【AI视野·今日CV 计算机视觉论文速览 第186期】Fri, 6 Nov 2020
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 6 Nov 2020
Totally 44 papers
上期速览✈更多精彩请移步主页

Interesting:
单目深度估计CLIFFNet, 提出了一种基于层次损失的单目深度估计算法,在不同层级的嵌入空间中测量预测深度图的误差。基于设计的多级嵌入生成器架构,探索了这些参数的相关性,交叉层级识别特征融合网络(CLIFFNet)可以利用更为可高的高层级特征来提升更为精细的底层特征图,并学习顶层和底层间更好的参数组合实现融合。(from 大连理工 鹏城实验室 adobe)
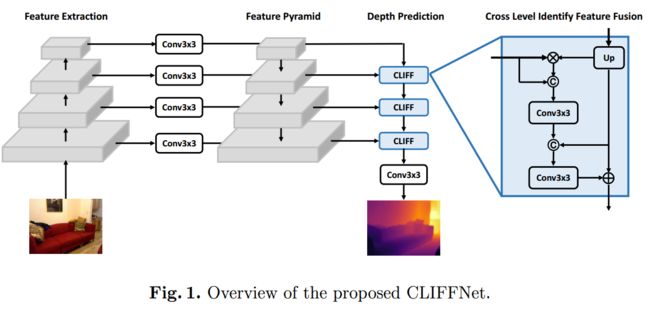

code
dataset:NYU-Depth V2 dataset [27], Cityscape [3]
Points2Surf, 提出了一种从原始扫描点云直接学习出表面的方法,而无需法向量的辅助(from adobe 伦敦大学学院等等)
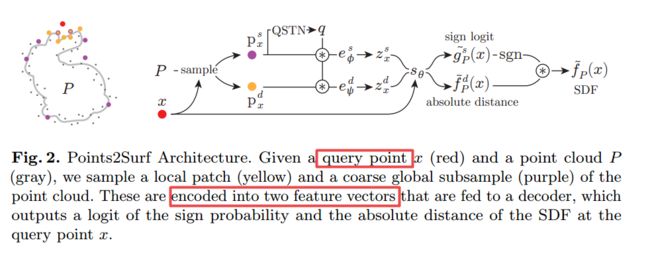
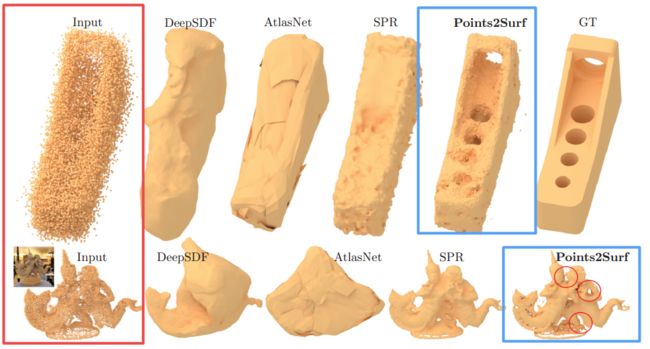
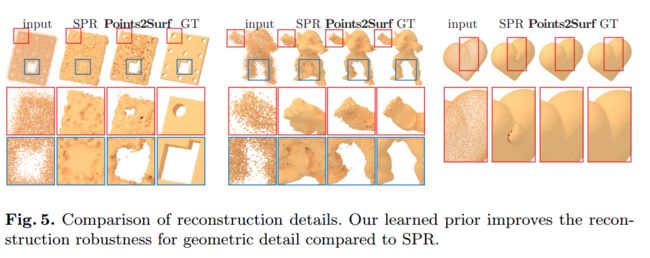
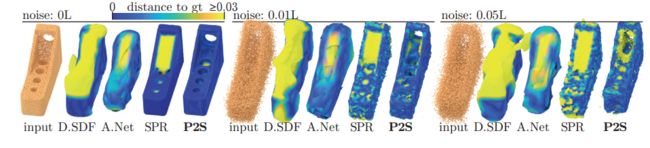

code
dataset: ABC dataset , Famous
ParSeNet点云参数化曲面方法, 一种可训练的基于深度学习的方法将点云转换为3D参数化曲面,通过大量训练获得了形状分解的语义先验信息,通过基于点云的分解、拟合最终优化得到最后的参数化结果。(from 麻省大学 adobe IIT)
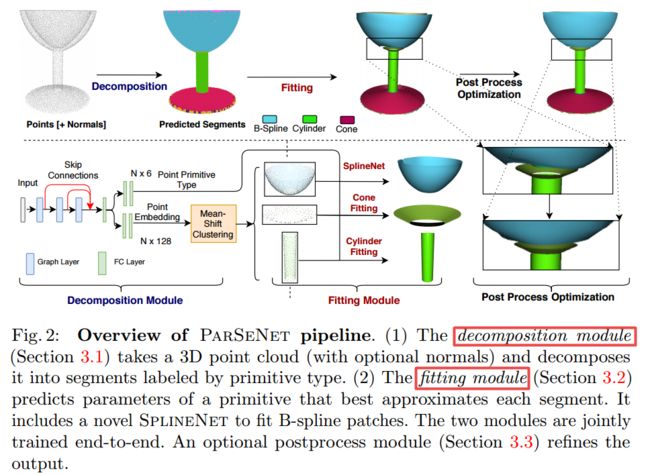
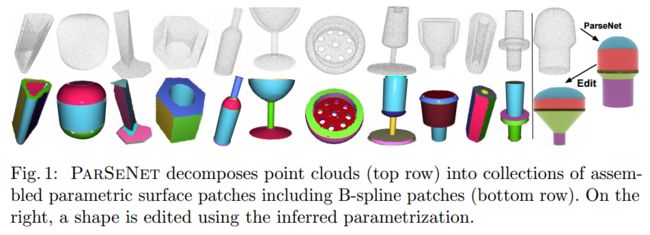

code, dataset: ABCPartsDataset, TracePart dataset
基于超图卷积的图像补全技术, 为了克服注意力机制不能捕捉全局信息造成图像模糊的问题,提出了使用超图卷积(hypergraph convolution)的方法来学习数据间的复杂内在关系。(from IIT 莫纳什等等)
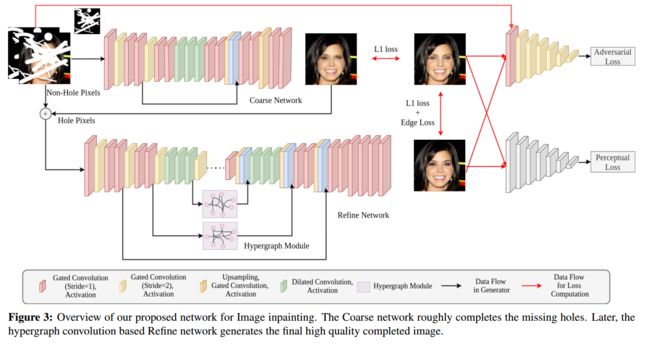
超图卷积的架构:
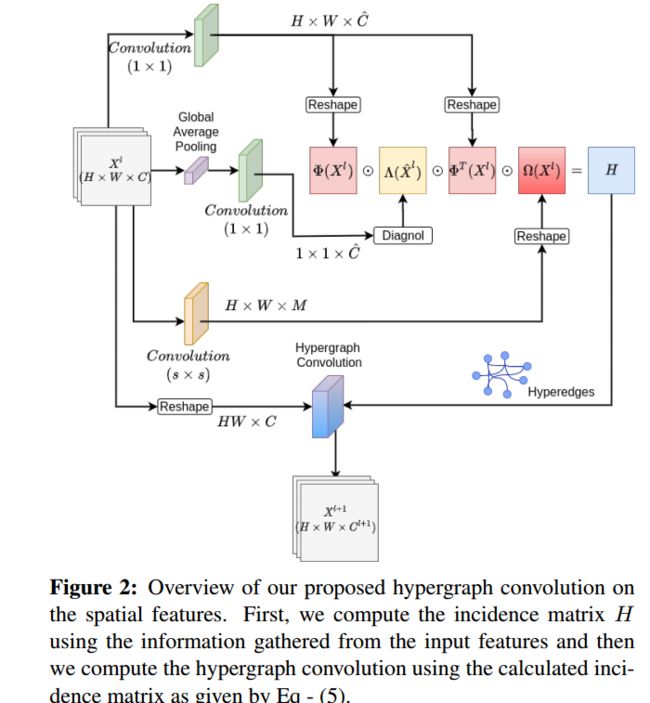

In [13], hypergraph neural network (HGNN) which introduces spectral convolution on hypergraphs, using the regularization framework introduced in [58].
In [2], the authors introduce a hypergraph attention module.
[13] Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao. Hypergraph neural networks. In AAAI, 2019.
基于多层特征聚合的深度场景解译, 同时需要进行几何感知和语义分析的场景解析任务,需要多成特征进行聚合,生成有效的全局表达先验,改善对于特征的辨识能力,同时多个调节也提供了很强的监督信号。(from 悉尼技术大学、格里菲斯大学 澳大利亚)

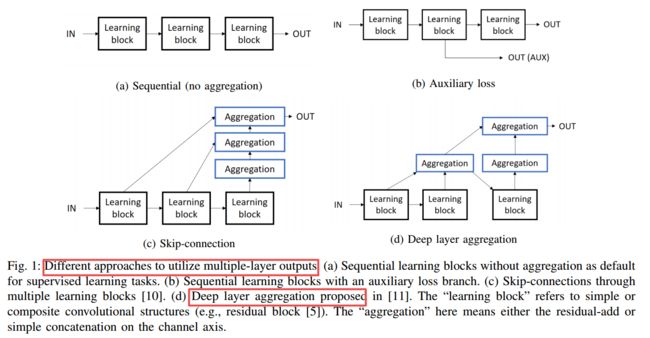

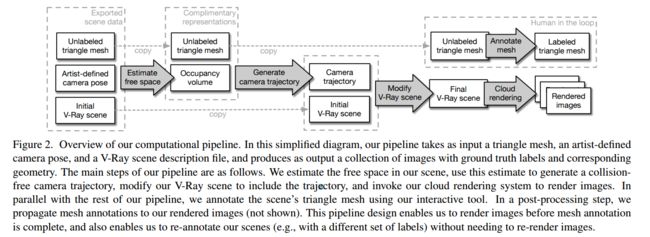
Hypersim 室内场景理解数据集, (from 苹果)

数据集构建渲染过程:

1Chaos Group V-Ray.
2 Evermotion Archinteriors Collection.
3 TurboSquid.
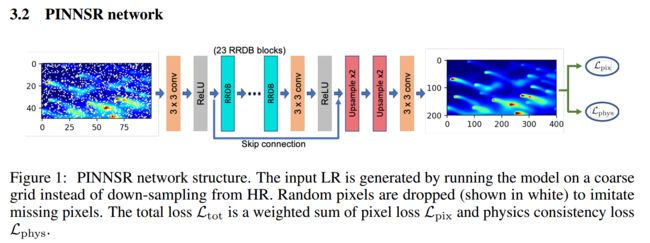
PINNSR基于物理原理连续性的图像超分辨, 用于 Advection-Diffusion Models
模型,添加缺失数据得到细粒度结果。提升模拟分辨率。(from ibm)
物理建模系统,添加了物理约束和物理连续性:

医学图像配准系统,(from 伦敦大学学院 InstaDeep等等)

DeepReg
Daily Computer Vision Papers
| CompressAI: a PyTorch library and evaluation platform for end-to-end compression research Authors Jean B gaint, Fabien Racap , Simon Feltman, Akshay Pushparaja 本文介绍了CompressAI,这是一个提供自定义操作,层,模型和工具以研究,开发和评估端到端图像和视频压缩编解码器的平台。特别是,CompressAI包括预先训练的模型和评估工具,用于将学习的方法与传统编解码器进行比较。因此,已在PyTorch中重新实现了从学习到的端到端压缩的最新技术模型,并从头开始进行了训练。我们还使用Kodak图像数据集作为测试集,报告了使用PSNR和MS SSIM指标与比特率的客观比较结果。尽管此框架当前实现用于静态图片压缩的模型,但打算很快将其扩展到视频压缩域。 |
| Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers Authors Zhaoshuo Li, Xingtong Liu, Francis X. Creighton, Russell H. Taylor, Mathias Unberath 立体深度估计依赖于左右图像中对极线上像素之间的最佳对应匹配来推断深度。在这项工作中,我们没有从单个像素上进行匹配,而是从序列到序列对应的角度重新审视了该问题,以使用位置信息和注意力将像素数量结构替换为密集的像素匹配。这种称为STereo TRANSformer STTR的方法具有多个优点。1放宽了固定视差范围的限制,2识别了被遮挡的区域并提供了估计的置信度,3在匹配过程中施加了唯一性约束。我们在合成数据集和现实世界数据集上均报告了令人鼓舞的结果,并表明STTR可以很好地在不同领域进行泛化,即使没有进行微调也是如此。我们的代码可在以下位置公开获得 |
| Hyperrealistic Image Inpainting with Hypergraphs Authors Gourav Wadhwa, Abhinav Dhall, Subrahmanyam Murala, Usman Tariq 由于有多种可能性来填充丢失的数据,图像修补在计算机视觉中是一项不平凡的任务,这可能取决于图像的全局信息。现有的大多数方法都使用注意力机制来学习图像的全局上下文。由于无法捕获全局上下文,因此这种注意机制会产生语义上合理的但模糊的结果。在本文中,我们介绍了关于空间特征的超图卷积,以了解数据之间的复杂关系。我们引入了一种可训练的机制来使用超边连接超图卷积来连接节点。就我们所知,超图卷积从未用于计算机视觉中任何图像到图像任务的空间特征。此外,我们在鉴别器中引入了门控卷积,以在预测图像中实现局部一致性。在Places2,CelebA HQ,Paris Street View和Facades数据集上进行的实验表明,我们的方法达到了最新水平。 |
| Robust building footprint extraction from big multi-sensor data using deep competition network Authors Mehdi Khoshboresh Masouleh, Mohammad R. Saradjian 从多传感器数据(例如光学图像和光检测以及测距LiDAR点云)中提取建筑足迹BFE已广泛用于遥感应用的各个领域。然而,由于从多传感器数据中的各种复杂场景中提取建筑物的技术效率相对较低,因此它仍然是具有挑战性的研究课题。在这项研究中,我们开发并评估了深度竞争网络DCN,该网络将超高空间分辨率的光学遥感影像与LiDAR数据融合在一起,从而获得稳定的BFE。 DCN是一种深度的超像素卷积编码器解码器体系结构,它使用具有分类结构的编码器矢量量化。 DCN由五个具有卷积权重的编码解码块组成,用于鲁棒的二进制表示超像素学习。 DCN在大型多传感器数据集中进行了培训和测试,该数据集来自美国印第安纳州,具有多个建筑物场景。准确性评估的比较结果表明,与其他深度语义二进制分割架构相比,DCN具有竞争性的BFE性能。因此,我们得出的结论是,所提出的模型是从大型多传感器数据中获取鲁棒BFE的合适解决方案。 |
| This Looks Like That, Because ... Explaining Prototypes for Interpretable Image Recognition Authors Meike Nauta, Annemarie Jutte, Jesper Provoost, Christin Seifert 带有原型的图像识别被认为是黑盒深度学习模型的可解释替代方案。分类取决于测试图像看起来像原型的程度。但是,人类的感知相似性可能与模型学习的相似性不同。用户不了解基础分类策略,并且不知道哪个图像特征,例如颜色或形状是该决定的主要特征。我们解决了这种歧义,并主张应解释原型。仅可视化原型可能不足以理解原型确切代表什么以及为什么原型和图像被视为相似。我们通过自动增强原型以及有关模型认为重要的视觉特征的额外信息来提高可解释性。具体来说,我们的方法量化了原型中色彩,形状,纹理,对比度和饱和度的影响。我们将我们的方法应用于现有的原型零件网络ProtoPNet,并表明我们的解释阐明了原型的含义,否则该原型可能会被错误地解释。我们还发现,视觉上相似的原型可以具有相同的解释,表明存在冗余。由于我们方法的通用性,它可以提高任何基于相似度的原型图像识别方法的可解释性。 |
| UAV-AdNet: Unsupervised Anomaly Detection using Deep Neural Networks for Aerial Surveillance Authors Ilker Bozcan, Erdal Kayacan 异常检测是自动监视系统的主要目标,该系统应能够警告异常观察。在本文中,我们提出了一种使用深度神经网络的整体异常检测系统,用于使用无人飞行器无人机监视关键基础设施,例如机场,港口,仓库。首先,我们提出一种启发式方法,用于在鸟瞰图像中明确表示对象的空间布局。然后,我们提出了一种用于无监督异常检测无人机AdNet的深度神经网络体系结构,该体系结构在环境表示和鸟瞰图图像的GPS标签上共同训练。与文献中的研究不同,我们将GPS和图像数据结合起来以预测异常观测。我们根据空中监视数据集上的几个基准评估了我们的模型,并表明该模型在场景重建和一些异常检测任务中表现更好。代码,训练有素的模型,数据集和视频将在以下位置提供 |
| Deep Metric Learning with Spherical Embedding Authors Dingyi Zhang, Yingming Li, Zhongfei Zhang 深度度量学习由于将距离度量学习与深度神经网络无缝结合而引起了近年来的广泛关注。许多努力致力于设计不同的基于成对的角度损失函数,这些函数对嵌入向量的幅度和方向信息进行解耦,并确保训练和测试度量的一致性。然而,这些传统的角度损失不能保证在训练阶段所有的样本嵌入都在同一个超球面上,这将导致批次优化中的梯度不稳定,并可能影响嵌入学习的快速收敛。在本文中,我们首先研究了嵌入范数对具有角度距离的深度度量学习的影响,然后提出了球形嵌入约束SEC来规范范数的分布。 SEC自适应地调整嵌入,使其落在同一超球上,并执行更平衡的方向更新。在深度度量学习,面部识别和对比自我监督学习方面的大量实验表明,基于SEC的角度空间学习策略可显着提高现有技术的性能。 |
| Fast Object Detection with Latticed Multi-Scale Feature Fusion Authors Yue Shi, Bo Jiang, Zhengping Che, Jian Tang 尺度差异是多尺度目标检测中的关键挑战之一。早期的方法通过利用图像和特征金字塔来解决此问题,这会带来次优的结果,并带来计算负担并受到固有网络结构的限制。开拓性工作还提出了多尺度(即多层次和多分支特征融合)来解决该问题并取得了令人鼓舞的进展。但是,现有的融合仍具有某些局限性,例如特征尺度不一致,对层级语义转换的无知和粗粒度。在这项工作中,我们提出了一种新颖的模块Fluff模块,以减轻当前多尺度融合方法的弊端并促进多尺度目标检测。具体而言,Fluff充分利用了具有扩展卷积的多级和多分支方案,以实现快速,有效和更细粒度的特征融合。此外,我们将Fluff作为FluffNet集成到SSD中,这是一种用于多尺度物体检测的功能强大的实时单级检测器。在MS COCO和PASCAL VOC上的经验结果表明,FluffNet以最先进的精度获得了显着的效率。此外,我们通过展示如何将Fluff块嵌入其他广泛使用的检测器来表明Fluff块的巨大通用性。 |
| Robust Unsupervised Video Anomaly Detection by Multi-Path Frame Prediction Authors Xuanzhao Wang, Zhengping Che, Ke Yang, Bo Jiang, Jian Tang, Jieping Ye, Jingyu Wang, Qi Qi 视频异常检测通常用于许多应用中,例如安全监控,并且非常具有挑战性。大多数最新的视频异常检测方法都使用深度重建模型,但由于在实践中正常视频帧和异常视频帧之间的重建误差差异不足,因此它们的性能通常欠佳。同时,基于帧预测的异常检测方法已显示出令人鼓舞的性能。在本文中,我们提出了一种新颖且健壮的,经过帧预测的,经过适当设计的,健壮的无监督视频异常检测方法,该方法更加符合监控视频的特性。所提出的方法配备有基于多路径ConvGRU的帧预测网络,该网络可以更好地处理语义信息对象和不同比例的区域,并捕获正常视频中的空间时间依赖性。在训练期间引入了噪声容限损失,以减轻由背景噪声引起的干扰。在中大大道,上海科技园区和UCSD行人数据集上进行了广泛的实验,结果表明我们提出的方法优于现有方法。值得注意的是,我们提出的方法在中大大道数据集上获得了88.3的帧级AUC分数。 |
| Goal-driven Long-Term Trajectory Prediction Authors Hung Tran, Vuong Le, Truyen Tran 通过使用强大的顺序建模和丰富的环境特征提取,对人类短期轨迹的预测有了显着进步。然而,由于误差可能会不断累积,因此长期预测仍然是当前方法的主要挑战。实际上,一直到轨迹末尾的一致且稳定的预测固有地需要对轨迹的整体结构进行更深入的分析,这与行人对旅程目的地的意图有关。在这项工作中,我们建议对假设过程进行建模,该过程确定行人的目标以及该过程对长期未来轨迹的影响。我们设计了目标驱动轨迹预测模型,实现了这种直觉的双通道神经网络。网络的两个渠道将发挥各自的作用,并协作以产生未来的发展轨迹。与传统的基于目标条件的,基于计划的方法不同,该模型体系结构旨在对模式进行泛化,并使用任意的几何和语义结构跨不同的场景工作。该模型在各种环境下,特别是在较大的预测范围内,均表现出优于现有技术的水平。该结果是人类行为分析中视觉和几何特征的自适应结构表示的有效性的另一证据。 |
| An analysis of the transfer learning of convolutional neural networks for artistic images Authors Nicolas Gonthier, Yann Gousseau, Sa d Ladjal 从庞大的自然图像数据集中进行转移学习,对深度神经网络进行微调以及使用相应的经过预先训练的网络,实际上已成为艺术分析应用程序的核心。但是,对转移学习的效果仍然知之甚少。在本文中,我们首先使用可视化网络内部表示的技术,以便为了解网络从艺术图像中学到的知识提供线索。然后,由于特征和参数空间中的度量以及根据最大激活图像集计算的度量,我们对学习过程引入的变化进行了定量分析。这些分析是对转移学习程序的几种变体进行的。尤其是,我们观察到该网络可以将一些经过预训练的过滤器专门用于新的图像模态,并且更高的层倾向于集中分类。最后,我们表明,即使任务发生更改,涉及中等大小的艺术数据集的双重微调也可以改善较小数据集的分类。 |
| Few-Shot Object Detection in Real Life: Case Study on Auto-Harvest Authors Kevin Riou, Jingwen Zhu, Suiyi Ling, Mathis Piquet, Vincent Truffault, Patrick Le Callet COVID 19期间的禁闭对全世界的农业造成了严重影响。作为有效的解决方案之一,基于对象检测和机械收割机的机械收割自动收割变得迫切需要。在自动收获系统中,健壮的少量射击对象检测模型是瓶颈之一,因为需要该系统处理新的蔬菜水果类别,并且所有新颖类别的大规模注释数据集的收集成本很高。社区开发的射击物体检测模型很少。然而,由于通常使用的训练数据集和在现实农业场景中收集的图像之间存在上下文差距,因此它们是否可以直接用于现实农业应用仍存在疑问。为此,在本研究中,我们提出了一个新颖的黄瓜数据集,并提出了两种有助于弥合上下文差距的数据增强策略。实验结果表明:1现有技术中的少数射击对象检测模型在新型黄瓜类别上的性能不佳; 2所提出的增强策略优于常用策略。 |
| DTGAN: Dual Attention Generative Adversarial Networks for Text-to-Image Generation Authors Zhenxing Zhang, Lambert Schomaker 现有的大多数文本到图像生成方法都采用多阶段模块化体系结构,该体系结构具有三个重要问题1训练多个网络会增加运行时间并影响生成模型的收敛性和稳定性2这些方法忽略了早期生成器图像的质量3许多鉴别人员需要接受培训。为此,我们提出了双重注意生成对抗网络DTGAN,它可以仅使用一个生成器鉴别器对就可以合成高质量和视觉逼真的图像。所提出的模型引入了通道感知和像素感知注意模块,这些模块可以指导生成器基于全局句子向量专注于与文本相关的通道和像素,并使用注意力权重来微调原始特征图。此外,还提出了条件自适应实例层规范化CAdaILN,以帮助我们的注意力模块通过输入自然语言描述灵活地控制形状和纹理的变化量。此外,通过确保生成的图像的生动形状和感知上均匀的颜色分布,利用一种新型的视觉损失来提高图像质量。在基准数据集上的实验结果表明,与具有多阶段框架的最新模型相比,我们提出的方法具有优越性。注意力图的可视化显示,通道意识的注意力模块能够定位区分区域,而像素意识的注意力模块具有捕获全局视觉内容以生成图像的能力。 |
| Center-wise Local Image Mixture For Contrastive Representation Learning Authors Hao Li, Xiaopeng Zhang, Ruoyu Sun, Hongkai Xiong, Qi Tian 无监督表示学习的最新进展取得了显着进展,特别是在对比学习的成就方面,对比学习将每个图像及其扩充视为一个单独的类,而没有考虑图像之间的语义相似性。本文提出了一种新的数据增强方法,称为中心明智局部图像混合,以扩展图像的邻域空间。 CLIM鼓励在提取相似图像的同时进行局部相似性和全局聚合。这是通过搜索图像的局部相似样本,并仅选择更靠近相应聚类中心的图像来实现的,我们将其称为中心方式局部选择。结果,相似的表示逐渐接近群集,同时又不破坏局部相似性。此外,将图像混合用作平滑正则化以避免对所选样本过度自信。此外,我们引入了多分辨率增强,它使表示成为尺度不变的。将这两个增强功能集成在一起,可以在几个无人监督的基准上更好地表现特征。值得注意的是,在通过ResNet 50进行线性评估时,我们达到了75.5 top 1准确性,而仅用1个标签进行微调时,我们达到了59.3 top 1准确性,并且在多个下游传输任务上始终优于有监督的预培训。 |
| Defense-friendly Images in Adversarial Attacks: Dataset and Metrics forPerturbation Difficulty Authors Camilo Pestana, Wei Liu, David Glance, Ajmal Mian 数据集偏差是对抗机器学习中的一个问题,尤其是在防御评估中。对抗性攻击或防御算法在报告的数据集上可能会比在其他数据集上显示出更好的结果。即使比较两种算法,它们的相对性能也会因数据集而异。深度学习为图像识别提供了最先进的解决方案,但是深度模型即使在很小的扰动下也很脆弱,该领域的研究主要侧重于对抗攻击和防御算法。在本文中,我们首次报告了一类健壮的图像,它们既具有抵御攻击的能力,又能通过简单的防御技术在对抗性攻击下比随机图像恢复得更好。对对抗性攻击或防御的表现产生误导性印象。我们提出了三个指标来确定数据集中鲁棒图像的比例,并提供评分来确定数据集偏差。我们还提供了包含15000张鲁棒图像的ImageNet R数据集,以促进对这种有趣的攻击图像强度现象的进一步研究。我们的数据集与拟议的指标相结合,对于对抗性攻击和防御算法的无偏基准测试非常有价值 |
| AOT: Appearance Optimal Transport Based Identity Swapping for Forgery Detection Authors Hao Zhu, Chaoyou Fu, Qianyi Wu, Wayne Wu, Chen Qian, Ran He 最近的研究表明,使用多样化且具有挑战性的Deepfakes数据集可以提高伪造检测的性能。但是,由于缺乏在外观上具有较大差异的Deepfakes数据集,而这种差异很难通过最新的身份交换方法生成,因此在这种情况下,检测算法可能会失败。在这项工作中,我们提供了一种新的身份交换算法,该算法在外观上存在很大差异,可用于人脸伪造检测。外观差异主要是由于现实世界中普遍存在的照明和肤色差异很大。但是,由于难以对复杂的外观映射进行建模,因此在保留身份特征的同时自适应地传输细粒度外观是一个挑战。本文将外观映射表述为最佳传输问题,并提出了一种外观最优传输模型AOT来在潜在空间和像素空间中对其进行表述。具体而言,重新照明发电机设计为模拟最佳运输计划。通过最小化潜在空间中学习特征的Wasserstein距离来解决该问题,与传统的优化方法相比,具有更好的性能和更少的计算量。为了进一步优化最佳运输计划的解决方案,我们开发了一个分割游戏以最小化像素空间中的Wasserstein距离。引入了区分器,以从真实和虚假图像补丁的混合中区分出虚假部分。大量的实验表明,与现有技术相比,我们的方法具有优越性,并且所生成的数据具有改善人脸伪造检测性能的能力。 |
| Deep Active Learning with Augmentation-based Consistency Estimation Authors SeulGi Hong, Heonjin Ha, Junmo Kim, Min Kook Choi 在主动学习中,重点主要放在未标记数据的选择策略上,以增强下一个学习周期的泛化能力。为此,已经提出了各种不确定性测量方法。另一方面,随着数据增强指标作为常规深度学习的正则化方法的出现,我们注意到在主动学习场景中,未标记数据选择方法与基于数据增强的正则化技术之间可能存在相互影响。通过各种实验,我们证实了基于分析学习理论的基于一致性的正则化可以结合现有的不确定性测量方法来影响分类器的泛化能力。基于这一事实,我们提出了一种通过将基于数据增强的技术应用于主动学习场景来提高泛化能力的方法。对于基于数据扩充的正则化损失,我们将cutout co和cutmix cm策略重新定义为定量指标,并应用于模型训练和未标记的数据选择步骤。我们已经表明,基于增强的正则化器可以在主动学习的训练步骤上提高性能,而该方法可以与到目前为止提出的不确定性度量标准有效地结合在一起。我们使用诸如FashionMNIST,CIFAR10,CIFAR100和STL10之类的数据集来验证所提出的主动学习技术在多个图像分类任务中的性能。我们的实验表明,每个数据集和预算方案的性能提升都是一致的。 |
| Utilizing Every Image Object for Semi-supervised Phrase Grounding Authors Haidong Zhu, Arka Sadhu, Zhaoheng Zheng, Ram Nevatia 短语基础模型会在给定引用表达式的情况下将对象定位在图像中。训练期间可用的带注释的语言查询受到限制,这也限制了模型在训练期间可以看到的语言组合的变化。在本文中,我们研究了应用没有标签查询的对象来训练半监督短语基础的案例。我们建议使用学习的位置和主题嵌入预测变量LSEP为训练集中缺少注释查询的对象生成相应的语言嵌入。在探测器的帮助下,我们还应用LSEP在图像上训练了接地模型而没有任何注释。我们在三个公共数据集RefCOCO,RefCOCO和RefCOCOg上基于MAttNet评估了我们的方法。我们表明,我们的预测变量可以使接地系统从没有标签查询的对象中学习,并相对于检测结果将准确性提高34.9。 |
| Disentangling Latent Space for Unsupervised Semantic Face Editing Authors Kanglin Liu, Gaofeng Cao, Fei Zhou, Bozhi Liu, Jiang Duan, Guoping Qiu 编辑由StyleGAN创建的面部图像是具有重要应用程序的热门研究主题。通过编辑潜矢量,可以控制面部特征,例如微笑,年龄,文本等。然而,面部属性纠缠在潜在空间中,这使得很难独立控制特定属性而不影响其他属性。开发整洁的语义控制的关键是完全消除潜在空间的干扰,并以无监督的方式执行图像编辑。在本文中,我们提出了一种新技术,称为具有权重分解和正交正则化STIA WO的结构纹理独立体系结构,以消除潜在空间的纠缠。应用STIA WO的GAN模型称为STGAN WO。 STGAN WO通过使用样式向量构建完全可控制的权重矩阵以控制图像合成来进行权重分解,并利用正交正则化确保样式向量的每个条目仅控制一个变化因子。为了进一步消除面部属性,STGAN WO引入了一种结构纹理独立的体系结构,该体系结构利用两个独立且相同分布的i.i.d.潜在矢量以解开的方式控制纹理和结构成分的合成。通过在粗糙层中沿其正交方向移动潜在代码来更改纹理相关属性,或将精细层中的潜在代码更改为处理与结构有关的。我们提供的实验结果表明,与最新方法相比,我们的新STGAN WO可以实现更好的属性编辑。 |
| GPR-based Model Reconstruction System for Underground Utilities Using GPRNet Authors Jinglun Feng, Liang Yang, Ejup Hoxha, Stanislav Sotnikov, Diar Sanakov, Jizhong Xiao 探地雷达GPR是最重要的无损评估NDE仪器之一,可检测和定位地下物体(例如钢筋,公用管道)。之前的许多研究仅集中在基于GPR图像的特征检测上,没有一个能够处理稀疏的GPR测量以成功地重建非常精细和详细的地下物体3D模型以实现更好的可视化。为了解决这个问题,本文提出了一种新颖的机器人系统来收集GPR数据,定位地下设施以及重建地下物体密集点云模型。该系统由三个模块组成:1基于视觉惯性的GPR数据收集模块,该模块以全向机器人提供的定位信息标记GPR测量值2深度神经网络DNN迁移模块,以将原始GPR B扫描图像解释为物体的横截面模型3是基于DNN的3D重建模块(即GPRNet),用于生成具有精细3D点云的地下实用模型。实验表明,我们的方法可以基于稀疏输入(即GPR原始数据)生成具有各种不完整度和噪声水平的稠密且完整的管状公用事业点云模型。综合数据和现场测试数据的实验结果证明了该方法的有效性。 |
| Lets Play Music: Audio-driven Performance Video Generation Authors Hao Zhu, Yi Li, Feixia Zhu, Aihua Zheng, Ran He 我们提出了一项名为“音频驱动的性能视频生成APVG”的新任务,该任务旨在合成在给定的音乐音频片段的指导下演奏某种乐器的人的视频。从低维音频模态产生高维时间一致视频是一项艰巨的任务。在本文中,我们提出了一个多阶段框架来实现这一新任务,以根据给定的音乐生成逼真的同步表演视频。首先,我们通过从给定的音乐分别生成粗略的视频和身体和手部的关键点来提供全局外观和局部空间信息。然后,我们建议通过可微分的空间转换器将生成的关键点转换为热图,因为热图提供了更多的空间信息,但更难直接从音频生成。最后,我们提出了一种结构化的时间UNet STU,以提取帧内结构化信息和帧间时间一致性。它们分别通过基于图的结构模块和基于CNN GRU的高级时间模块获得,用于最终视频生成。全面的实验验证了我们提出的框架的有效性。 |
| Transforming Facial Weight of Real Images by Editing Latent Space of StyleGAN Authors V N S Rama Krishna Pinnimty, Matt Zhao, Palakorn Achananuparp, Ee Peng Lim 我们提出了一种反转和编辑框架,可以利用生成对抗网络GAN的潜在空间中编码的语义面部属性,自动将输入面部图像的面部权重转换为看起来更薄或更重。使用预先训练的StyleGAN作为基础生成器,我们首先采用基于优化的嵌入方法将输入图像转换为StyleGAN潜在空间。然后,我们通过监督学习来识别潜在空间中的面部权重属性方向,并通过沿提取的特征轴正向或负向移动反向的潜在代码来对其进行编辑。根据经验显示,我们的框架可产生高质量且逼真的面部重量转换,而无需从头开始使用大量标记的面部图像训练GAN。最终,我们的框架可以用作干预措施的一部分,通过可视化他们的行为对外观的未来影响来激励个人做出更健康的食物选择。 |
| Universal Multi-Source Domain Adaptation Authors Yueming Yin, Zhen Yang, Haifeng Hu, Xiaofu Wu 无监督域自适应使智能模型能够将知识从标记的源域转移到相似但未标记的目标域。最近的研究表明,知识可以从一个源域转移到另一个未知的目标域,称为通用域适应UDA。但是,在现实世界的应用程序中,经常会有不止一个源域可用于域自适应。在本文中,我们正式提出了一个更通用的域适应设置,即通用多源域适应UMDA,其中多个源域的标签集可以不同,而目标域的标签集是完全未知的。 UMDA中的主要挑战是识别每个源域和目标域之间的公共标签集,并随着源域数量的增加保持模型可伸缩。为了解决这些挑战,我们提出了一种通用的多源自适应网络UMAN,以解决域自适应问题,而不会增加各种UMDA设置中模型的复杂性。在UMAN中,我们通过预测余量来估计公共标签集中每个已知类的可靠性,这有助于进行对抗训练,以更好地对齐公共标签集中多个源域和目标域的分布。此外,还为UMAN提供了理论保证。大量的实验结果表明,现有的UDA和多源DA MDA方法无法直接应用于UMDA,并且所提出的UMAN在各种UMDA设置下均达到了最先进的性能。 |
| Improved Algorithm for Seamlessly Creating Infinite Loops from a Video Clip, while Preserving Variety in Textures Authors Kunjal Panchal 该项目实现了Szeliski的论文Video Textures。目的是创建一个动态图片,或者我们通常称为它的GIF,它位于照片和视频之间。想法是输入具有重复运动纹理的视频,例如挥舞旗帜,下雨或点燃烛火。输出是一个新视频,它以无缝方式无限扩展原始视频。实际上,输出并不是真正无限的,而是使用视频播放器循环播放,并且足够长,以至于永远不会重复。 |
| Learning and Evaluating Representations for Deep One-class Classification Authors Kihyuk Sohn, Chun Liang Li, Jinsung Yoon, Minho Jin, Tomas Pfister 我们为深度一类分类提出了一个两阶段框架。我们首先从一个类别数据中学习自我监督的表示形式,然后在学习的表示形式上构建一个类别分类器。该框架不仅可以学习更好的表示形式,还可以构建忠实于目标任务的一类分类器。特别是,我们提出了一种新颖的分布增强的对比学习方法,该方法通过数据增强扩展了训练分布,从而阻碍了对比表示的一致性。此外,我们认为在生成或区分模型中受统计角度启发的分类器比现有方法更有效,例如来自替代分类器的正态性得分的平均值。在实验中,我们在视觉域一类分类基准上展示了最新的性能。最后,我们提出视觉上的解释,确认我们的深层分类器的决策过程对人类而言是直观的。该代码位于 |
| Multi-layer Feature Aggregation for Deep Scene Parsing Models Authors Litao Yu, Yongsheng Gao, Jun Zhou, Jian Zhang, Qiang Wu 从图像进行场景解析是视觉内容理解中的一个基本但具有挑战性的问题。在这种密集的预测任务中,解析模型将每个像素分配给分类标签,这需要相邻图像补丁的上下文信息。因此,这项学习任务面临的挑战是同时描述对象或场景的几何和语义特性。在本文中,我们通过设计一种新颖的特征聚合模块来事先生成适当的全局表示,以提高特征的判别能力,来探索有效地利用深度解析网络的多层特征输出来实现空间语义一致性。所提出的模块可以自动选择中间视觉特征以使空间和语义信息相关。同时,多个跳过连接形成强大的监控,使深度解析网络易于训练。在四个公共场景解析数据集上的大量实验证明,配备了所提出的特征聚合模块的深度解析网络可以取得非常有希望的结果。 |
| DUDE: Deep Unsigned Distance Embeddings for Hi-Fidelity Representation of Complex 3D Surfaces Authors Rahul Venkatesh, Sarthak Sharma, Aurobrata Ghosh, Laszlo Jeni, Maneesh Singh 具有任意拓扑的形状的高保真度表示是各种视觉和图形应用程序中的重要问题。由于分辨率有限,当在这些应用程序中使用点云,体素和网格进行经典离散形状表示时,会产生低质量的结果。已经提出了几种使用深度神经网络的隐式3D形状表示方法,从而显着提高了表示质量以及对下游应用程序的影响。但是,这些方法只能用于表示拓扑上封闭的形状,这极大地限制了它们可以表示的形状类别。结果,它们通常还需要干净,水密的网眼进行训练。在这项工作中,我们提出了DUDE深度无符号距离嵌入方法,该方法可以缓解这两个缺点。 DUDE是一种纠缠的形状表示,它使用无符号距离场uDF表示与曲面的接近度,并使用法向矢量场nVF表示表面方向。我们表明,这两个uDF nVF的组合可用于学习任意开放闭合形状的高保真表示。与诸如DeepSDF之类的先前工作相反,我们的形状表示可以直接从嘈杂的三角汤中学习,并且不需要水密网格。此外,我们提出了从学习的表示中提取和渲染等值面的新颖算法。我们在基准3D数据集上对DUDE进行了验证,并证明了DUDE与现有技术相比有了显着改进。 |
| Uncertainty-Aware Voxel based 3D Object Detection and Tracking with von-Mises Loss Authors Yuanxin Zhong, Minghan Zhu, Huei Peng 对象检测和跟踪是自治的关键任务。具体而言,3D对象检测和跟踪最近已成为新兴的热门话题。尽管已经提出了用于物体检测的各种方法,但是很少探索3D检测和跟踪任务中的不确定性。不确定性有助于我们解决感知系统中的错误并提高鲁棒性。在本文中,我们提出了一种通过向SECOND检测器添加不确定性回归来提高目标跟踪性能的方法,SECOND检测器是3D对象检测的最具代表性的算法之一。我们的方法使用高斯负对数似然法NLL损失估算位置和尺寸不确定性,并引入von Mises NLL损失进行角度不确定性估算。我们将不确定性输出输入到经典的对象跟踪框架中,并证明了与采用恒定协方差假设的香草跟踪器相比,我们的方法提高了跟踪性能。 |
| Mutual Modality Learning for Video Action Classification Authors Stepan Komkov, Maksim Dzabraev, Aleksandr Petiushko 视频动作分类模型的构建进展迅速。但是,通过与在不同模式下训练的相同模型进行集成,仍可以轻松地提高这些模型的性能。光流。不幸的是,在推理过程中使用几种模态在计算上是昂贵的。最近的工作研究了将多模式优势集成到单个RGB模型中的方法。但是,仍有改进的空间。在本文中,我们探索了将集成能力嵌入单个模型的各种方法。我们表明正确的初始化以及相互模态学习可以增强单个模态模型。结果,我们在Something Something v2基准测试中获得了最先进的结果。 |
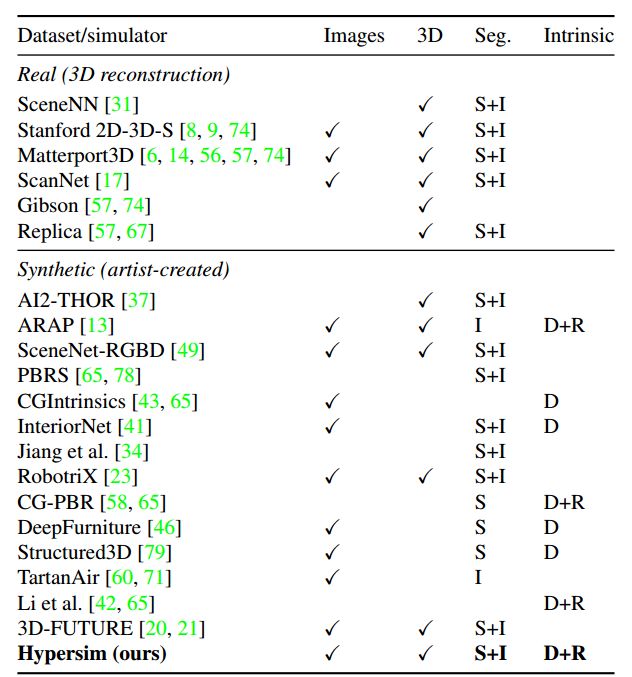
| Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding Authors Mike Roberts, Nathan Paczan 对于许多基本的场景理解任务,很难或不可能从真实图像中获得每个像素的地面真相标签。我们通过引入Hypersim(一种用于整体室内场景理解的逼真的合成数据集)来应对这一挑战。为了创建我们的数据集,我们利用了由专业艺术家创建的合成场景的大型存储库,并且生成了461个室内场景的77,400张图像,每个像素标签都带有详细的标签以及相应的地面真实几何形状。我们的数据集1仅依赖于公共可用的3D资产2包含完整的场景几何图形,材质信息和每个场景的照明信息3包括每个图像的密集的每像素语义实例分割,以及每个图像的4个因素,包括漫反射,漫反射和捕获视图相关照明效果的非漫射残差项。这些功能一起使我们的数据集非常适合需要直接3D监督的几何学习问题,需要在多个输入和输出模态上共同进行推理的多任务学习问题以及逆渲染问题。我们在场景,对象和像素级别分析数据集,并在金钱,注释工作量和计算时间方面分析成本。值得注意的是,我们发现有可能从头开始生成整个数据集,而花费的时间大约是训练最先进的自然语言处理模型所需的一半。我们用于生成数据集的所有代码都将在线提供。 |
| Physics-Informed Neural Network Super Resolution for Advection-Diffusion Models Authors Chulin Wang, Eloisa Bentivegna, Wang Zhou, Levente Klein, Bruce Elmegreen 物理信息神经网络NN是一种新兴技术,可提高空间分辨率并增强物理模型或卫星观测数据的物理一致性。在大气污染羽流的对流扩散模型中,探索了一种超分辨率SR技术从低分辨率图像重建4倍高分辨率图像。当对流扩散方程式除了传统的基于像素的约束条件之外还约束NN时,通常会提高SR性能。通过从模拟中随机删除图像像素并允许系统学习丢失数据的内容,研究了SR技术还可以重建丢失数据的能力。当在SR中包含40个像素损失的物理方程式时,可以证明S N的改进为11。与标准SR方法相比,物理通知的NN可以准确地重建损坏的图像并产生更好的结果。 |
| Monitoring the Impact of Wildfires on Tree Species with Deep Learning Authors Wang Zhou, Levente Klein 气候变化的影响之一是,在传统上被某些树种覆盖的地区发生野火后,树木难以再生。在这里,定制了深度学习模型,以根据野火前后的四波段航拍对土地覆盖物进行分类,以研究野火对树木物种造成的长期后果。这些树种标签是从人工划定的地图中生成的,这些地图包括针叶树,硬木,灌木,重新造林的树木和荒芜的五种土地覆盖类别。该模型在测试拆分上的准确度为92,适用于2009年至2018年的三个野火数据。该模型准确地描绘了因野火损坏,树木种类变化和燃烧区域反弹的区域。结果表明,有明显的野火影响当地生态系统的证据,概述的方法可以帮助监测重新造林的地区,观察森林组成的变化并跟踪野火对树木的影响。 |
| Deep-Dup: An Adversarial Weight Duplication Attack Framework to Crush Deep Neural Network in Multi-Tenant FPGA Authors Adnan Siraj Rakin, Yukui Luo, Xiaolin Xu, Deliang Fan 深度可编程神经网络DNN在高性能云计算平台中的广泛部署已经成为现场可编程门阵列FPGA的首选,因为它具有硬件重新编程的灵活性,可以作为提高性能的加速器。为了提高硬件资源利用的效率,已经在FPGA虚拟化方面投入了越来越多的精力,以使多个独立的租户并存于一个共享的FPGA芯片中。这种用于DNN加速的多租户FPGA设置可能会在恶意用户的严重威胁下暴露DNN干扰任务。据我们所知,这项工作是第一个探索多租户FPGA中DNN模型漏洞的工具。我们提出了一种新颖的对抗攻击框架Deep Dup,在该框架中,对抗租户可以向FPGA中的受害租户的DNN模型注入错误。具体来说,她可以使用恶意的电源掠夺电路使FPGA的共享电源分配系统大量过载,实现对抗性权重复制AWD硬件攻击,该攻击在芯片外存储器和片内缓冲器之间的数据传输期间复制某些DNN权重数据包,目的是劫持DNN受害人租户的职能。此外,为了确定给定恶意目标的最易受攻击的DNN权重包,我们提出了一种通用的易受攻击的权重包搜索算法,称为渐进差分进化搜索P DES,这是首次适用于深度学习白盒和黑匣子攻击模型。与仅在深度学习白盒设置中工作的先前工作不同,我们的适应性主要来自于以下事实:所提出的P DES不需要DNN模型的任何梯度信息。 |
| Conflicting Bundles: Adapting Architectures Towards the Improved Training of Deep Neural Networks Authors David Peer, Sebastian Stabinger, Antonio Rodriguez Sanchez 设计神经网络体系结构是一项艰巨的任务,知道必须对模型的哪些特定层进行修改以提高性能几乎是个谜。在本文中,我们引入了一种新颖的理论和度量来识别降低训练模型的测试准确性的层,这种识别最早在训练开始时就完成了。在最坏的情况下,这种层可能会导致根本无法训练的网络。更准确地说,我们发现了那些使性能恶化的层次,因为它们在我们新颖的理论分析中显示了相冲突的训练束,并辅之以广泛的实证研究。基于这些发现,引入了一种新颖的算法来自动去除性能下降层。与最先进的体系结构相比,通过该算法发现的体系结构具有竞争优势。在保持如此高的准确性的同时,我们的方法极大地减少了不同计算机视觉任务的内存消耗和推理时间。 |
| Imagining Grounded Conceptual Representations from Perceptual Information in Situated Guessing Games Authors Alessandro Suglia, Antonio Vergari, Ioannis Konstas, Yonatan Bisk, Emanuele Bastianelli, Andrea Vanzo, Oliver Lemon 在视觉猜谜游戏中,猜测者必须通过向Oracle提问来识别场景中的目标对象。对于玩家来说,一种有效的策略是学习具有区分性和表达力的对象的概念表示,以足以提出问题和正确猜测。但是,如Suglia等人所示。 2020年,现有模型无法学习真正的多模态表示,而是在训练和推理时都依赖于场景对象的黄金类别标签。当推理时的类别与训练时的类别匹配时,这提供了不自然的性能优势,并且在涉及域外对象类别的更现实的零击场景中导致模型失败。为了克服这个问题,我们引入了一个基于正则化自动编码器的新颖的想象力模块,该模块学习上下文感知和类别感知的潜在嵌入,而无需在推理时依赖类别标签。我们的想象力模块在CompGuessWhat零射击场景中达到8.26的游戏玩法准确性优于最先进的竞争对手Suglia等人(2020年),并且在没有可用的黄金类别时,在GuessWhat基准中将Oracle和Guesser的准确性提高了2.08和12.86。推理时间。想象力模块还增强了有关对象属性和属性的推理。 |
| Improving Robotic Grasping on Monocular Images Via Multi-Task Learning and Positional Loss Authors William Prew, Toby Breckon, Magnus Bordewich, Ulrik Beierholm 在本文中,我们介绍了从端到端CNN架构中的单眼彩色图像提高实时对象抓取性能的两种方法。首先是在模型训练多任务学习过程中添加辅助任务。当执行补充深度重建任务时,我们的多任务CNN模型将大型提花抓取数据集的抓取性能从基线平均值从72.04提高到78.14。第二种是引入位置损失函数,该函数强调仅在可以成功抓取的对象点上的辅助参数抓取器角度和宽度的每像素损失。这将性能从基准平均值72.04提高到78.92,并减少了所需的训练时期。这些方法还可以串联执行,从而在保持足够的推理速度以提供实时抓取处理的同时,将性能进一步提高到79.12。 |
| A Two-Stage Cascade Model with Variational Autoencoders and Attention Gates for MRI Brain Tumor Segmentation Authors Chenggang Lyu, Hai Shu MRI脑肿瘤的自动分割对疾病的诊断,监测和治疗计划至关重要。在本文中,我们提出了一种基于两阶段编码器解码器的脑肿瘤亚区域分割模型。在两个阶段中都使用了可变自动编码器正则化来防止过拟合问题。第二阶段网络采用注意门,并使用由第一阶段输出形成的扩展数据集进行额外培训。在BraTS 2020验证数据集上,针对整个肿瘤,肿瘤核心和增强型肿瘤,该方法的Dice平均得分分别为0.9041、0.8350和0.7958,Hausdorff距离95为4.953、6.299和23.608。在BraTS 2020测试数据集上,Dice得分的对应结果为0.8729、0.8357和0.8205,Hausdorff距离的对应结果为11.4288、19.9690和15.6711。 |
| Covariance Self-Attention Dual Path UNet for Rectal Tumor Segmentation Authors Haijun Gao, Bochuan Zheng, Dazhi Pan, Xiangyin Zeng 对于直肠肿瘤分割,深度学习算法更可取。但是,通过使用深度学习方法来准确地分割和识别直肠肿瘤的位置和大小仍然是一项艰巨的任务。为了提高提取足够的特征信息进行直肠肿瘤分割的能力,我们提出了一种协方差自注意双路径UNet CSA DPUNet。拟议的网络主要包括对UNet的两项改进1修改UNet,只有一个路径结构由两个收缩路径和两个扩展路径组成,作为DPUNet,可以帮助从CT图像中提取更多特征信息2采用criss cross self注意模块加入DPUNet中,同时用协方差运算代替了相关运算的原始计算方法,可以进一步增强DPUNet的表征能力,提高直肠肿瘤的分割精度。实验表明,与当前的最新结果相比,CSA DPUNet分别使Dice系数P,R,F1分别提高了15.31、7.2、11.8和9.5,这表明我们提出的CSA DPUNet对于直肠肿瘤分割是有效的。 |
| DR-Unet104 for Multimodal MRI brain tumor segmentation Authors Jordan Colman, Lei Zhang, Wenting Duan, Xujiong Ye 在本文中,我们提出了具有104个卷积层DR Unet104的二维深层残留Unet,用于脑MRI中的病变分割。我们对Unet架构进行了多次添加,包括将瓶颈残差块添加到Unet编码器,并在每个卷积块堆栈之后添加dropout。我们验证了采用小比率(例如,在体系结构上为0.2时,发现0.2的下降比没有下降或0.5的下降改善了总体性能。我们在多模式脑肿瘤分割BraTS 2020挑战赛中评估了拟议的架构,并将我们的方法与带有ResNet V2 152骨干的DeepLabV3进行了比较。我们发现DR Unet104分别获得了验证数据,整个肿瘤,增强的肿瘤和肿瘤核心的平均骰子得分系数,分别为0.8862、0.6756和0.6721,DeepLabV3对0.8770、0.65242和0.68134进行了总体改善。我们的方法在整个肿瘤上产生的最终平均DSC为0.8673、0.7514和0.7983,根据挑战测试数据可以增强肿瘤和肿瘤核心。我们将其作为最先进的2D病变分割体系结构提出,该体系结构可用于比3D体系结构更低功耗的计算机上。这项工作的源代码和经过训练的模型可以在以下位置公开获得 |
| Intriguing Properties of Contrastive Losses Authors Ting Chen, Lala Li 对比损失及其变体最近变得非常流行,用于在无监督的情况下学习视觉表示。在这项工作中,我们首先将基于交叉熵的标准对比损失推广到更广泛的损失家族,这些损失共享数学形式的L文本对齐方式Lambda数学形式的L文本分布的抽象形式,其中鼓励将隐藏表示形式在某些变换扩充下对齐1和2匹配高熵的先验分布。我们表明,在多层非线性投影头的存在下,广义损耗的各种实例化表现相似,并且在标准对比损耗中广泛使用的温度标度tau在与两个损耗项之间的权重λ反相关的范围内。然后,我们研究了共享的Acro增强视图中竞争特征之间的特征抑制现象,例如颜色分布与对象类。我们构建了具有显式且可控的竞争特征的数据集,并表明,对于对比学习而言,一些易于学习的共享特征可以抑制甚至完全阻止学习其他竞争特征集。有趣的是,基于重建损失的自动编码器中,此特性的危害要小得多。现有的对比学习方法严重依赖数据增强来支持某些功能集而不是其他功能集,而人们可能希望网络能够学习其能力所允许的所有竞争功能。 |
| A Multi-resolution Model for Histopathology Image Classification and Localization with Multiple Instance Learning Authors Jiayun Li, Wenyuan Li, Anthony Sisk, Huihui Ye, W. Dean Wallace, William Speier, Corey W. Arnold 组织病理学图像为疾病诊断提供了丰富的信息。大量的组织病理学图像已被数字化为高分辨率的完整幻灯片图像,这为开发计算图像分析工具提供了机会,以减少病理学家的工作量并潜在地改善内部和内部观察者的一致性。之前有关整个幻灯片图像分析的大多数工作都集中在对预先选定的小目标区域进行分类或分割,这需要细粒度的注释,并且对于大规模的整个幻灯片分析而言,扩展也不是一件容易的事。在本文中,我们提出了一种多分辨率多实例学习模型,该模型利用显着性图来检测可疑区域以进行细粒度等级预测。无需依赖昂贵的区域或像素级别注释,仅使用幻灯片级别标签即可端对端地训练我们的模型。该模型是在大规模前列腺活检数据集上开发的,该数据集包含来自830位患者的20,229张载玻片。该模型实现了92.7的准确度,良性,低级(即1级组)和高等级(即2级组)预测的Cohen s Kappa为81.8,在接收器工作特性曲线AUROC下的面积为98.2,以及区分恶性和恶性的平均精度AP为97.4。良性幻灯片。该模型在外部数据集上用于癌症检测的AUROC为99.4,AP为99.8。 |
| Compositional Scalable Object SLAM Authors Akash Sharma, Wei Dong, Michael Kaess 我们提出了一种快速,可扩展且准确的同时定位和制图SLAM系统,该系统将室内场景表示为对象的图形。充分利用人工环境由可识别对象构成和占据的观察结果,我们表明,可伸缩的对象映射组成公式适合用于无漂移大规模室内重建的强大SLAM解决方案。为实现此目的,我们提出了一种新颖的语义辅助数据关联策略,该策略可获取明确的持久对象界标,以及2.5D合成渲染方法,该方法使可靠的帧能够建模RGB D跟踪。因此,我们提供了一种优化的在线实施方案,该方案可以使用单个图形卡以接近帧速率的速度运行,并针对最新的基准水平进行全面评估。将在https占位符处提供开源实现。 |
| Learning a Decentralized Multi-arm Motion Planner Authors Huy Ha, Jingxi Xu, Shuran Song 我们提出了一种闭环多臂运动计划器,该计划器可以随着团队规模的扩展而灵活。传统的多臂机器人系统依赖于集中式运动计划器,其运行时间通常随团队规模成指数增长,因此无法通过开环控制来处理动态环境。在本文中,我们通过多主体强化学习解决了这个问题,在该模型中,通过观察分散的策略来控制多臂系统中的一个机器人手臂,从而在观察到其工作空间状态和目标末端执行器姿势的情况下达到其目标末端执行器姿势。该策略是使用Soft Actor Critic进行训练的,并具有基于采样的运动计划算法(即BiRRT)的专家演示。通过利用经典的规划算法,我们可以在保持神经网络快速推理时间的同时,提高强化学习算法的学习效率。最终的策略线性地扩展,可以部署在具有可变团队规模的多臂系统上。由于采用了闭环和分散式公式,我们的方法可以推广到5 10个多臂系统和动态移动目标,而对于10臂系统而言,成功率达到90,尽管只接受了带有静态目标的1 4臂计划任务的培训。可以在以下位置找到代码和数据链接 |
| DeepReg: a deep learning toolkit for medical image registration Authors Yunguan Fu, Nina Monta a Brown, Shaheer U. Saeed, Adri Casamitjana, Zachary M. C. Baum, R mi Delaunay, Qianye Yang, Alexander Grimwood, Zhe Min, Stefano B. Blumberg, Juan Eugenio Iglesias, Dean C. Barratt, Ester Bonmati, Daniel C. Alexander, Matthew J. Clarkson, Tom Vercauteren, Yipeng Hu DeepReg |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com