和深度学习社区中,在线学习是一种重要的方法。 GAN用于在线学习,其中它被训练用于在零和游戏中找到混合策略,其被命名为Checkov GAN 1 105。基于统计假设检验的生成矩匹配网络称为最大均值差异(MMD)106。用基于双样本的内核MMD替换GAN的鉴别器的一个有趣的想法是MMD-GAN。这种方法明显优于生成矩匹配网络(GMMN)技术,这是生成模型的另一种方法107。
GAN的一些其他应用包括姿势估计108,照片编辑网络109和异常检测110。 DiscoGAN用于学习与GAN的跨域关系[^40],无监督的图像到图像的转换与生成模型111,单一镜头学习与GAN 112,响应生成和问答系统113 ’ 114。最后但并非最不重要的是,WaveNet作为一种生成模型已被开发用于在115和116中的双路径网络中生成音频波形。
深度强化学习(DRL)
在前面的章节中,我们主要关注有监督和无监督的深度学习方法,包括DNN,CNN,RNN,包括LSTM和GRU,AE,RBM,GAN等。这些类型的深度学习方法用于预测,分类,编码,解码,数据生成和更多应用程序域。然而,本节基于最近开发的RL领域的方法,展示了深度强化学习(DRL)的调查。
对DRL的评论
DRL是一种学习方法,学习从未知的真实环境中以一般意义行事(有关详细信息,请阅读以下文章[^46] ’ 117)。 DRL方法的概念图如图43所示.RL可以应用于不同的领域,包括用于决策的基础科学,从计算机科学的角度来看的机器学习,在工程和数学领域,最优控制,机器人控制,电站控制,风力涡轮机和神经科学奖励策略在过去的几十年中得到了广泛的研究。它也适用于经济效用或博弈论,以便做出更好的决策和投资选择。经典条件反射的心理学概念是动物学习的方式。强化学习是一种技术,用于做什么以及如何将情境与行动相匹配。强化学习不同于最近的监督学习技术和其他类型的学习方法研究,包括传统的机器学习,统计模式识别和ANN。

与一般的监督和无监督机器学习不同,RL的定义不是通过表征学习方法,而是通过表征学习问题。然而,最近DL的成功对DRL的成功产生了巨大的影响,DRL被称为DRL。根据学习策略,通过观察学习RL技术。为了观察环境,有希望的DL技术包括CNN,RNN,LSTM和GRU,这取决于观察空间。因此,当DL技术有效地编码数据时,更准确地执行以下步骤。根据行动,代理人分别获得适当的奖励。因此,整个RL方法在环境中以更好的性能学习和交互变得更有效。
然而,现代DRL革命的历史始于2013年的谷歌深度思维与使用DRL的Atari游戏。其中基于DRL的方法在几乎所有游戏中对人类专家的表现都更好。在这种情况下,在使用CNN处理的视频帧上观察环境118 ’ 119。 DRL方法的成功取决于尝试解决任务的难度。在Google深度思维的Alpha-Go和Atari取得巨大成功之后,他们提出了一个基于2017年星际争霸II的强化学习环境,称为SC2LE(星际争霸II学习环境)120。 SC2LE是一款具有多个玩家互动的多智能体游戏。该提议的方法具有大的动作空间,涉及数百个单元的选择和控制。它包含许多要从原始特征空间观察的状态,它使用数千个步骤的策略。基于Python的开源StarCraft II游戏引擎已在线免费提供。
Q学习
对于使用DRL而言,有一些基本策略是必不可少的。首先,RL学习方法具有计算状态 - 动作组合的质量的功能,其被称为Q学习(Q-功能)。算法2描述了Q学习的基本计算流程。
Q学习被定义为无模型强化学习方法,用于为任何给定(有限)马尔可夫决策过程(MDP)找到最优动作选择策略。 MDP是使用状态,动作和奖励进行建模决策的数学框架。 Q-learning只需要了解可用状态以及每个州可能采取的措施。 Q-Learning的另一个改进版本称为双向Q-Learning。在本文中,讨论了Q-Learning,有关双向Q-Learning的详细信息,请参阅参考文献121。
在每个步骤s,选择最大化以下函数的动作 Q ( s , a ) Q(s,a) Q(s,a)
- ( Q ) (Q) (Q)是估计的效用函数 - 它告诉我们在某个状态下给出的动作有多好
- r ( s , a ) r(s,a) r(s,a)为结果状态制作动作最佳效用 ( Q ) (Q) (Q)的直接奖励这可以使用递归定义表达如下:
Q ( s , a ) = r ( s , a ) + γ max a ′ ( Q ( s ′ , a ′ ) ) Q(s,a) = r(s,a) + \gamma \max_{a'} (Q(s',a')) Q(s,a)=r(s,a)+γa′max(Q(s′,a′))
这个方程称为Bellman方程,它是RL的核心方程。这里 r ( s , a ) r(s,a) r(s,a)是立即奖励, γ \gamma γ是延迟与立即奖励的相对值 [ 0 , 1 ] s ′ [0,1] s' [0,1]s′是行动 a a a之后的新状态。 a a a和 a ′ a' a′分别是sate s s s和 s ′ s' s′中的动作。根据以下等式选择操作:
π ( s ) = a r g m a x a Q ( s , a ) \pi(s) = argmax_a Q(s,a) π(s)=argmaxaQ(s,a)
在每个状态中,分配一个称为Q值的值。当我们访问一个州并且我们相应地收到奖励。我们使用奖励来更新该州的估计值。由于奖励是随机的,因此我们需要多次访问这些州。此外,我们无法保证在另一集中获得相同的奖励( R t R_t Rt)。情节任务和环境中未来奖励的总和是不可预测的,未来,我们会进一步表达各种奖励,
G t = R t + 1 + R t + 2 + R t + 3 + ⋯ ⋯ ⋯ + R T G_t = R_{t+1} + R_{t+2} + R_{t+3} + \cdots \cdots \cdots +R_T Gt=Rt+1+Rt+2+Rt+3+⋯⋯⋯+RT
两种情况下的贴现未来奖励总和都是标量因素。[这个公式得注意,有问题]
G t = γ R t + 1 + γ 2 R t + 2 + γ 3 R t + 3 + ⋯ ⋯ ⋯ + γ T R T G_t = \gamma R_{t+1} + \gamma^2 R_{t+2} + \gamma^3 R_{t+3} + \cdots \cdots \cdots + \gamma^T R_T Gt=γRt+1+γ2Rt+2+γ3Rt+3+⋯⋯⋯+γTRT
这里γ是一个常数。我们在未来越多,我们就越少考虑到奖励。
Q学习的属性:
- Q函数的收敛:近似将收敛到真正的Q函数,但它必须无限次访问可能的状态 - 动作对。
- 状态表大小可根据观察空间和复杂程度而变化。
- 观察期间不考虑看不见的值。
解决这些问题的方法是使用神经网络(特别是DNN)作为近似而不是状态表。 DNN的输入是状态和动作,输出是0到1之间的数字,表示正确编码状态和动作的效用。在这里,深度学习方法有助于在国家信息方面做出更好的决策。在观察环境的大多数情况下,我们使用几个采集设备,包括摄像头或其他传感设备来观察学习环境。例如,如果您观察到Alpha-Go挑战的设置,则可以看出环境,动作和奖励是基于像素值(行动中的像素)学习的。有关详细信息,请参阅参考文献118 ’ 119 ’ 122。
然而,难以开发能够在任何观察环境中相互作用或表现良好的试剂。因此,该领域的大多数研究人员在培训该环境的代理之前选择他们的行动空间或环境。在这种情况下,与有监督或无监督的深度学习方法相比,基准概念略有不同。由于环境的多样性,基准测试取决于环境与先前或现有研究相比的难易程度?困难取决于不同的参数,代理商的数量,代理商之间的互动方式,参与者的数量等。
最近,DRL提出了另一种良好的学习方法[^46] ’ 117。有许多论文发表在不同的DRL网络上,包括深度Q网络(DQN),双DQN,异步方法,政策优化策略(包括确定性政策梯度,深度确定性政策梯度,指导性政策搜索,信任区域政策优化,组合提出了政策梯度和Q学习[^46] ’ 117。政策梯度(DAGGER)超人GO使用监督学习与政策梯度和蒙特卡罗树搜索与价值函数[^46] ’ 123。使用引导式策略搜索进行机器人操作124。使用政策梯度的3D游戏的DRL 125。

DRL的最新趋势及其应用
最近发布了一项调查,其中提出了基本的RL,DRL DQN,信任区域政策优化和异步优势行为者评论。本文还讨论了深度学习的优势,并着重于通过RL的视觉理解和当前的研究趋势126。基于在线RL技术约束的网络内聚被提议用于称为mHealth的移动设备上的医疗保健。该系统帮助类似用户有效地共享信息,以改进有限的用户信息并将其转换为更好学习的策略127。对于用于个性化mHealth干预的移动设备上的医疗保健,提出了与群组驱动的RL类似的工作。在这项工作中,K-means聚类应用于对人进行分组,最后与每个组的RL策略共享128。对于代理商来说,最优政策学习是一项具有挑战性的任务。选项 - 观察启动集(OOI)允许代理在POMDP的挑战性任务中学习最优策略,这些策略比RNN学得更快129。 DRL提出了3D Bin Packing Problem(BPP)。主要目的是放置可以最小化箱子表面积的长方体形状物品的数量130。
DRL的进口部分是根据观察和代理人的行动确定的奖励。现实世界的奖励功能在任何时候都不完美。由于传感器错误,代理可能获得最大奖励,而实际奖励应该更小。本文提出了一种基于广义马尔可夫决策问题(MDP)的公式,称为Corrupt Reward MDP 131。基于最近开发的Kronecker因式近似曲率(K-FAC)132,提出了基于深度RL的信赖域优化。此外,还有一些研究是在使用深度学习方法评估物理实验时进行的。该实验聚焦于代理来学习基本属性,例如交互式仿真环境中对象的质量和内聚133。
最近提出了适用于连续状态和动作空间的模糊RL策略134。对连续控制的政策梯度中的超参数进行了重要的调查和讨论,算法的一般方差。本文还提供了报告结果和与基线方法进行比较的指南135。 Deep RL也适用于高精度装配任务136。 Bellman方程是RL技术的主要功能之一,提出了一种函数逼近,确保Bellman最优性方程始终成立。然后估计函数以最大化观察到的运动的可能性137。基于DRL的分层系统用于可计算系统中的资源分配和功率管理138。提出了一种新颖的注意意识面部幻觉(Attention-FC),其中Deep RL用于增强单个补丁上图像的质量。
适用于脸部图像139。
163 ↩︎
164 ↩︎ ↩︎
165 ↩︎ ↩︎
129 ↩︎
166 ↩︎
167 ↩︎
168 ↩︎ ↩︎
169 ↩︎
170 ↩︎
171 ↩︎
172 ↩︎ ↩︎
173 ↩︎ ↩︎
174 ↩︎
175 ↩︎
176 ↩︎
177 ↩︎ ↩︎
178 ↩︎
179 ↩︎
180 ↩︎
181 ↩︎
182 ↩︎
183 ↩︎ ↩︎
184 ↩︎
185 ↩︎
186 ↩︎
187 ↩︎
188 ↩︎
189 ↩︎
190 ↩︎
191 ↩︎
192 ↩︎
193 ↩︎
194 ↩︎
195 ↩︎
196 ↩︎
197 ↩︎
25 ↩︎
198 ↩︎
199 ↩︎
200 ↩︎
201 ↩︎
202 ↩︎
61 ↩︎
203 ↩︎ ↩︎
65 ↩︎
204 ↩︎
205 ↩︎
206 ↩︎ ↩︎
207 ↩︎ ↩︎
208 ↩︎
209 ↩︎
210 ↩︎
211 ↩︎
212 ↩︎
213 ↩︎
214 ↩︎
57 ↩︎
215 ↩︎
216 ↩︎
217 ↩︎
218 ↩︎
219 ↩︎
220 ↩︎
221 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
222 ↩︎
223 ↩︎
224 ↩︎
225 ↩︎
226 ↩︎
227 ↩︎
228 ↩︎ ↩︎
229 ↩︎
230 ↩︎
231 ↩︎
232 ↩︎
233 ↩︎
234 ↩︎
235 ↩︎
236 ↩︎
237 ↩︎
238 ↩︎
239 ↩︎
240 ↩︎
241 ↩︎
242 ↩︎
243 ↩︎
244 ↩︎
245 ↩︎
246 ↩︎
247 ↩︎
248 ↩︎
249 ↩︎
250 ↩︎
251 ↩︎
252 ↩︎
253 ↩︎
254 ↩︎
255 ↩︎
256 ↩︎
257 ↩︎
258 ↩︎
259 ↩︎
260 ↩︎
261 ↩︎
262 ↩︎
263 ↩︎
264 ↩︎
265 ↩︎
266 ↩︎
267 ↩︎
268 ↩︎
269 ↩︎
270 ↩︎
271 ↩︎
272 ↩︎
273 ↩︎
274 ↩︎ ↩︎ ↩︎
275 ↩︎ ↩︎
276 ↩︎ ↩︎
277 ↩︎
278 ↩︎
279 ↩︎
280 ↩︎
281 ↩︎
282 ↩︎
283 ↩︎
284 ↩︎
285 ↩︎
286 ↩︎
287 ↩︎
288 ↩︎
289 ↩︎
290 ↩︎
291 ↩︎
292 ↩︎
293 ↩︎
294 ↩︎
295 ↩︎
296 ↩︎