Day71_Spark-streaming(一)
SparkStreaming基础架构
| 课程大纲 |
课程内容 |
学习效果 |
掌握目标 |
| SparkStreaming简介 |
流式计算 |
了解 |
|
| SparkStreaming简介 |
|||
| SparkStreaming API |
整合Kafka |
掌握 |
|
| 整合HDFS |
掌握 |
||
| 常见算子操作 |
掌握 |
||
| SparkStreaming优化 |
优化 |
掌握 |
一、流式计算简介
(二)什么是SparkStreaming

Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。

和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)。

DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
(二)为什么要学习Spark Streaming
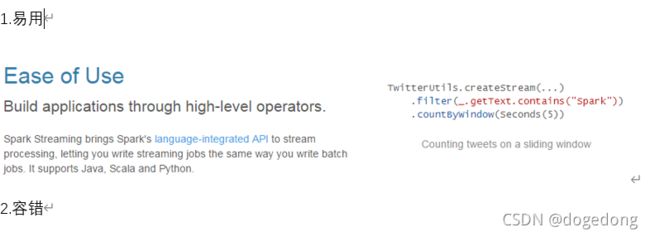

(三)流式计算
如何去理解流式计算,最形象的例子,就是小明往水池中放(入)水又放(出)水的案例。流式计算就像水流一样,数据连绵不断的产生,并被快速处理,所以流式计算拥有如下一些特点:
- 数据是无界的(unbounded)
- 数据是动态的
- 计算速度是非常快的
- 计算不止一次
- 计算不能终止
反过来看看一下离线计算有哪些特点:
- 数据是有界的(Bounded)
- 数据静态的
- 计算速度通常较慢
- 计算只执行一次
- 计算终会终止
在大数据计算领域中,通常所说的流式计算分为了实时计算和准实时计算。所谓时实计算就是来一条记录(一个事件Event)启动一次计算;而准实时计算则是介于实时计算和离线计算之间的一个计算,所以每次处理的是一个微小的批次。
(四)常见的离线和流式计算框架
常见的离线计算框架
- mapreduce
- spark-core
- flink-dataset
常见的流式计算框架
- storm(jstorm)
第一代的流式处理框架,每生成一条记录,提交一次作业。实时流处理,延迟低。
- spark-streaming
第二代的流式处理框架,短时间内生成mirco-batch,提交一次作业。准实时,延迟略高,秒级或者亚秒级延迟。
- flink-datastream(blink)
第三代的流式处理框架,每生成一条记录,提交一次作业。实时,延迟低。
(五)SparkStreaming简介
SparkStreaming,和SparkSQL一样,也是Spark生态栈中非常重要的一个模块,主要是用来进行流式计算的框架。流式计算框架,从计算的延迟上面,又可以分为纯实时流式计算和准实时流式计算,SparkStreaming是属于的准实时计算框架。
所谓纯实时的计算,指的是来一条记录(event事件),启动一次计算的作业;离线计算,指的是每次计算一个非常大的一批(比如几百G,好几个T)数据;准实时呢,介于纯实时和离线计算之间的一种计算方式。显然不是每一条记录就计算一次,显然比起离线计算数据量小的多,怎么表示?Micro-batch(微小的批次)。
SparkStreaming是SparkCore的api的一种扩展,使用DStream(discretized stream or DStream)作为数据模型,基于内存处理连续的数据流,本质上还是RDD的基于内存的计算。
DStream,本质上是RDD的序列。
(六)SparkStreaming基本工作原理
接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume、ZMQ和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。
DStream的内部,其实就是一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,弹性分布式数据集。DStream中的每个RDD都包含了一个时间段内的数据,如下图1-2所示。

对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作。
还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API,其计算过程如下图1-3所示。

(七)Storm V.S. SparkStreaming V.S. Flink
1、三者对比
对比过程如下图1-4所示。

2、storm和flink简介
(1)storm: storm.apache.org

(2)flink: flink.apache.org

(八)如何选择一款合适的流式处理框架
对于Storm来说:
- 建议在需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时计算系统,要求纯实时进行交易和分析时。
- 在实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm,但是Spark Streaming也可以保证数据的不丢失。
- 如果我们需要考虑针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),我们也可以考虑用Storm
对于Spark Streaming来说:
- 不满足上述3点要求的话,我们可以考虑使用Spark Streaming来进行实时计算。
- 考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询、图计算和MLIB机器学习等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
对于Flink来说:
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持Batch on Streaming处理和Streaming处理
- Flink在JVM内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
二、SparkStreaming实时处理入门案例
(一)编码
1、入口类StreamingContext
SparkStreaming中的入口类,称之为StreamingContext,但是底层还是得需要依赖SparkContext。
object SparkStreamingWordCountOps {
def main(args: Array[String]): Unit = {
/*
StreamingContext的初始化,需要至少两个参数,SparkConf和BatchDuration
SparkConf不用多说
batchDuration:提交两次作业之间的时间间隔,每次会提交一个DStream,将数据转化batch--->RDD
所以说:sparkStreaming的计算,就是每隔多长时间计算一次数据
*/
val conf = new SparkConf()
.setAppName("SparkStreamingWordCount")
.setMaster("local[*]")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
//业务
//为了执行的流式计算,必须要调用start来启动
ssc.start()
//为了不至于start启动程序结束,必须要调用awaitTermination方法等待程序业务完成之后调用stop方法结束程序,或者异常
ssc.awaitTermination()
}
}
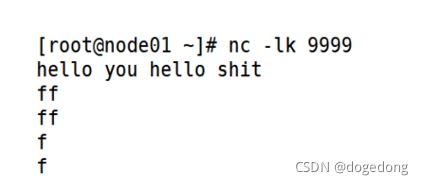
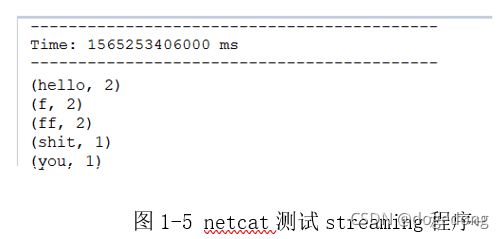
3.使用netcat进行测试
在终端通过netcat来模拟网络数据,运行streaming程序,然后观察控制台输出,如下图1-5所示。下载Netcat发送数据:yum install -y nc
按照Spark Core中的方式进行打包,并将程序上传到Spark机器上。并运行:
bin/spark-submit --master spark://node01:7077 --class WorldCount /root/SparkDay01-1.0-SNAPSHOT.jar (二)StreamingContext和Receiver
1、StreamingContext
StreamingContext是程序的入口类,用于创建DStream,维护SparkStreaming程序的生命周期。
关于local说明
当我们将上述程序中的master由local[*],修改为local的时候,程序业务不变,发生只能接收数据,无法处理数据,如下图1-6所示。

local[*]和local的区别,后者只为当前程序提供一个线程来处理,前者提供可用的所有的cpu的core来处理,当前情况下为2或者4。
所以我们推测,当前程序无法处理数据的原因,只能是拥有cpu-core或者线程个数造成的。
同时还可以推导出来的是,SparkStreaming在当下案例中,优先使用线程资源来接收数据,其次才是对数据的处理,接收数据的对象就是Receiver。
所以,以后注意,如果读取数据的时候有receiver,程序的线程个数至少为2。
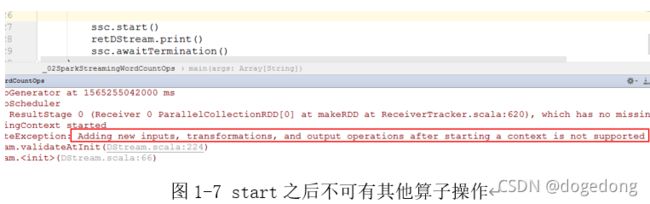
Start
start方法是用来启动当前sparkStreaming应用的,所以,是不能在ssc.start()之后再添加任何业务逻辑,否则,凉凉,如下图1-7所示!
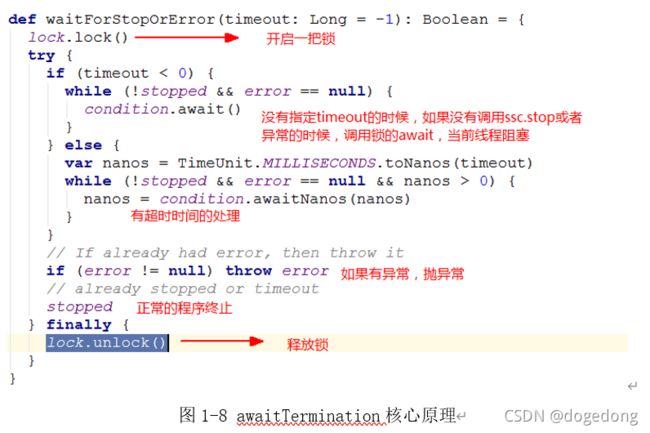
awaitTermination
要想持续不断的执行streaming计算,就必须要调用awaitTermination方法,以便driver能够在后台常驻,其核心原理如下图1-8所示。
2、Receiver
Receiver,顾名思义,就是数据的接收者,这里把资源分成了两部分,一部分用来接收数据,一部分用来处理数据。Receiver接收到的数据,说白了就是一个个的batch数据,是RDD,存储在Executor内存。Receiver就是Executor内存中的一部分。
不是所有的streaming作业都需要有Receiver。
通过下图1-9,来阐述基于Receiver的程序执行的流程。

三、SparkStreaming编程
(一)、SparkStreaming整合HDFS
1、说明
SparkStreaming监听hdfs的某一个目录,目录下的新增文件,做实时处理。这种方式在特定情况下还是挺多的。需要使用的api为:ssc.fileStream()。
监听的文件,必须要从另一个相匹配的目录移动到其它目录。
监听本地
无法读取手动拷贝,或者剪切到指定目录下的文件,只能读取通过流写入的文件。
监听hdfs
有的操作系统和监听本地是一样。
正常情况下,我们可以读取到通过put上传的文件,还可以读取通过cp拷贝的文件,但是读取不了mv移动的文件。
读取文件的这种方式,没有额外的Receiver消耗线程资源,所以可以指定master为local
2、基本编程
object SparkStreamingHDFS {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("SparkStreamingHDFS")
.setMaster("local")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
//读取local中数据 --->需要通过流的方式写入
// val lines = ssc.textFileStream("file:///E:/data/monitored")
//hdfs
val lines = ssc.textFileStream("hdfs://node01:9000/data/spark")
lines.print()
ssc.start()
ssc.awaitTermination()
}
}(二)、SparkStreaming整合Kafka
1、整合简述
kafka是做消息的缓存,数据和业务隔离操作的消息队列,而sparkstreaming是一款准实时流式计算框架,所以二者的整合,是大势所趋。
二者的整合,有主要的两大版本,如下图1-10所示。

在spark-stremaing-kafka-0-8的版本中又分为了两种方式:receiver的方式和direct的方式来读取kafka中的数据,主要区别就是是否依赖zookeeper来管理offset信息,以及是否拥有receiver。
但需要说明的0.8的版本自spark2.3之后便进入不维护阶段,此时建议大家使用0.10的版本,在此讲义中我们就是0.10的版本来进行讲述二者的整合。
Spark对于Kafka的连接主要有两种方式,一种是Direct方式直连模式,另外一种是Receiver方式接收器模式。Direct方式只在 driver 端接收数据,所以继承了 InputDStream,是没有 receivers 的。
主要通过KafkaUtils#createDirectStream以及KafkaUtils#createStream这两个 API 来创建,除了要传入的参数不同外,接收 kafka 数据的节点、拉取数据的时机也完全不同。
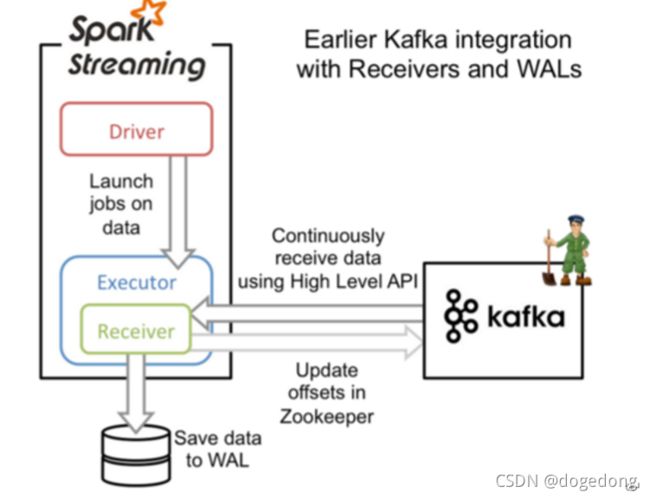
(2)Receiver方式
Receiver:接收器模式是使用Kafka高级Consumer API实现的。与所有接收器一样,从Kafka通过Receiver接收的数据存储在Spark Executor的内存中,然后由Spark Streaming启动的job来处理数据。然而默认配置下,这种方式可能会因为底层的失败而丢失数据(请参阅接收器可靠性)。如果要启用高可靠机制,确保零数据丢失,要启用Spark Streaming的预写日志机制(Write Ahead Log,(已引入)在Spark 1.2)。该机制会同步地将接收到的Kafka数据保存到分布式文件系统(比如HDFS)上的预写日志中,以便底层节点在发生故障时也可以使用预写日志中的数据进行恢复。
单点读数据,读到的数据会缓存到executor的cache里,增大了内存使用的压力。
在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。
特点
在spark的executor中,启动一个接收器,专门用于读取kafka的数据,然后存入到内存中,供sparkStreaming消费
1、为了保证数据0丢失,WAL,数据会保存2份,有冗余
2、Receiver是单点读数据,如果挂掉,程序不能运行
3、数据读到executor内存中,增大了内存使用的压力,如果消费不及时,会造成数据积压
如下图:
对于使用Maven项目定义的Scala / Java应用程序时,我们需要添加相应的依赖包:
org.apache.spark
spark-streaming-kafka_2.11
1.6.3
在流应用程序代码中,导入KafkaUtils并创建输入DStream,如下所示。
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
(3)Direct方式
Direct:直连模式,在spark1.3之后,引入了Direct方式。不同于Receiver的方式,Direct方式没有receiver这一层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,并且相应的定义要在每个batch中处理偏移范围,当启动处理数据的作业时,kafka的简单的消费者api用于从kafka读取定义的偏移范围 。其形式如下图:
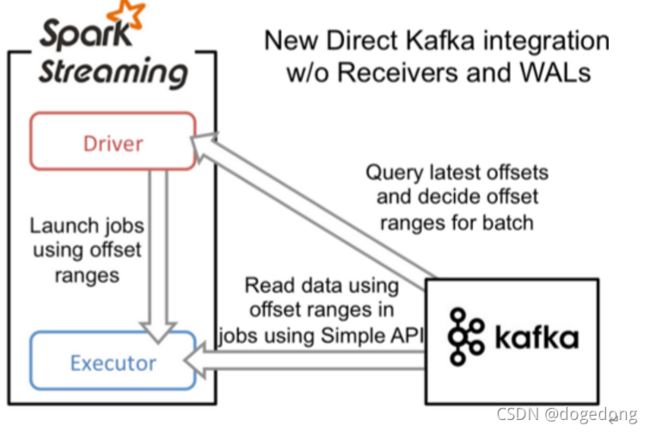
这种方法相较于Receiver方式的优势在于:
1、简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
2、高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
3、精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
请注意,此方法的一个缺点是它不会更新Zookeeper中的偏移量,因此基于Zookeeper的Kafka监视工具将不会显示进度。但是,您可以在每个批处理中访问此方法处理的偏移量,并自行更新Zookeeper。
直连模式特点:batch time 每隔一段时间,去kafka读取一批数据,然后消费
简化并行度,rdd的分区数量=topic的分区数量
数据存储于kafka中,没有数据冗余
不存在单点问题
效率高
可以实现仅消费一次的语义 exactly-once语义
2、整合编码
(1)从kafka读取数据
earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.serializer.KryoSerializer
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
/*
SparkStremaing从kafka中读取数据
PerPartitionConfig
spark.streaming.kafka.maxRatePerPartition
spark.streaming.kafka.minRatePerPartition
都是代表了streaming程序消费kafka速率,
max: 每秒钟从每个分区读取的最大的纪录条数
max=10,分区个数为3,间隔时间为2s
所以这一个批次能够读到的最大的纪录条数就是:10*3*2=60
如果配置的为0,或者不设置,起速率没有上限
min: 每秒钟从每个分区读取的最小的纪录条数
那么也就意味着,streaming从kafka中读取数据的速率就在[min, max]之间
执行过程中出现序列化问题:
serializable (class: org.apache.kafka.clients.consumer.ConsumerRecord, value: ConsumerRecord
spark中有两种序列化的方式
默认的就是java序列化的方式,也就是写一个类 implement Serializable接口,这种方式的有点事非常稳定,但是一个非常的确定是性能不佳
还有一种高性能的序列化方式——kryo的序列化,性能非常高,官方给出的数据是超过java的序列化性能10倍,同时在使用的时候只需要做一个声明式的注册即可
sparkConf.set("spark.serializer", classOf[KryoSerializer].getName)//指定序列化的方式
.registerKryoClasses(Array(classOf[ConsumerRecord[String, String]]))//注册要序列化的类
*/
object StreamingFromKafkaOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
.setAppName("StreamingFromKafkaOps")
// .set("spark.serializer", classOf[KryoSerializer].getName)
// .registerKryoClasses(Array(classOf[ConsumerRecord[String, String]]))
//两次流式计算之间的时间间隔,batchInterval
val batchDuration = Seconds(2) // 每隔2s提交一次sparkstreaming的作业
val ssc = new StreamingContext(conf, batchDuration)
val topics = Set("hadoop")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark-kafka-grou-0817",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> "false"
)
/*
从kafka中读取数据
locationStrategy:位置策略
制定如何去给特定的topic和partition来分配消费者进行调度,可以通过LocationStrategies来得到实例。
在kafka0.10之后消费者先拉取数据,所以在适当的executor来缓存executor操作对于提高性能是非常重要的。
PreferBrokers:
如果你的executor在kafka的broker实例在相同的节点之上可以使用这种方式。
PreferConsistent:
大多数情况下使用这个策略,会把partition分散给所有的executor
PreferFixed:
当网络或者设备性能等个方便不均衡的时候,可以蚕蛹这种方式给特定executor来配置特定partition。
不在这个map映射中的partition使用PreferConsistent策略
consumerStrategy:消费策略
配置在driver或者在executor上面创建的kafka的消费者。该接口封装了消费者进程信息和相关的checkpoint数据
消费者订阅的时候的策略:
Subscribe : 订阅多个topic进行消费,这多个topic用集合封装
SubscribePattern : 可以通过正则匹配的方式,来订阅多个消费者,比如订阅的topic有 aaa,aab,aac,adc,可以通过a[abc](2)来表示
Assign : 指定消费特定topic的partition来进行消费,是更加细粒度的策略
*/
val message:InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topics, kafkaParams))
// message.print()//直接打印有序列化问题
message.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {
println("-------------------------------------------")
println(s"Time: $bTime")
println("-------------------------------------------")
rdd.foreach(record => {
println(record)
})
}
})
ssc.start()
ssc.awaitTermination()
}
}
(2)从kafka指定offset读取数据
/*
SparkStremaing从kafka中读取数据
从指定的offset位置来读取数据
*/
object StreamingFromKafkaOps2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
.setAppName("StreamingFromKafkaOps2")
//两次流式计算之间的时间间隔,batchInterval
val batchDuration = Seconds(2) // 每隔2s提交一次sparkstreaming的作业
val ssc = new StreamingContext(conf, batchDuration)
val topics = Set("hadoop")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark-kafka-group-0817",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> "false"
)
val offsets = Map[TopicPartition, Long](
new TopicPartition("hadoop", 0) -> 451,
new TopicPartition("hadoop", 1) -> 452,
new TopicPartition("hadoop", 2) -> 447
)
val message:InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topics, kafkaParams, offsets))
message.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {
println("-------------------------------------------")
println(s"Time: $bTime")
println("-------------------------------------------")
rdd.foreach(record => {
println(record)
})
}
})
ssc.start()
ssc.awaitTermination()
}
}(3)使用MySQL来管理偏移量
import java.sql.{DriverManager, ResultSet}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Kafka_Demo {
def main(args: Array[String]): Unit = {
//创建SparkStreaming程序入口
val conf: SparkConf = new SparkConf().setAppName("demo").setMaster("local[*]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(5))
//设置日志级别
sc.setLogLevel("WARN")
//连接kafka相关配置文件
val kafkaParams = Map[String, Object](
//连接kafka
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
//key的反序列化
"key.deserializer" -> classOf[StringDeserializer],
//value的反序列化
"value.deserializer" -> classOf[StringDeserializer],
//消费者组id
"group.id" -> "use_a_separate_group_id_for_each_stream",
//从最新偏移量进行消费
"auto.offset.reset" -> "latest",
//是否自动提交偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//消费kafka当中哪个主题下的数据
val topics = Array("test")
//获取数据库当中是否已经存在了偏移量
val offsetMap: mutable.Map[TopicPartition, Long] = OffsetUtil.getOffsetMap("use_a_separate_group_id_for_each_stream","test")
//判断数据库当中之前是否已经存在了偏移量
val data: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.size>0){
println("数据库当中有数据")
KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams,offsetMap))
}else {
println("数据库当中没有数据")
KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))
}
//消费数据,维护偏移量到数据库
data.foreachRDD(rdd=>{
if (rdd.count()>0){
//查看消费到的数据是什么
rdd.foreach(record=>println("传进来的数据为:"+record))
//为了维护偏移量,spark自带了一个类,用来维护偏移量
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//遍历offsetRanges,查看都有哪些东西
for (o<-offsetRanges){
println(s"topic=${o.topic},partition=${o.partition},fromoffset=${o.fromOffset},untiloffset=${o.untilOffset}")
}
OffsetUtil.saveOffsetRanges("use_a_separate_group_id_for_each_stream",offsetRanges)
}
})
ssc.start()
ssc.awaitTermination()
}
}
工具类:
object OffsetUtil {
def getOffsetMap(groupid: String, topic: String) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "root")
val pstmt = connection.prepareStatement("select * from t_offset where groupid=? and topic=?")
pstmt.setString(1, groupid)
pstmt.setString(2, topic)
val rs: ResultSet = pstmt.executeQuery()
val offsetMap = mutable.Map[TopicPartition, Long]()
while (rs.next()) {
offsetMap += new TopicPartition(rs.getString("topic"), rs.getInt("partition")) -> rs.getLong("offset")
}
rs.close()
pstmt.close()
connection.close()
offsetMap
}
def saveOffsetRanges(groupid: String, offsetRange: Array[OffsetRange]) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "root")
//replace into表示之前有就替换,没有就插入
val pstmt = connection.prepareStatement("replace into t_offset (`topic`, `partition`, `groupid`, `offset`) values(?,?,?,?)")
for (o <- offsetRange) {
pstmt.setString(1, o.topic)
pstmt.setInt(2, o.partition)
pstmt.setString(3, groupid)
pstmt.setLong(4, o.untilOffset)
pstmt.executeUpdate()
}
pstmt.close()
connection.close()
}
}
建表语句:
/*
手动维护offset的工具类
首先在MySQL创建如下表
CREATE TABLE `t_offset` (
`topic` varchar(255) NOT NULL,
`partition` int(11) NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint(20) DEFAULT NULL,
PRIMARY KEY (`topic`,`partition`,`groupid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/