数据集成工具——DataX&DataX-Web
文章目录
- DataX的安装及使用
-
- 1、Hive通过外部表与HBase表关联
-
- 1)、hive建表语句:
- 2)、hbase表
- 3)、直接执行查询语句:
- 2、DataX的安装
- 3、DataX的使用
-
- 1)、stream2stream
-
- ①、编写配置文件stream2stream.json
- ②、执行同步任务
- ③、执行结果
- 2)、mysql2mysql
-
- ①、编写配置文件mysql2mysql.json
- ②、执行同步任务
- 3)、mysql2hdfs
-
- ①、编写配置文件mysql2hdfs.json
- 4)、hbase2mysql
- 5)、mysql2hbase
- 4、DataX-web的安装(Java 8、支持Python3(默认Python2.7)、Mysql5.7)
-
- ★★★注意★★★:一定要先配好java、python环境变量
- 1)、使用idea同步源代码
- 2)、在mysql5.1中新建dataxweb数据库
- 3)、执行数据库初始化脚本
- 4)、修改admin配置文件
- 5)、启动DataX-Web-Admin
- 6)、修改datax-web-executor配置文件
- 7)、启动datax-web-executor
- 5、DataX-Web的使用
-
- 1)、新建数据源
- 2)新建项目test1
- 3)、新建任务模板
- 4)、构建任务
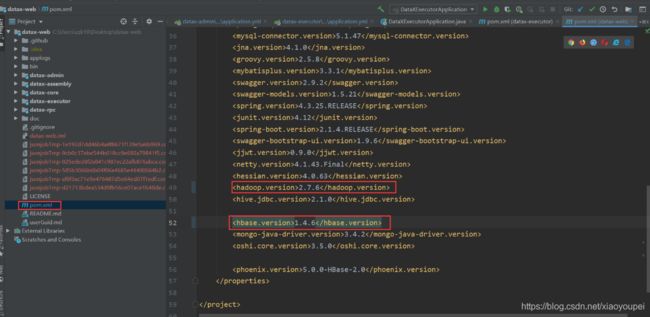
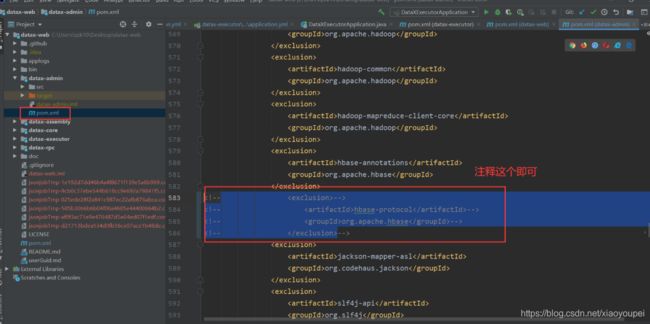
- 5)、添加hbase 数据源会报错,需要修改两个pom.xml文件(hbase1.4.6)
DataX的安装及使用
1、Hive通过外部表与HBase表关联
1)、hive建表语句:
// 第一个字段通常命名为key
CREATE EXTERNAL TABLE hivehbasetable(
key INT
,name STRING
,age INT
,gender STRING
,clazz STRING
,last_mod STRING
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,cf1:name,cf1:age,cf1:gender,cf1:clazz,cf1:last_mod")
TBLPROPERTIES("hbase.table.name" = "student");
2)、hbase表
create 'student','cf1'

3)、直接执行查询语句:
select key,name from hivehbasetable limit 10;

hbase外部表 不能使用sqoop直接导入数据,必须通过例如:insert into这样的形式导入
因为sqoop导入数据,使用的原理是load data,load data只能在表的存储格式为textfile时,才能真正将数据加载到表中
2、DataX的安装
DataX不需要依赖其他服务,直接上传、解压、安装、配置环境变量即可
也可以直接在windows上解压
3、DataX的使用
1)、stream2stream
①、编写配置文件stream2stream.json
# stream2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
②、执行同步任务
datax.py stream2stream.json
③、执行结果
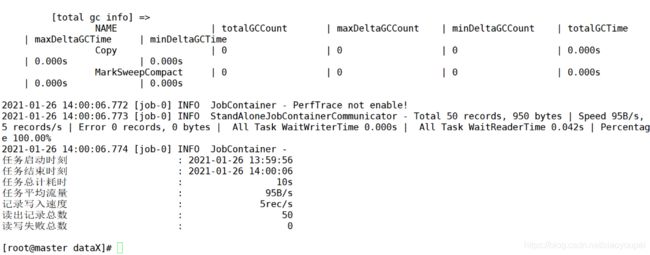
2)、mysql2mysql
需要新建student2数据库,并创建student表
①、编写配置文件mysql2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"gender",
"clazz",
"last_mod"
],
"splitPk": "age",
"connection": [
{
"table": [
"student"
],
"jdbcUrl": [
"jdbc:mysql://master:3306/student"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"gender",
"clazz",
"last_mod"
],
"preSql": [
"truncate student2"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://master:3306/student2?useUnicode=true&characterEncoding=utf8",
"table": [
"student2"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
②、执行同步任务
datax.py mysql2mysql.json
3)、mysql2hdfs
写hive跟hdfs时一样的
①、编写配置文件mysql2hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"gender",
"clazz",
"last_mod"
],
"splitPk": "age",
"connection": [
{
"table": [
"student"
],
"jdbcUrl": [
"jdbc:mysql://master:3306/student"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://master:9000",
"fileType": "text",
"path": "/user/hive/warehouse/datax.db/students",
"fileName": "student",
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "INT"
},
{
"name": "gender",
"type": "string"
},
{
"name": "clazz",
"type": "string"
},
{
"name": "last_mod",
"type": "string"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
4)、hbase2mysql
{
"job": {
"content": [
{
"reader": {
"name": "hbase11xreader",
"parameter": {
"hbaseConfig": {
"hbase.zookeeper.quorum": "master:2181"
},
"table": "student",
"encoding": "utf-8",
"mode": "normal",
"column": [
{
"name": "rowkey",
"type": "string"
},
{
"name": "cf1:name",
"type": "string"
},
{
"name": "cf1:age",
"type": "string"
},
{
"name": "cf1:gender",
"type": "string"
},
{
"name": "cf1:clazz",
"type": "string"
}
],
"range": {
"startRowkey": "",
"endRowkey": "",
"isBinaryRowkey": false
}
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"gender",
"clazz"
],
"preSql": [
"truncate student2"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://master:3306/student2?useUnicode=true&characterEncoding=utf8",
"table": [
"student2"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
5)、mysql2hbase
mysql中的score表需将cource_id改为course_id,并将student_id、course_id设为主键,并将所有字段的类型改为int
hbase需先创建score表:create ‘score’,‘cf1’
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"student_id",
"course_id",
"score"
],
"splitPk": "course_id",
"connection": [
{
"table": [
"score"
],
"jdbcUrl": [
"jdbc:mysql://master:3306/student"
]
}
]
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"hbaseConfig": {
"hbase.zookeeper.quorum": "master:2181"
},
"table": "score",
"mode": "normal",
"rowkeyColumn": [
{
"index":0,
"type":"string"
},
{
"index":-1,
"type":"string",
"value":"_"
},
{
"index":1,
"type":"string"
}
],
"column": [
{
"index":2,
"name": "cf1:score",
"type": "int"
}
],
"encoding": "utf-8"
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
4、DataX-web的安装(Java 8、支持Python3(默认Python2.7)、Mysql5.7)
★★★注意★★★:一定要先配好java、python环境变量
1)、使用idea同步源代码
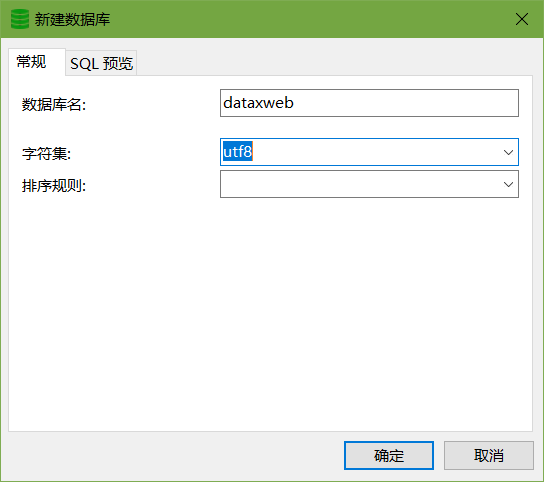
2)、在mysql5.1中新建dataxweb数据库
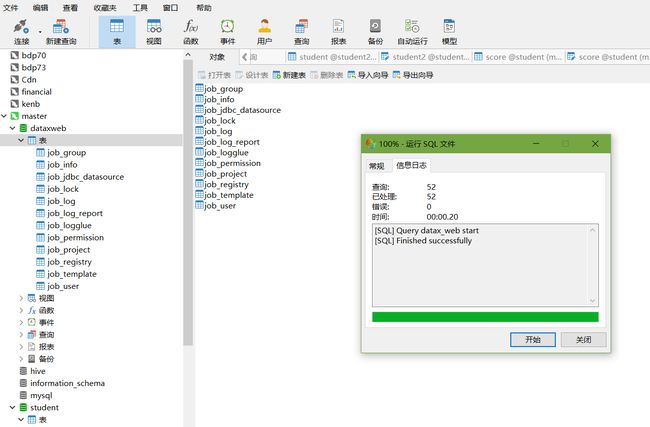
3)、执行数据库初始化脚本
4)、修改admin配置文件
- bootstrap.properties
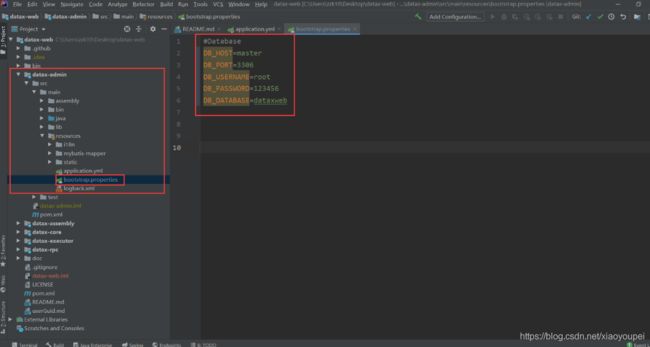
#Database
DB_HOST=master
DB_PORT=3306
DB_USERNAME=root
DB_PASSWORD=123456
DB_DATABASE=dataxweb
- application.yml
server:
#port: 8080
port: 8080
spring:
#数据源
datasource:
# username: root
#password: root
#url: jdbc:mysql://localhost:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
password: ${DB_PASSWORD:password}
username: ${DB_USERNAME:username}
url: jdbc:mysql://${DB_HOST:127.0.0.1}:${DB_PORT:3306}/${DB_DATABASE:dataxweb}?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
hikari:
## 最小空闲连接数量
minimum-idle: 5
## 空闲连接存活最大时间,默认600000(10分钟)
idle-timeout: 180000
## 连接池最大连接数,默认是10
maximum-pool-size: 10
## 数据库连接超时时间,默认30秒,即30000
connection-timeout: 30000
connection-test-query: SELECT 1
##此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
max-lifetime: 1800000
# datax-web email
mail:
host: smtp.qq.com
port: 25
#username: [email protected]
#password: xxx
username: root
password: root
properties:
mail:
smtp:
auth: true
starttls:
enable: true
required: true
socketFactory:
class: javax.net.ssl.SSLSocketFactory
management:
health:
mail:
enabled: false
server:
servlet:
context-path: /actuator
mybatis-plus:
# mapper.xml文件扫描
mapper-locations: classpath*:/mybatis-mapper/*Mapper.xml
# 实体扫描,多个package用逗号或者分号分隔
#typeAliasesPackage: com.yibo.essyncclient.*.entity
global-config:
# 数据库相关配置
db-config:
# 主键类型 AUTO:"数据库ID自增", INPUT:"用户输入ID", ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";
id-type: AUTO
# 字段策略 IGNORED:"忽略判断",NOT_NULL:"非 NULL 判断"),NOT_EMPTY:"非空判断"
field-strategy: NOT_NULL
# 驼峰下划线转换
column-underline: true
# 逻辑删除
logic-delete-value: 0
logic-not-delete-value: 1
# 数据库类型
db-type: mysql
banner: false
# mybatis原生配置
configuration:
map-underscore-to-camel-case: true
cache-enabled: false
call-setters-on-nulls: true
jdbc-type-for-null: 'null'
type-handlers-package: com.wugui.datax.admin.core.handler
# 配置mybatis-plus打印sql日志
logging:
#level:
# com.wugui.datax.admin.mapper: info
#path: ./data/applogs/admin
level:
com.wugui.datax.admin.mapper: error
path: ./applogs/admin
#datax-job, access token
datax:
job:
accessToken:
#i18n (default empty as chinese, "en" as english)
i18n:
## triggerpool max size
triggerpool:
fast:
max: 200
slow:
max: 100
### log retention days
logretentiondays: 30
datasource:
aes:
key: AD42F6697B035B75
5)、启动DataX-Web-Admin
- 访问: http://127.0.0.1:8080/index.html,用户名:admin,密码:123456
6)、修改datax-web-executor配置文件
- application.yml
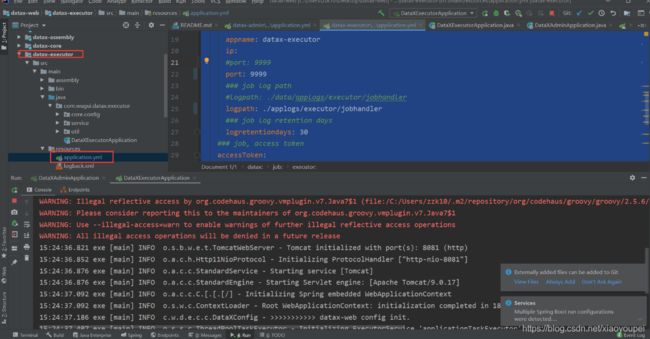
# web port
server:
port: 8081
#port: 8081
# log config
logging:
config: classpath:logback.xml
path: ./applogs/executor/jobhandler
#path: ./data/applogs/executor/jobhandler
datax:
job:
admin:
### datax admin address list, such as "http://address" or "http://address01,http://address02"
#addresses: http://127.0.0.1:8080
addresses: http://127.0.0.1:8080
executor:
appname: datax-executor
ip:
#port: 9999
port: 9999
### job log path
#logpath: ./data/applogs/executor/jobhandler
logpath: ./applogs/executor/jobhandler
### job log retention days
logretentiondays: 30
### job, access token
accessToken:
executor:
#jsonpath: D:\\temp\\executor\\json\\
jsonpath: ./json
#pypath: F:\tools\datax\bin\datax.py
pypath: C:\Users\zzk10\Documents\MacOS\DataIntegrate\datax\datax\bin\datax.py
注意pypath:这个路径需要解压datax.tar.gz到自己的路径,不要使用中文路径
解压后使用datax-web中的python3脚本替换掉 datax/bin/
7)、启动datax-web-executor
只要进程没有自己停止,一直在后台运行即可
5、DataX-Web的使用
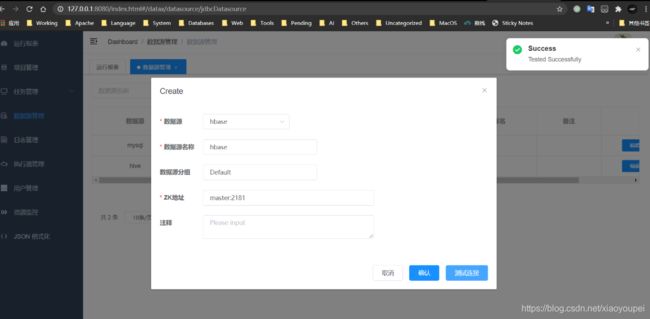
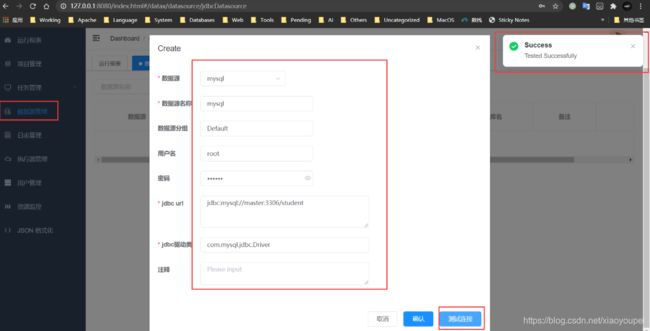
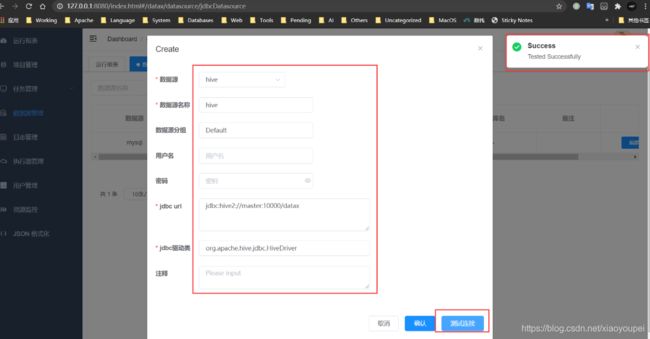
1)、新建数据源
- mysql
-
hive
需要先启动hiveserver2服务
下面这条命令需要在linux shell中执行
hive --service hiveserver2
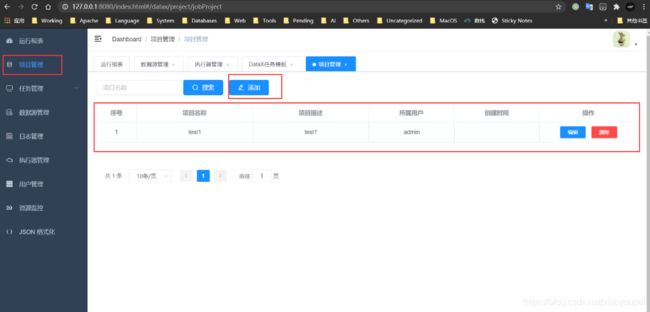
2)新建项目test1
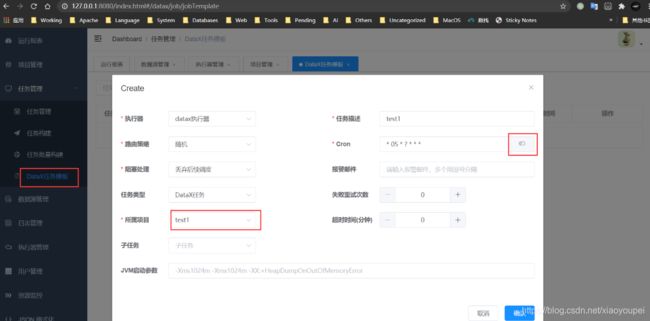
3)、新建任务模板
4)、构建任务
- 创建reader
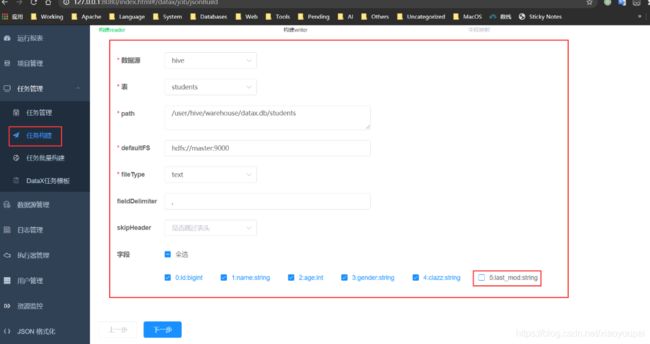
- 创建writer
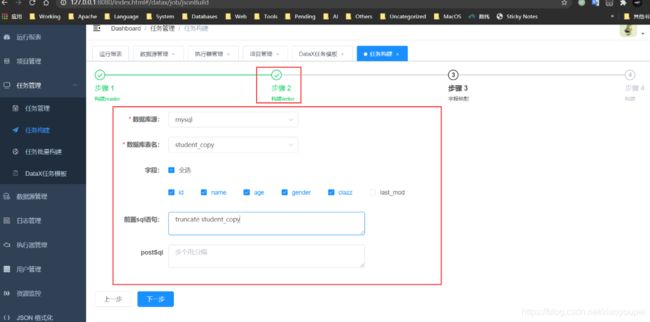
- 字段映射

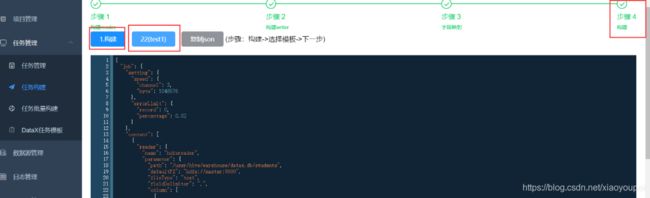
- 构建任务
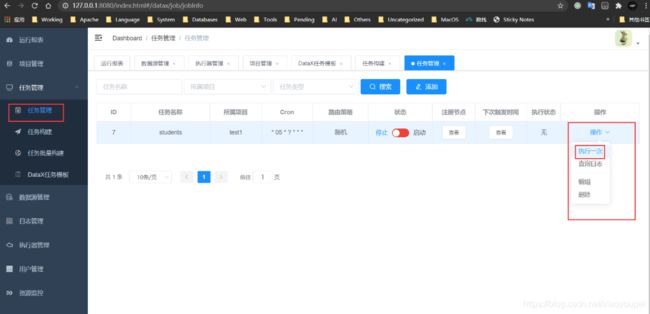
- 执行任务
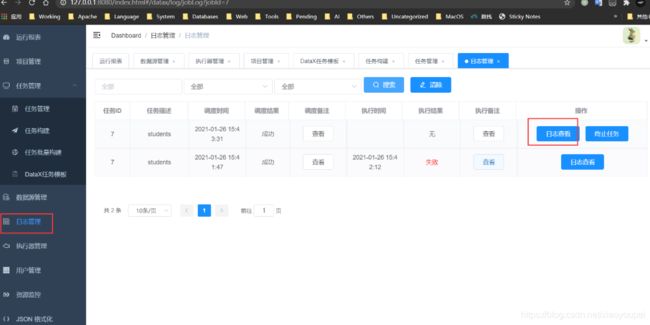
- 查看日志
5)、添加hbase 数据源会报错,需要修改两个pom.xml文件(hbase1.4.6)
改完pom文件,记得重新reimport,才会生效
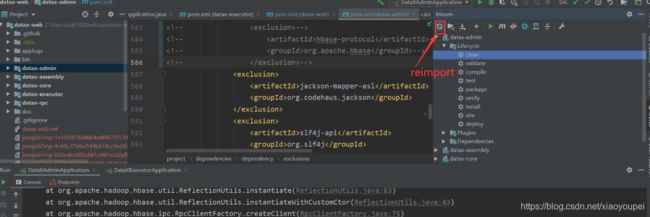
- 重新测试hbase连通性