90 矩阵——矩阵微分与求导
文章目录
-
- 1 求导定义与布局方式
-
- 1.1 矩阵求导术
- 1.2 分子布局和分母布局
- 2 标量对矩阵的求导术的基本思想
-
- 2.2 微分法
- 2.3 迹技巧
- 2.4 迹函数对向量或矩阵的求导
- 3、矩阵对矩阵求导
-
- 3.1 微分技巧
- 3.2 Kronecker积技巧
- 参考
矩阵线性代数笔记整理汇总,超全面
本文符号定义
- x : x: x: 标量
- x \mathrm{x} x 或者 x : n \boldsymbol{x}: \mathrm{n} x:n 维向量
- X : m × n X: m \times n X:m×n 维的矩阵
- y : y: y: 标量
- y \mathrm{y} y 或者 y : m \boldsymbol{y}: \mathrm{m} y:m 维向量
- Y Y Y : p × q : p \times q :p×q 维的矩阵
1 求导定义与布局方式
1.1 矩阵求导术
根据求导的自变量和因变量是标量,向量还是矩阵,我们有9种可能的矩阵求导定义,如下:
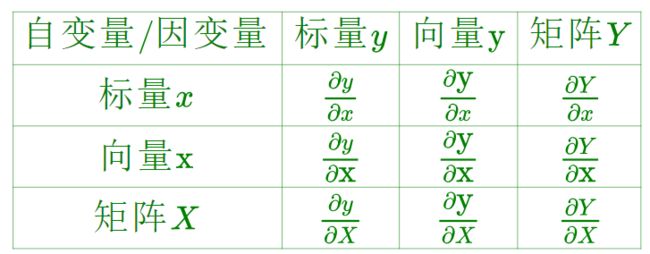
1.2 分子布局和分母布局
依旧使用一个m维向量 y \mathrm{y} y 对标量 x x x 的求导,结果也是个 m m m维向量 ∂ y ∂ x \frac{\partial\mathrm{y}}{\partial x} ∂x∂y 来举例,我们很确定 ∂ y ∂ x \frac{\partial \mathrm{y}}{\partial x} ∂x∂y 是一个 m m m维向量,可问题是:它究竟应该表示成行向量,还是表示成列向量呢?
答案是:都可以。求导的本质是把导数信息,即求导的结果排列起来,至于是按行排列还是按列排列都是可以的。但是这样也有问题,在我们机器学习算法法优化过程中,如果行向量或者列向量随便写,那么结果就不唯一,所以为了解决这个问题,我们引入求导布局的概念。
- 分子布局:导数的维度以分子为主。
- 分母布局:导数的维度以分母为主。
向量对标量求导(表第2项):
比如上面的 ∂ y ∂ x \frac{\partial\mathrm{y}}{\partial x} ∂x∂y (单独提到 x \mathrm x x 或者 y \mathrm y y 均按照列向量讨论),如果按照分子布局,结果就会是 m m m维列向量,与分子维度一致。如果按照分母布局,结果就会是 m m m维行向量。
标量对向量求导(表第4项):
比如 ∂ y ∂ x \frac{\partial\mathrm{y}}{\partial x} ∂x∂y ,注意这次自变量是列向量,因变量是标量了。如果按照分子布局,结果就会是** m m m维行向量**。如果按照分母布局,结果就会是 m m m维列向量,与分母维度一致。
标量对矩阵求导(表第7项):
比如,标量 y y y 对矩阵 X X X 求导,那么如果按分母布局,则求导结果的维度和矩阵 X X X 的维度 m × n m \times n m×n 是一致的。如果是分子布局, 则求导结果的维度为 n × m n \times m n×m.
矩阵对标量求导(表第3项) :
比如, 矩阵 Y Y Y 对标量 x x x 求导,那么如果按分子布局, 则求导结果的维度和矩阵 Y Y Y 的维度 p × q p \times q p×q 是一致的。如果是分母布局, 则求导结果的维度为 q × p q \times p q×p 。
向量对向量求导(表第5项):
比如, m m m 维的向量 y \mathrm{y} y 对 n n n 维的向量 x \mathrm{x} x 求导, 一共有 m n m n mn 个标量对标量的求导。求导的结果 一般是排列为一个矩阵。那么如果按分子布局,则结果矩阵的第一个维度以分子为准, m m m, 即结果是个 m × n m \times n m×n 维的矩阵:
∂ y ∂ x = ( ∂ y 1 ∂ x 1 ∂ y 1 ∂ x 2 ⋯ ∂ y 1 ∂ x n ∂ y 2 ∂ x 1 ∂ y 2 ∂ x 2 ⋯ ∂ y 2 ∂ x n ⋮ ⋮ ⋯ ⋮ ∂ y m ∂ x 1 ∂ y m ∂ x 2 ⋯ ∂ y m ∂ x n ) \large \color{green}{\frac{\partial \mathrm y}{\partial \mathrm x}= \begin{pmatrix} \frac{\partial y_1}{\partial x_1} &\frac{\partial y_1}{\partial x_2} &\cdots &\frac{\partial y_1}{\partial x_n} \\ \frac{\partial y_2}{\partial x_1} &\frac{\partial y_2}{\partial x_2} &\cdots &\frac{\partial y_2}{\partial x_n} \\ \vdots& \vdots & \cdots & \vdots \\ \frac{\partial y_m}{\partial x_1} &\frac{\partial y_m}{\partial x_2} &\cdots &\frac{\partial y_m}{\partial x_n} \end{pmatrix}} ∂x∂y=⎝⎜⎜⎜⎜⎜⎛∂x1∂y1∂x1∂y2⋮∂x1∂ym∂x2∂y1∂x2∂y2⋮∂x2∂ym⋯⋯⋯⋯∂xn∂y1∂xn∂y2⋮∂xn∂ym⎠⎟⎟⎟⎟⎟⎞
如果按分母布局,则结果矩阵的第一个维度以分母为准, n n n,即结果是个
∂ y ∂ x = ( ∂ y 1 ∂ x 1 ∂ y 2 ∂ x 1 ⋯ ∂ y m ∂ x 1 ∂ y 1 ∂ x 2 ∂ y 2 ∂ x 2 ⋯ ∂ y m ∂ x 2 ⋮ ⋮ ⋯ ⋮ ∂ y 1 ∂ x n ∂ y 2 ∂ x n ⋯ ∂ y m ∂ x n ) \large \color{green}{ \frac{\partial \mathrm y}{\partial \mathrm x}= \begin{pmatrix} \frac{\partial y_1}{\partial x_1} &\frac{\partial y_2}{\partial x_1} &\cdots &\frac{\partial y_m}{\partial x_1} \\ \frac{\partial y_1}{\partial x_2} &\frac{\partial y_2}{\partial x_2} &\cdots &\frac{\partial y_m}{\partial x_2} \\ \vdots& \vdots & \cdots & \vdots \\ \frac{\partial y_1}{\partial x_n} &\frac{\partial y_2}{\partial x_n} &\cdots &\frac{\partial y_m}{\partial x_n} \end{pmatrix} } ∂x∂y=⎝⎜⎜⎜⎜⎜⎛∂x1∂y1∂x2∂y1⋮∂xn∂y1∂x1∂y2∂x2∂y2⋮∂xn∂y2⋯⋯⋯⋯∂x1∂ym∂x2∂ym⋮∂xn∂ym⎠⎟⎟⎟⎟⎟⎞
结论:分子布局和分母布局的结果相差一个转置。
在机器学习的算法推导里,通常遵循以下布局的规范:
- 如果向量或者矩阵对标量求导,则以分子布局为准。
- 如果标量对向量或者矩阵求导,则以分母布局为准。
- 对于向量对对向量求导,有些分歧,一般以分子布局的雅克比矩阵为主。
总结如下:
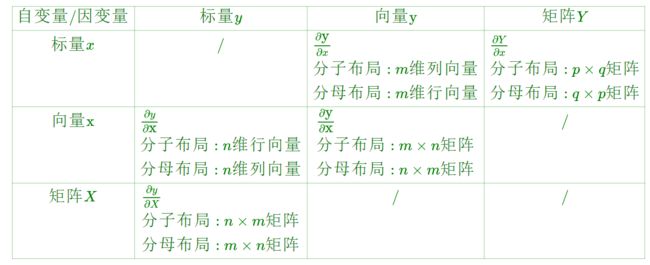
2 标量对矩阵的求导术的基本思想
在进行标量对矩阵的求导时我们默认按照分母布局,即求导的结果与矩阵的维度一致。比如 y = a T X b y=\mathrm{a}^{T} X \mathrm{~b} y=aTX b, 其中 y y y 是标量, a \mathrm{a} a 是 m m m维向量, b \mathrm{b} b 是 n n n维向量, X X X 是 m × n m \times n m×n 维的矩阵。
如果求 ∂ y ∂ X \frac{\partial y}{\partial X} ∂X∂y, 则结果是也应当是 m × n m \times n m×n 维的矩阵。这个矩阵里面的每一个元素应该是标量 y y y 对 X X X 里面的每个元素 X i j X_{i j} Xij 的导数。因为结果是分母布局,所以:
∂ y ∂ X ∣ i j = ∂ y ∂ X i j = ∂ a T X b ∂ X i j = ∂ a i X i j b j ∂ X i j = a i b j \large \color{green}{ \frac{\partial y}{\partial X}\Bigg|_{ij}=\frac{\partial y}{\partial X_{ij}}=\frac{\partial \mathrm a^TX\mathrm b}{\partial X_{ij}}=\frac{\partial \mathrm a_{i}X_{ij}\mathrm b_j}{\partial X_{ij}}=a_ib_j } ∂X∂y∣∣∣∣∣ij=∂Xij∂y=∂Xij∂aTXb=∂Xij∂aiXijbj=aibj
所以最后的结果应该长成这个样子:
∂ y ∂ X = ( a 1 b 1 a 1 b 2 a 1 b n a 2 b 1 a 2 b 2 a 2 b n ⋮ ⋮ ⋯ a m b 1 a m b 2 a m b n ) = a b T \large \color{green}{\frac{\partial y}{\partial X}= \begin{pmatrix} a_1b_1 &a_1b_2 &a_1b_n \\ a_2b_1 &a_2b_2 &a_2b_n \\ \vdots& \vdots & \cdots & \\ a_mb_1 &a_mb_2 &a_mb_n \end{pmatrix} =ab^T } ∂X∂y=⎝⎜⎜⎜⎜⎛a1b1a2b1⋮amb1a1b2a2b2⋮amb2a1bna2bn⋯ambn⎠⎟⎟⎟⎟⎞=abT
是 m × n m\times n m×n 维的矩阵。
当然,上面的做法相当于是硬生生把标量对矩阵的求导拆成了一堆标量对标量的求导,再把这些结果按照分母布局给组合了起来。这种方法可以称为定义法,但是它只适用于表达式不复杂,你能展开的情况。就像上面的
y = a T X b = a 1 X 11 b 1 + a 1 X 12 b 2 + ⋅ ⋅ ⋅ + a m X m n b n \large \color{green}{y=\mathrm a^TX\mathrm b=a_1X_{11}b_1+a_1X_{12}b_2+\cdot\cdot\cdot+a_mX_{mn}b_n} y=aTXb=a1X11b1+a1X12b2+⋅⋅⋅+amXmnbn
但如果表达式很复杂,你没法展开成分量的形式,那就没法转化成标量对标量的求导,这种方法就不再适用了。定义法所遵循的逐元素求导破坏了整体性。求导时不宜拆开矩阵,而是要找一个从整体出发的算法。即下面的微分法。
2.2 微分法
-
在数学分析的一元微积分中,导数(标量对标量的导数)与微分有联系:
-
d f = f ′ ( x ) d x \large \color{green}{df = f'(x)dx} df=f′(x)dx
-
在多元微积分中,梯度(标量对向量的导数)也与微分有联系:
-
d f = ∑ i = 1 n ∂ f ∂ x i d x i = ∂ f ∂ x T d x \large \color{green}{df = \sum_{i=1}^n \frac{\partial f}{\partial x_i}dx_i = \frac{\partial f}{\partial \boldsymbol{x}}^T d\boldsymbol{x}} df=i=1∑n∂xi∂fdxi=∂x∂fTdx
这里第一个等号是全微分公式,第二个等号表达了梯度与微分的联系。
全微分 d f d f df 是梯度向量 ∂ f ∂ x ( n × 1 ) \frac{\partial f}{\partial \boldsymbol{x}}(n \times 1) ∂x∂f(n×1) 与微分向量 d x ( n × 1 ) d \boldsymbol{x}(n \times 1) dx(n×1) 的内积; 受此启发,我们将矩阵导数与微分建立联系。在这之前要先了解一个关于矩阵迹的性质:
对尺寸相同的矩阵 A , B , tr ( A T B ) = ∑ i , j A i j B i j A, B, \operatorname{tr}\left(A^{T} B\right)=\sum_{i, j} A_{i j} B_{i j} A,B,tr(ATB)=∑i,jAijBij, 即 tr ( A T B ) \operatorname{tr}\left(A^{T} B\right) tr(ATB) 是矩阵 A A A, B B B 的内积。
- 把多元微积分中的梯度与微分之间的联系扩展到矩阵, 则有:
d f = ∑ i = 1 m ∑ j = 1 n ∂ f ∂ X i j d X i j = tr ( ∂ f T ∂ X d X ) \large \color{green}{d f=\sum_{i=1}^{m} \sum_{j=1}^{n} \frac{\partial f}{\partial X_{i j}} d X_{i j}=\operatorname{tr}\left(\frac{\partial f^{T}}{\partial X} d X\right)} df=i=1∑mj=1∑n∂Xij∂fdXij=tr(∂X∂fTdX)
其中tr代表迹(trace)是方阵对角线元素之和, 最后一步的变换是根据上面的矩阵迹的性质。
从上面矩阵微分的式子,我们可以看到矩阵微分和它的导数也有一个转置的关系, 不过在外面套了一个迹函数而已。由于标量的迹函数就是它本身,那么矩阵微分和向量微分可以统一表 示,即:
d f = tr ( ∂ f ∂ X T d X ) d f = ∂ f ∂ x T d x \large \color{green}{ df = \text{tr}\left(\frac{\partial f}{\partial X}^T dX\right) \\ df = \frac{\partial f}{\partial \boldsymbol{x}}^T d\boldsymbol{x} } df=tr(∂X∂fTdX)df=∂x∂fTdx
得到这2个式子的作用是什么?
答: 这2个式子里面的 ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f 和 ∂ f ∂ x \frac{\partial f}{\partial \boldsymbol{x}} ∂x∂f, 正是我们要求的标量对矩阵/向量的导数。
换句话说,假定题目给任意一个函数 f ( f\left(\right. f( 就比如说 f = a T X b ) \left.f=\boldsymbol{a}^{T} X \boldsymbol{b}\right) f=aTXb), 求它对于里面的某个矩阵 X X X 的导数。
我们只需要先想方设法搞出来 d f d f df, 那么再套上迹 t r \mathrm{tr} tr, 则 ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f 就可以得到了。
这就是微分法求对矩阵导数的基本思想, 算法如下:
Algorithms:
根据给定的 f f f 寻找 d f d f_{} df .
给 d f d f df 套上迹 t r ∘ \mathrm{tr}_{\circ} tr∘ 等号左边因为 d f d f df 是 个标量, 所以不受影响, 等号右边根据迹的技巧进行化简。
等号右边化简之后先找到 d X d X dX, 根据导数与微分的联素 d f = tr ( ∂ f ∂ X T d X ) df = \text{tr}\left(\frac{\partial f}{\partial X}^T dX\right) df=tr(∂X∂fTdX) 得到 ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f 。
根据上述Algorithms, 理论上对于任何求对矩阵导数的问题可以三步搞定。
但只有基本思想还远远不够,因为要搞出来 d f df df,你还需要掌握一些矩阵微分的操作,如下面常用的矩阵微分运算法则所示,这些法则更详细的解读可以参考张贤达的**《矩阵分析与应用》**。
常用的矩阵微分运算法则:
-
加减法:
d ( X ± Y ) = d X ± d Y \large \color{green}{d(X \pm Y)=d X \pm d Y} d(X±Y)=dX±dY -
矩阵乘法:
d ( X Y ) = ( d X ) Y + X d Y \large \color{green}{d(X Y)=(d X) Y+X d Y} d(XY)=(dX)Y+XdY -
转置:
d ( X T ) = ( d X ) T \large \color{green}{d\left(X^{T}\right)=(d X)^{T}} d(XT)=(dX)T -
迹:
d tr ( X ) = tr ( d X ) \large \color{green}{d \operatorname{tr}(X)=\operatorname{tr}(d X)} dtr(X)=tr(dX) -
逐元素乘法:
d ( X ⊙ Y ) = d X ⊙ Y + X ⊙ d Y \large \color{green}{d(X \odot Y)=d X \odot Y+X \odot d Y} d(X⊙Y)=dX⊙Y+X⊙dY⊙ \odot ⊙ 表示尺寸相同的矩阵 X , Y X, Y X,Y 逐元素相乘。
-
逆:
d X − 1 = − X − 1 d X X − 1 \large \color{green}{dX^{-1} = -X^{-1}dX X^{-1}} dX−1=−X−1dXX−1此式可在 X X − 1 = I X X^{-1}=I^{\text {}} XX−1=I 两侧求微分来证明。
-
行列式:
d ∣ X ∣ = tr ( X ∗ d X ) \large \color{green}{d|X| = \text{tr}(X^{*}dX)} d∣X∣=tr(X∗dX)其中 X ∗ X^{*} X∗表示 X X X的伴随矩阵,在 X X X 可逆时又可以写作
d ∣ X ∣ = ∣ X ∣ tr ( X − 1 d X ) \large \color{green}{d|X|= |X|\text{tr}(X^{-1}dX)} d∣X∣=∣X∣tr(X−1dX) -
逐元素函数:
d σ ( X ) = σ ′ ( X ) ⊙ d X \large \color{green}{d\sigma(X) = \sigma'(X)\odot dX} dσ(X)=σ′(X)⊙dX
σ ( X ) = [ σ ( X i j ) ] \sigma(X) = \left[\sigma(X_{ij})\right] σ(X)=[σ(Xij)]是逐元素标量函数运算, σ ′ ( X ) = [ σ ′ ( X i j ) ] \sigma'(X)=[\sigma'(X_{ij})] σ′(X)=[σ′(Xij)] 是逐元素求导数。
例如:
X = [ X 11 X 12 X 21 X 22 ] , d sin ( X ) = [ cos X 11 d X 11 cos X 12 d X 12 cos X 21 d X 21 cos X 22 d X 22 ] = cos ( X ) ⊙ d X \large \color{green}{X=\left[\begin{matrix}X_{11} & X_{12} \\ X_{21} & X_{22}\end{matrix}\right], d \sin(X) = \left[\begin{matrix}\cos X_{11} dX_{11} & \cos X_{12} d X_{12}\\ \cos X_{21} d X_{21}& \cos X_{22} dX_{22}\end{matrix}\right] = \cos(X)\odot dX} X=[X11X21X12X22],dsin(X)=[cosX11dX11cosX21dX21cosX12dX12cosX22dX22]=cos(X)⊙dX
2.3 迹技巧
除此之外,微分法求对矩阵导数的基本思想的很重要的一步是给 d f d f df 套上迹 t r \mathrm{tr} tr, 所以, 矩阵的迹技巧(trace trick)也非常重要, 下面列举一些:
-
标量的迹等于自己:
-
a = tr ( a ) \large \color{green}{a=\operatorname{tr}(a)} a=tr(a)
-
转置:
-
tr ( A T ) = tr ( A ) \large \color{green}{\operatorname{tr}\left(A^{T}\right)=\operatorname{tr}(A)} tr(AT)=tr(A)
-
线性:
-
tr ( A ± B ) = tr ( A ) ± tr ( B ) \large \color{green}{\operatorname{tr}(A \pm B)=\operatorname{tr}(A) \pm \operatorname{tr}(B)} tr(A±B)=tr(A)±tr(B)
-
交换律:
-
tr ( A B ) = tr ( B A ) \large \color{green}{\operatorname{tr}(A B)=\operatorname{tr}(B A)} tr(AB)=tr(BA)
-
其中 A A A 与 B T B^{T} BT 尺寸相同。两侧都等于 ∑ i , j A i j B j i \sum_{i, j} A_{i j} B_{j i} ∑i,jAijBji 。
-
矩阵乘法/逐元素乘法交换:
-
tr ( A T ( B ⊙ C ) ) = tr ( ( A ⊙ B ) T C ) \large \color{green}{\operatorname{tr}\left(A^{T}(B \odot C)\right)=\operatorname{tr}\left((A \odot B)^{T} C\right)} tr(AT(B⊙C))=tr((A⊙B)TC)
-
其中 A , B , C A, B, C A,B,C 尺寸相同。两侧都等于 ∑ i , j A i j B i j C i j \sum_{i, j} A_{i j} B_{i j} C_{i j} ∑i,jAijBijCij 。
以上就是微分法求对矩阵导数的方法,在实际操作时万不可随意套用微积分中标量导数的结论, 比如认为 A X A X AX 对 X X X 的导数为 A A A, 这是没有根据的。
下面举很经典的例子:
例 1 \Large\color{violet}{例1} 例1 f = a T X b f=\boldsymbol{a}^{T} X \boldsymbol{b} f=aTXb, 求 ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f 。其中 a \boldsymbol{a} a 是 m × 1 m \times 1 m×1 列向量, X X X 是 m × n m \times n m×n 矩阵, b \boldsymbol{b} b 是 n × 1 n \times 1 n×1 列向量, f f f 是标量。
解:根据上面的Algorithms:
- 先使用矩阵乘法法则求微分 d f : d f: df:
d f = d a T X b + a T d X b + a T X d b = a T d X b \large \color{green}{ df = d\boldsymbol{a}^TX\boldsymbol{b}+\boldsymbol{a}^TdX\boldsymbol{b}+\boldsymbol{a}^TXd\boldsymbol{b} = \boldsymbol{a}^TdX\boldsymbol{b}} df=daTXb+aTdXb+aTXdb=aTdXb
这里的 a , b \boldsymbol{a}, \boldsymbol{b} a,b 是常量, d a = 0 , d b = 0 d \boldsymbol{a}=\mathbf{0}, d \boldsymbol{b}=\mathbf{0} da=0,db=0, 故有:
d f = a T d X b \large \color{green}{df = \boldsymbol{a}^TdX\boldsymbol{b}} df=aTdXb
-
给 d f d f df 套上迹 t r tr tr:
d f = t r d f = tr ( a T d X b ) \large \color{green}{d f=\mathrm{tr} ~d f=\operatorname{tr}\left(\boldsymbol{a}^{T} d X \boldsymbol{b}\right)} df=tr df=tr(aTdXb) -
使用迹技巧做矩阵乘法交换。根据 tr ( A B ) = tr ( B A ) \operatorname{tr}(A B)=\operatorname{tr}(B A) tr(AB)=tr(BA) 有:
tr ( a T d X b ) = tr ( b a T d X ) = tr ( ( a b T ) T d X ) \large \color{green}{\operatorname{tr}\left(\boldsymbol{a}^{T} d X \boldsymbol{b}\right)=\operatorname{tr}\left(\boldsymbol{b} \boldsymbol{a}^{T} d X\right)=\operatorname{tr}\left(\left(\boldsymbol{a} \boldsymbol{b}^{T}\right)^{T} d X\right)} tr(aTdXb)=tr(baTdX)=tr((abT)TdX)
根据导数与微分的联系 d f = tr ( ∂ f ∂ X T d X ) df = \text{tr}\left(\frac{\partial f}{\partial X}^T dX\right) df=tr(∂X∂fTdX) 有:
∂ f ∂ X = a b T \large \color{green}{\frac{\partial f}{\partial X}=\boldsymbol{a} \boldsymbol{b}^{T}} ∂X∂f=abT
与一开始所用的定义法结果吻合。
例 2 \Large\color{violet}{例2} 例2 f = a T exp ( X b ) f=\boldsymbol{a}^{T} \exp (X \boldsymbol{b}) f=aTexp(Xb), 求 ∂ f ∂ X . \frac{\partial f}{\partial X} . ∂X∂f. 其中 a \boldsymbol{a} a 是 m × 1 m \times 1 m×1 列向量, X X X 是 m × n m \times n m×n 矩阵, b \boldsymbol{b} b 是 n × 1 n \times 1 n×1 列向量, exp \exp exp 表示逐元素求指数, f f f 是标量。
解:根据上面的Algorithms:
-
先使用矩阵乘法法则求微分 d f : d f: df:
d f = a T ( exp ( X b ) ⊙ ( d X b ) ) \large \color{green}{df = \boldsymbol{a}^T(\exp(X\boldsymbol{b})\odot (dX\boldsymbol{b}))} df=aT(exp(Xb)⊙(dXb)) -
给 d f d f df 套上迹 t r \mathrm{tr} tr :
d f = tr ( a T ( exp ( X b ) ⊙ ( d X b ) ) ) \large \color{green}{d f=\operatorname{tr}\left(\boldsymbol{a}^{T}(\exp (X \boldsymbol{b}) \odot(d X \boldsymbol{b}))\right)} df=tr(aT(exp(Xb)⊙(dXb))) -
使用迹技巧做矩阵乘法交换:
根据 tr ( A T ( B ⊙ C ) ) = tr ( ( A ⊙ B ) T C ) \operatorname{tr}\left(A^{T}(B \odot C)\right)=\operatorname{tr}\left((A \odot B)^{T} C\right) tr(AT(B⊙C))=tr((A⊙B)TC) 有:
d f = tr ( a T ( exp ( X b ) ⊙ ( d X b ) ) ) = tr ( ( a ⊙ exp ( X b ) ) T d X b ) = tr ( b ( a ⊙ exp ( X b ) ) T d X ) = tr ( ( ( a ⊙ exp ( X b ) ) b T ) T d X ) \large \color{green}{\begin{array}{ll} d f&=\operatorname{tr}\left(\boldsymbol{a}^{T}(\exp (X \boldsymbol{b}) \odot(d X \boldsymbol{b}))\right)=\operatorname{tr}\left((\boldsymbol{a} \odot \exp (X \boldsymbol{b}))^{T} d X \boldsymbol{b}\right)\\ &=\operatorname{tr}\left(\boldsymbol{b}(\boldsymbol{a} \odot \exp (X \boldsymbol{b}))^{T} d X\right)\\ &=\operatorname{tr}\left(\left((\boldsymbol{a} \odot \exp (X \boldsymbol{b})) \boldsymbol{b}^{T}\right)^{T} d X\right) \end{array}} df=tr(aT(exp(Xb)⊙(dXb)))=tr((a⊙exp(Xb))TdXb)=tr(b(a⊙exp(Xb))TdX)=tr(((a⊙exp(Xb))bT)TdX)
根据导数与微分的联系 d f = tr ( ∂ f T ∂ X d X ) d f=\operatorname{tr}\left(\frac{\partial f^{T}}{\partial X} d X\right) df=tr(∂X∂fTdX) 有:
∂ f ∂ X = ( a ⊙ exp ( X b ) ) b T \large \color{green}{\frac{\partial f}{\partial X}=(\boldsymbol{a} \odot \exp (X \boldsymbol{b})) \boldsymbol{b}^{T}} ∂X∂f=(a⊙exp(Xb))bT
例 3 \Large\color{violet}{例3} 例3 l = ∥ X w − y ∥ 2 l=\|X \boldsymbol{w}-\boldsymbol{y}\|^{2} l=∥Xw−y∥2, 求 w \boldsymbol{w} w 的最小二乘估计,即求 ∂ l ∂ w \frac{\partial l}{\partial \boldsymbol{w}} ∂w∂l 的零点。其中 y \boldsymbol{y} y 是 m × 1 m \times 1 m×1 列向量, X X X 是 m × n m \times n m×n 矩阵, w \boldsymbol{w} w 是 n × 1 n \times 1 n×1 列向量, l l l 是标量。
解:依然是求标量对向量的导数。首先解决这个向量模的平方的问题:
l = ∥ X w − y ∥ 2 = ( X w − y ) T ( X w − y ) \large \color{green}{l=\|X \boldsymbol{w}-\boldsymbol{y}\|^{2}=(X \boldsymbol{w}-\boldsymbol{y})^{T}(X \boldsymbol{w}-\boldsymbol{y})} l=∥Xw−y∥2=(Xw−y)T(Xw−y)
根据上面的Algorithms:
-
先使用矩阵衫法法则求微分 d l d l dl :
d l = ( X d w ) T ( X w − y ) + ( X w − y ) T ( X d w ) \large \color{green}{d l=(X \boldsymbol{d} \boldsymbol{w})^{T}(X \boldsymbol{w}-\boldsymbol{y})+(X \boldsymbol{w}-\boldsymbol{y})^{T}(X \boldsymbol{d} \boldsymbol{w})} dl=(Xdw)T(Xw−y)+(Xw−y)T(Xdw) -
给 d l d l dl 套上迹 tr:
d l = tr ( X d w ) T ( X w − y ) + ( X w − y ) T ( X d w ) = tr [ 2 ( X w − y ) T ( X d w ) ] \large \color{green}{\begin{array}{ll} dl &= \text{tr}(X\boldsymbol{dw})^T(X\boldsymbol{w}- \boldsymbol{y})+ (X\boldsymbol{w}- \boldsymbol{y})^T(X\boldsymbol{dw})\\ &=\operatorname{tr}\left[2(X \boldsymbol{w}-\boldsymbol{y})^{T}(X \boldsymbol{d} \boldsymbol{w})\right]\\ \end{array}} dl=tr(Xdw)T(Xw−y)+(Xw−y)T(Xdw)=tr[2(Xw−y)T(Xdw)]
根据导数与微分的联系 d l = tr ( ∂ l T ∂ w d w ) d l=\operatorname{tr}\left(\frac{\partial l^{T}}{\partial \boldsymbol{w}} d \boldsymbol{w}\right) dl=tr(∂w∂lTdw) 有:
∂ f ∂ w = 2 X T ( X w − y ) \large \color{green}{\frac{\partial f}{\partial \boldsymbol{w}}=2X^T(X\boldsymbol{w}- \boldsymbol{y})} ∂w∂f=2XT(Xw−y)
令 ∂ l ∂ w = 0 \frac{\partial l}{\partial \boldsymbol{w}}=\boldsymbol{0} ∂w∂l=0 ,有:
X T X w = X T y X^TX\boldsymbol{w} = X^T\boldsymbol{y} XTXw=XTy ,得到 w \boldsymbol{w} w 的最小二乘估计为 w = ( X T X ) − 1 X T y \boldsymbol{w} = (X^TX)^{-1}X^T\boldsymbol{y} w=(XTX)−1XTy
例 4 \Large\color{violet}{例4} 例4 样本 x 1 , … , x N ∼ N ( μ , Σ ) \boldsymbol{x}_{1}, \ldots, \boldsymbol{x}_{N} \sim \mathcal{N}(\boldsymbol{\mu}, \Sigma) x1,…,xN∼N(μ,Σ), 求方差 Σ \Sigma Σ 的最大似然估计。写成数学式是:
l = log ∣ Σ ∣ + 1 N ∑ i = 1 N ( x i − x ‾ ) T Σ − 1 ( x i − x ‾ ) \large \color{green}{l=\log |\Sigma|+\frac{1}{N} \sum_{i=1}^{N}\left(\boldsymbol{x}_{i}-\overline{\boldsymbol{x}}\right)^{T} \Sigma^{-1}\left(\boldsymbol{x}_{i}-\overline{\boldsymbol{x}}\right)} l=log∣Σ∣+N1i=1∑N(xi−x)TΣ−1(xi−x)
, 求 ∂ l ∂ Σ \frac{\partial l}{\partial \Sigma} ∂Σ∂l 的零点。其中 x i \boldsymbol{x}_{i} xi 是 m × 1 m \times 1 m×1 列向量, x ‾ = 1 N ∑ i = 1 N x i \overline{\boldsymbol{x}}=\frac{1}{N} \sum_{i=1}^{N} \boldsymbol{x}_{i} x=N1∑i=1Nxi 是样本均值, Σ \Sigma Σ 是 m × m m \times m m×m 对称正定矩阵, l l l 是标量, log \log log 表示自然对数。
解: 本题可以转化成求 ∂ l ∂ Σ \frac{\partial l }{\partial \Sigma} ∂Σ∂l 的问题。
根据上面的Algorithms:
- 先使用矩阵乘法法则求微分 d l d l dl :
但是要求出 d l d l dl 需要用到之前讲解的几个关于矩阵微分的性质:
逆: d X − 1 = − X − 1 d X X − 1 d X^{-1}=-X^{-1} d X X^{-1} dX−1=−X−1dXX−1 。 行列式: d ∣ X ∣ = tr ( X ∗ d X ) d|X|=\operatorname{tr}\left(X^{*} d X\right) d∣X∣=tr(X∗dX), d ∣ X ∣ = ∣ X ∣ tr ( X − 1 d X ) d|X|= |X|\text{tr}(X^{-1}dX) d∣X∣=∣X∣tr(X−1dX)
第1项:
d log ∣ Σ ∣ = ∣ Σ ∣ − 1 d ∣ Σ ∣ = ∣ Σ ∣ − 1 ∣ Σ ∣ tr ( Σ − 1 d Σ ) = tr ( Σ − 1 d Σ ) \large \color{green}{d \log |\Sigma|=|\Sigma|^{-1} d|\Sigma|=|\Sigma|^{-1}|\Sigma| \operatorname{tr}\left(\Sigma^{-1} d \Sigma\right)=\operatorname{tr}\left(\Sigma^{-1} d \Sigma\right)} dlog∣Σ∣=∣Σ∣−1d∣Σ∣=∣Σ∣−1∣Σ∣tr(Σ−1dΣ)=tr(Σ−1dΣ)
第2项:
1 N ∑ i = 1 N ( x i − x ˉ ) T d Σ − 1 ( x i − x ˉ ) = − 1 N ∑ i = 1 N ( x i − x ˉ ) T Σ − 1 d Σ Σ − 1 ( x i − x ˉ ) \large \color{green}{\frac{1}{N}\sum_{i=1}^N(\boldsymbol{x}_i-\boldsymbol{\bar{x}})^Td\Sigma^{-1}(\boldsymbol{x}_i-\boldsymbol{\bar{x}}) = -\frac{1}{N}\sum_{i=1}^N(\boldsymbol{x}_i-\boldsymbol{\bar{x}})^T\Sigma^{-1}d\Sigma\Sigma^{-1}(\boldsymbol{x}_i-\boldsymbol{\bar{x}})} N1i=1∑N(xi−xˉ)TdΣ−1(xi−xˉ)=−N1i=1∑N(xi−xˉ)TΣ−1dΣΣ−1(xi−xˉ)
-
再给第二项套上迹 tr \text{tr} tr :
tr ( 1 N ∑ i = 1 N ( x i − x ˉ ) T Σ − 1 d Σ Σ − 1 ( x i − x ˉ ) ) = 1 N ∑ i = 1 N ( tr ( x i − x ˉ ) T Σ − 1 d Σ Σ − 1 ( x i − x ˉ ) ) = 1 N ∑ i = 1 N ( tr ( Σ − 1 ( x i − x ˉ ) ( x i − x ˉ ) T Σ − 1 d Σ ) = tr ( Σ − 1 S Σ − 1 d Σ ) \large \color{green}{\begin{aligned} \text{tr}&\left(\frac{1}{N}\sum_{i=1}^N(\boldsymbol{x}_i-\boldsymbol{\bar{x}})^T\Sigma^{-1}d\Sigma\Sigma^{-1}(\boldsymbol{x}_i-\boldsymbol{\bar{x}})\right)\\ &=\frac{1}{N}\sum_{i=1}^N\left(\text{tr}(\boldsymbol{x}_i-\boldsymbol{\bar{x}})^T\Sigma^{-1}d\Sigma\Sigma^{-1}(\boldsymbol{x}_i-\boldsymbol{\bar{x}})\right)\\ &=\frac{1}{N}\sum_{i=1}^N\left(\text{tr}(\Sigma^{-1}(\boldsymbol{x}_i-\boldsymbol{\bar{x}})(\boldsymbol{x}_i-\boldsymbol{\bar{x}})^T\Sigma^{-1}d\Sigma\right) \\ &=\text{tr}(\Sigma^{-1}S\Sigma^{-1}d\Sigma) \end{aligned}} tr⎝⎛N1i=1∑N(xi−xˉ)TΣ−1dΣΣ−1(xi−xˉ)⎠⎞=N1i=1∑N(tr(xi−xˉ)TΣ−1dΣΣ−1(xi−xˉ))=N1i=1∑N(tr(Σ−1(xi−xˉ)(xi−xˉ)TΣ−1dΣ)=tr(Σ−1SΣ−1dΣ)
其中定义
S = 1 N ∑ i = 1 N ( x i − x ˉ ) ( x i − x ˉ ) T \large \color{green}{S = \frac{1}{N}\sum_{i=1}^N(\boldsymbol{x}_i-\boldsymbol{\bar{x}})(\boldsymbol{x}_i-\boldsymbol{\bar{x}})^T} S=N1i=1∑N(xi−xˉ)(xi−xˉ)T
为样本方差矩阵。综上, d l = tr ( ( Σ − 1 − Σ − 1 S Σ − 1 ) d Σ ) dl = \text{tr}\left(\left(\Sigma^{-1}-\Sigma^{-1}S\Sigma^{-1}\right)d\Sigma\right) dl=tr((Σ−1−Σ−1SΣ−1)dΣ)
-
根据导数与微分的联系 d f = tr ( ∂ f ∂ Σ T d Σ ) df = \text{tr}\left(\frac{\partial f}{\partial \Sigma}^T d\Sigma\right) df=tr(∂Σ∂fTdΣ) 有:
∂ l ∂ Σ = ( Σ − 1 − Σ − 1 S Σ − 1 ) T \large \color{green}{\frac{\partial l }{\partial \Sigma}=(\Sigma^{-1}-\Sigma^{-1}S\Sigma^{-1})^T} ∂Σ∂l=(Σ−1−Σ−1SΣ−1)T
, 其零点即 Σ \Sigma Σ 的最大似然估计为 Σ = S \Sigma=S_{\text { }} Σ=S
例 5 \Large\color{violet}{例5} 例5 l = − y T log softmax ( W x ) l=-\boldsymbol{y}^{T} \log \operatorname{softmax}(W \boldsymbol{x}) l=−yTlogsoftmax(Wx), 求 ∂ l ∂ W \frac{\partial l}{\partial W} ∂W∂l. 其中 y \boldsymbol{y} y 是除一个元素为1外其它元素为0的 m × 1 m \times 1 m×1 列向量, W W W 是 m × n m \times n m×n 矩阵, x \boldsymbol{x} x 是 n × 1 n \times 1 n×1 列向量, l l l 是标量; log \log log 表示自然对数, softmax ( a ) = exp ( a ) 1 T exp ( a ) \operatorname{softmax}(\boldsymbol{a})=\frac{\exp (\boldsymbol{a})}{\mathbf{1}^{T} \exp (\boldsymbol{a})} softmax(a)=1Texp(a)exp(a), 其中 exp ( a ) \exp (\boldsymbol{a}) exp(a) 表示逐元素求指数, 1 \mathbf{1} 1 代表全1向量。
解:首先把 softmax \operatorname{softmax} softmax 展开,注意逐元素log满足等式 log ( u / c ) = log ( u ) − 1 log ( c ) \log (\boldsymbol{u} / c)=\log (\boldsymbol{u})-\mathbf{1} \log (c) log(u/c)=log(u)−1log(c),以及 y \boldsymbol{y} y 满足 y T 1 = 1 \boldsymbol{y}^{T} \mathbf{1}=1 yT1=1 。得到:
l = − y T log exp ( W x ) + 1 y T log 1 T exp ( W x ) = − y T W x + log ( 1 T exp ( W x ) ) \large \color{green}{\begin{aligned} l&=-\boldsymbol{y}^{T} \log \exp (\boldsymbol{W} \boldsymbol{x})+\mathbf{1} \boldsymbol{y}^{T} \log \mathbf{1}^{T} \exp (\boldsymbol{W} \boldsymbol{x})\\ &=-\boldsymbol{y}^{T} \boldsymbol{W} \boldsymbol{x}+\log \left(\mathbf{1}^{T} \exp (\boldsymbol{W} \boldsymbol{x})\right) \end{aligned}} l=−yTlogexp(Wx)+1yTlog1Texp(Wx)=−yTWx+log(1Texp(Wx))
根据上面的Algorithms:
-
先使用矩阵乘法法则求微分 d l dl dl :
d l = − y T d W x + 1 T ( exp ( W x ) ⊙ ( d W x ) ) 1 T exp ( W x ) = − y T d W x + exp ( W x ) T ( d W x ) 1 T exp ( W x ) = − x ( softmax ( W x ) − y ) T d W \large \color{green}{\begin{aligned} dl & =- \boldsymbol{y}^TdW\boldsymbol{x}+\frac{\boldsymbol{1}^T\left(\exp(W\boldsymbol{x})\odot(dW\boldsymbol{x})\right)}{\boldsymbol{1}^T\exp(W\boldsymbol{x})}\\ \\& =- \boldsymbol{y}^TdW\boldsymbol{x}+\frac{\exp(W\boldsymbol{x})^T(dW\boldsymbol{x})}{\boldsymbol{1}^T\exp(W\boldsymbol{x})} \\& =- \boldsymbol{x}(\text{softmax}(W\boldsymbol{x})-\boldsymbol{y})^TdW \end{aligned}} dl=−yTdWx+1Texp(Wx)1T(exp(Wx)⊙(dWx))=−yTdWx+1Texp(Wx)exp(Wx)T(dWx)=−x(softmax(Wx)−y)TdW根据迹技巧:
矩阵乘法/逐元素乘法交换: tr ( A T ( B ⊙ C ) ) = tr ( ( A ⊙ B ) T C ) \operatorname{tr}\left(A^{T}(B \odot C)\right)=\operatorname{tr}\left((A \odot B)^{T} C\right) tr(AT(B⊙C))=tr((A⊙B)TC), 其中 A , B , C A, B, C A,B,C 尺寸相同。两侧都等于 ∑ i , j A i j B i j C i j . \sum_{i, j} A_{i j} B_{i j} C_{i j} . ∑i,jAijBijCij.
-
给 d l d l dl 套上迹 tr:
d l = − tr ( x ( softmax ( W x ) − y ) T d W ) \large \color{green}{dl =- \text{tr}\left(\boldsymbol{x}(\text{softmax}(W\boldsymbol{x})-\boldsymbol{y})^TdW\right)} dl=−tr(x(softmax(Wx)−y)TdW) -
根据导数与微分的联系 d l = tr ( ∂ l ∂ W T d W ) dl = \text{tr}\left(\frac{\partial l}{\partial W}^T dW\right) dl=tr(∂W∂lTdW)有:
∂ l ∂ W = ( softmax ( W x ) − y ) x T \large \color{green}{\frac{\partial l}{\partial W}= (\text{softmax}(W\boldsymbol{x})-\boldsymbol{y})\boldsymbol{x}^T} ∂W∂l=(softmax(Wx)−y)xT
2.4 迹函数对向量或矩阵的求导
迹函数对对向量矩阵求导这一大类问题, 其实更简单,因为它省去了Algorithms中的第1,2 步,相当于已经帮你套上了 t r \mathrm{tr} tr 。
例 6 \Large\color{violet}{例6} 例6: 求 tr ( A B ) \operatorname{tr}(A B) tr(AB) 对于矩阵 A A A 的导数。
解:直接假设 f = tr ( A B ) f=\operatorname{tr}(A B) f=tr(AB), 按照Algorithms一步一步来:
- 先使用矩阵乘法法则求微分 d f d f df :
d f = d tr ( A B ) = tr d ( A B ) = tr d A ⋅ B + tr B ⋅ d A \large \color{green}{d f=d \operatorname{tr}(A B)=\operatorname{tr} d(A B)=\operatorname{tr} d A \cdot B+\operatorname{tr} B \cdot d A} df=dtr(AB)=trd(AB)=trdA⋅B+trB⋅dA
矩阵 B B B 相当于常数,故有:
d f = tr d A ⋅ B = tr B d A \large \color{green}{d f=\operatorname{tr} d A \cdot B=\operatorname{tr} B d A} df=trdA⋅B=trBdA
根据导数与微分的联系 d f = tr ( ∂ f T ∂ X d X ) d f=\operatorname{tr}\left(\frac{\partial f^{T}}{\partial X} d X\right) df=tr(∂X∂fTdX) 有: ∂ f ∂ A = B T \frac{\partial f}{\partial A}=B^{T} ∂A∂f=BT
例 7 \Large\color{violet}{例7} 例7 求 tr ( B T X T C X B ) \operatorname{tr}\left(B^{T} X^{T} C X B\right) tr(BTXTCXB) 对于矩阵 X X X 的导数。
解: 直接假设 f = tr ( B T X T C X B ) f=\operatorname{tr}\left(B^{T} X^{T} C X B\right) f=tr(BTXTCXB), 按照Algorithms一步一步来:
- 先使用矩阵乘法法则求微分 d f : d f: df:
d f = d tr ( B T X T C X B ) = tr d ( B T X T C X B ) = tr ( B T d X T C X B ) + tr ( B T X T C d X B ) \large \color{green}{df=d~\text {tr}(B^TX^TCXB)=\text {tr}~d(B^TX^TCXB)=\text {tr}(B^TdX^TCXB)+\text {tr}(B^TX^TCdXB)} df=d tr(BTXTCXB)=tr d(BTXTCXB)=tr(BTdXTCXB)+tr(BTXTCdXB)
我们一项一项化简:
第1项 tr ( B T d X T C X B ) \operatorname{tr}\left(B^{T} d X^{T} C X B\right) tr(BTdXTCXB) 里面有个烦人的 d X T d X^{T} dXT, 想办法把它化简掉, 根据迹的转置不变性和交换律有:
tr ( B T d X T C X B ) = tr ( B T X T C T d X B ) = tr ( B B T X T C T d X ) \large \color{green}{\operatorname{tr}\left(B^{T} d X^{T} C X B\right)=\operatorname{tr}\left(B^{T} X^{T} C^{T} d X B\right)=\operatorname{tr}\left(B B^{T} X^{T} C^{T} d X\right)} tr(BTdXTCXB)=tr(BTXTCTdXB)=tr(BBTXTCTdX)
第2项 tr ( B T X T C d X B ) = tr ( B B T X T C d X ) \operatorname{tr}\left(B^{T} X^{T} C d X B\right)=\operatorname{tr}\left(B B^{T} X^{T} C d X\right) tr(BTXTCdXB)=tr(BBTXTCdX)
所以:
d f = tr ( B B T X T C T d X ) + tr ( B B T X T C d X ) \large \color{green}{d f=\operatorname{tr}\left(B B^{T} X^{T} C^{T} d X\right)+\operatorname{tr}\left(B B^{T} X^{T} C d X\right)} df=tr(BBTXTCTdX)+tr(BBTXTCdX)
- 根据导数与微分的联系 d f = tr ( ∂ f T ∂ X d X ) d f=\operatorname{tr}\left(\frac{\partial f^{T}}{\partial X} d X\right) df=tr(∂X∂fTdX) 有:
∂ f ∂ X = ( B B T X T C T ) T + ( B B T X T C ) T = C X B B T + C T X B B T \large \color{green}{\begin{aligned} \frac{\partial f}{\partial X}&=\left(B B^{T} X^{T} C^{T}\right)^{T}+\left(B B^{T} X^{T} C\right)^{T} \\& =C X B B^{T}+C^{T} X B B^{T} \end{aligned}} ∂X∂f=(BBTXTCT)T+(BBTXTC)T=CXBBT+CTXBBT
3、矩阵对矩阵求导
矩阵对矩阵的求导采用了向量化的思路,常应用于二阶方法中Hessian矩阵的分析。
首先来塚磨一下定义。矩阵对矩阵的导数,需要什么样的定义?
- 第一, 矩阵 F ( p × q ) F(p \times q) F(p×q) 对矩阵 X ( m × n ) X(m \times n) X(m×n) 的导数应包含所有 m n p q mnpq mnpq个偏导数 ∂ F k l ∂ X i j \frac{\partial F_{k l}}{\partial X_{i j}} ∂Xij∂Fkl, 从而不损失信息;
- 第二,导数与微分有简明的联系,因为在计算导数和应用中需要这个联系;
- 第三,导数有简明的从整体出发的算法。
我们先定义向量 f ( p × 1 ) \boldsymbol{f}(\mathrm{p} \times 1) f(p×1) 对向量 x ( m × 1 ) \boldsymbol{x}(\mathrm{m} \times 1) x(m×1) 的导数
∂ f ∂ x = [ ∂ f 1 ∂ x 1 ∂ f 2 ∂ x 1 ⋯ ∂ f p ∂ x 1 ∂ f 1 ∂ x 2 ∂ f 2 ∂ x 2 ⋯ ∂ f p ∂ x 2 ⋮ ⋮ ⋱ ⋮ ∂ f 1 ∂ x m ∂ f 2 ∂ x m ⋯ ∂ f p ∂ x m ] ( m × p ) \large \color{green}{\frac{\partial \boldsymbol{f}}{\partial \boldsymbol{x}} = \begin{bmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_2}{\partial x_1} & \cdots & \frac{\partial f_p}{\partial x_1}\\ \frac{\partial f_1}{\partial x_2} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_p}{\partial x_2}\\ \vdots & \vdots & \ddots & \vdots\\ \frac{\partial f_1}{\partial x_m} & \frac{\partial f_2}{\partial x_m} & \cdots & \frac{\partial f_p}{\partial x_m}\\ \end{bmatrix}_{(\mathrm{m} \times \mathrm{p})}} ∂x∂f=⎣⎢⎢⎢⎢⎢⎡∂x1∂f1∂x2∂f1⋮∂xm∂f1∂x1∂f2∂x2∂f2⋮∂xm∂f2⋯⋯⋱⋯∂x1∂fp∂x2∂fp⋮∂xm∂fp⎦⎥⎥⎥⎥⎥⎤(m×p)
有 d f = ∂ f T ∂ x d x ; d \boldsymbol{f}=\frac{\partial \boldsymbol{f}^{T}}{\partial \boldsymbol{x}} d \boldsymbol{x} ; df=∂x∂fTdx; 再定义矩阵的 (按列优先) 向量化
vec ( X ) = [ X 11 , … , X m 1 , X 12 , … , X m 2 , … , X 1 n , … , X m n ] ( m n × 1 ) T \large \color{green}{\operatorname{vec}(X)=\left[X_{11}, \ldots, X_{m 1}, X_{12}, \ldots, X_{m 2}, \ldots, X_{1 n}, \ldots, X_{m n}\right]^{T}_{(\mathrm{mn} \times 1)}} vec(X)=[X11,…,Xm1,X12,…,Xm2,…,X1n,…,Xmn](mn×1)T
并定义矩阵 F F F对矩阵 X X X的导数 ∂ F ∂ X = ∂ vec ( F ) ∂ vec ( X ) ( m n × p q ) \large \color{green}{\frac{\partial F}{\partial X}=\frac{\partial \operatorname{vec}(F)}{\partial \operatorname{vec}(X)}_{(\mathrm{mn} \times \mathrm{pq}) }} ∂X∂F=∂vec(X)∂vec(F)(mn×pq)
导数与微分有联系: vec ( d F ) = ∂ F T ∂ X vec ( d X ) \large \color{green}{\operatorname{vec}(d F)=\frac{\partial F^{T}}{\partial X} \operatorname{vec}(d X)} vec(dF)=∂X∂FTvec(dX) .
几点说明如下:
-
按此定义,标量对矩阵 X ( m × n ) X(\mathrm{m} \times \mathrm{n}) X(m×n) 的导数 ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f 是 m n × 1 \mathrm{mn} \times 1 mn×1 向量, 与上节的定义不兼容, 不过二者容易相互转换。为避免混淆, 用记号 ∇ X f \nabla_{X} f ∇Xf 表示上节定义的m × \times × n矩阵, 则有 ∂ f ∂ X = vec ( ∇ X f ) \frac{\partial f}{\partial X}=\operatorname{vec}\left(\nabla_{X} f\right) ∂X∂f=vec(∇Xf) 。
-
标量对矩阵的二阶导数,又称Hessian矩阵,定义为 ∇ X 2 f = ∂ 2 f ∂ X 2 = ∂ ∇ X f ∂ X \nabla^2_X f = \frac{\partial^2 f}{\partial X^2} = \frac{\partial \nabla_X f}{\partial X} ∇X2f=∂X2∂2f=∂X∂∇Xf ( m n × m n ) (\mathrm{mn} \times \mathrm{mn}) (mn×mn), 是对称矩阵。对向量 ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f 或矩阵 ∇ X f \nabla_{X} f ∇Xf 求导都可以得到Hessian矩阵,但从矩阵 ∇ X f \nabla_{X} f ∇Xf 出发更方便。
-
∂ F ∂ X = ∂ vec ( F ) ∂ X = ∂ F ∂ vec ( X ) = ∂ vec ( F ) ∂ vec ( X ) \large \color{green}{\frac{\partial F}{\partial X}=\frac{\partial \operatorname{vec}(F)}{\partial X}=\frac{\partial F}{\partial \operatorname{vec}(X)}=\frac{\partial \operatorname{vec}(F)}{\partial \operatorname{vec}(X)}} ∂X∂F=∂X∂vec(F)=∂vec(X)∂F=∂vec(X)∂vec(F), 求导时矩阵被向量化,弊端是这在一定程度破坏了矩阵的结构,会导致结果变得形式复杂;好处是多元微积分中关于梯度、Hessian矩阵的结论可以沿用过来,只需将矩阵向量化。例如优化问题中,牛顿法的更新 Δ X \Delta X ΔX, 满足vec ( Δ X ) = − ( ∇ X 2 f ) − 1 vec ( ∇ X f ) (\Delta X)=-\left(\nabla_{X}^{2} f\right)^{-1} \operatorname{vec}\left(\nabla_{X} f\right) (ΔX)=−(∇X2f)−1vec(∇Xf)
-
在资料中, 矩阵对矩阵的导数还有其它定义, 比如 ∂ F ∂ X = [ ∂ F k l ∂ X ] ( m p × n q ) \frac{\partial F}{\partial X} = \left[\frac{\partial F_{kl}}{\partial X}\right](\mathrm{mp} \times \mathrm{nq}) ∂X∂F=[∂X∂Fkl](mp×nq), 或是 ∂ F ∂ X = [ ∂ F ∂ X i j ] ( m p × n q ) \frac{\partial F}{\partial X}=\left[\frac{\partial F}{\partial X_{i j}}\right](\mathrm{mp} \times \mathrm{nq}) ∂X∂F=[∂Xij∂F](mp×nq), 它能兼容上节中的标量对矩阵导数的定义, 但微分与导数的联系 ( \left(\right. ( dF等于 ∂ F ∂ X \frac{\partial F}{\partial X} ∂X∂F 中逐个 m × n m \times n m×n 子块分别与 d X \mathrm{dX} dX 做内积 ) ) ) 不够简明, 不便于计算和应用。资料 [5]综述了以上定义,并批判它们是坏的定义,能配合微分运算的才是好的定义。
-
在资料中,有分子布局和分母布局两种定义,其中向量对向量的导数的排布有所不同。本文使用的是分母布局,机器学习和优化中的梯度矩阵采用此定义。而控制论等领域中的 Jacobian矩阵采用分子布局, 向量 f \boldsymbol{f} f 对向量 x \boldsymbol{x} x 的导数定义是
∂ f ∂ x = [ ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 ⋯ ∂ f 1 ∂ x m ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 ⋯ ∂ f 2 ∂ x m ⋮ ⋮ ⋱ ⋮ ∂ f p ∂ x 1 ∂ f p ∂ x 2 ⋯ ∂ f p ∂ x m ] \large \color{green}{\frac{\partial \boldsymbol{f}}{\partial \boldsymbol{x}} = \begin{bmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_m}\\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_m}\\ \vdots & \vdots & \ddots & \vdots\\ \frac{\partial f_p}{\partial x_1} & \frac{\partial f_p}{\partial x_2} & \cdots & \frac{\partial f_p}{\partial x_m}\\ \end{bmatrix}} ∂x∂f=⎣⎢⎢⎢⎢⎢⎡∂x1∂f1∂x1∂f2⋮∂x1∂fp∂x2∂f1∂x2∂f2⋮∂x2∂fp⋯⋯⋱⋯∂xm∂f1∂xm∂f2⋮∂xm∂fp⎦⎥⎥⎥⎥⎥⎤
,对应地导数与微分的联系是 d f = ∂ f ∂ x d x d\boldsymbol{f} = \frac{\partial \boldsymbol{f} }{\partial \boldsymbol{x}} d\boldsymbol{x} df=∂x∂fdx ;同样通过向量化定义矩阵F对矩阵X的导数 ∂ F ∂ X = ∂ v e c ( F ) ∂ v e c ( X ) \frac{\partial F}{\partial X} = \frac{\partial \mathrm{vec}(F)}{\partial \mathrm{vec}(X)} ∂X∂F=∂vec(X)∂vec(F) ,有 v e c ( d F ) = ∂ F ∂ X v e c ( d X ) \mathrm{vec}(dF) = \frac{\partial F}{\partial X} \mathrm{vec}(dX) vec(dF)=∂X∂Fvec(dX) 。两种布局下的导数互为转置,二者求微分的步骤是相同的,仅在对照导数与微分的联系时有一个转置的区别,读者可根据所在领域的习惯选定一种布局。
3.1 微分技巧
微分得到导数需要一些向量化的技巧:
-
线性:
vec ( A + B ) = vec ( A ) + vec ( B ) \large \color{green}{\operatorname{vec}(A+B)=\operatorname{vec}(A)+\operatorname{vec}(B)} vec(A+B)=vec(A)+vec(B) -
矩阵乘法:
v e c ( A X B ) = ( B T ⊗ A ) v e c ( X ) \large \color{green}{\mathrm{vec}(AXB) = (B^T \otimes A) \mathrm{vec}(X)} vec(AXB)=(BT⊗A)vec(X)
,其中 ⊗ \otimes ⊗表示Kronecker积,A(m×n)与 B ( p × q ) \mathrm{B}(\mathrm{p} \times \mathrm{q}) B(p×q) 的Kronecker积是 A ⊗ B = [ A i j B ] ( m p × n q ) 。 A \otimes B=\left[A_{i j} B_{}\right](\mathrm{mp} \times \mathrm{nq})_{。} A⊗B=[AijB](mp×nq)。 Kronecker积 -
转置:
vec ( A T ) = K m n vec ( A ) \large \color{green}{\operatorname{vec}\left(A^{T}\right)=K_{m n} \operatorname{vec}(A)} vec(AT)=Kmnvec(A)
A A A是 m × n m \times n m×n 矩阵, 其中 K m n ( m n × m n ) K_{m n}(\mathrm{mn} \times \mathrm{mn}) Kmn(mn×mn) 是交换矩阵(commutation matrix), 将按列优先的向量化变为按行优先的向量化。例如
K 22 = [ 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 1 ] , vec ( A T ) = [ A 11 A 12 A 21 A 22 ] , vec ( A ) = [ A 11 A 21 A 12 A 22 ] \large \color{green}{K_{22}=\left[\begin{array}{cccc} 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \end{array}\right], \operatorname{vec}\left(A^{T}\right)=\left[\begin{array}{c} A_{11} \\ A_{12} \\ A_{21} \\ A_{22} \end{array}\right], \operatorname{vec}(A)=\left[\begin{array}{c} A_{11} \\ A_{21} \\ A_{12} \\ A_{22} \end{array}\right]} K22=⎣⎢⎢⎢⎡1000001001000001⎦⎥⎥⎥⎤,vec(AT)=⎣⎢⎢⎢⎡A11A12A21A22⎦⎥⎥⎥⎤,vec(A)=⎣⎢⎢⎢⎡A11A21A