python处理数据可视化_数据整理101:使用Python提取,处理和可视化NBA数据
python处理数据可视化
由Viraj Parekh | 2017年4月6日 (by Viraj Parekh | April 6, 2017)
This is a basic tutorial using pandas and a few other packages to build a simple datapipe for getting NBA data. Even though this tutorial is done using NBA data, you don’t need to be an NBA fan to follow along. The same concepts and techniques can be applied to any project of your choosing.
这是使用熊猫和其他一些软件包来构建用于获取NBA数据的简单数据管道的基础教程。 即使本教程是使用NBA数据完成的,您也不必成为NBA粉丝。 相同的概念和技术可以应用于您选择的任何项目。
This is meant to be used as a general tutorial for beginners with some experience in Python or R.
旨在将其用作具有Python或R经验的初学者的通用教程。
第一步:我们需要什么数据? (Step One: What data do we need?)
The first step to any data project is getting an idea of what you want. We’re going to focus on getting NBA data at a team level on a game by game basis. From my experience, these team level stats usually exist in different places, making them harder to compare across games.
任何数据项目的第一步都是要了解您想要的东西。 我们将专注于逐场比赛在团队层面获取NBA数据。 根据我的经验,这些团队级别的统计数据通常存在于不同的地方,这使得它们在整个游戏中很难进行比较。
Our goal is to build box scores across a team level to easily compare them against each other. Hopefully this will give some insight as to how a team’s play has changed over the course of the season or make it easier to do any other type of analysis.
我们的目标是在整个团队水平上建立盒子分数,以轻松地相互比较。 希望这能对团队的表现在整个赛季中发生的变化提供一些见解,或者使进行任何其他类型的分析变得更加容易。
On a high level, this might look something like:
从高层次看,这可能看起来像:
Game | Days Rest | Total Passes | Total Assists | Passes/Assist | EFG | Outcome
游戏 天休息| 总通行证| 助攻总数| 通过/协助| EFG | 结果
下一步:数据来自哪里? (Next step: Where is the data coming from?)
stats.nba.com has all the NBA data that’s out there, but the harder part is finding a quick way to fetch and manipulate it into the form that’s needed (and what most of this tutorial will be about).
stats.nba.com拥有所有的NBA数据,但更难的部分是找到一种快速方法来将其提取并操纵为所需的形式(以及本教程大部分内容)。
Analytics is fun, but everything around it can be tough.
分析很有趣,但是周围的一切都很艰难。
We’re going to use the nba_py package
我们将使用nba_py包
Huge shoutout to https://github.com/seemethere for putting this together.
要大声地对https://github.com/seemethere进行大喊大叫,以将其整合在一起。
This is going to focus on team stats, so lets play around a little bit to get a sense of what we’re working with.
这将集中在团队统计数据上,因此让我们稍作练习以了解我们正在使用的工具。
Start by importing the packages we’ll need:
首先导入我们需要的软件包:
import pandas as pd from nba_py import teamimport pandas as pd from nba_py import team
If you’re using jupyter notebooks notebooks you can pip-install any packages you don’t have straight from the notebook using:
如果您使用的是jupyter笔记本电脑笔记本,则可以使用以下方法从笔记本电脑中直接安装您没有的任何软件包:
If you’re using Yhat’s Python IDE, Rodeo you can install nba_py in the packages tab.
如果您使用的是Yhat的Python IDE Rodeo ,则可以在“软件包”标签中安装nba_py 。
Install packages in the Packages tab. No surprises here.
在“软件包”选项卡中安装软件包。 这里没有惊喜。
So referring to the docs, it looks like we’ll need some sort of roster id to get data for each team. This api hits an endpoint on the NBA”s website, so the IDs are most likely in the URL:
因此,参考文档,看来我们需要某种名册ID才能获取每个团队的数据。 该api会在NBA网站上命中一个端点,因此ID最有可能出现在URL中:
(Unapologetic Knicks bias) Looking at the team page for the on stats.nba.com, here’s the url: http://stats.nba.com/team/#!/1610612752/
(无奈的尼克斯偏见)在stats.nba.com上查看团队页面,以下是URL:http://stats.nba.com/team/#!/1610612752/
That number at the end looks like a team ID. Let’s see how the passing data works:
最后的数字看起来像一个团队ID。 让我们看看传递的数据如何工作:
class nba_py.team.TeamPassTracking(team_id, measure_type=’Base’, per_mode=’PerGame’, plus_minus=’N’, pace_adjust=’N’, rank=’N’, league_id=’00’, season=’2016-17′, season_type=’Regular Season’, po_round=’0′, outcome=”, location=”, month=’0′, season_segment=”, date_from=”, date_to=”, opponent_team_id=’0′, vs_conference=”, vs_division=”, game_segment=”, period=’0′, shot_clock_range=”, last_n_games=’0′)
class nba_py.team.TeamPassTracking(team_id,measure_type ='Base',per_mode ='PerGame',plus_minus ='N',progress_adjust ='N',rank ='N',League_id = '00',season ='2016- 17',season_type =“常规季节”,po_round ='0',results =”,location =”,month ='0',season_segment =”,date_from =”,date_to =”,对手_team_id ='0',vs_conference = ”,vs_division =”,game_segment =”,期间='0',shot_clock_range =”,last_n_games ='0')
passes_made() passes_recieved()
pass_made()pass_recieved()
knicks = team.TeamPassTracking(1610612752)knicks = team.TeamPassTracking(1610612752)
All the info is stored in the knicks object:
所有信息都存储在尼克斯对象中:
| TEAM_ID | TEAM_ID | TEAM_NAME | 队名 | PASS_TYPE | PASS_TYPE | G | G | PASS_FROM | 通行证 | PASS_TEAMMATE_PLAYER_ID | PASS_TEAMMATE_PLAYER_ID | FREQUENCY | 频率 | PASS | 通过 | AST | AST | FGM | 女性外阴残割 | FGA | FGA | FG_PCT | FG_PCT | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 64 | 64 | Rose, Derrick | 罗斯,德里克 | 201565 | 201565 | 0.144 | 0.144 | 56.73 | 56.73 | 4.42 | 4.42 | 6.30 | 6.30 | 14.02 | 14.02 | 0.449 | 0.449 | 4.34 | 4.34 | 8.64 | 8.64 | 0.503 | 0.503 | 1.95 | 1.95 | 5.38 | 5.38 | 0.363 | 0.363 |
| 1 | 1个 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 58 | 58 | Jennings, Brandon | 詹宁斯,布兰登 | 201943 | 201943 | 0.111 | 0.111 | 48.22 | 48.22 | 4.93 | 4.93 | 7.09 | 7.09 | 15.47 | 15.47 | 0.458 | 0.458 | 5.31 | 5.31 | 10.50 | 10.50 | 0.506 | 0.506 | 1.78 | 1.78 | 4.97 | 4.97 | 0.358 | 0.358 |
| 2 | 2 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 66 | 66 | Porzingis, Kristaps | 克里斯蒂安(Kristaps)波尔津吉斯(Porzingis) | 204001 | 204001 | 0.106 | 0.106 | 40.61 | 40.61 | 1.47 | 1.47 | 3.29 | 3.29 | 7.65 | 7.65 | 0.430 | 0.430 | 2.56 | 2.56 | 5.50 | 5.50 | 0.466 | 0.466 | 0.73 | 0.73 | 2.15 | 2.15 | 0.338 | 0.338 |
| 3 | 3 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 46 | 46 | Noah, Joakim | 诺亚(Joahm) | 201149 | 201149 | 0.073 | 0.073 | 40.20 | 40.20 | 2.24 | 2.24 | 4.17 | 4.17 | 8.85 | 8.85 | 0.472 | 0.472 | 3.43 | 3.43 | 6.93 | 6.93 | 0.495 | 0.495 | 0.74 | 0.74 | 1.91 | 1.91 | 0.386 | 0.386 |
| 4 | 4 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 72 | 72 | Anthony, Carmelo | 安东尼(Carmelo) | 2546 | 2546 | 0.102 | 0.102 | 35.83 | 35.83 | 2.88 | 2.88 | 4.18 | 4.18 | 9.65 | 9.65 | 0.433 | 0.433 | 3.13 | 3.13 | 6.99 | 6.99 | 0.447 | 0.447 | 1.06 | 1.06 | 2.67 | 2.67 | 0.396 | 0.396 |
| 5 | 5 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 73 | 73 | Lee, Courtney | 李·考特尼 | 201584 | 201584 | 0.090 | 0.090 | 30.92 | 30.92 | 2.33 | 2.33 | 3.92 | 3.92 | 8.42 | 8.42 | 0.465 | 0.465 | 3.01 | 3.01 | 5.97 | 5.97 | 0.505 | 0.505 | 0.90 | 0.90 | 2.45 | 2.45 | 0.369 | 0.369 |
| 6 | 6 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 68 | 68 | Hernangomez, Willy | 威利·埃尔南戈梅斯 | 1626195 | 1626195 | 0.076 | 0.076 | 28.26 | 28.26 | 1.25 | 1.25 | 2.32 | 2.32 | 5.50 | 5.50 | 0.422 | 0.422 | 1.74 | 1.74 | 3.93 | 3.93 | 0.442 | 0.442 | 0.59 | 0.59 | 1.57 | 1.57 | 0.374 | 0.374 |
| 7 | 7 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 46 | 46 | Baker, Ron | 贝克,罗恩 | 1627758 | 1627758 | 0.045 | 0.045 | 24.93 | 24.93 | 1.87 | 1.87 | 2.61 | 2.61 | 5.72 | 5.72 | 0.456 | 0.456 | 1.93 | 1.93 | 3.80 | 3.80 | 0.509 | 0.509 | 0.67 | 0.67 | 1.91 | 1.91 | 0.352 | 0.352 |
| 8 | 8 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 46 | 46 | Thomas, Lance | 托马斯·兰斯 | 202498 | 202498 | 0.042 | 0.042 | 23.24 | 23.24 | 0.76 | 0.76 | 1.93 | 1.93 | 4.67 | 4.67 | 0.414 | 0.414 | 1.70 | 1.70 | 3.78 | 3.78 | 0.448 | 0.448 | 0.24 | 0.24 | 0.89 | 0.89 | 0.268 | 0.268 |
| 9 | 9 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 75 | 75 | O’Quinn, Kyle | 奥奎恩,凯尔 | 203124 | 203124 | 0.068 | 0.068 | 22.93 | 22.93 | 1.49 | 1.49 | 2.35 | 2.35 | 4.87 | 4.87 | 0.482 | 0.482 | 1.93 | 1.93 | 3.63 | 3.63 | 0.533 | 0.533 | 0.41 | 0.41 | 1.24 | 1.24 | 0.333 | 0.333 |
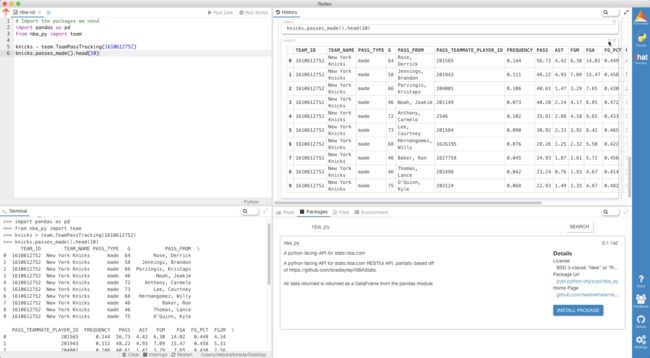
Did you know you can inspect, copy and save data frames in the History tab in Rodeo?
您是否知道可以在Rodeo的“历史记录”选项卡中检查,复制和保存数据框?
Referring back to the docs, this looks like per game averages for passes. Definitely a lot that can be done with this, but let’s try to get it for a specific game. Referring to the docs:
回到文档,这看起来像每场比赛的传球平均值。 绝对可以做到这一点,但让我们尝试针对特定游戏获得它。 参考文档:
knicks_last_game = team.TeamPassTracking(1610612752, last_n_games = 1) knicks_last_game.passes_made().head(10)knicks_last_game = team.TeamPassTracking(1610612752, last_n_games = 1) knicks_last_game.passes_made().head(10)
| TEAM_ID | TEAM_ID | TEAM_NAME | 队名 | PASS_TYPE | PASS_TYPE | G | G | PASS_FROM | 通行证 | PASS_TEAMMATE_PLAYER_ID | PASS_TEAMMATE_PLAYER_ID | FREQUENCY | 频率 | PASS | 通过 | AST | AST | FGM | 女性外阴残割 | FGA | FGA | FG_PCT | FG_PCT | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Baker, Ron | 贝克,罗恩 | 1627758 | 1627758 | 0.212 | 0.212 | 72.0 | 72.0 | 6.0 | 6.0 | 7.0 | 7.0 | 15.0 | 15.0 | 0.467 | 0.467 | 7.0 | 7.0 | 11.0 | 11.0 | 0.636 | 0.636 | 0.0 | 0.0 | 4.0 | 4.0 | 0.000 | 0.000 |
| 1 | 1个 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Ndour, Maurice | 恩杜尔,莫里斯 | 1626254 | 1626254 | 0.135 | 0.135 | 46.0 | 46.0 | 1.0 | 1.0 | 3.0 | 3.0 | 9.0 | 9.0 | 0.333 | 0.333 | 3.0 | 3.0 | 4.0 | 4.0 | 0.750 | 0.750 | 0.0 | 0.0 | 5.0 | 5.0 | 0.000 | 0.000 |
| 2 | 2 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Anthony, Carmelo | 安东尼(Carmelo) | 2546 | 2546 | 0.126 | 0.126 | 43.0 | 43.0 | 2.0 | 2.0 | 5.0 | 5.0 | 16.0 | 16.0 | 0.313 | 0.313 | 4.0 | 4.0 | 13.0 | 13.0 | 0.308 | 0.308 | 1.0 | 1.0 | 3.0 | 3.0 | 0.333 | 0.333 |
| 3 | 3 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | O’Quinn, Kyle | 奥奎恩,凯尔 | 203124 | 203124 | 0.118 | 0.118 | 40.0 | 40.0 | 5.0 | 5.0 | 5.0 | 5.0 | 6.0 | 6.0 | 0.833 | 0.833 | 4.0 | 4.0 | 4.0 | 4.0 | 1.000 | 1.000 | 1.0 | 1.0 | 2.0 | 2.0 | 0.500 | 0.500 |
| 4 | 4 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Lee, Courtney | 李·考特尼 | 201584 | 201584 | 0.118 | 0.118 | 40.0 | 40.0 | 3.0 | 3.0 | 6.0 | 6.0 | 8.0 | 8.0 | 0.750 | 0.750 | 2.0 | 2.0 | 4.0 | 4.0 | 0.500 | 0.500 | 4.0 | 4.0 | 4.0 | 4.0 | 1.000 | 1.000 |
| 5 | 5 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Hernangomez, Willy | 威利·埃尔南戈梅斯 | 1626195 | 1626195 | 0.082 | 0.082 | 28.0 | 28.0 | 3.0 | 3.0 | 4.0 | 4.0 | 8.0 | 8.0 | 0.500 | 0.500 | 4.0 | 4.0 | 6.0 | 6.0 | 0.667 | 0.667 | 0.0 | 0.0 | 2.0 | 2.0 | 0.000 | 0.000 |
| 6 | 6 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Holiday, Justin | 假日,贾斯汀 | 203200 | 203200 | 0.071 | 0.071 | 24.0 | 24.0 | 3.0 | 3.0 | 4.0 | 4.0 | 7.0 | 7.0 | 0.571 | 0.571 | 4.0 | 4.0 | 6.0 | 6.0 | 0.667 | 0.667 | 0.0 | 0.0 | 1.0 | 1.0 | 0.000 | 0.000 |
| 7 | 7 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Kuzminskas, Mindaugas | 明道加斯Kuzminskas | 1627851 | 1627851 | 0.059 | 0.059 | 20.0 | 20.0 | 2.0 | 2.0 | 2.0 | 2.0 | 6.0 | 6.0 | 0.333 | 0.333 | 2.0 | 2.0 | 5.0 | 5.0 | 0.400 | 0.400 | 0.0 | 0.0 | 1.0 | 1.0 | 0.000 | 0.000 |
| 8 | 8 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Randle, Chasson | 查森·兰德尔 | 1626184 | 1626184 | 0.044 | 0.044 | 15.0 | 15.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.000 | 0.000 | 0.0 | 0.0 | 1.0 | 1.0 | 0.000 | 0.000 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N |
| 9 | 9 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Vujacic, Sasha | 萨沙武贾西奇 | 2756 | 2756 | 0.035 | 0.035 | 12.0 | 12.0 | 1.0 | 1.0 | 2.0 | 2.0 | 3.0 | 3.0 | 0.667 | 0.667 | 2.0 | 2.0 | 2.0 | 2.0 | 1.000 | 1.000 | 0.0 | 0.0 | 1.0 | 1.0 | 0.000 | 0.000 |
This looks clean enough to be wrangled into a form that can be worked with.
这看起来很干净,可以整理成可以使用的形式。
If we’re trying to create a team level box score, we’re more than likely going to need to join tables together down the line, just something to keep in mind.
如果我们要创建团队级别的盒子分数,那么很可能需要将表连接在一起,这是需要牢记的。
Hitting the ShotTracking endpoint looks interesting:
击中ShotTracking端点看起来很有趣:
| TEAM_ID | TEAM_ID | TEAM_NAME | 队名 | SORT_ORDER | 排序 | G | G | CLOSE_DEF_DIST_RANGE | CLOSE_DEF_DIST_RANGE | FGA_FREQUENCY | FGA_FREQUENCY | FGM | 女性生殖器 | FGA | FGA | FG_PCT | FG_PCT | EFG_PCT | EFG_PCT | FG2A_FREQUENCY | FG2A_FREQUENCY | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3A_FREQUENCY | FG3A_FREQUENCY | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 1 | 1个 | 1 | 1个 | 0-2 Feet – Very Tight | 0-2英尺–非常紧 | 0.091 | 0.091 | 4.0 | 4.0 | 8.0 | 8.0 | 0.500 | 0.500 | 0.500 | 0.500 | 0.091 | 0.091 | 4.0 | 4.0 | 8.0 | 8.0 | 0.500 | 0.500 | 0.000 | 0.000 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N |
| 1 | 1个 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 2 | 2 | 1 | 1个 | 2-4 Feet – Tight | 2-4英尺–紧 | 0.318 | 0.318 | 15.0 | 15.0 | 28.0 | 28.0 | 0.536 | 0.536 | 0.536 | 0.536 | 0.295 | 0.295 | 15.0 | 15.0 | 26.0 | 26.0 | 0.577 | 0.577 | 0.023 | 0.023 | 0.0 | 0.0 | 2.0 | 2.0 | 0.000 | 0.000 |
| 2 | 2 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 3 | 3 | 1 | 1个 | 4-6 Feet – Open | 4-6英尺–开放 | 0.409 | 0.409 | 16.0 | 16.0 | 36.0 | 36.0 | 0.444 | 0.444 | 0.500 | 0.500 | 0.250 | 0.250 | 12.0 | 12.0 | 22.0 | 22.0 | 0.545 | 0.545 | 0.159 | 0.159 | 4.0 | 4.0 | 14.0 | 14.0 | 0.286 | 0.286 |
| 3 | 3 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 4 | 4 | 1 | 1个 | 6+ Feet – Wide Open | 6英尺以上-张开 | 0.182 | 0.182 | 7.0 | 7.0 | 16.0 | 16.0 | 0.438 | 0.438 | 0.500 | 0.500 | 0.102 | 0.102 | 5.0 | 5.0 | 9.0 | 9.0 | 0.556 | 0.556 | 0.080 | 0.080 | 2.0 | 2.0 | 7.0 | 7.0 | 0.286 | 0.286 |
Following along in Rodeo? Your view should look something like this.
跟随牛仔竞技表演吗? 您的视图应如下所示。
This looks interesting! We wanted EFG% (effective field goal percentage) in our original table, but it looks like we can get EFG% for open and covered shots. Let’s group ‘Open’ and ‘Wide Open’ together, along with ‘Tight’ and ‘Very Tight.’
这看起来很有趣! 我们希望在原始表格中使用EFG%(有效投篮命中率),但看起来我们可以为公开和掩护投篮获得EFG%。 让我们将“ Open”和“ Wide Open”以及“ Tight”和“ Very Tight”分组在一起。
Effective field goal percentage is a statistic that adjusts field goal percentage to account for the fact that three-point field goals count for three points while field goals only count for two points:
有效投篮命中率是一种统计数据,它会调整投篮命中率,以说明三分投篮命中占3分而投篮命中仅占2分这一事实:
This might help answer questions like “Do teams hit more open shots when they win?”
这可能有助于回答“团队获胜时会打更多空位吗?”之类的问题。
df_grouped = knicks_shots.closest_defender_shooting() df_grouped['OPEN'] = df_grouped['CLOSE_DEF_DIST_RANGE'].map(lambda x : True if 'Open' in x else False) ##This creates a new column OPEN, mapped from the 'CLOSE_DEF_DIST_RANGE' column. ##http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.map.html df_groupeddf_grouped = knicks_shots.closest_defender_shooting() df_grouped['OPEN'] = df_grouped['CLOSE_DEF_DIST_RANGE'].map(lambda x : True if 'Open' in x else False) ##This creates a new column OPEN, mapped from the 'CLOSE_DEF_DIST_RANGE' column. ##http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.map.html df_grouped
| TEAM_ID | TEAM_ID | TEAM_NAME | 队名 | SORT_ORDER | 排序 | G | G | CLOSE_DEF_DIST_RANGE | CLOSE_DEF_DIST_RANGE | FGA_FREQUENCY | FGA_FREQUENCY | FGM | 女性外阴残割 | FGA | FGA | FG_PCT | FG_PCT | EFG_PCT | EFG_PCT | FG2A_FREQUENCY | FG2A_FREQUENCY | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3A_FREQUENCY | FG3A_FREQUENCY | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | OPEN | 打开 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 1 | 1个 | 1 | 1个 | 0-2 Feet – Very Tight | 0-2英尺–非常紧 | 0.091 | 0.091 | 4.0 | 4.0 | 8.0 | 8.0 | 0.500 | 0.500 | 0.500 | 0.500 | 0.091 | 0.091 | 4.0 | 4.0 | 8.0 | 8.0 | 0.500 | 0.500 | 0.000 | 0.000 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N | False | 假 |
| 1 | 1个 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 2 | 2 | 1 | 1个 | 2-4 Feet – Tight | 2-4英尺–紧 | 0.318 | 0.318 | 15.0 | 15.0 | 28.0 | 28.0 | 0.536 | 0.536 | 0.536 | 0.536 | 0.295 | 0.295 | 15.0 | 15.0 | 26.0 | 26.0 | 0.577 | 0.577 | 0.023 | 0.023 | 0.0 | 0.0 | 2.0 | 2.0 | 0.000 | 0.000 | False | 假 |
| 2 | 2 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 3 | 3 | 1 | 1个 | 4-6 Feet – Open | 4-6英尺–开放 | 0.409 | 0.409 | 16.0 | 16.0 | 36.0 | 36.0 | 0.444 | 0.444 | 0.500 | 0.500 | 0.250 | 0.250 | 12.0 | 12.0 | 22.0 | 22.0 | 0.545 | 0.545 | 0.159 | 0.159 | 4.0 | 4.0 | 14.0 | 14.0 | 0.286 | 0.286 | True | 真正 |
| 3 | 3 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 4 | 4 | 1 | 1个 | 6+ Feet – Wide Open | 6英尺以上-张开 | 0.182 | 0.182 | 7.0 | 7.0 | 16.0 | 16.0 | 0.438 | 0.438 | 0.500 | 0.500 | 0.102 | 0.102 | 5.0 | 5.0 | 9.0 | 9.0 | 0.556 | 0.556 | 0.080 | 0.080 | 2.0 | 2.0 | 7.0 | 7.0 | 0.286 | 0.286 | True | 真正 |
The last column ‘OPEN’ gives us the information we need. Now we can aggregate based off of it. Let’s get the total number of open shots.
最后一列“ OPEN”为我们提供了我们所需的信息。 现在我们可以基于它进行聚合。 让我们获取打开镜头的总数。
That looks like it worked. Similarly, we can get the total number of “covered” shots taken (looks like it’s a lot higher…nothing surprising there.)
看起来很有效。 同样,我们可以获得已拍摄的“被覆盖”镜头的总数(看起来要高很多……不足为奇)。
Keep in mind, this is a bit misleading, as layups and other shots near the basket are more likely to have a nearby defender.
请记住,这有点误导,因为篮筐附近的上篮得分和其他投篮更有可能在附近有后卫。
Referring to the definition for EFG%:
参考EFG%的定义:
$$EFG = frac{(FGM + .5 * 3PM)}{FGA}$$
$$ EFG = frac {(FGM + .5 * 3PM)} {FGA} $$
We definitely have all the information we need to compute this for open and covered shots:
我们肯定拥有计算公开和掩饰照片所需的所有信息:
#Mapping the formula above into a column: open_efg = (df_grouped.loc[df_grouped['OPEN']== True, 'FGM'].sum() + (.5 * df_grouped.loc[df_grouped['OPEN']== True, 'FG3M'].sum()))/(df_grouped.loc[df_grouped['OPEN']== True, 'FGA'].sum()) covered_efg = (df_grouped.loc[df_grouped['OPEN']== False, 'FGM'].sum() + (.5 * df_grouped.loc[df_grouped['OPEN']== False, 'FG3M'].sum()))/(df_grouped.loc[df_grouped['OPEN']== False, 'FGA'].sum()) print open_efg print covered_efg 0.5 0.527777777778#Mapping the formula above into a column: open_efg = (df_grouped.loc[df_grouped['OPEN']== True, 'FGM'].sum() + (.5 * df_grouped.loc[df_grouped['OPEN']== True, 'FG3M'].sum()))/(df_grouped.loc[df_grouped['OPEN']== True, 'FGA'].sum()) covered_efg = (df_grouped.loc[df_grouped['OPEN']== False, 'FGM'].sum() + (.5 * df_grouped.loc[df_grouped['OPEN']== False, 'FG3M'].sum()))/(df_grouped.loc[df_grouped['OPEN']== False, 'FGA'].sum()) print open_efg print covered_efg 0.5 0.527777777778
Interesting… shooting better when there’s a defender nearby makes it look like there’s more to the story. Then again, nothing about the Knicks ever seems to makes sense.
有趣的是……在附近有后卫的情况下拍摄得更好,这使故事看起来还有更多。 再说一次,关于尼克斯的一切似乎都没有道理。
Referring back to the original plan, it looks like we have most of the stats we set out to get. However, we still haven’t addressed:
回到最初的计划,看起来我们已经有了大部分的统计数据。 但是,我们仍然没有解决:
1)与谁比赛? 谁赢了? (1) Who was the game against? Who won?)
2)每个团队休息了几天? (2) How many days rest did each team have?)
3)我们如何将所有这些数据汇总在一起? (3) How are we going to get all this data together?)
From the looks of it, there isn’t anything in the nba_py team modules we’re using that can be directly used as an identifier.
从外观上看,我们正在使用的nba_py团队模块中没有任何可直接用作标识符的内容。
However, it looks like we can get stats for date ranges. To test this, let’s look at a single game the Knicks played on Sunday, January 29th:
但是,看来我们可以获得日期范围的统计信息。 为了测试这一点,让我们看一下尼克斯队在1月29日星期日进行的一场比赛:
| TEAM_ID | TEAM_ID | TEAM_NAME | 队名 | SORT_ORDER | 排序 | G | G | CLOSE_DEF_DIST_RANGE | CLOSE_DEF_DIST_RANGE | FGA_FREQUENCY | FGA_FREQUENCY | FGM | 女性生殖器 | FGA | FGA | FG_PCT | FG_PCT | EFG_PCT | EFG_PCT | FG2A_FREQUENCY | FG2A_FREQUENCY | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3A_FREQUENCY | FG3A_FREQUENCY | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 1 | 1个 | 1 | 1个 | 0-2 Feet – Very Tight | 0-2英尺–非常紧 | 0.156 | 0.156 | 6.0 | 6.0 | 20.0 | 20.0 | 0.300 | 0.300 | 0.300 | 0.300 | 0.148 | 0.148 | 6.0 | 6.0 | 19.0 | 19.0 | 0.316 | 0.316 | 0.008 | 0.008 | 0.0 | 0.0 | 1.0 | 1.0 | 0.000 | 0.000 |
| 1 | 1个 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 2 | 2 | 1 | 1个 | 2-4 Feet – Tight | 2-4英尺–紧 | 0.344 | 0.344 | 23.0 | 23.0 | 44.0 | 44.0 | 0.523 | 0.523 | 0.591 | 0.591 | 0.258 | 0.258 | 17.0 | 17.0 | 33.0 | 33.0 | 0.515 | 0.515 | 0.086 | 0.086 | 6.0 | 6.0 | 11.0 | 11.0 | 0.545 | 0.545 |
| 2 | 2 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 3 | 3 | 1 | 1个 | 4-6 Feet – Open | 4-6英尺–开放 | 0.320 | 0.320 | 13.0 | 13.0 | 41.0 | 41.0 | 0.317 | 0.317 | 0.390 | 0.390 | 0.156 | 0.156 | 7.0 | 7.0 | 20.0 | 20.0 | 0.350 | 0.350 | 0.164 | 0.164 | 6.0 | 6.0 | 21.0 | 21.0 | 0.286 | 0.286 |
| 3 | 3 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 4 | 4 | 1 | 1个 | 6+ Feet – Wide Open | 6英尺以上-张开 | 0.180 | 0.180 | 9.0 | 9.0 | 23.0 | 23.0 | 0.391 | 0.391 | 0.522 | 0.522 | 0.039 | 0.039 | 3.0 | 3.0 | 5.0 | 5.0 | 0.600 | 0.600 | 0.141 | 0.141 | 6.0 | 6.0 | 18.0 | 18.0 | 0.333 | 0.333 |
A quick check of the box score confirms that the Knicks shot a total of 128, so it looks like adding a date field will work out. We’ll just need to figure out which dates to pass in:
快速检查一下盒子得分,可以确认尼克斯一共打了128球,因此添加日期字段看起来很可行。 我们只需要找出要传递的日期即可:
We still don’t know what the outcome was, so let’s jump back into the docs to see if another module will help out.
我们仍然不知道结果是什么,所以让我们跳回到文档中看看是否其他模块会有所帮助。
#Hitting another endpoint knicks_log = team.TeamGameLogs(knicks_id) knicks_log.info()#Hitting another endpoint knicks_log = team.TeamGameLogs(knicks_id) knicks_log.info()
| Team_ID | Team_ID | Game_ID | Game_ID | GAME_DATE | GAME_DATE | MATCHUP | 配对 | WL | WL | W | w ^ | L | 大号 | W_PCT | PCT | MIN | 最低 | FGM | 女性外阴残割 | … | … | FT_PCT | FT_PCT | OREB | OREB | DREB | DREB | REB | REB | AST | AST | STL | STL | BLK | 黑色 | TOV | TOV | PF | PF | PTS | PTS | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | 0021601160 | 0021601160 | APR 04, 2017 | 2017年4月4日 | NYK vs. CHI | NYK vs.CHI | W | w ^ | 30 | 30 | 48 | 48 | 0.385 | 0.385 | 240 | 240 | 42 | 42 | … | … | 0.625 | 0.625 | 16 | 16 | 37 | 37 | 53 | 53 | 26 | 26 | 5 | 5 | 7 | 7 | 15 | 15 | 22 | 22 | 100 | 100 |
| 1 | 1个 | 1610612752 | 1610612752 | 0021601145 | 0021601145 | APR 02, 2017 | 2017年4月2日 | NYK vs. BOS | NYK与BOS | L | 大号 | 29 | 29 | 48 | 48 | 0.377 | 0.377 | 240 | 240 | 33 | 33 | … | … | 0.840 | 0.840 | 8 | 8 | 24 | 24 | 32 | 32 | 20 | 20 | 12 | 12 | 2 | 2 | 11 | 11 | 20 | 20 | 94 | 94 |
| 2 | 2 | 1610612752 | 1610612752 | 0021601133 | 0021601133 | MAR 31, 2017 | 2017年3月31日 | NYK @ MIA | NYK @ MIA | W | w ^ | 29 | 29 | 47 | 47 | 0.382 | 0.382 | 240 | 240 | 38 | 38 | … | … | 0.941 | 0.941 | 8 | 8 | 31 | 31 | 39 | 39 | 25 | 25 | 9 | 9 | 5 | 5 | 14 | 14 | 18 | 18 | 98 | 98 |
| 3 | 3 | 1610612752 | 1610612752 | 0021601115 | 0021601115 | MAR 29, 2017 | 2017年3月29日 | NYK vs. MIA | NYK与MIA | L | 大号 | 28 | 28 | 47 | 47 | 0.373 | 0.373 | 240 | 240 | 33 | 33 | … | … | 0.810 | 0.810 | 17 | 17 | 35 | 35 | 52 | 52 | 19 | 19 | 2 | 2 | 6 | 6 | 14 | 14 | 16 | 16 | 88 | 88 |
| 4 | 4 | 1610612752 | 1610612752 | 0021601098 | 0021601098 | MAR 27, 2017 | 2017年3月27日 | NYK vs. DET | NYK与DET | W | w ^ | 28 | 28 | 46 | 46 | 0.378 | 0.378 | 240 | 240 | 45 | 45 | … | … | 0.923 | 0.923 | 4 | 4 | 33 | 33 | 37 | 37 | 26 | 26 | 13 | 13 | 5 | 5 | 12 | 12 | 16 | 16 | 109 | 109 |
| 5 | 5 | 1610612752 | 1610612752 | 0021601085 | 0021601085 | MAR 25, 2017 | 2017年3月25日 | NYK @ SAS | NYK @ SAS | L | 大号 | 27 | 27 | 46 | 46 | 0.370 | 0.370 | 240 | 240 | 41 | 41 | … | … | 0.867 | 0.867 | 12 | 12 | 33 | 33 | 45 | 45 | 24 | 24 | 6 | 6 | 5 | 5 | 16 | 16 | 16 | 16 | 98 | 98 |
| 6 | 6 | 1610612752 | 1610612752 | 0021601071 | 0021601071 | MAR 23, 2017 | 2017年3月23日 | NYK @ POR | NYK @ POR | L | 大号 | 27 | 27 | 45 | 45 | 0.375 | 0.375 | 240 | 240 | 36 | 36 | … | … | 0.900 | 0.900 | 9 | 9 | 31 | 31 | 40 | 40 | 23 | 23 | 5 | 5 | 9 | 9 | 11 | 11 | 20 | 20 | 95 | 95 |
| 7 | 7 | 1610612752 | 1610612752 | 0021601066 | 0021601066 | MAR 22, 2017 | 2017年3月22日 | NYK @ UTA | 纽约@UTA | L | 大号 | 27 | 27 | 44 | 44 | 0.380 | 0.380 | 240 | 240 | 38 | 38 | … | … | 0.889 | 0.889 | 9 | 9 | 27 | 27 | 36 | 36 | 19 | 19 | 5 | 5 | 1 | 1个 | 11 | 11 | 26 | 26 | 101 | 101 |
| 8 | 8 | 1610612752 | 1610612752 | 0021601050 | 0021601050 | MAR 20, 2017 | 2017年3月20日 | NYK @ LAC | 纽约@ LAC | L | 大号 | 27 | 27 | 43 | 43 | 0.386 | 0.386 | 240 | 240 | 40 | 40 | … | … | 0.792 | 0.792 | 14 | 14 | 34 | 34 | 48 | 48 | 24 | 24 | 6 | 6 | 1 | 1个 | 12 | 12 | 19 | 19 | 105 | 105 |
| 9 | 9 | 1610612752 | 1610612752 | 0021601016 | 0021601016 | MAR 16, 2017 | 2017年3月16日 | NYK vs. BKN | NYK对阵BKN | L | 大号 | 27 | 27 | 42 | 42 | 0.391 | 0.391 | 240 | 240 | 41 | 41 | … | … | 0.962 | 0.962 | 5 | 5 | 29 | 29 | 34 | 34 | 20 | 20 | 6 | 6 | 4 | 4 | 7 | 7 | 26 | 26 | 110 | 110 |
| 10 | 10 | 1610612752 | 1610612752 | 0021601001 | 0021601001 | MAR 14, 2017 | 2017年3月14日 | NYK vs. IND | NYK vs.IND | W | w ^ | 27 | 27 | 41 | 41 | 0.397 | 0.397 | 240 | 240 | 35 | 35 | … | … | 0.615 | 0.615 | 11 | 11 | 41 | 41 | 52 | 52 | 21 | 21 | 8 | 8 | 4 | 4 | 14 | 14 | 15 | 15 | 87 | 87 |
| 11 | 11 | 1610612752 | 1610612752 | 0021600986 | 0021600986 | MAR 12, 2017 | 2017年3月12日 | NYK @ BKN | NYK @ BKN | L | 大号 | 26 | 26 | 41 | 41 | 0.388 | 0.388 | 240 | 240 | 39 | 39 | … | … | 0.813 | 0.813 | 11 | 11 | 32 | 32 | 43 | 43 | 22 | 22 | 5 | 5 | 8 | 8 | 9 | 9 | 20 | 20 | 112 | 112 |
| 12 | 12 | 1610612752 | 1610612752 | 0021600975 | 0021600975 | MAR 11, 2017 | 2017年3月11日 | NYK @ DET | NYK @ DET | L | 大号 | 26 | 26 | 40 | 40 | 0.394 | 0.394 | 240 | 240 | 36 | 36 | … | … | 0.636 | 0.636 | 8 | 8 | 36 | 36 | 44 | 44 | 26 | 26 | 4 | 4 | 7 | 7 | 18 | 18 | 18 | 18 | 92 | 92 |
| 13 | 13 | 1610612752 | 1610612752 | 0021600952 | 0021600952 | MAR 08, 2017 | 2017年3月8日 | NYK @ MIL | NYK @ MIL | L | 大号 | 26 | 26 | 39 | 39 | 0.400 | 0.400 | 240 | 240 | 39 | 39 | … | … | 0.667 | 0.667 | 10 | 10 | 33 | 33 | 43 | 43 | 22 | 22 | 4 | 4 | 6 | 6 | 15 | 15 | 20 | 20 | 93 | 93 |
| 14 | 14 | 1610612752 | 1610612752 | 0021600935 | 0021600935 | MAR 06, 2017 | 2017年3月6日 | NYK @ ORL | NYK @ ORL | W | w ^ | 26 | 26 | 38 | 38 | 0.406 | 0.406 | 240 | 240 | 40 | 40 | … | … | 0.964 | 0.964 | 12 | 12 | 33 | 33 | 45 | 45 | 26 | 26 | 6 | 6 | 1 | 1个 | 9 | 9 | 23 | 23 | 113 | 113 |
| 15 | 15 | 1610612752 | 1610612752 | 0021600928 | 0021600928 | MAR 05, 2017 | 2017年3月5日 | NYK vs. GSW | NYK与GSW | L | 大号 | 25 | 25 | 38 | 38 | 0.397 | 0.397 | 240 | 240 | 39 | 39 | … | … | 0.800 | 0.800 | 12 | 12 | 35 | 35 | 47 | 47 | 18 | 18 | 5 | 5 | 6 | 6 | 15 | 15 | 20 | 20 | 105 | 105 |
| 16 | 16 | 1610612752 | 1610612752 | 0021600909 | 0021600909 | MAR 03, 2017 | 2017年3月3日 | NYK @ PHI | NYK @ PHI | L | 大号 | 25 | 25 | 37 | 37 | 0.403 | 0.403 | 240 | 240 | 33 | 33 | … | … | 0.879 | 0.879 | 9 | 9 | 32 | 32 | 41 | 41 | 14 | 14 | 10 | 10 | 3 | 3 | 10 | 10 | 20 | 20 | 102 | 102 |
| 17 | 17 | 1610612752 | 1610612752 | 0021600895 | 0021600895 | MAR 01, 2017 | 2017年3月1日 | NYK @ ORL | NYK @ ORL | W | w ^ | 25 | 25 | 36 | 36 | 0.410 | 0.410 | 240 | 240 | 34 | 34 | … | … | 0.806 | 0.806 | 13 | 13 | 37 | 37 | 50 | 50 | 21 | 21 | 9 | 9 | 3 | 3 | 11 | 11 | 16 | 16 | 101 | 101 |
| 18 | 18 | 1610612752 | 1610612752 | 0021600882 | 0021600882 | FEB 27, 2017 | 2017年2月27日 | NYK vs. TOR | NYK vs.TOR | L | 大号 | 24 | 24 | 36 | 36 | 0.400 | 0.400 | 240 | 240 | 33 | 33 | … | … | 0.842 | 0.842 | 8 | 8 | 32 | 32 | 40 | 40 | 17 | 17 | 10 | 10 | 6 | 6 | 17 | 17 | 19 | 19 | 91 | 91 |
| 19 | 19 | 1610612752 | 1610612752 | 0021600868 | 0021600868 | FEB 25, 2017 | 2017年2月25日 | NYK vs. PHI | NYK对战PHI | W | w ^ | 24 | 24 | 35 | 35 | 0.407 | 0.407 | 240 | 240 | 43 | 43 | … | … | 0.783 | 0.783 | 10 | 10 | 34 | 34 | 44 | 44 | 21 | 21 | 6 | 6 | 7 | 7 | 11 | 11 | 22 | 22 | 110 | 110 |
| 20 | 20 | 1610612752 | 1610612752 | 0021600853 | 0021600853 | FEB 23, 2017 | 2017年2月23日 | NYK @ CLE | NYK @ CLE | L | 大号 | 23 | 23 | 35 | 35 | 0.397 | 0.397 | 240 | 240 | 42 | 42 | … | … | 0.706 | 0.706 | 16 | 16 | 34 | 34 | 50 | 50 | 24 | 24 | 4 | 4 | 7 | 7 | 12 | 12 | 19 | 19 | 104 | 104 |
| 21 | 21 | 1610612752 | 1610612752 | 0021600845 | 0021600845 | FEB 15, 2017 | 2017年2月15日 | NYK @ OKC | NYK @ OKC | L | 大号 | 23 | 23 | 34 | 34 | 0.404 | 0.404 | 240 | 240 | 41 | 41 | … | … | 0.857 | 0.857 | 6 | 6 | 33 | 33 | 39 | 39 | 19 | 19 | 8 | 8 | 12 | 12 | 15 | 15 | 21 | 21 | 105 | 105 |
| 22 | 22 | 1610612752 | 1610612752 | 0021600817 | 0021600817 | FEB 12, 2017 | 2017年2月12日 | NYK vs. SAS | NYK与SAS | W | w ^ | 23 | 23 | 33 | 33 | 0.411 | 0.411 | 240 | 240 | 34 | 34 | … | … | 0.810 | 0.810 | 5 | 5 | 39 | 39 | 44 | 44 | 18 | 18 | 5 | 5 | 8 | 8 | 19 | 19 | 19 | 19 | 94 | 94 |
| 23 | 23 | 1610612752 | 1610612752 | 0021600800 | 0021600800 | FEB 10, 2017 | 2017年2月10日 | NYK vs. DEN | NYK对阵DEN | L | 大号 | 22 | 22 | 33 | 33 | 0.400 | 0.400 | 240 | 240 | 52 | 52 | … | … | 0.600 | 0.600 | 10 | 10 | 23 | 23 | 33 | 33 | 36 | 36 | 10 | 10 | 5 | 5 | 10 | 10 | 14 | 14 | 123 | 123 |
| 24 | 24 | 1610612752 | 1610612752 | 0021600791 | 0021600791 | FEB 08, 2017 | 2017年2月8日 | NYK vs. LAC | 纽约和洛杉矶 | L | 大号 | 22 | 22 | 32 | 32 | 0.407 | 0.407 | 240 | 240 | 46 | 46 | … | … | 0.833 | 0.833 | 12 | 12 | 29 | 29 | 41 | 41 | 25 | 25 | 9 | 9 | 5 | 5 | 11 | 11 | 22 | 22 | 115 | 115 |
| 25 | 25 | 1610612752 | 1610612752 | 0021600768 | 0021600768 | FEB 06, 2017 | 2017年2月6日 | NYK vs. LAL | NYK对阵LAL | L | 大号 | 22 | 22 | 31 | 31 | 0.415 | 0.415 | 240 | 240 | 37 | 37 | … | … | 0.788 | 0.788 | 6 | 6 | 34 | 34 | 40 | 40 | 16 | 16 | 4 | 4 | 4 | 4 | 16 | 16 | 24 | 24 | 107 | 107 |
| 26 | 26 | 1610612752 | 1610612752 | 0021600759 | 0021600759 | FEB 04, 2017 | 2017年2月4日 | NYK vs. CLE | NYK与CLE | L | 大号 | 22 | 22 | 30 | 30 | 0.423 | 0.423 | 240 | 240 | 39 | 39 | … | … | 0.500 | 0.500 | 13 | 13 | 29 | 29 | 42 | 42 | 23 | 23 | 9 | 9 | 7 | 7 | 10 | 10 | 20 | 20 | 104 | 104 |
| 27 | 27 | 1610612752 | 1610612752 | 0021600733 | 0021600733 | FEB 01, 2017 | 2017年2月1日 | NYK @ BKN | NYK @ BKN | W | w ^ | 22 | 22 | 29 | 29 | 0.431 | 0.431 | 240 | 240 | 35 | 35 | … | … | 0.613 | 0.613 | 21 | 21 | 37 | 37 | 58 | 58 | 23 | 23 | 16 | 16 | 7 | 7 | 13 | 13 | 18 | 18 | 95 | 95 |
| 28 | 28 | 1610612752 | 1610612752 | 0021600724 | 0021600724 | JAN 31, 2017 | 2017年1月31日 | NYK @ WAS | NYK @ WAS | L | 大号 | 21 | 21 | 29 | 29 | 0.420 | 0.420 | 240 | 240 | 34 | 34 | … | … | 0.800 | 0.800 | 22 | 22 | 29 | 29 | 51 | 51 | 18 | 18 | 8 | 8 | 2 | 2 | 12 | 12 | 17 | 17 | 101 | 101 |
| 29 | 29 | 1610612752 | 1610612752 | 0021600711 | 0021600711 | JAN 29, 2017 | 2017年1月29日 | NYK @ ATL | NYK @ ATL | L | 大号 | 21 | 21 | 28 | 28 | 0.429 | 0.429 | 340 | 340 | 51 | 51 | … | … | 0.826 | 0.826 | 15 | 15 | 48 | 48 | 63 | 63 | 32 | 32 | 9 | 9 | 11 | 11 | 12 | 12 | 39 | 39 | 139 | 139 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 48 | 48 | 1610612752 | 1610612752 | 0021600456 | 0021600456 | DEC 25, 2016 | 2016年12月25日 | NYK vs. BOS | NYK与BOS | L | 大号 | 16 | 16 | 14 | 14 | 0.533 | 0.533 | 240 | 240 | 41 | 41 | … | … | 0.889 | 0.889 | 17 | 17 | 32 | 32 | 49 | 49 | 11 | 11 | 5 | 5 | 6 | 6 | 17 | 17 | 23 | 23 | 114 | 114 |
| 49 | 49 | 1610612752 | 1610612752 | 0021600438 | 0021600438 | DEC 22, 2016 | 2016年12月22日 | NYK vs. ORL | NYK与ORL | W | w ^ | 16 | 16 | 13 | 13 | 0.552 | 0.552 | 240 | 240 | 41 | 41 | … | … | 0.882 | 0.882 | 18 | 18 | 34 | 34 | 52 | 52 | 26 | 26 | 9 | 9 | 9 | 9 | 15 | 15 | 18 | 18 | 106 | 106 |
| 50 | 50 | 1610612752 | 1610612752 | 0021600421 | 0021600421 | DEC 20, 2016 | 2016年12月20日 | NYK vs. IND | NYK vs.IND | W | w ^ | 15 | 15 | 13 | 13 | 0.536 | 0.536 | 240 | 240 | 44 | 44 | … | … | 0.810 | 0.810 | 4 | 4 | 41 | 41 | 45 | 45 | 24 | 24 | 6 | 6 | 8 | 8 | 14 | 14 | 18 | 18 | 118 | 118 |
| 51 | 51 | 1610612752 | 1610612752 | 0021600404 | 0021600404 | DEC 17, 2016 | 2016年12月17日 | NYK @ DEN | 纽约@DEN | L | 大号 | 14 | 14 | 13 | 13 | 0.519 | 0.519 | 240 | 240 | 35 | 35 | … | … | 0.923 | 0.923 | 9 | 9 | 26 | 26 | 35 | 35 | 18 | 18 | 6 | 6 | 4 | 4 | 11 | 11 | 27 | 27 | 114 | 114 |
| 52 | 52 | 1610612752 | 1610612752 | 0021600388 | 0021600388 | DEC 15, 2016 | 2016年12月15日 | NYK @ GSW | NYK @ GSW | L | 大号 | 14 | 14 | 12 | 12 | 0.538 | 0.538 | 240 | 240 | 38 | 38 | … | … | 0.474 | 0.474 | 14 | 14 | 35 | 35 | 49 | 49 | 19 | 19 | 10 | 10 | 5 | 5 | 11 | 11 | 10 | 10 | 90 | 90 |
| 53 | 53 | 1610612752 | 1610612752 | 0021600372 | 0021600372 | DEC 13, 2016 | 2016年12月13日 | NYK @ PHX | NYK @ PHX | L | 大号 | 14 | 14 | 11 | 11 | 0.560 | 0.560 | 265 | 265 | 38 | 38 | … | … | 0.737 | 0.737 | 11 | 11 | 32 | 32 | 43 | 43 | 23 | 23 | 10 | 10 | 4 | 4 | 13 | 13 | 27 | 27 | 111 | 111 |
| 54 | 54 | 1610612752 | 1610612752 | 0021600360 | 0021600360 | DEC 11, 2016 | 2016年12月11日 | NYK @ LAL | NYK @ LAL | W | w ^ | 14 | 14 | 10 | 10 | 0.583 | 0.583 | 240 | 240 | 41 | 41 | … | … | 0.839 | 0.839 | 8 | 8 | 36 | 36 | 44 | 44 | 21 | 21 | 9 | 9 | 11 | 11 | 10 | 10 | 15 | 15 | 118 | 118 |
| 55 | 55 | 1610612752 | 1610612752 | 0021600345 | 0021600345 | DEC 09, 2016 | 2016年12月9日 | NYK @ SAC | NYK @ SAC | W | w ^ | 13 | 13 | 10 | 10 | 0.565 | 0.565 | 240 | 240 | 36 | 36 | … | … | 0.840 | 0.840 | 12 | 12 | 42 | 42 | 54 | 54 | 22 | 22 | 3 | 3 | 6 | 6 | 16 | 16 | 25 | 25 | 103 | 103 |
| 56 | 56 | 1610612752 | 1610612752 | 0021600327 | 0021600327 | DEC 07, 2016 | 2016年12月7日 | NYK vs. CLE | NYK与CLE | L | 大号 | 12 | 12 | 10 | 10 | 0.545 | 0.545 | 240 | 240 | 35 | 35 | … | … | 0.867 | 0.867 | 13 | 13 | 30 | 30 | 43 | 43 | 22 | 22 | 6 | 6 | 3 | 3 | 16 | 16 | 22 | 22 | 94 | 94 |
| 57 | 57 | 1610612752 | 1610612752 | 0021600316 | 0021600316 | DEC 06, 2016 | 2016年12月6日 | NYK @ MIA | NYK @ MIA | W | w ^ | 12 | 12 | 9 | 9 | 0.571 | 0.571 | 240 | 240 | 48 | 48 | … | … | 0.688 | 0.688 | 18 | 18 | 35 | 35 | 53 | 53 | 22 | 22 | 6 | 6 | 6 | 6 | 10 | 10 | 18 | 18 | 114 | 114 |
| 58 | 58 | 1610612752 | 1610612752 | 0021600302 | 0021600302 | DEC 04, 2016 | 2016年12月4日 | NYK vs. SAC | NYK vs.SAC | W | w ^ | 11 | 11 | 9 | 9 | 0.550 | 0.550 | 240 | 240 | 39 | 39 | … | … | 0.708 | 0.708 | 14 | 14 | 44 | 44 | 58 | 58 | 20 | 20 | 5 | 5 | 10 | 10 | 18 | 18 | 25 | 25 | 106 | 106 |
| 59 | 59 | 1610612752 | 1610612752 | 0021600285 | 0021600285 | DEC 02, 2016 | 2016年12月2日 | NYK vs. MIN | NYK vs.MIN | W | w ^ | 10 | 10 | 9 | 9 | 0.526 | 0.526 | 240 | 240 | 41 | 41 | … | … | 0.800 | 0.800 | 11 | 11 | 32 | 32 | 43 | 43 | 26 | 26 | 9 | 9 | 6 | 6 | 15 | 15 | 18 | 18 | 118 | 118 |
| 60 | 60 | 1610612752 | 1610612752 | 0021600271 | 0021600271 | NOV 30, 2016 | 2016年11月30日 | NYK @ MIN | NYK @ MIN | W | w ^ | 9 | 9 | 9 | 9 | 0.500 | 0.500 | 240 | 240 | 41 | 41 | … | … | 0.733 | 0.733 | 12 | 12 | 27 | 27 | 39 | 39 | 24 | 24 | 8 | 8 | 3 | 3 | 13 | 13 | 26 | 26 | 106 | 106 |
| 61 | 61 | 1610612752 | 1610612752 | 0021600255 | 0021600255 | NOV 28, 2016 | 2016年11月28日 | NYK vs. OKC | NYK对阵OKC | L | 大号 | 8 | 8 | 9 | 9 | 0.471 | 0.471 | 240 | 240 | 36 | 36 | … | … | 0.893 | 0.893 | 12 | 12 | 28 | 28 | 40 | 40 | 20 | 20 | 9 | 9 | 11 | 11 | 5 | 5 | 16 | 16 | 103 | 103 |
| 62 | 62 | 1610612752 | 1610612752 | 0021600241 | 0021600241 | NOV 26, 2016 | 2016年11月26日 | NYK @ CHA | NYK @ CHA | L | 大号 | 8 | 8 | 8 | 8 | 0.500 | 0.500 | 240 | 240 | 37 | 37 | … | … | 0.800 | 0.800 | 11 | 11 | 36 | 36 | 47 | 47 | 26 | 26 | 9 | 9 | 6 | 6 | 8 | 8 | 27 | 27 | 102 | 102 |
| 63 | 63 | 1610612752 | 1610612752 | 0021600228 | 0021600228 | NOV 25, 2016 | 2016年11月25日 | NYK vs. CHA | NYK对阵CHA | W | w ^ | 8 | 8 | 7 | 7 | 0.533 | 0.533 | 265 | 265 | 45 | 45 | … | … | 0.923 | 0.923 | 13 | 13 | 42 | 42 | 55 | 55 | 26 | 26 | 9 | 9 | 8 | 8 | 16 | 16 | 21 | 21 | 113 | 113 |
| 64 | 64 | 1610612752 | 1610612752 | 0021600208 | 0021600208 | NOV 22, 2016 | 2016年11月22日 | NYK vs. POR | NYK与POR | W | w ^ | 7 | 7 | 7 | 7 | 0.500 | 0.500 | 240 | 240 | 45 | 45 | … | … | 1.000 | 1.000 | 10 | 10 | 33 | 33 | 43 | 43 | 26 | 26 | 8 | 8 | 5 | 5 | 13 | 13 | 23 | 23 | 107 | 107 |
| 65 | 65 | 1610612752 | 1610612752 | 0021600193 | 0021600193 | NOV 20, 2016 | 2016年11月20日 | NYK vs. ATL | NYK与ATL | W | w ^ | 6 | 6 | 7 | 7 | 0.462 | 0.462 | 240 | 240 | 42 | 42 | … | … | 0.714 | 0.714 | 11 | 11 | 39 | 39 | 50 | 50 | 21 | 21 | 8 | 8 | 1 | 1个 | 15 | 15 | 23 | 23 | 104 | 104 |
| 66 | 66 | 1610612752 | 1610612752 | 0021600169 | 0021600169 | NOV 17, 2016 | 2016年11月17日 | NYK @ WAS | NYK @ WAS | L | 大号 | 5 | 5 | 7 | 7 | 0.417 | 0.417 | 240 | 240 | 41 | 41 | … | … | 0.900 | 0.900 | 10 | 10 | 26 | 26 | 36 | 36 | 23 | 23 | 9 | 9 | 1 | 1个 | 13 | 13 | 20 | 20 | 112 | 112 |
| 67 | 67 | 1610612752 | 1610612752 | 0021600162 | 0021600162 | NOV 16, 2016 | 2016年11月16日 | NYK vs. DET | NYK与DET | W | w ^ | 5 | 5 | 6 | 6 | 0.455 | 0.455 | 240 | 240 | 42 | 42 | … | … | 0.632 | 0.632 | 19 | 19 | 33 | 33 | 52 | 52 | 24 | 24 | 8 | 8 | 9 | 9 | 9 | 9 | 11 | 11 | 105 | 105 |
| 68 | 68 | 1610612752 | 1610612752 | 0021600146 | 0021600146 | NOV 14, 2016 | 2016年11月14日 | NYK vs. DAL | NYK对DAL | W | w ^ | 4 | 4 | 6 | 6 | 0.400 | 0.400 | 240 | 240 | 34 | 34 | … | … | 0.889 | 0.889 | 14 | 14 | 37 | 37 | 51 | 51 | 18 | 18 | 5 | 5 | 5 | 5 | 17 | 17 | 16 | 16 | 93 | 93 |
| 69 | 69 | 1610612752 | 1610612752 | 0021600131 | 0021600131 | NOV 12, 2016 | 2016年11月12日 | NYK @ TOR | NYK @ TOR | L | 大号 | 3 | 3 | 6 | 6 | 0.333 | 0.333 | 240 | 240 | 44 | 44 | … | … | 0.750 | 0.750 | 17 | 17 | 32 | 32 | 49 | 49 | 19 | 19 | 3 | 3 | 2 | 2 | 16 | 16 | 23 | 23 | 107 | 107 |
| 70 | 70 | 1610612752 | 1610612752 | 0021600125 | 0021600125 | NOV 11, 2016 | 2016年11月11日 | NYK @ BOS | NYK @ BOS | L | 大号 | 3 | 3 | 5 | 5 | 0.375 | 0.375 | 240 | 240 | 33 | 33 | … | … | 0.882 | 0.882 | 21 | 21 | 36 | 36 | 57 | 57 | 19 | 19 | 7 | 7 | 11 | 11 | 25 | 25 | 26 | 26 | 87 | 87 |
| 71 | 71 | 1610612752 | 1610612752 | 0021600106 | 0021600106 | NOV 09, 2016 | 2016年11月9日 | NYK vs. BKN | NYK对阵BKN | W | w ^ | 3 | 3 | 4 | 4 | 0.429 | 0.429 | 240 | 240 | 44 | 44 | … | … | 0.706 | 0.706 | 9 | 9 | 41 | 41 | 50 | 50 | 25 | 25 | 11 | 11 | 5 | 5 | 14 | 14 | 21 | 21 | 110 | 110 |
| 72 | 72 | 1610612752 | 1610612752 | 0021600087 | 0021600087 | NOV 06, 2016 | 2016年11月6日 | NYK vs. UTA | NYK vs.UTA | L | 大号 | 2 | 2 | 4 | 4 | 0.333 | 0.333 | 240 | 240 | 42 | 42 | … | … | 0.895 | 0.895 | 10 | 10 | 29 | 29 | 39 | 39 | 18 | 18 | 8 | 8 | 5 | 5 | 12 | 12 | 26 | 26 | 109 | 109 |
| 73 | 73 | 1610612752 | 1610612752 | 0021600073 | 0021600073 | NOV 04, 2016 | 2016年11月4日 | NYK @ CHI | NYK @ CHI | W | w ^ | 2 | 2 | 3 | 3 | 0.400 | 0.400 | 240 | 240 | 46 | 46 | … | … | 0.762 | 0.762 | 11 | 11 | 29 | 29 | 40 | 40 | 32 | 32 | 7 | 7 | 2 | 2 | 5 | 5 | 23 | 23 | 117 | 117 |
| 74 | 74 | 1610612752 | 1610612752 | 0021600058 | 0021600058 | NOV 02, 2016 | 2016年11月2日 | NYK vs. HOU | NYK vs.侯 | L | 大号 | 1 | 1个 | 3 | 3 | 0.250 | 0.250 | 240 | 240 | 37 | 37 | … | … | 0.680 | 0.680 | 7 | 7 | 27 | 27 | 34 | 34 | 18 | 18 | 10 | 10 | 6 | 6 | 16 | 16 | 22 | 22 | 99 | 99 |
| 75 | 75 | 1610612752 | 1610612752 | 0021600050 | 0021600050 | NOV 01, 2016 | 2016年11月1日 | NYK @ DET | NYK @ DET | L | 大号 | 1 | 1个 | 2 | 2 | 0.333 | 0.333 | 240 | 240 | 35 | 35 | … | … | 0.800 | 0.800 | 8 | 8 | 35 | 35 | 43 | 43 | 18 | 18 | 6 | 6 | 9 | 9 | 11 | 11 | 20 | 20 | 89 | 89 |
| 76 | 76 | 1610612752 | 1610612752 | 0021600028 | 0021600028 | OCT 29, 2016 | 2016年10月29日 | NYK vs. MEM | NYK与MEM | W | w ^ | 1 | 1个 | 1 | 1个 | 0.500 | 0.500 | 240 | 240 | 40 | 40 | … | … | 0.641 | 0.641 | 6 | 6 | 35 | 35 | 41 | 41 | 24 | 24 | 4 | 4 | 4 | 4 | 12 | 12 | 25 | 25 | 111 | 111 |
| 77 | 77 | 1610612752 | 1610612752 | 0021600001 | 0021600001 | OCT 25, 2016 | 2016年10月25日 | NYK @ CLE | NYK @ CLE | L | 大号 | 0 | 0 | 1 | 1个 | 0.000 | 0.000 | 240 | 240 | 32 | 32 | … | … | 0.750 | 0.750 | 13 | 13 | 29 | 29 | 42 | 42 | 17 | 17 | 6 | 6 | 6 | 6 | 18 | 18 | 22 | 22 | 88 | 88 |
78 rows × 27 columns
78行×27列
Looks like this can be manipulated to get rest days:
看起来可以这样来休息一下:
| Team_ID | Team_ID | Game_ID | Game_ID | GAME_DATE | GAME_DATE | MATCHUP | 配对 | WL | WL | W | w ^ | L | 大号 | W_PCT | PCT | MIN | 最低 | FGM | 女性外阴残割 | … | … | OREB | OREB | DREB | DREB | REB | REB | AST | AST | STL | STL | BLK | 黑色 | TOV | TOV | PF | PF | PTS | PTS | DAYS_REST | DAYS_REST | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | 0021601160 | 0021601160 | 2017-04-04 | 2017-04-04 | NYK vs. CHI | NYK vs.CHI | W | w ^ | 30 | 30 | 48 | 48 | 0.385 | 0.385 | 240 | 240 | 42 | 42 | … | … | 16 | 16 | 37 | 37 | 53 | 53 | 26 | 26 | 5 | 5 | 7 | 7 | 15 | 15 | 22 | 22 | 100 | 100 | 2 days | 2天 |
| 1 | 1个 | 1610612752 | 1610612752 | 0021601145 | 0021601145 | 2017-04-02 | 2017-04-02 | NYK vs. BOS | NYK与BOS | L | 大号 | 29 | 29 | 48 | 48 | 0.377 | 0.377 | 240 | 240 | 33 | 33 | … | … | 8 | 8 | 24 | 24 | 32 | 32 | 20 | 20 | 12 | 12 | 2 | 2 | 11 | 11 | 20 | 20 | 94 | 94 | 2 days | 2天 |
| 2 | 2 | 1610612752 | 1610612752 | 0021601133 | 0021601133 | 2017-03-31 | 2017-03-31 | NYK @ MIA | NYK @ MIA | W | w ^ | 29 | 29 | 47 | 47 | 0.382 | 0.382 | 240 | 240 | 38 | 38 | … | … | 8 | 8 | 31 | 31 | 39 | 39 | 25 | 25 | 9 | 9 | 5 | 5 | 14 | 14 | 18 | 18 | 98 | 98 | 2 days | 2天 |
| 3 | 3 | 1610612752 | 1610612752 | 0021601115 | 0021601115 | 2017-03-29 | 2017-03-29 | NYK vs. MIA | NYK与MIA | L | 大号 | 28 | 28 | 47 | 47 | 0.373 | 0.373 | 240 | 240 | 33 | 33 | … | … | 17 | 17 | 35 | 35 | 52 | 52 | 19 | 19 | 2 | 2 | 6 | 6 | 14 | 14 | 16 | 16 | 88 | 88 | 2 days | 2天 |
| 4 | 4 | 1610612752 | 1610612752 | 0021601098 | 0021601098 | 2017-03-27 | 2017-03-27 | NYK vs. DET | NYK与DET | W | w ^ | 28 | 28 | 46 | 46 | 0.378 | 0.378 | 240 | 240 | 45 | 45 | … | … | 4 | 4 | 33 | 33 | 37 | 37 | 26 | 26 | 13 | 13 | 5 | 5 | 12 | 12 | 16 | 16 | 109 | 109 | 2 days | 2天 |
5 rows × 28 columns
5行×28列
df_game_log.dtypes Team_ID int64 Game_ID object GAME_DATE datetime64[ns] MATCHUP object WL object W int64 L int64 W_PCT float64 MIN int64 FGM int64 FGA int64 FG_PCT float64 FG3M int64 FG3A int64 FG3_PCT float64 FTM int64 FTA int64 FT_PCT float64 OREB int64 DREB int64 REB int64 AST int64 STL int64 BLK int64 TOV int64 PF int64 PTS int64 DAYS_REST timedelta64[ns] dtype: objectdf_game_log.dtypes Team_ID int64 Game_ID object GAME_DATE datetime64[ns] MATCHUP object WL object W int64 L int64 W_PCT float64 MIN int64 FGM int64 FGA int64 FG_PCT float64 FG3M int64 FG3A int64 FG3_PCT float64 FTM int64 FTA int64 FT_PCT float64 OREB int64 DREB int64 REB int64 AST int64 STL int64 BLK int64 TOV int64 PF int64 PTS int64 DAYS_REST timedelta64[ns] dtype: object
Team_ID int64 Game_ID object GAME_DATE datetime64[ns] MATCHUP object WL object W int64 L int64 W_PCT float64 MIN int64 FGM int64 FGA int64 FG_PCT float64 FG3M int64 FG3A int64 FG3_PCT float64 FTM int64 FTA int64 FT_PCT float64 OREB int64 DREB int64 REB int64 AST int64 STL int64 BLK int64 TOV int64 PF int64 PTS int64 DAYS_REST float64 dtype: objectTeam_ID int64 Game_ID object GAME_DATE datetime64[ns] MATCHUP object WL object W int64 L int64 W_PCT float64 MIN int64 FGM int64 FGA int64 FG_PCT float64 FG3M int64 FG3A int64 FG3_PCT float64 FTM int64 FTA int64 FT_PCT float64 OREB int64 DREB int64 REB int64 AST int64 STL int64 BLK int64 TOV int64 PF int64 PTS int64 DAYS_REST float64 dtype: object
This looks like we’ll get all the info for all games. We’ll start by appending the information for a single game and then try to do it for all dates:
看来我们将获得所有游戏的所有信息。 我们将从为单个游戏添加信息开始,然后尝试在所有日期进行:
| Team_ID | Team_ID | Game_ID | Game_ID | GAME_DATE | GAME_DATE | MATCHUP | 配对 | WL | WL | W | w ^ | L | 大号 | W_PCT | PCT | MIN | 最低 | FGM | 女性外阴残割 | … | … | OREB | OREB | DREB | DREB | REB | REB | AST | AST | STL | STL | BLK | 黑色 | TOV | TOV | PF | PF | PTS | PTS | DAYS_REST | DAYS_REST | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | 0021601160 | 0021601160 | 2017-04-04 | 2017-04-04 | NYK vs. CHI | NYK vs.CHI | W | w ^ | 30 | 30 | 48 | 48 | 0.385 | 0.385 | 240 | 240 | 42 | 42 | … | … | 16 | 16 | 37 | 37 | 53 | 53 | 26 | 26 | 5 | 5 | 7 | 7 | 15 | 15 | 22 | 22 | 100 | 100 | 2.0 | 2.0 |
| 1 | 1个 | 1610612752 | 1610612752 | 0021601145 | 0021601145 | 2017-04-02 | 2017-04-02 | NYK vs. BOS | NYK与BOS | L | 大号 | 29 | 29 | 48 | 48 | 0.377 | 0.377 | 240 | 240 | 33 | 33 | … | … | 8 | 8 | 24 | 24 | 32 | 32 | 20 | 20 | 12 | 12 | 2 | 2 | 11 | 11 | 20 | 20 | 94 | 94 | 2.0 | 2.0 |
| 2 | 2 | 1610612752 | 1610612752 | 0021601133 | 0021601133 | 2017-03-31 | 2017-03-31 | NYK @ MIA | NYK @ MIA | W | w ^ | 29 | 29 | 47 | 47 | 0.382 | 0.382 | 240 | 240 | 38 | 38 | … | … | 8 | 8 | 31 | 31 | 39 | 39 | 25 | 25 | 9 | 9 | 5 | 5 | 14 | 14 | 18 | 18 | 98 | 98 | 2.0 | 2.0 |
| 3 | 3 | 1610612752 | 1610612752 | 0021601115 | 0021601115 | 2017-03-29 | 2017-03-29 | NYK vs. MIA | NYK与MIA | L | 大号 | 28 | 28 | 47 | 47 | 0.373 | 0.373 | 240 | 240 | 33 | 33 | … | … | 17 | 17 | 35 | 35 | 52 | 52 | 19 | 19 | 2 | 2 | 6 | 6 | 14 | 14 | 16 | 16 | 88 | 88 | 2.0 | 2.0 |
| 4 | 4 | 1610612752 | 1610612752 | 0021601098 | 0021601098 | 2017-03-27 | 2017-03-27 | NYK vs. DET | NYK与DET | W | w ^ | 28 | 28 | 46 | 46 | 0.378 | 0.378 | 240 | 240 | 45 | 45 | … | … | 4 | 4 | 33 | 33 | 37 | 37 | 26 | 26 | 13 | 13 | 5 | 5 | 12 | 12 | 16 | 16 | 109 | 109 | 2.0 | 2.0 |
5 rows × 28 columns
5行×28列
#Get the dates from the game logs and pass them into the other functions: dates = df_game_log['GAME_DATE'] print len(dates) 78#Get the dates from the game logs and pass them into the other functions: dates = df_game_log['GAME_DATE'] print len(dates) 78
game_infogame_info
| TEAM_ID | TEAM_ID | TEAM_NAME | 队名 | PASS_TYPE | PASS_TYPE | G | G | PASS_FROM | 通行证 | PASS_TEAMMATE_PLAYER_ID | PASS_TEAMMATE_PLAYER_ID | FREQUENCY | 频率 | PASS | 通过 | AST | AST | FGM | 女性外阴残割 | FGA | FGA | FG_PCT | FG_PCT | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | GAME_DATE | GAME_DATE | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Baker, Ron | 贝克,罗恩 | 1627758 | 1627758 | 0.238 | 0.238 | 67.0 | 67.0 | 6.0 | 6.0 | 7.0 | 7.0 | 18.0 | 18.0 | 0.389 | 0.389 | 5.0 | 5.0 | 14.0 | 14.0 | 0.357 | 0.357 | 2.0 | 2.0 | 4.0 | 4.0 | 0.5 | 0.5 | 2017-03-31 | 2017-03-31 |
| 1 | 1个 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Vujacic, Sasha | 萨沙武贾西奇 | 2756 | 2756 | 0.149 | 0.149 | 42.0 | 42.0 | 7.0 | 7.0 | 8.0 | 8.0 | 15.0 | 15.0 | 0.533 | 0.533 | 5.0 | 5.0 | 9.0 | 9.0 | 0.556 | 0.556 | 3.0 | 3.0 | 6.0 | 6.0 | 0.5 | 0.5 | 2017-03-31 | 2017-03-31 |
| 2 | 2 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Hernangomez, Willy | 威利·埃尔南戈梅斯 | 1626195 | 1626195 | 0.131 | 0.131 | 37.0 | 37.0 | 2.0 | 2.0 | 3.0 | 3.0 | 5.0 | 5.0 | 0.600 | 0.600 | 3.0 | 3.0 | 5.0 | 5.0 | 0.600 | 0.600 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N | 2017-03-31 | 2017-03-31 |
| 3 | 3 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Porzingis, Kristaps | 克里斯蒂安(Kristaps)Porzingis | 204001 | 204001 | 0.113 | 0.113 | 32.0 | 32.0 | 3.0 | 3.0 | 4.0 | 4.0 | 9.0 | 9.0 | 0.444 | 0.444 | 4.0 | 4.0 | 7.0 | 7.0 | 0.571 | 0.571 | 0.0 | 0.0 | 2.0 | 2.0 | 0.0 | 0.0 | 2017-03-31 | 2017-03-31 |
| 4 | 4 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Lee, Courtney | 李·考特尼 | 201584 | 201584 | 0.106 | 0.106 | 30.0 | 30.0 | 1.0 | 1.0 | 4.0 | 4.0 | 6.0 | 6.0 | 0.667 | 0.667 | 4.0 | 4.0 | 5.0 | 5.0 | 0.800 | 0.800 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 2017-03-31 | 2017-03-31 |
| 5 | 5 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | O’Quinn, Kyle | 奥奎恩,凯尔 | 203124 | 203124 | 0.096 | 0.096 | 27.0 | 27.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 5.0 | 0.600 | 0.600 | 3.0 | 3.0 | 5.0 | 5.0 | 0.600 | 0.600 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N | 2017-03-31 | 2017-03-31 |
| 6 | 6 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Holiday, Justin | 假日,贾斯汀 | 203200 | 203200 | 0.082 | 0.082 | 23.0 | 23.0 | 2.0 | 2.0 | 4.0 | 4.0 | 5.0 | 5.0 | 0.800 | 0.800 | 3.0 | 3.0 | 3.0 | 3.0 | 1.000 | 1.000 | 1.0 | 1.0 | 2.0 | 2.0 | 0.5 | 0.5 | 2017-03-31 | 2017-03-31 |
| 7 | 7 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Randle, Chasson | 查森·兰德尔 | 1626184 | 1626184 | 0.057 | 0.057 | 16.0 | 16.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 2.0 | 0.000 | 0.000 | 0.0 | 0.0 | 2.0 | 2.0 | 0.000 | 0.000 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N | 2017-03-31 | 2017-03-31 |
| 8 | 8 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | made | 制作 | 1 | 1个 | Ndour, Maurice | 恩杜尔,莫里斯 | 1626254 | 1626254 | 0.028 | 0.028 | 8.0 | 8.0 | 1.0 | 1.0 | 1.0 | 1.0 | 2.0 | 2.0 | 0.500 | 0.500 | 1.0 | 1.0 | 2.0 | 2.0 | 0.500 | 0.500 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N | 2017-03-31 | 2017-03-31 |
df_sum.reset_index(level = 0, inplace = True) df_sumdf_sum.reset_index(level = 0, inplace = True) df_sum
| GAME_DATE | GAME_DATE | TEAM_ID | TEAM_ID | G | G | PASS_TEAMMATE_PLAYER_ID | PASS_TEAMMATE_PLAYER_ID | FREQUENCY | 频率 | PASS | 通过 | AST | AST | FGM | 女性外阴残割 | FGA | FGA | FG_PCT | FG_PCT | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2017-03-31 | 2017-03-31 | 14495514768 | 14495514768 | 9 | 9 | 7321056 | 7321056 | 1.0 | 1.0 | 282.0 | 282.0 | 25.0 | 25.0 | 34.0 | 34.0 | 67.0 | 67.0 | 4.533 | 4.533 | 28.0 | 28.0 | 52.0 | 52.0 | 4.984 | 4.984 | 6.0 | 6.0 | 15.0 | 15.0 | 1.5 | 1.5 |
When we merge this row back up to the bigger dataframe, we can drop the columns we don’t need.
当我们将此行合并回更大的数据框时,我们可以删除不需要的列。
shot_infoshot_info
| TEAM_ID | TEAM_ID | TEAM_NAME | 队名 | SORT_ORDER | 排序 | G | G | CLOSE_DEF_DIST_RANGE | CLOSE_DEF_DIST_RANGE | FGA_FREQUENCY | FGA_FREQUENCY | FGM | 女性外阴残割 | FGA | FGA | FG_PCT | FG_PCT | EFG_PCT | EFG_PCT | FG2A_FREQUENCY | FG2A_FREQUENCY | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3A_FREQUENCY | FG3A_FREQUENCY | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 1 | 1个 | 1 | 1个 | 0-2 Feet – Very Tight | 0-2英尺–非常紧 | 0.200 | 0.200 | 8.0 | 8.0 | 16.0 | 16.0 | 0.500 | 0.500 | 0.500 | 0.500 | 0.200 | 0.200 | 8.0 | 8.0 | 16.0 | 16.0 | 0.500 | 0.500 | 0.000 | 0.000 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | N |
| 1 | 1个 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 2 | 2 | 1 | 1个 | 2-4 Feet – Tight | 2-4英尺–紧 | 0.450 | 0.450 | 15.0 | 15.0 | 36.0 | 36.0 | 0.417 | 0.417 | 0.417 | 0.417 | 0.425 | 0.425 | 15.0 | 15.0 | 34.0 | 34.0 | 0.441 | 0.441 | 0.025 | 0.025 | 0.0 | 0.0 | 2.0 | 2.0 | 0.0 | 0.0 |
| 2 | 2 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 3 | 3 | 1 | 1个 | 4-6 Feet – Open | 4-6英尺–开放 | 0.263 | 0.263 | 11.0 | 11.0 | 21.0 | 21.0 | 0.524 | 0.524 | 0.619 | 0.619 | 0.138 | 0.138 | 7.0 | 7.0 | 11.0 | 11.0 | 0.636 | 0.636 | 0.125 | 0.125 | 4.0 | 4.0 | 10.0 | 10.0 | 0.4 | 0.4 |
| 3 | 3 | 1610612752 | 1610612752 | New York Knicks | 纽约尼克斯 | 4 | 4 | 1 | 1个 | 6+ Feet – Wide Open | 6英尺以上-张开 | 0.088 | 0.088 | 4.0 | 4.0 | 7.0 | 7.0 | 0.571 | 0.571 | 0.714 | 0.714 | 0.038 | 0.038 | 2.0 | 2.0 | 3.0 | 3.0 | 0.667 | 0.667 | 0.050 | 0.050 | 2.0 | 2.0 | 4.0 | 4.0 | 0.5 | 0.5 |
df_sumdf_sum
| GAME_DATE | GAME_DATE | TEAM_ID | TEAM_ID | G | G | PASS_TEAMMATE_PLAYER_ID | PASS_TEAMMATE_PLAYER_ID | FREQUENCY | 频率 | PASS | 通过 | AST | AST | FGM | 女性外阴残割 | FGA | FGA | FG_PCT | FG_PCT | FG2M | FG2M | FG2A | FG2A | FG2_PCT | FG2_PCT | FG3M | FG3M | FG3A | FG3A | FG3_PCT | FG3_PCT | OPEN_SHOTS | OPEN_SHOTS | OPEN_EFG | OPEN_EFG | COVERED_EFG | COVERED_EFG | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2017-03-31 | 2017-03-31 | 14495514768 | 14495514768 | 9 | 9 | 7321056 | 7321056 | 1.0 | 1.0 | 282.0 | 282.0 | 25.0 | 25.0 | 34.0 | 34.0 | 67.0 | 67.0 | 4.533 | 4.533 | 28.0 | 28.0 | 52.0 | 52.0 | 4.984 | 4.984 | 6.0 | 6.0 | 15.0 | 15.0 | 1.5 | 1.5 | 28.0 | 28.0 | 0.642857 | 0.642857 | 0.442308 | 0.442308 |
Now to append the columns we need back up. This is going to work like a SQL left-join.
现在要追加列,我们需要备份。 这将像SQL左联接一样工作。
df_custom_boxscore.head(10)df_custom_boxscore.head(10)
| Team_ID | Team_ID | Game_ID | Game_ID | GAME_DATE | GAME_DATE | MATCHUP | 配对 | WL | WL | W | w ^ | L | 大号 | W_PCT | PCT | MIN | 最低 | FGM | 女性外阴残割 | … | … | BLK | 黑色 | TOV | TOV | PF | PF | PTS | PTS | DAYS_REST | DAYS_REST | PASS | 通过 | FG2M | FG2M | OPEN_SHOTS | OPEN_SHOTS | OPEN_EFG | OPEN_EFG | COVERED_EFG | COVERED_EFG | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | 0021601160 | 0021601160 | 2017-04-04 | 2017-04-04 | NYK vs. CHI | NYK vs.CHI | W | w ^ | 30 | 30 | 48 | 48 | 0.385 | 0.385 | 240 | 240 | 42 | 42 | … | … | 7 | 7 | 15 | 15 | 22 | 22 | 100 | 100 | 2.0 | 2.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 1 | 1个 | 1610612752 | 1610612752 | 0021601145 | 0021601145 | 2017-04-02 | 2017-04-02 | NYK vs. BOS | NYK与BOS | L | 大号 | 29 | 29 | 48 | 48 | 0.377 | 0.377 | 240 | 240 | 33 | 33 | … | … | 2 | 2 | 11 | 11 | 20 | 20 | 94 | 94 | 2.0 | 2.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 2 | 2 | 1610612752 | 1610612752 | 0021601133 | 0021601133 | 2017-03-31 | 2017-03-31 | NYK @ MIA | NYK @ MIA | W | w ^ | 29 | 29 | 47 | 47 | 0.382 | 0.382 | 240 | 240 | 38 | 38 | … | … | 5 | 5 | 14 | 14 | 18 | 18 | 98 | 98 | 2.0 | 2.0 | 282.0 | 282.0 | 28.0 | 28.0 | 28.0 | 28.0 | 0.642857 | 0.642857 | 0.442308 | 0.442308 |
| 3 | 3 | 1610612752 | 1610612752 | 0021601115 | 0021601115 | 2017-03-29 | 2017-03-29 | NYK vs. MIA | NYK与MIA | L | 大号 | 28 | 28 | 47 | 47 | 0.373 | 0.373 | 240 | 240 | 33 | 33 | … | … | 6 | 6 | 14 | 14 | 16 | 16 | 88 | 88 | 2.0 | 2.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 4 | 4 | 1610612752 | 1610612752 | 0021601098 | 0021601098 | 2017-03-27 | 2017-03-27 | NYK vs. DET | NYK与DET | W | w ^ | 28 | 28 | 46 | 46 | 0.378 | 0.378 | 240 | 240 | 45 | 45 | … | … | 5 | 5 | 12 | 12 | 16 | 16 | 109 | 109 | 2.0 | 2.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 5 | 5 | 1610612752 | 1610612752 | 0021601085 | 0021601085 | 2017-03-25 | 2017-03-25 | NYK @ SAS | NYK @ SAS | L | 大号 | 27 | 27 | 46 | 46 | 0.370 | 0.370 | 240 | 240 | 41 | 41 | … | … | 5 | 5 | 16 | 16 | 16 | 16 | 98 | 98 | 2.0 | 2.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 6 | 6 | 1610612752 | 1610612752 | 0021601071 | 0021601071 | 2017-03-23 | 2017-03-23 | NYK @ POR | NYK @ POR | L | 大号 | 27 | 27 | 45 | 45 | 0.375 | 0.375 | 240 | 240 | 36 | 36 | … | … | 9 | 9 | 11 | 11 | 20 | 20 | 95 | 95 | 1.0 | 1.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 7 | 7 | 1610612752 | 1610612752 | 0021601066 | 0021601066 | 2017-03-22 | 2017-03-22 | NYK @ UTA | 纽约@UTA | L | 大号 | 27 | 27 | 44 | 44 | 0.380 | 0.380 | 240 | 240 | 38 | 38 | … | … | 1 | 1个 | 11 | 11 | 26 | 26 | 101 | 101 | 2.0 | 2.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 8 | 8 | 1610612752 | 1610612752 | 0021601050 | 0021601050 | 2017-03-20 | 2017-03-20 | NYK @ LAC | 纽约@ LAC | L | 大号 | 27 | 27 | 43 | 43 | 0.386 | 0.386 | 240 | 240 | 40 | 40 | … | … | 1 | 1个 | 12 | 12 | 19 | 19 | 105 | 105 | 4.0 | 4.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 9 | 9 | 1610612752 | 1610612752 | 0021601016 | 0021601016 | 2017-03-16 | 2017-03-16 | NYK vs. BKN | NYK对阵BKN | L | 大号 | 27 | 27 | 42 | 42 | 0.391 | 0.391 | 240 | 240 | 41 | 41 | … | … | 4 | 4 | 7 | 7 | 26 | 26 | 110 | 110 | 2.0 | 2.0 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
10 rows × 33 columns
10行×33列
Looks like everything joined correctly for exactly the date we chose. Let’s make some modifications and then work on a script to join the rest of the dates.
看起来一切都在我们选择的日期正确地加入了。 让我们进行一些修改,然后使用脚本将其余的日期合并在一起。
We should be good to go!
我们应该很好走!
Put all the steps above into a function:
将以上所有步骤放入函数中:
def custom_boxscore(roster_id): game_logs = team.TeamGameLogs(roster_id) df_game_logs = game_logs.info() df_game_logs['GAME_DATE'] = pd.to_datetime(df_game_logs['GAME_DATE']) df_game_logs['DAYS_REST'] = df_game_logs['GAME_DATE'] - df_game_logs['GAME_DATE'].shift(-1) df_game_logs['DAYS_REST'] = df_game_logs['DAYS_REST'].astype('timedelta64[D]') ##Just like before, that should get us the gamelogs we need and the rest days column ##Now to loop through the list of dates for our other stats ##This will build up a dataframe of the custom stats and join that to the gamelogs df_all =pd.DataFrame() ##blank dataframe dates = df_game_logs['GAME_DATE'] for date in dates: game_info = team.TeamPassTracking(roster_id, date_from=date, date_to=date).passes_made() game_info['GAME_DATE'] = date ## We need to append the date to this so we can join back temp_df = game_info.groupby(['GAME_DATE']).sum() temp_df.reset_index(level = 0, inplace = True) ##now to get the shot info. For the most part, we're just reusing code we've already written open_info = team.TeamShotTracking(roster_id,date_from =date, date_to = date).closest_defender_shooting() open_info['OPEN'] = open_info['CLOSE_DEF_DIST_RANGE'].map(lambda x: True if 'Open' in x else False) temp_df['OPEN_SHOTS'] = open_info.loc[open_info['OPEN'] == True, 'FGA'].sum() temp_df['OPEN_EFG']= (open_info.loc[open_info['OPEN']== True, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== True, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== True, 'FGA'].sum()) temp_df['COVERED_EFG']= (open_info.loc[open_info['OPEN']== False, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== False, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== False, 'FGA'].sum()) ##append this to our bigger dataframe df_all = df_all.append(temp_df) df_boxscore = pd.merge(df_game_logs, df_all[['PASS', 'FG2M', 'FG2_PCT', 'OPEN_SHOTS', 'OPEN_EFG', 'COVERED_EFG']], how = 'left', left_on = df_game_logs['GAME_DATE'], right_on = df_all['GAME_DATE']) df_boxscore['PASS_AST'] = df_boxscore['PASS'] / df_boxscore['AST'] df_boxscore['RESULT'] = df_boxscore['WL'].map(lambda x: 1 if 'W' in x else 0 ) return df_boxscoredef custom_boxscore(roster_id): game_logs = team.TeamGameLogs(roster_id) df_game_logs = game_logs.info() df_game_logs['GAME_DATE'] = pd.to_datetime(df_game_logs['GAME_DATE']) df_game_logs['DAYS_REST'] = df_game_logs['GAME_DATE'] - df_game_logs['GAME_DATE'].shift(-1) df_game_logs['DAYS_REST'] = df_game_logs['DAYS_REST'].astype('timedelta64[D]') ##Just like before, that should get us the gamelogs we need and the rest days column ##Now to loop through the list of dates for our other stats ##This will build up a dataframe of the custom stats and join that to the gamelogs df_all =pd.DataFrame() ##blank dataframe dates = df_game_logs['GAME_DATE'] for date in dates: game_info = team.TeamPassTracking(roster_id, date_from=date, date_to=date).passes_made() game_info['GAME_DATE'] = date ## We need to append the date to this so we can join back temp_df = game_info.groupby(['GAME_DATE']).sum() temp_df.reset_index(level = 0, inplace = True) ##now to get the shot info. For the most part, we're just reusing code we've already written open_info = team.TeamShotTracking(roster_id,date_from =date, date_to = date).closest_defender_shooting() open_info['OPEN'] = open_info['CLOSE_DEF_DIST_RANGE'].map(lambda x: True if 'Open' in x else False) temp_df['OPEN_SHOTS'] = open_info.loc[open_info['OPEN'] == True, 'FGA'].sum() temp_df['OPEN_EFG']= (open_info.loc[open_info['OPEN']== True, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== True, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== True, 'FGA'].sum()) temp_df['COVERED_EFG']= (open_info.loc[open_info['OPEN']== False, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== False, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== False, 'FGA'].sum()) ##append this to our bigger dataframe df_all = df_all.append(temp_df) df_boxscore = pd.merge(df_game_logs, df_all[['PASS', 'FG2M', 'FG2_PCT', 'OPEN_SHOTS', 'OPEN_EFG', 'COVERED_EFG']], how = 'left', left_on = df_game_logs['GAME_DATE'], right_on = df_all['GAME_DATE']) df_boxscore['PASS_AST'] = df_boxscore['PASS'] / df_boxscore['AST'] df_boxscore['RESULT'] = df_boxscore['WL'].map(lambda x: 1 if 'W' in x else 0 ) return df_boxscore
Let’s see if this worked:
让我们看看这是否有效:
df_knicks_box_scores.head(10)df_knicks_box_scores.head(10)
| Team_ID | Team_ID | Game_ID | Game_ID | GAME_DATE | GAME_DATE | MATCHUP | 配对 | WL | WL | W | w ^ | L | 大号 | W_PCT | PCT | MIN | 最低 | FGM | 女性外阴残割 | … | … | PTS | PTS | DAYS_REST | DAYS_REST | PASS | 通过 | FG2M | FG2M | FG2_PCT | FG2_PCT | OPEN_SHOTS | OPEN_SHOTS | OPEN_EFG | OPEN_EFG | COVERED_EFG | COVERED_EFG | PASS/ASSIST | 通过/协助 | RESULT | 结果 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1610612752 | 1610612752 | 0021600845 | 0021600845 | 2017-02-15 | 2017-02-15 | NYK @ OKC | NYK @ OKC | L | 大号 | 23 | 23 | 34 | 34 | 0.404 | 0.404 | 240 | 240 | 41 | 41 | … | … | 105 | 105 | 3.0 | 3.0 | 339.0 | 339.0 | 26.0 | 26.0 | 4.070 | 4.070 | 38.0 | 38.0 | 0.500000 | 0.500000 | 0.572917 | 0.572917 | 17.842105 | 17.842105 | 0 | 0 |
| 1 | 1个 | 1610612752 | 1610612752 | 0021600817 | 0021600817 | 2017-02-12 | 2017-02-12 | NYK vs. SAS | NYK与SAS | W | w ^ | 23 | 23 | 33 | 33 | 0.411 | 0.411 | 240 | 240 | 34 | 34 | … | … | 94 | 94 | 2.0 | 2.0 | 261.0 | 261.0 | 22.0 | 22.0 | 4.882 | 4.882 | 28.0 | 28.0 | 0.750000 | 0.750000 | 0.437500 | 0.437500 | 14.500000 | 14.500000 | 1 | 1个 |
| 2 | 2 | 1610612752 | 1610612752 | 0021600800 | 0021600800 | 2017-02-10 | 2017-02-10 | NYK vs. DEN | NYK对阵DEN | L | 大号 | 22 | 22 | 33 | 33 | 0.400 | 0.400 | 240 | 240 | 52 | 52 | … | … | 123 | 123 | 2.0 | 2.0 | 313.0 | 313.0 | 31.0 | 31.0 | 5.733 | 5.733 | 46.0 | 46.0 | 0.652174 | 0.652174 | 0.638298 | 0.638298 | 8.694444 | 8.694444 | 0 | 0 |
| 3 | 3 | 1610612752 | 1610612752 | 0021600791 | 0021600791 | 2017-02-08 | 2017-02-08 | NYK vs. LAC | 纽约和洛杉矶 | L | 大号 | 22 | 22 | 32 | 32 | 0.407 | 0.407 | 240 | 240 | 46 | 46 | … | … | 115 | 115 | 2.0 | 2.0 | 336.0 | 336.0 | 36.0 | 36.0 | 4.981 | 4.981 | 47.0 | 47.0 | 0.542553 | 0.542553 | 0.544444 | 0.544444 | 13.440000 | 13.440000 | 0 | 0 |
| 4 | 4 | 1610612752 | 1610612752 | 0021600768 | 0021600768 | 2017-02-06 | 2017-02-06 | NYK vs. LAL | NYK对阵LAL | L | 大号 | 22 | 22 | 31 | 31 | 0.415 | 0.415 | 240 | 240 | 37 | 37 | … | … | 107 | 107 | 2.0 | 2.0 | 316.0 | 316.0 | 30.0 | 30.0 | 4.501 | 4.501 | 35.0 | 35.0 | 0.571429 | 0.571429 | 0.445652 | 0.445652 | 19.750000 | 19.750000 | 0 | 0 |
| 5 | 5 | 1610612752 | 1610612752 | 0021600759 | 0021600759 | 2017-02-04 | 2017-02-04 | NYK vs. CLE | NYK与CLE | L | 大号 | 22 | 22 | 30 | 30 | 0.423 | 0.423 | 240 | 240 | 39 | 39 | … | … | 104 | 104 | 3.0 | 3.0 | 308.0 | 308.0 | 21.0 | 21.0 | 3.457 | 3.457 | 46.0 | 46.0 | 0.510870 | 0.510870 | 0.486842 | 0.486842 | 13.391304 | 13.391304 | 0 | 0 |
| 6 | 6 | 1610612752 | 1610612752 | 0021600733 | 0021600733 | 2017-02-01 | 2017-02-01 | NYK @ BKN | NYK @ BKN | W | w ^ | 22 | 22 | 29 | 29 | 0.431 | 0.431 | 240 | 240 | 35 | 35 | … | … | 95 | 95 | 1.0 | 1.0 | 305.0 | 305.0 | 23.0 | 23.0 | 4.150 | 4.150 | 37.0 | 37.0 | 0.297297 | 0.297297 | 0.435484 | 0.435484 | 13.260870 | 13.260870 | 1 | 1个 |
| 7 | 7 | 1610612752 | 1610612752 | 0021600724 | 0021600724 | 2017-01-31 | 2017-01-31 | NYK @ WAS | NYK @ WAS | L | 大号 | 21 | 21 | 29 | 29 | 0.420 | 0.420 | 240 | 240 | 34 | 34 | … | … | 101 | 101 | 2.0 | 2.0 | 293.0 | 293.0 | 24.0 | 24.0 | 5.245 | 5.245 | 41.0 | 41.0 | 0.317073 | 0.317073 | 0.460784 | 0.460784 | 16.277778 | 16.277778 | 0 | 0 |
| 8 | 8 | 1610612752 | 1610612752 | 0021600711 | 0021600711 | 2017-01-29 | 2017-01-29 | NYK @ ATL | NYK @ ATL | L | 大号 | 21 | 21 | 28 | 28 | 0.429 | 0.429 | 340 | 340 | 51 | 51 | … | … | 139 | 139 | 2.0 | 2.0 | 479.0 | 479.0 | 32.0 | 32.0 | 4.137 | 4.137 | 64.0 | 64.0 | 0.437500 | 0.437500 | 0.500000 | 0.500000 | 14.968750 | 14.968750 | 0 | 0 |
| 9 | 9 | 1610612752 | 1610612752 | 0021600699 | 0021600699 | 2017-01-27 | 2017-01-27 | NYK vs. CHA | NYK对阵CHA | W | w ^ | 21 | 21 | 27 | 27 | 0.438 | 0.438 | 240 | 240 | 46 | 46 | … | … | 110 | 110 | 2.0 | 2.0 | 350.0 | 350.0 | 31.0 | 31.0 | 6.167 | 6.167 | 37.0 | 37.0 | 0.594595 | 0.594595 | 0.483051 | 0.483051 | 15.909091 | 15.909091 | 1 | 1个 |
10 rows × 36 columns
10行×36列
I’m going to throw in a safeguard against divide by 0 errors just in case. This is a really janky, ugly fix, but it’ll get the job done for the time being:
为了防万一,我将提出防止除以0错误的措施。 这是一个非常棘手的丑陋修复程序,但是暂时可以完成工作:
df_knicks_box_scores = custom_boxscore(knicks_id)df_knicks_box_scores = custom_boxscore(knicks_id)
Awesome! Looks like everything came out okay. With a team_id, we can do this with every team. We just need a get a list of team_ids and team names.
太棒了! 看起来一切都顺利了。 使用team_id,我们可以对每个团队执行此操作。 我们只需要获取team_id和团队名称的列表即可。
From the documentation:
从文档中:
http://nba-py.readthedocs.io/en/0.1a2/nba_py/
http://nba-py.readthedocs.io/en/0.1a2/nba_py/
df_teams.head()df_teams.head()
| TEAM | 球队 | TEAM_ID | TEAM_ID | ||
|---|---|---|---|---|---|
| 0 | 0 | Boston | 波斯顿 | 1610612738 | 1610612738 |
| 1 | 1个 | Cleveland | 克利夫兰 | 1610612739 | 1610612739 |
| 2 | 2 | Toronto | 多伦多 | 1610612761 | 1610612761 |
| 3 | 3 | Washington | 华盛顿州 | 1610612764 | 1610612764 |
| 4 | 4 | Milwaukee | 密尔沃基 | 1610612749 | 1610612749 |
Now we can pass in the team IDs to create custom boxscores for all teams.
现在,我们可以传入团队ID来为所有团队创建自定义Boxscore。
teams = df_teams['TEAM'] roster_ids = df_teams['TEAM_ID']teams = df_teams['TEAM'] roster_ids = df_teams['TEAM_ID']
Just feed in these two arrays into the function and we should be good to go.
只需将这两个数组输入函数中,我们就应该做好了。
I went ahead and did this for a few teams. The NBA’s website cuts you off if you make too many requests too quickly (hence all the sleep statements above).
我继续前进,并为一些团队做到了这一点。 如果您提出太多请求太快(因此上面的所有睡眠声明),NBA网站都会拒绝您。
After fiddling with it for a while, I was finally able to get the data for each team. You might have to run the code above piece by piece, or just use the CSVs here:
经过一段时间的摆弄,我终于能够获得每个团队的数据。 您可能需要逐段运行代码,或仅在此处使用CSV:
可视化 (Visualization)
Let’s see if we can visually represent anything about each team’s offense:
让我们看看我们是否可以直观地代表每支球队的进攻:
These visualizations are going to be done in Plotly because I think it’s the best vizualiation library out there for quickly and easily making graphs that are both visually appleaing and interactive, but feel free to use something else (although I can’t imagine why you would).
这些可视化将在Plotly中完成,因为我认为它是最好的vizualiation库,可以快速轻松地制作既可视化又可交互的图形,但可以随意使用其他图形(尽管我无法想象为什么会这样) )。
This is going to break my heart a bit…but lets compare some of the stats fetched between the Knicks and teams that aren’t the Knicks.
这会让我有些伤心……但是让我们比较一下尼克斯队和不是尼克斯队的球员之间取得的一些数据。
Something about not counting another man’s money right?
关于不算另一个人的钱的事情对吗?
import plotly.plotly as py import plotly.graph_objs as go trace0 = go.Box( y=knicks['PASS'], name='Knicks', boxmean='sd' ) trace1 = go.Box( y=spurs['PASS'], name='Spurs', boxmean='sd' ) trace2 = go.Box( y=warriors['PASS'], name='Warriors', boxmean='sd' ) trace3 = go.Box( y=thunder['PASS'], name='Thunder', boxmean='sd' ) trace4 = go.Box( y=celtics['PASS'], name='Celtics', boxmean='sd' ) layout = go.Layout( title='Passing Box Plot', ) data = [trace0, trace1, trace2, trace3, trace4] fig = go.Figure(data=data, layout=layout) py.iplot(fig)import plotly.plotly as py import plotly.graph_objs as go trace0 = go.Box( y=knicks['PASS'], name='Knicks', boxmean='sd' ) trace1 = go.Box( y=spurs['PASS'], name='Spurs', boxmean='sd' ) trace2 = go.Box( y=warriors['PASS'], name='Warriors', boxmean='sd' ) trace3 = go.Box( y=thunder['PASS'], name='Thunder', boxmean='sd' ) trace4 = go.Box( y=celtics['PASS'], name='Celtics', boxmean='sd' ) layout = go.Layout( title='Passing Box Plot', ) data = [trace0, trace1, trace2, trace3, trace4] fig = go.Figure(data=data, layout=layout) py.iplot(fig)
Ignoring the outlier from the 4OT Knicks-Hawks game, this graph is pretty telling. Obviously this isn’t the full story, but it looks like the Spurs and Thunder play pretty consistent but different offenses . What’s really interesting is that despite the Spurs and Warriors having coaches and systems that emphasize ball movement, they throw FEWER passes than a team like the Knicks.
忽略4OT Knicks-Hawks游戏中的异常值,此图非常清楚。 显然这还不是完整的故事,但看起来马刺和雷霆的表现相当一致,但进攻方式却不同。 真正有趣的是,尽管马刺和勇士拥有强调球运动的教练和系统,但与尼克斯这样的球队相比,他们拥有更多的传球机会。
Let’s look at if those passes translate to assists:
让我们看看这些通行证是否可以转化为助攻:
These two graphs in conjunction are pretty telling. On average, it takes the Knicks almost 2 more passes than the Spurs, and 5 more than the Warriors to get an assist.
将这两个图结合起来很不错。 平均而言,尼克斯需要比马刺多2次传球,比勇士多5次才能得到助攻。
Going by this graph every, ~10th pass the Warriors make results in an assist. From the previous graph, we see that they make an average of 313 passes a game. This almost lines up with their season average of roughly 31 assists/game.
每次经过这个图表,勇士队都会在第10次传球中获得助攻。 从上一张图表中,我们可以看到他们平均每局进行313次传球。 这几乎与他们每赛季约31次助攻的赛季平均水平相符。
The standard deviation of the above graph can be interpreted in a few ways. On one hand, it’s a loose metric of playstyle consistency; teams that play the same way through the entire game are probably going to have a lower standard deviation than teams who pass the ball for 3 quarters and forget to in the 4th (cough cough, New York, cough cough). On the other hand, teams might have different playstyles depending on the lineups they have on the floor, resulting in a higher standard deviation (Spurs).
上图的标准偏差可以通过几种方式解释。 一方面,这是游戏风格一致性的宽松指标; 在整个比赛中以相同方式进行比赛的球队,其标准偏差可能会比传球连续3个季度又忘记第4位的球员(咳嗽,纽约,咳嗽)的标准偏差要低。 另一方面,球队可能会有不同的打法,这取决于他们在场上的阵容,从而导致更高的标准差(马刺)。
The Thunder probably fall into this, most likely due to Russell Westbrook averaging over 10 of the team’s total 20 assists per game.
雷霆队很可能落入这个位置,这很可能是由于拉塞尔·威斯布鲁克平均每场20次助攻中超过10次。
Obviously, there’s a lot more to the story. How many passes led to FTs? Is there any correlation between passes per assist and wins? If anything, stats like these tell you more about what kind of offense a team runs, not how effectively they run it.
显然,这个故事还有很多。 有多少通行证导致了FT? 每个助攻的传球次数和获胜次数之间有相关性吗? 如果有的话,这些统计信息可以告诉您更多有关团队进攻的类型,而不是他们如何有效地进攻。
Now let’s see if there’s any noticeable difference in wins vs losses:
现在,我们来看看胜利与失败之间是否存在明显差异:
import plotly.plotly as py import plotly.graph_objs as go trace0 = go.Box( y=knicks.loc[knicks['WL'] == 'W']['PASS_AST'], name='Knicks Wins', boxmean='sd' ) trace1 = go.Box( y=knicks.loc[knicks['WL'] == 'L']['PASS_AST'], name='Knicks Loss', boxmean='sd' ) trace2 = go.Box( y=spurs.loc[spurs['WL'] == 'W']['PASS_AST'], name='Spurs Wins', boxmean='sd' ) trace3 = go.Box( y=spurs.loc[spurs['WL'] == 'L']['PASS_AST'], name='Spurs Loss', boxmean='sd' ) trace4 = go.Box( y=warriors.loc[warriors['WL'] == 'W']['PASS_AST'], name='Warriors Wins', boxmean='sd' ) trace5 = go.Box( y=warriors.loc[warriors['WL'] == 'L']['PASS_AST'], name='Warriors Losses', boxmean='sd' ) trace6 = go.Box( y=thunder.loc[thunder['WL'] == 'W']['PASS_AST'], name='Thunder Wins', boxmean='sd' ) trace7 = go.Box( y=thunder.loc[thunder['WL'] == 'L']['PASS_AST'], name='Thunder Losses', boxmean='sd' ) trace8 = go.Box( y=celtics.loc[celtics['WL'] == 'W']['PASS_AST'], name='Celtics Wins', boxmean='sd' ) trace9 = go.Box( y=celtics.loc[celtics['WL'] == 'L']['PASS_AST'], name='Celtics Lossses', boxmean='sd' ) layout = go.Layout( title='Passes per Assist in Wins vs Losses', ) data = [trace0, trace1, trace2, trace3, trace4, trace5, trace6, trace7, trace8, trace9] fig = go.Figure(data=data, layout=layout) py.iplot(fig)import plotly.plotly as py import plotly.graph_objs as go trace0 = go.Box( y=knicks.loc[knicks['WL'] == 'W']['PASS_AST'], name='Knicks Wins', boxmean='sd' ) trace1 = go.Box( y=knicks.loc[knicks['WL'] == 'L']['PASS_AST'], name='Knicks Loss', boxmean='sd' ) trace2 = go.Box( y=spurs.loc[spurs['WL'] == 'W']['PASS_AST'], name='Spurs Wins', boxmean='sd' ) trace3 = go.Box( y=spurs.loc[spurs['WL'] == 'L']['PASS_AST'], name='Spurs Loss', boxmean='sd' ) trace4 = go.Box( y=warriors.loc[warriors['WL'] == 'W']['PASS_AST'], name='Warriors Wins', boxmean='sd' ) trace5 = go.Box( y=warriors.loc[warriors['WL'] == 'L']['PASS_AST'], name='Warriors Losses', boxmean='sd' ) trace6 = go.Box( y=thunder.loc[thunder['WL'] == 'W']['PASS_AST'], name='Thunder Wins', boxmean='sd' ) trace7 = go.Box( y=thunder.loc[thunder['WL'] == 'L']['PASS_AST'], name='Thunder Losses', boxmean='sd' ) trace8 = go.Box( y=celtics.loc[celtics['WL'] == 'W']['PASS_AST'], name='Celtics Wins', boxmean='sd' ) trace9 = go.Box( y=celtics.loc[celtics['WL'] == 'L']['PASS_AST'], name='Celtics Lossses', boxmean='sd' ) layout = go.Layout( title='Passes per Assist in Wins vs Losses', ) data = [trace0, trace1, trace2, trace3, trace4, trace5, trace6, trace7, trace8, trace9] fig = go.Figure(data=data, layout=layout) py.iplot(fig)
Apart from the Celtics, every team had to make more at least 1 more pass to get an assist in games they lost compared to games they lost. In one way, it’s almost like they have to “work harder” for assists.
除凯尔特人队外,每支球队必须多丢至少1个传球才能获得与输掉的比赛相比的帮助。 在某种程度上,这几乎就像他们必须“更加努力”获得帮助。
From the looks of this graph, the Warriors offense when its firing on all cylinders is a in a league of its own.
从该图的外观来看,勇士在进攻所有汽缸时都属于自己的进攻。
Just to reiterate once again, the purpose of the visualizations above is to ask, not answer questions.
再次重申一下,以上可视化的目的是询问而不是回答问题。
But now, let’s see if we can get any team specific insights from any of this:
但是现在,让我们看看是否可以从以下任何一个方面获得任何针对团队的见解:
The Clippers have played without Chris Paul and Blake Griffin, two of the best passers at their position in the league.
快船队没有克里斯·保罗和布雷克·格里芬,他们是联盟中最好的两个传球手。
Do the boxscores show how their offense has had to adjust?
方块分数是否显示他们的进攻情况如何调整?
/home/virajparekh/anaconda2/lib/python2.7/site-packages/ipykernel/__main__.py:2: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)/home/virajparekh/anaconda2/lib/python2.7/site-packages/ipykernel/__main__.py:2: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)
| Unnamed: 0 | 未命名:0 | Team_ID | Team_ID | Game_ID | Game_ID | GAME_DATE | GAME_DATE | MATCHUP | 配对 | WL | WL | W | w ^ | L | 大号 | W_PCT | PCT | MIN | 最低 | … | … | DAYS_REST | DAYS_REST | PASS | 通过 | FG2M | FG2M | FG2_PCT | FG2_PCT | OPEN_SHOTS | OPEN_SHOTS | COVERED_SHOTS | COVERED_SHOTS | OPEN_EFG | OPEN_EFG | COVERED_EFG | COVERED_EFG | PASS_AST | 通行证 | RESULT | 结果 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 77 | 77 | 53.0 | 53.0 | 1610612746 | 1610612746 | 21600017 | 21600017 | 2016-10-27 | 2016-10-27 | LAC @ POR | LAC @ POR | W | w ^ | 1 | 1个 | 0 | 0 | 1.00 | 1.00 | 240 | 240 | … | … | NaN | N | 301.0 | 301.0 | 21.0 | 21.0 | 4.047 | 4.047 | 41.0 | 41.0 | 50.0 | 50.0 | 0.463415 | 0.463415 | 0.440000 | 0.440000 | 25.083333 | 25.083333 | 1.0 | 1.0 |
| 76 | 76 | 52.0 | 52.0 | 1610612746 | 1610612746 | 21600035 | 21600035 | 2016-10-30 | 2016-10-30 | LAC vs. UTA | LAC与UTA | W | w ^ | 2 | 2 | 0 | 0 | 1.00 | 1.00 | 240 | 240 | … | … | 3.0 | 3.0 | 275.0 | 275.0 | 22.0 | 22.0 | 4.757 | 4.757 | 34.0 | 34.0 | 48.0 | 48.0 | 0.558824 | 0.558824 | 0.375000 | 0.375000 | 16.176471 | 16.176471 | 1.0 | 1.0 |
| 75 | 75 | 51.0 | 51.0 | 1610612746 | 1610612746 | 21600045 | 21600045 | 2016-10-31 | 2016-10-31 | LAC vs. PHX | LAC与PHX | W | w ^ | 3 | 3 | 0 | 0 | 1.00 | 1.00 | 240 | 240 | … | … | 1.0 | 1.0 | 276.0 | 276.0 | 28.0 | 28.0 | 4.795 | 4.795 | 38.0 | 38.0 | 42.0 | 42.0 | 0.565789 | 0.565789 | 0.511905 | 0.511905 | 13.142857 | 13.142857 | 1.0 | 1.0 |
| 74 | 74 | 50.0 | 50.0 | 1610612746 | 1610612746 | 21600064 | 21600064 | 2016-11-02 | 2016-11-02 | LAC vs. OKC | LAC与OKC | L | 大号 | 3 | 3 | 1 | 1个 | 0.75 | 0.75 | 240 | 240 | … | … | 2.0 | 2.0 | 302.0 | 302.0 | 24.0 | 24.0 | 2.893 | 2.893 | 33.0 | 33.0 | 54.0 | 54.0 | 0.424242 | 0.424242 | 0.435185 | 0.435185 | 13.727273 | 13.727273 | 0.0 | 0.0 |
| 73 | 73 | 49.0 | 49.0 | 1610612746 | 1610612746 | 21600074 | 21600074 | 2016-11-04 | 2016-11-04 | LAC @ MEM | LAC @ MEM | W | w ^ | 4 | 4 | 1 | 1个 | 0.80 | 0.80 | 240 | 240 | … | … | 2.0 | 2.0 | 300.0 | 300.0 | 17.0 | 17.0 | 2.681 | 2.681 | 41.0 | 41.0 | 44.0 | 44.0 | 0.451220 | 0.451220 | 0.397727 | 0.397727 | 15.789474 | 15.789474 | 1.0 | 1.0 |
5 rows × 38 columns
5行×38列
clippers_rolling.head(10)clippers_rolling.head(10)
| GAME_DATE | GAME_DATE | PTS | PTS | TOV | TOV | PASS | 通过 | OPEN_SHOTS | OPEN_SHOTS | OPEN_EFG | OPEN_EFG | AST | AST | PASS_AST | 通行证 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 77 | 77 | 2016-10-27 | 2016-10-27 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 76 | 76 | 2016-10-30 | 2016-10-30 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 75 | 75 | 2016-10-31 | 2016-10-31 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 74 | 74 | 2016-11-02 | 2016-11-02 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 73 | 73 | 2016-11-04 | 2016-11-04 | 100.0 | 100.0 | 12.8 | 12.8 | 290.8 | 290.8 | 37.4 | 37.4 | 0.492698 | 0.492698 | 18.2 | 18.2 | 16.783881 | 16.783881 |
| 72 | 72 | 2016-11-05 | 2016-11-05 | 100.4 | 100.4 | 13.0 | 13.0 | 293.6 | 293.6 | 37.4 | 37.4 | 0.514649 | 0.514649 | 20.6 | 20.6 | 14.392215 | 14.392215 |
| 71 | 71 | 2016-11-07 | 2016-11-07 | 105.6 | 105.6 | 12.4 | 12.4 | 302.4 | 302.4 | 39.2 | 39.2 | 0.544745 | 0.544745 | 22.8 | 22.8 | 13.435492 | 13.435492 |
| 70 | 70 | 2016-11-09 | 2016-11-09 | 104.6 | 104.6 | 10.6 | 10.6 | 303.0 | 303.0 | 38.8 | 38.8 | 0.537143 | 0.537143 | 23.4 | 23.4 | 13.131921 | 13.131921 |
| 69 | 69 | 2016-11-11 | 2016-11-11 | 110.0 | 110.0 | 9.2 | 9.2 | 308.8 | 308.8 | 41.2 | 41.2 | 0.563405 | 0.563405 | 22.6 | 22.6 | 14.064244 | 14.064244 |
| 68 | 68 | 2016-11-12 | 2016-11-12 | 114.0 | 114.0 | 9.8 | 9.8 | 306.6 | 306.6 | 40.8 | 40.8 | 0.591110 | 0.591110 | 23.8 | 23.8 | 13.218349 | 13.218349 |
If we want to see all of this on the same graph, we need to normalize it. This means we’re going to scale each value by subtracting it from the mean, and dividing by standard deviation.
如果我们想在同一张图上看到所有这些,我们需要对其进行归一化。 这意味着我们将通过从平均值中减去每个值并除以标准偏差来缩放每个值。
This is a bit of a janky way to do so because it relies on the columns being in the same order.
这有点麻烦,因为它依赖于列的顺序相同。
clippers_rolling.head(10)clippers_rolling.head(10)
| GAME_DATE | GAME_DATE | PTS | PTS | TOV | TOV | PASS | 通过 | OPEN_SHOTS | OPEN_SHOTS | OPEN_EFG | OPEN_EFG | AST | AST | PASS_AST | 通行证 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 77 | 77 | 2016-10-27 | 2016-10-27 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 76 | 76 | 2016-10-30 | 2016-10-30 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 75 | 75 | 2016-10-31 | 2016-10-31 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 74 | 74 | 2016-11-02 | 2016-11-02 | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N | NaN | N |
| 73 | 73 | 2016-11-04 | 2016-11-04 | -0.705388 | -0.705388 | 0.033424 | 0.033424 | -0.403622 | -0.403622 | -0.504550 | -0.504550 | -0.714018 | -0.714018 | -0.878286 | -0.878286 | 0.739290 | 0.739290 |
| 72 | 72 | 2016-11-05 | 2016-11-05 | -0.672092 | -0.672092 | 0.088895 | 0.088895 | -0.284434 | -0.284434 | -0.504550 | -0.504550 | -0.480817 | -0.480817 | -0.376102 | -0.376102 | 0.083865 | 0.083865 |
| 71 | 71 | 2016-11-07 | 2016-11-07 | -0.239256 | -0.239256 | -0.077516 | -0.077516 | 0.090155 | 0.090155 | -0.202852 | -0.202852 | -0.161093 | -0.161093 | 0.084234 | 0.084234 | -0.178321 | -0.178321 |
| 70 | 70 | 2016-11-09 | 2016-11-09 | -0.322493 | -0.322493 | -0.576750 | -0.576750 | 0.115695 | 0.115695 | -0.269896 | -0.269896 | -0.241857 | -0.241857 | 0.209780 | 0.209780 | -0.261513 | -0.261513 |
| 69 | 69 | 2016-11-11 | 2016-11-11 | 0.126991 | 0.126991 | -0.965042 | -0.965042 | 0.362583 | 0.362583 | 0.132369 | 0.132369 | 0.037146 | 0.037146 | 0.042385 | 0.042385 | -0.006014 | -0.006014 |
| 68 | 68 | 2016-11-12 | 2016-11-12 | 0.459943 | 0.459943 | -0.798631 | -0.798631 | 0.268936 | 0.268936 | 0.065325 | 0.065325 | 0.331470 | 0.331470 | 0.293477 | 0.293477 | -0.237828 | -0.237828 |
According to this, Blake’s abscence definitely had an effect on how the team runs their offense. Passes per assist went up just as total points went down after Blake’s injury.
据此,布雷克的缺席无疑对球队进攻的方式产生了影响。 布雷克受伤后,每助攻的传球次数都与总得分下降一样。
From the looks of it, the Clippers were starting to adjust to Blake being out just as CP3 got hurt, but for the most part, there’s too much noise here.
从外观上看,快船队开始调整以适应布雷克在CP3受伤时的状态,但在大多数情况下,这里的噪音太大了。
Blake gets injured almost every year, so I wonder how this graph looks for 2015-2016 data…..
布雷克几乎每年都会受伤,所以我想知道这张图如何看待2015-2016年的数据…..
This is just the tip of the iceburg. Exploratory analysis like this is about finding interesting questions, not answering them.
这只是冰山一角。 这样的探索性分析是关于找到有趣的问题,而不是回答它们。
建立管道: (Building the Pipe:)
Now that we can what we can do with the data, let’s get everything piping into a database.
现在我们可以处理数据了,让我们将所有内容整理到数据库中。
If you see yourself doing some of your own analysis or just want some more experience moving and cleaning data, this section is a high level overview of how to do that:
如果您看到自己在做一些自己的分析,或者只是想获得更多有关移动和清理数据的经验,那么本节将概述如何进行此操作:
I stored the output from the previous function in CSVs in the same directory as this notebook so they can be easily imported.
我将前一个函数的输出存储在与该笔记本相同的目录中的CSV文件中,以便可以轻松导入它们。
Pandas has a built in to_sql function that works with sqlalchemy:
Pandas具有与sqlalchemy一起使用的内置to_sql函数:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html
import glob, os import time files = [] os.chdir("YOUR_DIRECTORY_HERE") for file in glob.glob("*.csv"): files.append(file)import glob, os import time files = [] os.chdir("YOUR_DIRECTORY_HERE") for file in glob.glob("*.csv"): files.append(file)
The python sqlalchemy package supports most databases, so refer to the documentation for each db’s connection string:
python sqlalchemy软件包支持大多数数据库,因此请参考文档以获取每个数据库的连接字符串:
http://www.sqlalchemy.org/
http://www.sqlalchemy.org/
What would really make analysis easier is if information updated after every game. Let’s try using the info we have to update one of the CSVs, and then use that to do it for all the other files:
真正让分析变得更容易的是,如果每场比赛之后都更新信息。 让我们尝试使用必须更新其中一个CSV的信息,然后对所有其他文件使用该信息:
def update_info(file): file_name = str(file) name = file_name.partition('.csv')[0].replace(' ','_').replace('.','').lower() old_info = pd.read_csv(file_name) team_id = old_info['Team_ID'].max() new_logs = team.TeamGameLogs(team_id).info() old_info['GAME_DATE'] = pd.to_datetime(old_info['GAME_DATE']) order = old_info.columns new_logs['GAME_DATE'] = pd.to_datetime(new_logs['GAME_DATE']) ## If there's no new games for the team, return: if max(new_logs['GAME_DATE']) == max(old_info['GAME_DATE']): return new_logs['DAYS_REST']= new_logs['GAME_DATE'] - new_logs['GAME_DATE'].shift(-1) ##this gives us our days rest column new_logs['DAYS_REST']= new_logs['DAYS_REST'].astype('timedelta64[D]') ##keeping datatypes consistent new_logs['Game_ID'] = new_logs['Game_ID'].astype(str).astype(int) ##Append the info from the previously saved CSV and append it to the new game logs info = pd.concat([old_info, new_logs], ignore_index = True) ##Drop the duplicates info = info.drop_duplicates(['Game_ID'], keep = 'first') ## Sort by date info = info.sort(['GAME_DATE'], ascending = [0]) ##Reset the axis info = info.reset_index(drop = True) ##Find the dates where there's no values for any of the stats we fetched. We can make requests for only those dates updates = info.loc[np.isnan(info['COVERED_EFG'])] ##If the team's boxscore is up to date, return. if len(updates) == 0: return dates = updates['GAME_DATE'] df_passes = pd.DataFrame() for d in dates: ##All exactly the same as before game_info = team.TeamPassTracking(team_id, date_from =d, date_to = d).passes_made() game_info['EVENT_DATE'] = d df_sum = game_info.groupby(['EVENT_DATE']).sum() df_sum.reset_index(level = 0, inplace = True) open_info = team.TeamShotTracking(team_id, date_from =d, date_to = d).closest_defender_shooting() open_info['OPEN'] = open_info['CLOSE_DEF_DIST_RANGE'].map(lambda x: True if 'Open' in x else False) df_sum['OPEN_SHOTS'] = open_info.loc[open_info['OPEN']== True, 'FGA'].sum() df_sum['COVERED_SHOTS'] = open_info.loc[open_info['OPEN']== False, 'FGA'].sum() if (open_info.loc[open_info['OPEN']== True, 'FGA'].sum() > 0): df_sum['OPEN_EFG']= (open_info.loc[open_info['OPEN']== True, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== True, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== True, 'FGA'].sum()) else: df_sum['OPEN_EFG'] = 0 if (open_info.loc[open_info['OPEN']== False, 'FGA'].sum() > 0): df_sum['COVERED_EFG']= (open_info.loc[open_info['OPEN']== False, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== False, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== False, 'FGA'].sum()) else: df_sum['COVERED_EFG']=0 df_passes = df_passes.append(df_sum) df_passes = df_passes.reset_index(drop = True) ##Join the new stats with the old information. info.update(df_passes[['PASS', 'FG2M', 'FG2_PCT', 'OPEN_SHOTS', 'OPEN_EFG', 'COVERED_EFG','COVERED_SHOTS']]) ##Calculate these two post join in case there were any stat corrections info['PASS_AST'] = info['PASS'] / info['AST'] info['RESULT'] = info['WL'].map(lambda x: 1 if 'W' in x else 0 ) ##Reorder the columns in the dataframe info = info[order] ##Save to csv info.to_csv(file_name, index = False) ##Upload, and replace the information already there. Since we're working with a relatively small volume of data, ##upserts isn't worth the time. info.to_sql(con = eng, index = False, name = name, schema = 'nba', if_exists = 'replace') print name return infodef update_info(file): file_name = str(file) name = file_name.partition('.csv')[0].replace(' ','_').replace('.','').lower() old_info = pd.read_csv(file_name) team_id = old_info['Team_ID'].max() new_logs = team.TeamGameLogs(team_id).info() old_info['GAME_DATE'] = pd.to_datetime(old_info['GAME_DATE']) order = old_info.columns new_logs['GAME_DATE'] = pd.to_datetime(new_logs['GAME_DATE']) ## If there's no new games for the team, return: if max(new_logs['GAME_DATE']) == max(old_info['GAME_DATE']): return new_logs['DAYS_REST']= new_logs['GAME_DATE'] - new_logs['GAME_DATE'].shift(-1) ##this gives us our days rest column new_logs['DAYS_REST']= new_logs['DAYS_REST'].astype('timedelta64[D]') ##keeping datatypes consistent new_logs['Game_ID'] = new_logs['Game_ID'].astype(str).astype(int) ##Append the info from the previously saved CSV and append it to the new game logs info = pd.concat([old_info, new_logs], ignore_index = True) ##Drop the duplicates info = info.drop_duplicates(['Game_ID'], keep = 'first') ## Sort by date info = info.sort(['GAME_DATE'], ascending = [0]) ##Reset the axis info = info.reset_index(drop = True) ##Find the dates where there's no values for any of the stats we fetched. We can make requests for only those dates updates = info.loc[np.isnan(info['COVERED_EFG'])] ##If the team's boxscore is up to date, return. if len(updates) == 0: return dates = updates['GAME_DATE'] df_passes = pd.DataFrame() for d in dates: ##All exactly the same as before game_info = team.TeamPassTracking(team_id, date_from =d, date_to = d).passes_made() game_info['EVENT_DATE'] = d df_sum = game_info.groupby(['EVENT_DATE']).sum() df_sum.reset_index(level = 0, inplace = True) open_info = team.TeamShotTracking(team_id, date_from =d, date_to = d).closest_defender_shooting() open_info['OPEN'] = open_info['CLOSE_DEF_DIST_RANGE'].map(lambda x: True if 'Open' in x else False) df_sum['OPEN_SHOTS'] = open_info.loc[open_info['OPEN']== True, 'FGA'].sum() df_sum['COVERED_SHOTS'] = open_info.loc[open_info['OPEN']== False, 'FGA'].sum() if (open_info.loc[open_info['OPEN']== True, 'FGA'].sum() > 0): df_sum['OPEN_EFG']= (open_info.loc[open_info['OPEN']== True, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== True, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== True, 'FGA'].sum()) else: df_sum['OPEN_EFG'] = 0 if (open_info.loc[open_info['OPEN']== False, 'FGA'].sum() > 0): df_sum['COVERED_EFG']= (open_info.loc[open_info['OPEN']== False, 'FGM'].sum() + (.5 * open_info.loc[open_info['OPEN']== False, 'FG3M'].sum()))/(open_info.loc[open_info['OPEN']== False, 'FGA'].sum()) else: df_sum['COVERED_EFG']=0 df_passes = df_passes.append(df_sum) df_passes = df_passes.reset_index(drop = True) ##Join the new stats with the old information. info.update(df_passes[['PASS', 'FG2M', 'FG2_PCT', 'OPEN_SHOTS', 'OPEN_EFG', 'COVERED_EFG','COVERED_SHOTS']]) ##Calculate these two post join in case there were any stat corrections info['PASS_AST'] = info['PASS'] / info['AST'] info['RESULT'] = info['WL'].map(lambda x: 1 if 'W' in x else 0 ) ##Reorder the columns in the dataframe info = info[order] ##Save to csv info.to_csv(file_name, index = False) ##Upload, and replace the information already there. Since we're working with a relatively small volume of data, ##upserts isn't worth the time. info.to_sql(con = eng, index = False, name = name, schema = 'nba', if_exists = 'replace') print name return info
You can put the script above in a seperate .py file in the same directory as all of the team CSVs and schedule it via crontab to run automatically so your database and CSVs will always contain the latest information (assuming stats.nba.com doesn’t change anything on their end).
您可以将上面的脚本与所有团队CSV放在一个单独的.py文件中,并通过crontab安排它自动运行,以便您的数据库和CSV始终包含最新信息(假设stats.nba.com不会)不能改变他们的目标)。
Here’s a great tutorial on how to do so: https://www.youtube.com/watch?v=hDJ3XQzW8nk
这是有关如何执行此操作的出色教程: https : //www.youtube.com/watch?v=hDJ3XQzW8nk
包装全部 (Wrapping it all up)
That should be everything you need to get started.
那应该是您入门所需的一切。
If this was interesting to you and you want to test what you learned, here are a few excercises (in relatively increasing difficulty):
如果这对您很有趣,并且您想测试您学到的知识,请参考以下一些练习(难度相对增加):
1) The current boxscores only have a team_id in each table. Find a way to insert a column for a team name.
1)当前的Boxscores在每个表中只有一个team_id。 找到一种为团队名称插入列的方法。
2) Throw in some data about conested/unconested rebounding. This might be interesting when looking at different factors that contribute to wins.
2)投掷有关巢穴/未巢穴反弹的一些数据。 当查看有助于获胜的不同因素时,这可能很有趣。
3) There’s no player specific data in any of this. Try throwing in a column in each team’s boxscores with each game’s leading scorer.
3)任何一项都没有球员特定的数据。 尝试与每场比赛的领先得分手在每支球队的得分中加入一列。
4) Compare data across seasons! Is it possible to visualize changes to the Thunder offense after KD left? How different is Tom Thibideau’s offense from Sam Mitchell’s scheme in Minnesota?
4)比较各个季节的数据! KD离开后是否可以可视化雷霆进攻的变化? Tom Thibideau的罪行与Sam Mitchell在明尼苏达州的计划有何不同?
5) Do some data science! I’d love to see what sort of interesting models can be drummed up using this infastructure.
5)做一些数据科学! 我很想看看使用这种基础结构可以鼓出什么样的有趣模型。
Thanks for reading! Send your suggestions, solutions, or anything else to [email protected]
谢谢阅读! 将您的建议,解决方案或其他任何方式发送至[email protected]
翻译自: https://www.pybloggers.com/2017/04/data-wrangling-101-using-python-to-fetch-manipulate-visualize-nba-data/
python处理数据可视化