中文NER任务简析与深度算法模型总结和实战展示
目录
一、中文NER定义
1、什么是NER
2、怎么来完成NER
3、NER标注体系
二、基于pytoch和TensorFlow的深度学习算法NER实战
1、算法概览
2、算法实战
A、BiLstm+CRF+pytorch
B、BERT+CRF+pytorch
C、BERT+Pytorch
D、 Bert+CRF+Pytorch+多任务型
Bert+Crf+TensorFlow2.0
一、中文NER定义
1、什么是NER
命名实体识别——Named Entity Recognition——简称NER,是指从文本中识别出具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单举例:
6月15日,河南省文物考古研究所曹操高陵文物队公开发表声明承认:“从来没有说过出土的珠子是墓主人的识别出的实体结果:
{"organization": {"河南省文物考古研究所": [[6, 15]], "文物队": [[20, 22]]}, "name": {"曹操": [[16, 17]]}}}结果显示就把举例文本中的具有特定意义的实体,机构名和人名以及它们的具体位置都识别出来了。
以上就是一个NER任务的实际样例,在做具体的项目的时候,往往涉及到的实体类型更多,有可能成百上千,然后数据量更多。其他都是一样的。
2、怎么来完成NER
从NER的举例中可以看出,实体都是一些特定意义的短语和词语组成,那么很显然很直接的就能想到一种方法——直接建立一个超级大的实体词典,这类方法其实就是基于规则的方法。这样的方法往往成本很高,而且需要词汇、词表的维护以及专业领域知识。另外一类就是基于机器学习和深度学习的方法了,设计一种算法或者模型,然后让机器自己去识别实体。这类方法主要就是分类思想和最大概率序列思想。基于分类的思想,就是把文本的每一个字符的标签视为一个类别进行采用分类算法或者模型进行分类;而最大概率序列思想就是把NER理解为序列标注问题——每个字符前后出现的字符的合理性预测。
第一种方案,基于规则的词表之类的完成NER。其实就只有一个关键点,就是维护词表的建立,然后基于词表进行匹配;第二种方案就复杂一些涉及到算法,一般都需要进行算法的设计,数据集的标注等成本也不小。
3、NER标注体系
在使用算法和模型来进行NER任务的时候,不管是基于机器学习还是各种花式的深度学习算法模型,首先就需要确定NER的标注方法,对数据进行标注,确定文本元素是实体和非实体,以及确定实体分别是那些等等。先看一个例子:
文本数据:
6月15日,河南省文物考古研究所曹操高陵文物队公开发表声明承认:“从来没有说过出土的珠子是墓主人的实体数据:
{"organization": {"河南省文物考古研究所": [[6, 15]], "文物队": [[20, 22]]}, "name": {"曹操": [[16, 17]]}}}可以看到该条数据中有3个实体,分别是6-15和20-22的organization实体,6-17的name实体,共2类、3个不同的实体。
使用BIO体系进行标注的话,得到标注后的labels:
O O O O O O B I I I I I I I I I B I O O B I I O O O O O O O O O O O O O O O O O O O O O O O O O O O每个字的标签就是B、I、O——B表示实体的开始,I表示实体中间,O表示非实体。通过这样一种方式就能把每个实体和他们之间具体的位置区别开来。
有的时候实体还有单个字符的实体,同时也为了更加准确的区分每个实体,就开发出来不同的标注体系。从文章——序列标注方法BIO、BIOSE、IOB、BILOU、BMEWO、BMEWO+的异同——中可以得出现有的标注体系可以有如下的方式BIO、BIOSE、IOB、BILOU、BMEWO、BMEWO等。对标注体系中的每个字母做个说明:
- B stands for 'beginning' (signifies beginning of an NE)
- I stands for 'inside' (signifies that the word is inside an NE)
- O stands for 'outside' (signifies that the word is just a regular word outside of an NE)
- E stands for 'end' (signifies that the word is the end of an NE)
- S stands for 'singleton'(signifies that the single word is an NE )
- L stands for 'last' (signifies that the last word of an NE)
- U stands for 'unit'(signifies that the single word is an NE )
- M stands for 'middle' (signifies that the word is inside an NE)
- W stands for 'whole'(signifies that the whole word is an NE )
可以看到I和M是相同的意思,E和L是相同的意思,S、U、M和W具有类似的意思,只有细微的差别。实际上诸多主流的序列标注方法本质上就有3种,BIO,IOB,IBOES。它们之间可能的优劣如下:
- IOB因为缺少B-tag作为实体标注的头部表示,丢失了部分标注信息,导致很多任务上的效果不佳
- BIO解决了IOB的问题,所以整体效果优于IOB
- BIOES额外提供了End的信息,并给出了单个词汇的S-tag,提供了更多的信息,可能效果更优,但其需要预测的标签更多(多了E和S),效果也可能受到影响。
文章中得出的结论显示——大多数情况下,直接用BIO就可以了; 大多数情况下BIO和BIOES的结果差不太。我个人理解,在不同的数据集上可能会呈现出一些小的差异,比如说你数据集中单个字符的实体比较多,你使用BIO的效果可能就是比BIOES要差一点,但是差距不明显。要追求极限的准确性的话,就得在具体的业务场景下结合数据的特征,选择最合适的标注方法。
二、基于pytoch和TensorFlow的深度学习算法NER实战
1、算法概览
由于深度学习的算法模型来做NER效果是目前最好的——经过不严格的调研——目前做NER主要还是使用深度学习中的各种花式算法模型,毕竟现在都在追人工智能(智障)呀!通过资料得知,在2018年10月Bert出来之前,2015-2019年期间人们做NER任务都是基于BiLstm-CRF这个模型来进行的;2019年到现在快2021年了,就只有Bert-CRF或者Bert+BiLstm+CRF或者Bert或者其他的结合CRF的新模型(例如Lattice LSTM和FLAT模型——这些都是采用词汇增强的方法——把词汇信息融入模型中)。关于从2019-2020年这两年NER任务的论文都在做什么事情,知乎王院长分析的很到位——流水的NLP铁打的NER:命名实体识别实践与探索。现在主流的做法分为下面3类吧:
A、BiLstm+CRF
B、Bert+CRF或者Bert
C、新模型Lattice LSTM等词汇增强系列(包含GCN和Bert的结合等)
由于个人能力有限,后面的文章主要是就A和B两类算法模型做一个实现和效果演示,以及这个过程中遇到的一些坑。不涉及到相关的原理解释,网上有很多CRF、BiLstm以及BERT的文章;另外Lattice LSTM等词汇增强系列(Lattice LSTM和邱锡鹏团队的FLAT)等比较新,具体原理和代码,我还没有弄清楚,等弄清楚了再来修改博客。
2、算法实战
数据集
数据集来源于CLUEbenchmark在文本分类数据集THUCTC部分文本的标注结果,详细情况如下:
训练集:10748
验证集集:1343
按照不同标签类别统计,训练集数据分布如下(注:一条数据中出现的所有实体都进行标注,如果一条数据出现两个地址(address)实体,那么统计地址(address)类别数据的时候,算两条数据):
【训练集】标签数据分布如下:
地址(address):2829
书名(book):1131
公司(company):2897
游戏(game):2325
政府(government):1797
电影(movie):1109
姓名(name):3661
组织机构(organization):3075
职位(position):3052
景点(scene):1462
【验证集】标签数据分布如下:
地址(address):364
书名(book):152
公司(company):366
游戏(game):287
政府(government):244
电影(movie):150
姓名(name):451
组织机构(organization):344
职位(position):425
景点(scene):199部分实例如下:
{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": {"name": {"叶老桂": [[9, 11]]}, "company": {"浙商银行": [[0, 3]]}}}
{"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {"game": {"CSOL": [[4, 7]]}}}
{"text": "那不勒斯vs锡耶纳以及桑普vs热那亚之上呢?", "label": {"organization": {"那不勒斯": [[0, 3]], "锡耶纳": [[6, 8]], "桑普": [[11, 12]], "热那亚": [[15, 17]]}}}
{"text": "加勒比海盗3:世界尽头》的去年同期成绩死死甩在身后,后者则即将赶超《变形金刚》,", "label": {"movie": {"加勒比海盗3:世界尽头》": [[0, 11]], "《变形金刚》": [[33, 38]]}}}
{"text": "布鲁京斯研究所桑顿中国中心研究部主任李成说,东亚的和平与安全,是美国的“核心利益”之一。", "label": {"address": {"美国": [[32, 33]]}, "organization": {"布鲁京斯研究所桑顿中国中心": [[0, 12]]}, "name": {"李成": [[18, 19]]}, "position": {"研究部主任": [[13, 17]]}}}
{"text": "目前主赞助商暂时空缺,他们的球衣上印的是“unicef”(联合国儿童基金会),是公益性质的广告;", "label": {"organization": {"unicef": [[21, 26]], "联合国儿童基金会": [[29, 36]]}}}
{"text": "此数据换算成亚洲盘罗马客场可让平半低水。", "label": {"organization": {"罗马": [[9, 10]]}}}
{"text": "你们是最棒的!#英雄联盟d学sanchez创作的原声王", "label": {"game": {"英雄联盟": [[8, 11]]}}}
{"text": "除了吴湖帆时现精彩,吴待秋、吴子深、冯超然已然归入二三流了,", "label": {"name": {"吴湖帆": [[2, 4]], "吴待秋": [[10, 12]], "吴子深": [[14, 16]], "冯超然": [[18, 20]]}}}
{"text": "在豪门被多线作战拖累时,正是他们悄悄追赶上来的大好时机。重新找回全队的凝聚力是拉科赢球的资本。", "label": {"organization": {"拉科": [[39, 40]]}}}
简单说明一下,数据集label中数字表示实体在本条数据中的序列,从0开始。
算法模型
A、BiLstm+CRF+pytorch
这个就是比较经典的模型,简单的看一看该模型的架构图:
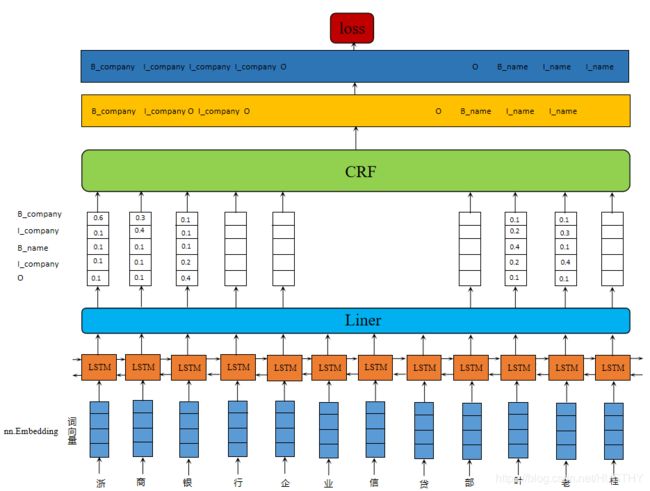
简单的说一说基本流程——文本数据中的每个字符,经过Embedding处理得到初始向量。然后把这些向量输入BiLstm模型经过记忆单元处理,输出每个字符对应标签的一个得分可能性。最后,把这些得分输入到CRF层。在CRF层中,选择预测得分最高的标签序列作为NER序列的最佳答案。话不多说,接下来直接开始coding。
在具体实践NER任务的时候,我把它分为单任务型和多任务型。单任务的意思就是——采用BIO标注方式,n类实体,那么就把这里的NER简单是视为对每个字进行3*n类labels进行分类任务。而多任务型就是——采用BIO标注方式,n类实体,首先把NER视为对每个字符进行3类别(BIO)的分类任务,其次视为n类别(n类实体)的分类任务,训练目标就是它们两者的loss和最小。在类别数目比较多的时候,我猜想多任务型的准确率应该会高一点的。对于单任务型,它的labels就只有一种结果,多任务型就有两种。
单任务型——标注采用的是BIOS
文本,labels——bios_attri_label
浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,B_company I_company I_company I_company O O O O O B_name I_name I_name O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O多任务——标注采用的是BIOS
文本、labels——bios、labels——attri
浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,B I I I O O O O O B I I O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O Ocompany company company company NULL NULL NULL NULL NULL name name name NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL单任务型——模型代码
这里是实现的模型是Bilstm+CRF,采用单任务型。标注方法用的是BIOS,共10类实体,那么总计labels就是40。对于LSTM的输入中embedding_size = 128;hidden_size = 384;对于字embedding采用torch.nn.Embedding(vocab_size,embedding_size)进行编码,然后进过dropout、LSTM网络模块、归一化模块和全连接分类器,最后输入到一个CRF模块中。CRF模块的实现比较复杂,这里直接调用别人写好的。
整体网络Bilstm+CRF定义:
import torch
import torch.nn as nn
from .crf import CRF
from torch.nn import LayerNorm
class SpatialDropout(nn.Dropout2d):
def __init__(self, p=0.6):
super(SpatialDropout, self).__init__(p=p)
def forward(self, x):
x = x.unsqueeze(2) # (N, T, 1, K)
x = x.permute(0, 3, 2, 1) # (N, K, 1, T)
x = super(SpatialDropout, self).forward(x) # (N, K, 1, T), some features are masked
x = x.permute(0, 3, 2, 1) # (N, T, 1, K)
x = x.squeeze(2) # (N, T, K)
return x
class BiLstmCRFNer(nn.Module):
"""
vocab_size:词典的大小
input_size = embedding_size:sequence_length 可以是句子的长度也可以比句子长
hidden_size:字向量的维度
biso_num_labels:标注的labels
bilstm后接一个分类器,然后再接一个CRF控制输出
nn.Embedding:随机进行字向量构建
"""
def __init__(self,vocab_size,embedding_size,hidden_size,biso_labels,drop_p):
super(BiLstmCRFNer,self).__init__()
self.embedding_size = embedding_size
self.embedding = nn.Embedding(vocab_size,embedding_size)
self.bilstm = nn.LSTM(input_size=embedding_size,hidden_size=hidden_size,batch_first=True,num_layers=2,dropout=drop_p,bidirectional=True)
self.dropout = SpatialDropout(drop_p)
self.layer_norm = LayerNorm(hidden_size * 2)
self.classifier = nn.Linear(hidden_size * 2, len(biso_labels))
self.crf = CRF(num_tags = len(biso_labels),batch_first=True)
def forward(self,input_ids, input_mask,bio_labels=None):
embs = self.embedding(input_ids)
embs = self.dropout(embs)
embs = embs*input_mask.float().unsqueeze(2)
seqence_output, _ = self.bilstm(embs)
seqence_output = self.layer_norm(seqence_output)
features = self.classifier(seqence_output)
outputs = (features,)
if bio_labels is not None:
loss = self.crf(emissions=features, tags=bio_labels, mask=input_mask)
outputs = (-1 * loss,) + outputs
return outputs # (loss), scores
CRF模块——(直接调用别人的):
import torch
import torch.nn as nn
from typing import List,Optional
class CRF(nn.Module):
"""
Attributes:
start_transitions (`~torch.nn.Parameter`): Start transition score tensor of size
``(num_tags,)``.
end_transitions (`~torch.nn.Parameter`): End transition score tensor of size
``(num_tags,)``.
transitions (`~torch.nn.Parameter`): Transition score tensor of size
``(num_tags, num_tags)``.
.. [LMP01] Lafferty, J., McCallum, A., Pereira, F. (2001).
"Conditional random fields: Probabilistic models for segmenting and
labeling sequence data". *Proc. 18th International Conf. on Machine
Learning*. Morgan Kaufmann. pp. 282–289.
.. _Viterbi algorithm: https://en.wikipedia.org/wiki/Viterbi_algorithm
"""
def __init__(self, num_tags: int, batch_first: bool = False) -> None:
if num_tags <= 0:
raise ValueError(f'invalid number of tags: {num_tags}')
super().__init__()
self.num_tags = num_tags
self.batch_first = batch_first
self.start_transitions = nn.Parameter(torch.empty(num_tags))
self.end_transitions = nn.Parameter(torch.empty(num_tags))
self.transitions = nn.Parameter(torch.empty(num_tags, num_tags))
self.reset_parameters()
def reset_parameters(self):
"""
Initialize the transition parameters.
The parameters will be initialized randomly from a uniform distribution
between -0.1 and 0.1.
:return:
"""
nn.init.uniform_(self.start_transitions,-0.1,0.1)
nn.init.uniform_(self.end_transitions,-0.1,0.1)
nn.init.uniform_(self.transitions,-0.1,0.1)
def __repr__(self) -> str:
return f'{self.__class__.__name__}(num_tags={self.num_tags})'
def forward(self, emissions: torch.Tensor,
tags: torch.LongTensor,
mask: Optional[torch.ByteTensor] = None,
reduction: str = 'mean'):
"""Compute the conditional log likelihood of a sequence of tags given emission scores.
Args:
emissions (`~torch.Tensor`): Emission score tensor of size
``(seq_length, batch_size, num_tags)`` if ``batch_first`` is ``False``,
``(batch_size, seq_length, num_tags)`` otherwise.
tags (`~torch.LongTensor`): Sequence of tags tensor of size
``(seq_length, batch_size)`` if ``batch_first`` is ``False``,
``(batch_size, seq_length)`` otherwise.
mask (`~torch.ByteTensor`): Mask tensor of size ``(seq_length, batch_size)``
if ``batch_first`` is ``False``, ``(batch_size, seq_length)`` otherwise.
reduction: Specifies the reduction to apply to the output:
``none|sum|mean|token_mean``. ``none``: no reduction will be applied.
``sum``: the output will be summed over batches. ``mean``: the output will be
averaged over batches. ``token_mean``: the output will be averaged over tokens.
Returns:
`~torch.Tensor`: The log likelihood. This will have size ``(batch_size,)`` if
reduction is ``none``, ``()`` otherwise.
"""
if reduction not in ('none', 'sum', 'mean', 'token_mean'):
raise ValueError(f'invalid reduction: {reduction}')
if mask is None:
mask = torch.ones_like(tags, dtype=torch.uint8, device=tags.device)
if mask.dtype != torch.uint8:
mask = mask.byte()
self._validate(emissions, tags=tags, mask=mask)\
if self.batch_first:
emissions = emissions.transpose(0, 1)
tags = tags.transpose(0, 1)
mask = mask.transpose(0, 1)
# shape: (batch_size,)
numerator = self._compute_score(emissions, tags, mask)
# shape: (batch_size,)
denominator = self._compute_normalizer(emissions, mask)
# shape: (batch_size,)
llh = numerator - denominator
if reduction == 'none':
return llh
if reduction == 'sum':
return llh.sum()
if reduction == 'mean':
return llh.mean()
return llh.sum() / mask.float().sum()
def decode(self, emissions: torch.Tensor,
mask: Optional[torch.ByteTensor] = None,
nbest: Optional[int] = None,
pad_tag: Optional[int] = None) -> List[List[List[int]]]:
"""Find the most likely tag sequence using Viterbi algorithm.
Args:
emissions (`~torch.Tensor`): Emission score tensor of size
``(seq_length, batch_size, num_tags)`` if ``batch_first`` is ``False``,
``(batch_size, seq_length, num_tags)`` otherwise.
mask (`~torch.ByteTensor`): Mask tensor of size ``(seq_length, batch_size)``
if ``batch_first`` is ``False``, ``(batch_size, seq_length)`` otherwise.
nbest (`int`): Number of most probable paths for each sequence
pad_tag (`int`): Tag at padded positions. Often input varies in length and
the length will be padded to the maximum length in the batch. Tags at
the padded positions will be assigned with a padding tag, i.e. `pad_tag`
Returns:
A PyTorch tensor of the best tag sequence for each batch of shape
(nbest, batch_size, seq_length)
"""
if nbest is None:
nbest = 1
if mask is None:
mask = torch.ones(emissions.shape[:2], dtype=torch.uint8,
device=emissions.device)
if mask.dtype != torch.uint8:
mask = mask.byte()
self._validate(emissions, mask=mask)
if self.batch_first:
emissions = emissions.transpose(0, 1)
mask = mask.transpose(0, 1)
if nbest == 1:
return self._viterbi_decode(emissions, mask, pad_tag).unsqueeze(0)
return self._viterbi_decode_nbest(emissions, mask, nbest, pad_tag)
def _validate(self, emissions: torch.Tensor,
tags: Optional[torch.LongTensor] = None,
mask: Optional[torch.ByteTensor] = None) -> None:
if emissions.dim() != 3:
raise ValueError(f'emissions must have dimension of 3, got {emissions.dim()}')
if emissions.size(2) != self.num_tags:
raise ValueError(
f'expected last dimension of emissions is {self.num_tags}, '
f'got {emissions.size(2)}')
if tags is not None:
if emissions.shape[:2] != tags.shape:
raise ValueError(
'the first two dimensions of emissions and tags must match, '
f'got {tuple(emissions.shape[:2])} and {tuple(tags.shape)}')
if mask is not None:
if emissions.shape[:2] != mask.shape:
raise ValueError(
'the first two dimensions of emissions and mask must match, '
f'got {tuple(emissions.shape[:2])} and {tuple(mask.shape)}')
no_empty_seq = not self.batch_first and mask[0].all()
no_empty_seq_bf = self.batch_first and mask[:, 0].all()
if not no_empty_seq and not no_empty_seq_bf:
raise ValueError('mask of the first timestep must all be on')
def _compute_score(self, emissions: torch.Tensor,
tags: torch.LongTensor,
mask: torch.ByteTensor) -> torch.Tensor:
# emissions: (seq_length, batch_size, num_tags)
# tags: (seq_length, batch_size)
# mask: (seq_length, batch_size)
seq_length, batch_size = tags.shape
mask = mask.float()
# Start transition score and first emission
# shape: (batch_size,)
score = self.start_transitions[tags[0]]
score += emissions[0, torch.arange(batch_size), tags[0]]
for i in range(1, seq_length):
# Transition score to next tag, only added if next timestep is valid (mask == 1)
# shape: (batch_size,)
score += self.transitions[tags[i - 1], tags[i]] * mask[i]
# Emission score for next tag, only added if next timestep is valid (mask == 1)
# shape: (batch_size,)
score += emissions[i, torch.arange(batch_size), tags[i]] * mask[i]
# End transition score
# shape: (batch_size,)
seq_ends = mask.long().sum(dim=0) - 1
# shape: (batch_size,)
last_tags = tags[seq_ends, torch.arange(batch_size)]
# shape: (batch_size,)
score += self.end_transitions[last_tags]
return score
def _compute_normalizer(self, emissions: torch.Tensor,
mask: torch.ByteTensor) -> torch.Tensor:
# emissions: (seq_length, batch_size, num_tags)
# mask: (seq_length, batch_size)
seq_length = emissions.size(0)
# Start transition score and first emission; score has size of
# (batch_size, num_tags) where for each batch, the j-th column stores
# the score that the first timestep has tag j
# shape: (batch_size, num_tags)
score = self.start_transitions + emissions[0]
for i in range(1, seq_length):
# Broadcast score for every possible next tag
# shape: (batch_size, num_tags, 1)
broadcast_score = score.unsqueeze(2)
# Broadcast emission score for every possible current tag
# shape: (batch_size, 1, num_tags)
broadcast_emissions = emissions[i].unsqueeze(1)
# Compute the score tensor of size (batch_size, num_tags, num_tags) where
# for each sample, entry at row i and column j stores the sum of scores of all
# possible tag sequences so far that end with transitioning from tag i to tag j
# and emitting
# shape: (batch_size, num_tags, num_tags)
next_score = broadcast_score + self.transitions + broadcast_emissions
# Sum over all possible current tags, but we're in score space, so a sum
# becomes a log-sum-exp: for each sample, entry i stores the sum of scores of
# all possible tag sequences so far, that end in tag i
# shape: (batch_size, num_tags)
next_score = torch.logsumexp(next_score, dim=1)
# Set score to the next score if this timestep is valid (mask == 1)
# shape: (batch_size, num_tags)
score = torch.where(mask[i].unsqueeze(1), next_score, score)
# End transition score
# shape: (batch_size, num_tags)
score += self.end_transitions
# Sum (log-sum-exp) over all possible tags
# shape: (batch_size,)
return torch.logsumexp(score, dim=1)
def _viterbi_decode(self, emissions: torch.FloatTensor,
mask: torch.ByteTensor,
pad_tag: Optional[int] = None) -> List[List[int]]:
# emissions: (seq_length, batch_size, num_tags)
# mask: (seq_length, batch_size)
# return: (batch_size, seq_length)
if pad_tag is None:
pad_tag = 0
device = emissions.device
seq_length, batch_size = mask.shape
# Start transition and first emission
# shape: (batch_size, num_tags)
score = self.start_transitions + emissions[0]
history_idx = torch.zeros((seq_length, batch_size, self.num_tags),
dtype=torch.long, device=device)
oor_idx = torch.zeros((batch_size, self.num_tags),
dtype=torch.long, device=device)
oor_tag = torch.full((seq_length, batch_size), pad_tag,
dtype=torch.long, device=device)
# - score is a tensor of size (batch_size, num_tags) where for every batch,
# value at column j stores the score of the best tag sequence so far that ends
# with tag j
# - history_idx saves where the best tags candidate transitioned from; this is used
# when we trace back the best tag sequence
# - oor_idx saves the best tags candidate transitioned from at the positions
# where mask is 0, i.e. out of range (oor)
# Viterbi algorithm recursive case: we compute the score of the best tag sequence
# for every possible next tag
for i in range(1, seq_length):
# Broadcast viterbi score for every possible next tag
# shape: (batch_size, num_tags, 1)
broadcast_score = score.unsqueeze(2)
# Broadcast emission score for every possible current tag
# shape: (batch_size, 1, num_tags)
broadcast_emission = emissions[i].unsqueeze(1)
# Compute the score tensor of size (batch_size, num_tags, num_tags) where
# for each sample, entry at row i and column j stores the score of the best
# tag sequence so far that ends with transitioning from tag i to tag j and emitting
# shape: (batch_size, num_tags, num_tags)
next_score = broadcast_score + self.transitions + broadcast_emission
# Find the maximum score over all possible current tag
# shape: (batch_size, num_tags)
next_score, indices = next_score.max(dim=1)
# Set score to the next score if this timestep is valid (mask == 1)
# and save the index that produces the next score
# shape: (batch_size, num_tags)
score = torch.where(mask[i].unsqueeze(-1), next_score, score)
indices = torch.where(mask[i].unsqueeze(-1), indices, oor_idx)
history_idx[i - 1] = indices
# End transition score
# shape: (batch_size, num_tags)
end_score = score + self.end_transitions
_, end_tag = end_score.max(dim=1)
# shape: (batch_size,)
seq_ends = mask.long().sum(dim=0) - 1
# insert the best tag at each sequence end (last position with mask == 1)
history_idx = history_idx.transpose(1, 0).contiguous()
history_idx.scatter_(1, seq_ends.view(-1, 1, 1).expand(-1, 1, self.num_tags),
end_tag.view(-1, 1, 1).expand(-1, 1, self.num_tags))
history_idx = history_idx.transpose(1, 0).contiguous()
# The most probable path for each sequence
best_tags_arr = torch.zeros((seq_length, batch_size),
dtype=torch.long, device=device)
best_tags = torch.zeros(batch_size, 1, dtype=torch.long, device=device)
for idx in range(seq_length - 1, -1, -1):
best_tags = torch.gather(history_idx[idx], 1, best_tags)
best_tags_arr[idx] = best_tags.data.view(batch_size)
return torch.where(mask, best_tags_arr, oor_tag).transpose(0, 1)
def _viterbi_decode_nbest(self, emissions: torch.FloatTensor,
mask: torch.ByteTensor,
nbest: int,
pad_tag: Optional[int] = None) -> List[List[List[int]]]:
# emissions: (seq_length, batch_size, num_tags)
# mask: (seq_length, batch_size)
# return: (nbest, batch_size, seq_length)
if pad_tag is None:
pad_tag = 0
device = emissions.device
seq_length, batch_size = mask.shape
# Start transition and first emission
# shape: (batch_size, num_tags)
score = self.start_transitions + emissions[0]
history_idx = torch.zeros((seq_length, batch_size, self.num_tags, nbest),
dtype=torch.long, device=device)
oor_idx = torch.zeros((batch_size, self.num_tags, nbest),
dtype=torch.long, device=device)
oor_tag = torch.full((seq_length, batch_size, nbest), pad_tag,
dtype=torch.long, device=device)
# + score is a tensor of size (batch_size, num_tags) where for every batch,
# value at column j stores the score of the best tag sequence so far that ends
# with tag j
# + history_idx saves where the best tags candidate transitioned from; this is used
# when we trace back the best tag sequence
# - oor_idx saves the best tags candidate transitioned from at the positions
# where mask is 0, i.e. out of range (oor)
# Viterbi algorithm recursive case: we compute the score of the best tag sequence
# for every possible next tag
for i in range(1, seq_length):
if i == 1:
broadcast_score = score.unsqueeze(-1)
broadcast_emission = emissions[i].unsqueeze(1)
# shape: (batch_size, num_tags, num_tags)
next_score = broadcast_score + self.transitions + broadcast_emission
else:
broadcast_score = score.unsqueeze(-1)
broadcast_emission = emissions[i].unsqueeze(1).unsqueeze(2)
# shape: (batch_size, num_tags, nbest, num_tags)
next_score = broadcast_score + self.transitions.unsqueeze(1) + broadcast_emission
# Find the top `nbest` maximum score over all possible current tag
# shape: (batch_size, nbest, num_tags)
next_score, indices = next_score.view(batch_size, -1, self.num_tags).topk(nbest, dim=1)
if i == 1:
score = score.unsqueeze(-1).expand(-1, -1, nbest)
indices = indices * nbest
# convert to shape: (batch_size, num_tags, nbest)
next_score = next_score.transpose(2, 1)
indices = indices.transpose(2, 1)
# Set score to the next score if this timestep is valid (mask == 1)
# and save the index that produces the next score
# shape: (batch_size, num_tags, nbest)
score = torch.where(mask[i].unsqueeze(-1).unsqueeze(-1), next_score, score)
indices = torch.where(mask[i].unsqueeze(-1).unsqueeze(-1), indices, oor_idx)
history_idx[i - 1] = indices
# End transition score shape: (batch_size, num_tags, nbest)
end_score = score + self.end_transitions.unsqueeze(-1)
_, end_tag = end_score.view(batch_size, -1).topk(nbest, dim=1)
# shape: (batch_size,)
seq_ends = mask.long().sum(dim=0) - 1
# insert the best tag at each sequence end (last position with mask == 1)
history_idx = history_idx.transpose(1, 0).contiguous()
history_idx.scatter_(1, seq_ends.view(-1, 1, 1, 1).expand(-1, 1, self.num_tags, nbest),
end_tag.view(-1, 1, 1, nbest).expand(-1, 1, self.num_tags, nbest))
history_idx = history_idx.transpose(1, 0).contiguous()
# The most probable path for each sequence
best_tags_arr = torch.zeros((seq_length, batch_size, nbest),
dtype=torch.long, device=device)
best_tags = torch.arange(nbest, dtype=torch.long, device=device) \
.view(1, -1).expand(batch_size, -1)
for idx in range(seq_length - 1, -1, -1):
best_tags = torch.gather(history_idx[idx].view(batch_size, -1), 1, best_tags)
best_tags_arr[idx] = best_tags.data.view(batch_size, -1) // nbest
return torch.where(mask.unsqueeze(-1), best_tags_arr, oor_tag).permute(2, 1, 0)DataSet部分,这里比较简单,主要是把文字通过词表映射为一个向量的过程,并封装成Tensor,可以分配批输入到模型中。文字通过词表映射向量的过程,也没有自己去实现,而是采用了transformers 的 BertTokenizer,可以很方便的完成映射过程。核心代码如下:
def convert_into_indextokens_and_segment_id(self,text):
tokeniz_text = self.tokenizer.tokenize(text[0:self.max_sentence_length])
input_ids = self.tokenizer.convert_tokens_to_ids(tokeniz_text)
attention_mask = [1] * len(input_ids)
pad_indextokens = [0] * (self.max_sentence_length - len(input_ids))
input_ids.extend(pad_indextokens)
attention_mask_pad = [0] * (self.max_sentence_length - len(attention_mask))
attention_mask.extend(attention_mask_pad)
return input_ids, attention_mask该函数中实现了文本到向量的映射,以及padding补0的操作。其他的代码,这里就不演示了。
另外就是模型的训练代码了,模型初始化,dataLoader加载数据,损失函数和学习率变化策略,优化器的使用,以及loss的更新。直接演示部分DataLoader初始化和模型训练代码:
#顺序执行,没有打乱,我实验的时候源代码是打乱了的使用randomSampler
train_sampler = SequentialSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.batch_size, collate_fn=collate_fn)
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps,num_training_steps=t_total)
model.zero_grad()
。。。。。。
othercode
for epoch in tqdm(range(args.epochs), desc='Epoch'):
for step, batch in enumerate(train_dataloader):
model.train()
batch = tuple(t.to(args.device) for t in batch)
inputs = {'input_ids': batch[0], 'attention_mask': batch[1], 'bio_labels': batch[3]}
outputs = model(**inputs)
biesos_logits = outputs[1]
loss = outputs[0]
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
scheduler.step()
optimizer.step()
model.zero_grad()
global_step += 1
。。。。。。
othercode整个流程很清晰,基于pytorch框架那一套模型训练的流程,注意model.train()一定不要忘记,同时loss的后向传播更新,优化器和模型的更新以及梯度置零。这里还对参数进行了梯度裁剪,避免或者缓解模型爆炸的问题。
最后关于模型的评价这里仍然选择Acc、F1和Recall之类的评价指标,由于这里个NER的标签可以视为多分类任务且以实体为单位而不是字符为单位和2分类任务的计算方式有所差异,把预测出来的实体和真是的实体做比对,按照混淆矩阵的定义来严格计算。特别注意的是,要得到每个字符的具体label,这里模型中使用了CRF,所以需要进行解码过程:
......
inputs = {'input_ids': batch[0], 'input_mask': batch[1], "bio_labels": batch[2]}
outputs = model(**inputs)
loss, biesos_logits = outputs[0], outputs[1]
biesos_tags = model.crf.decode(biesos_logits,inputs['input_mask'])
biesos_tags = biesos_tags.squeeze(0).cpu().numpy().tolist()
......截取最后的模型训练结果图:

可以看到每一类实体的各种详细评价指标,为了更好的评估模型的性能,我们要综合所有的实体一起来看,可以平均一下所有类别实体的各项评价指标。计算得知:F1 = 0.72 Precision = 0.69 recall = 0.722
B、BERT+CRF+pytorch
先给出模型结构图:

该模型BERT+CRF其实和BiLstm+CRF差不多的,唯一的不同就是字向量的编码方式一个是BERT模型得到一个是Bilstm得到;另外一方面。从图中可以看出,模型的输入也是不相同的。其他的部分都是类似的。
模型具体代码如下:
class BertCrfOneStageForNer(BertPreTrainedModel):
def __init__(self,config):
super(BertCrfOneStageForNer,self).__init__(config)
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.cls = nn.Linear(config.hidden_size,config.biso_num_labels)
self.crf = CRF(num_tags=config.biso_num_labels,batch_first=True)
def forward(self,input_ids, token_type_ids=None, attention_mask=None,bio_labels=None):
outputs = self.bert(input_ids = input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.cls(sequence_output)
outputs = (logits,)
if bio_labels is not None:
loss = self.crf(emissions = logits, tags=bio_labels, mask=attention_mask)
outputs = (-1*loss,)+outputs
return outputs # (loss), scores在Bert的实现上,这里是调用了huggingface库实现的Bert模型,细节就不展开了。其他的部分代码都是大同小异,值得注意的是以下几个细节影响模型的准确率:
1、文本数据映射的时候,数据集里含有英文单位,这里要把英文单位用空格隔开,不然BertTokenizer.tokenize(text)不能严格的按照字符来进行映射,这样会影响最后结果的准确性。
2、序列数据的标注采用BIOS的时候,标注的非实体类O不能用0来映射,需要使用非0数字来映射,因为Bert中有个padding需要用到0,不然把padding字符单位和非实体类O字符单位弄混淆了,也会影响最后结果的准确性。
3、sequence的长度在不同的Batch中要动态调整,这里的实现就是collate_fn函数,每个batch取自己的最长的那个序列作为每个sequence的长度。——结果表明在DataLoader中传入collate_fn()动态处理seq_len后,准确率会有一定的提升,同时也是减小内存占用。
1问题的处理很简单:
def convert_into_indextokens_and_segment_id(self,text):
text = ' '.join(text)
text = '[CLS]' + text + '[SEP]'
tokeniz_text = self.tokenizer.tokenize(text[0:self.max_sentence_length])
input_ids = self.tokenizer.convert_tokens_to_ids(tokeniz_text)
attention_mask = [1] * len(input_ids)
pad_indextokens = [0] * (self.max_sentence_length - len(input_ids))
input_ids.extend(pad_indextokens)
attention_mask_pad = [0] * (self.max_sentence_length - len(attention_mask))
attention_mask.extend(attention_mask_pad)
return input_ids, attention_mask把text文本用空格隔开。
3问题动态处理batch中seq的长度代码如下:
def collate_fn(batch):
all_input_ids, all_attention_mask, all_labels,input_lens = map(torch.stack, zip(*batch))
max_len = max(input_lens).item()
# print('max_len',max_len)
all_input_ids = all_input_ids[:, :max_len]
all_attention_mask = all_attention_mask[:, :max_len]
all_labels = all_labels[:,:max_len]
return all_input_ids, all_attention_mask, all_labels其他功能的代码就不展示了,看一看训练后的结果:
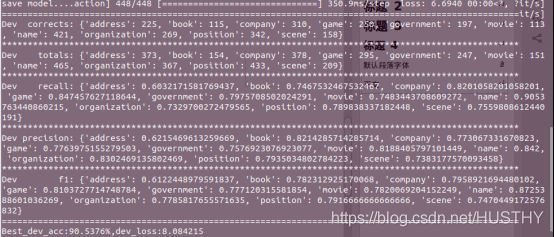
经过平均计算得到:F1 = 0.776 Precision = 0.779 recall = 0.776
C、BERT+Pytorch
这个就是直接使用BERT来做NER了,不需要经过CRF模型的约束限制。模型结构就很简单了,直接在BERT模型后面接一个线性层就OK了。模型结构比较简单就不画图了,就是上面的BERT+CRF去掉CRF就可以了。
模型代码如图:
class BertOneStageForNer(BertPreTrainedModel):
def __init__(self,config):
super(BertOneStageForNer,self).__init__(config)
self.num_labels = config.biso_num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.cls = nn.Linear(config.hidden_size, config.biso_num_labels)
self.init_weights()
def forward(self,input_ids, attention_mask=None,bio_labels=None):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.cls(sequence_output)
outputs = (logits,)
if bio_labels is not None:
loss_fct = CrossEntropyLoss(ignore_index=0)
if attention_mask is not None:
active_loss = attention_mask.view(-1) == 1
active_logits = logits.view(-1,self.num_labels)[active_loss]
active_labels = bio_labels.view(-1)[active_loss]
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1,self.num_labels),bio_labels.view(-1))
outputs = (loss,) + outputs
return outputs其他代码数据加载、模型训练过程的代码在前面的内容已经给出部分关键代码,这里就不在重复给出了。直接看效果如何:
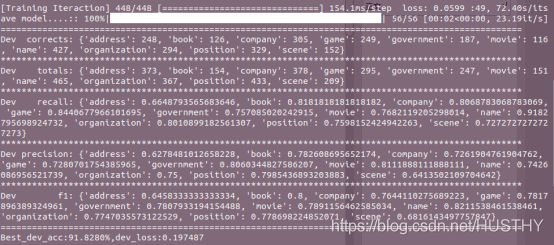
经过平均计算得到:F1 = 0.76 Precision = 0.742 recall = 0.788
D、 Bert+CRF+Pytorch+多任务型
这里由于是采用多任务型的,有2个loss,模型结构图如下:
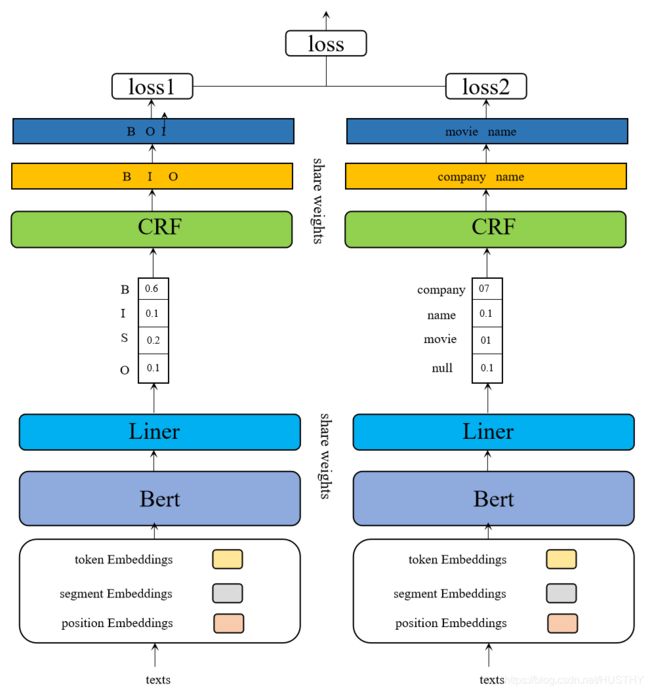
这种方案在模型层面没有什么区别,就是用同一个模型对数据进行不同的序列任务,一个是识别BIOS类别,一个是识别具体的实体类,然后对loss和进行训练。
class BertCrfTwoStageForNer(BertPreTrainedModel):
def __init__(self,config):
super(BertCrfTwoStageForNer,self).__init__(config)
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.cls_bieso = nn.Linear(config.hidden_size,config.bieso_num_labels)
self.cls_att = nn.Linear(config.hidden_size, config.att_num_labels)
self.cls_dropout = nn.Dropout(config.cls_dropout)
self.crf_bieso = CRF(num_tags=config.bieso_num_labels,batch_first=True)
self.crf_att = CRF(num_tags=config.att_num_labels, batch_first=True)
self.init_weights()
def forward(self,input_ids, attention_mask=None,bieso_labels=None,att_labels=None):
outputs = self.bert(input_ids = input_ids,attention_mask=attention_mask)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
bieso_logits = self.cls_dropout(self.cls_bieso(sequence_output))
att_logits = self.cls_dropout(self.cls_att(sequence_output))
outputs = (bieso_logits,att_logits)
if bieso_labels is not None and att_labels is not None:
bieso_loss = self.crf_bieso(emissions = bieso_logits, tags=bieso_labels, mask=attention_mask) #这里报错了
att_loss = self.crf_att(emissions = att_logits, tags=att_labels, mask=attention_mask)
loss = bieso_loss + att_loss
outputs = (-1*loss,)+outputs
return outputs # (loss), scores
代码中可以看出来这里有两个loss一个是bios的loss,一个是具体实体att的loss。模型训练的目标就是使得这两个loss最小。当然这里的att可以是非CRF求出的loss,没有做详细的实验,可以尝试。在这个数据集下,Bert+CRF+Pytorch+多任务型得出的效果貌似并不好。

经过平均计算得到:F1 = 0.695 Precision = 0.674 recall = 0.722;这种设计思路可能存在问题,需要优化。
Bert+Crf+TensorFlow2.0
TensorFlow2.0+版本的代码改进很大,方便我们搭建模型和训练模型。这里也把Bert+Crf做NER的代码实现一下:
模型代码
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
from tensorflow.keras import models,layers,losses
from transformers.modeling_tf_bert import TFBertModel
import tensorflow as tf
class BertOneStageForNer(models.Model):
def __init__(self,args):
super(BertOneStageForNer,self).__init__()
self.num_labels = args.biso_num_labels
self.bert = TFBertModel.from_pretrained(args.bert_model_path, from_pt=True)
self.dropout = layers.Dropout(args.hidden_dropout_prob)#舍弃的概率
# self.dropout = tf.nn.dropout(1-config.hidden_dropout_prob)#保留的概率
self.cls = layers.Dense(args.biso_num_labels,activation='softmax')
def call(self,input_ids, attention_mask,bio_labels):
inputs = {'input_ids': input_ids, 'attention_mask': attention_mask}
outputs = self.bert(inputs)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.cls(sequence_output)
outputs = (logits,)
if bio_labels is not None:
loss_fct = losses.SparseCategoricalCrossentropy()
if attention_mask is not None:
active_loss = tf.reshape(attention_mask,[-1])
active_loss = active_loss == 1
active_logits = tf.reshape(logits,[-1,self.num_labels])
active_logits = active_logits[active_loss]
active_labels = tf.reshape(bio_labels,[-1])
active_labels = active_labels[active_loss]
loss = loss_fct(active_labels, active_logits)
else:
loss = loss_fct(tf.reshape(bio_labels,[-1]),tf.reshape(logits,[-1, self.num_labels]))
outputs = (loss,) + outputs
return outputs实现的代码和pytoch有很多相像的地方,__init()__中定义模型的组件的时候,都是采用相似的API,改个名字而已。注意细节:
self.dropout = layers.Dropout(args.hidden_dropout_prob)#舍弃的概率
# self.dropout = tf.nn.dropout(1-config.hidden_dropout_prob)#保留的概率采用的损失函数都是交叉熵,函数名改变了:
loss_fct = losses.SparseCategoricalCrossentropy()还有其他的关于tensor的操作的API也有所差别,这就需要去多加使用了。
数据加载的方式,也没有pytorch中的DataSet和DataLoader了,但是有类似功能的替代品,感觉还更加灵活。
例如使用生成器:
"
other codes
"
def __call__(self,*args, **kwargs):
for (input_ids,attention_mask,biso_label,input_lens) in self.process_data_list:
yield input_ids,attention_mask,biso_label,input_lenstrain_generator = OneStageDataReader(args=args, text_file_name='train_text.txt', bieso_file_name='train_bios.txt')
train_len = train_generator.length
train_data = tf.data.Dataset.from_generator(train_generator,(tf.int32,tf.int32,tf.int32,tf.int32)).shuffle(buffer_size=1000).batch(args.batch_size).prefetch(buffer_size = tf.data.experimental.AUTOTUNE)
tf.data.Dataset.from_generator()就是类似torch中的DataLoader的作用,数据管道。
在TensorFlow2.0+版本模型的训练也是不太一样的。
训练代码:
@tf.function
def train_step(model,input_ids,attention_mask,biso_label,train_loss,trian_metric,optimizer):
optimizer = optimizers.Adam(learning_rate=args.learning_rate)
train_loss = metrics.Mean(name = 'train_loss')
trian_metric = metrics.SparseCategoricalAccuracy(name='train_accuracy')
with tf.GradientTape() as tape:
outputs = model(input_ids,attention_mask,biso_label)
loss = outputs[0]
predictions = outputs[1]
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss.update_state(loss)
trian_metric.update_state(biso_label, predictions)
return loss使用梯度磁带和及优化器使用来达到模型训练梯度更新loss更新的目的,具体的写法上要进行区别。最后看一看它的结果:
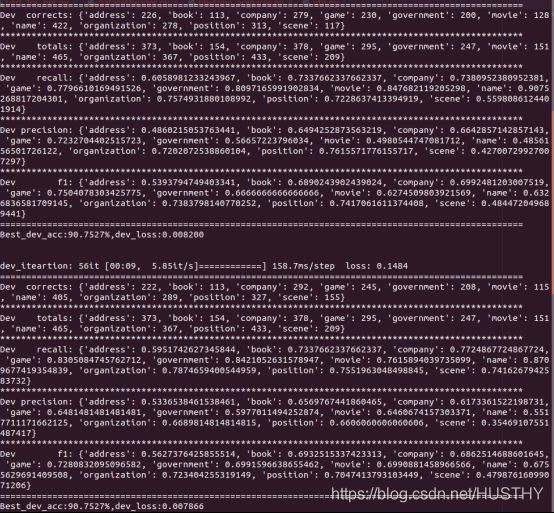
F1 = 0.657 Precision = 0.60 recall = 0.747
文章就写在这里了,由于还要工作,断断续续的看理论调代码,花了几个月吧!自此也算是把NER任务完全是过了一遍。理论和实战都了解过,本博客主要是实战的展示,重在不同模型在不同框架下代码的具体实现和效果的一个展示,为后续做NER项目提供一个直接参考的baseline。
最后,文章中引用的几篇文章都是大佬写的,写的很好,有兴趣的读者可以去读一下。关于NER论文中最新的一些方法和代码,希望以后有时间了可以再去研究!
参考文章
美团搜索中NER技术的探索与实践
综述&实践 | NLP中的命名实体识别(NER)
序列标注方法BIO、BIOSE、IOB、BILOU、BMEWO、BMEWO+的异同
流水的NLP铁打的NER:命名实体识别实践与探索
通俗易懂!BiLSTM上的CRF,用命名实体识别任务来解释CRF
基于MRC框架的命名实体识别方法