虚拟机安装Centos7并安装jdk搭建hdfs和yarn环境
一.安装Centos7
1.点击自定义安装 2.点击下一步
2.点击下一步
 3.选择稍后安装操作系统,点击下一步
3.选择稍后安装操作系统,点击下一步
 4.选择操作系统为linux和版本为Centos7
4.选择操作系统为linux和版本为Centos7
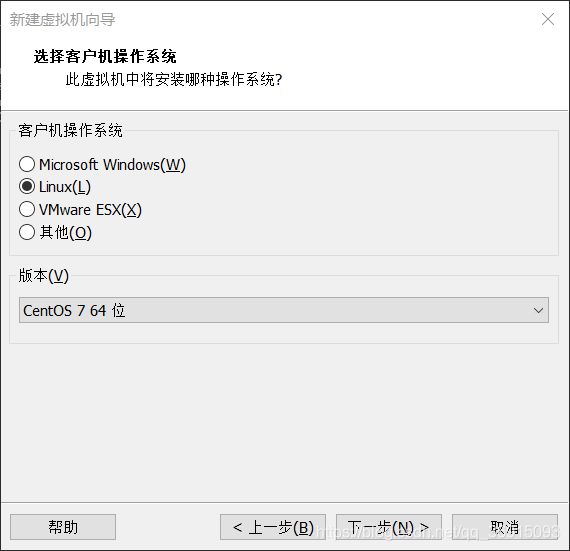 5.设置虚拟机名称和位置,位置后最好自己命名一个文件夹名称
5.设置虚拟机名称和位置,位置后最好自己命名一个文件夹名称
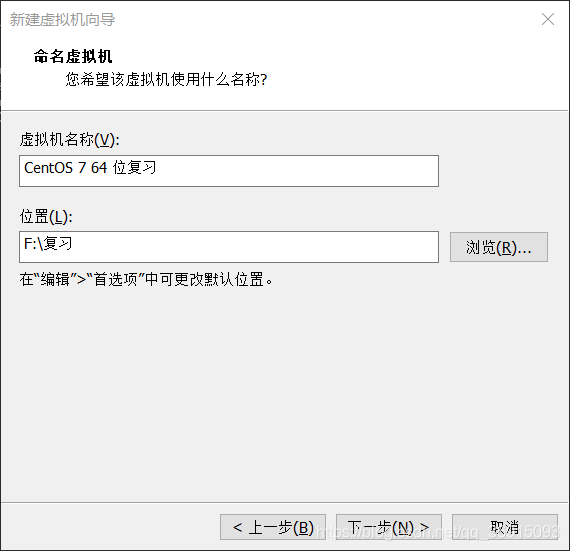 6.直接下一步
6.直接下一步
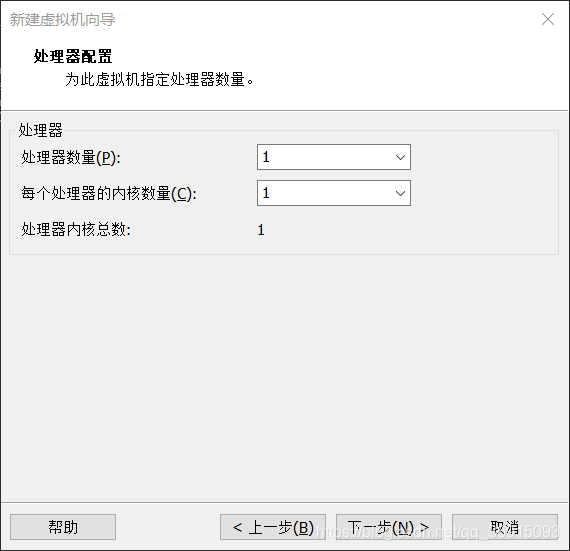
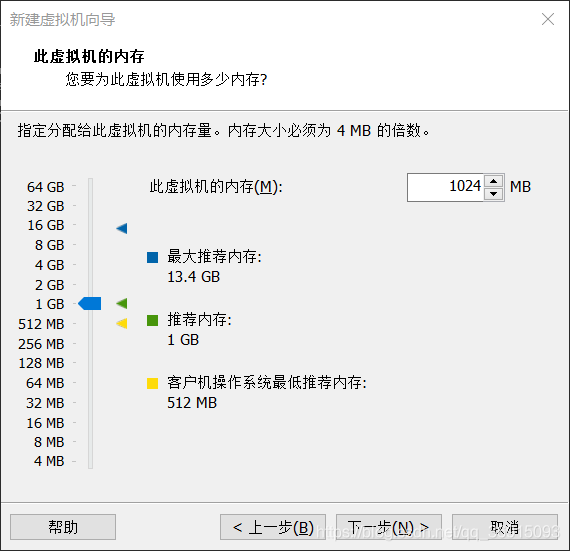 7.使用网络地址转换
7.使用网络地址转换
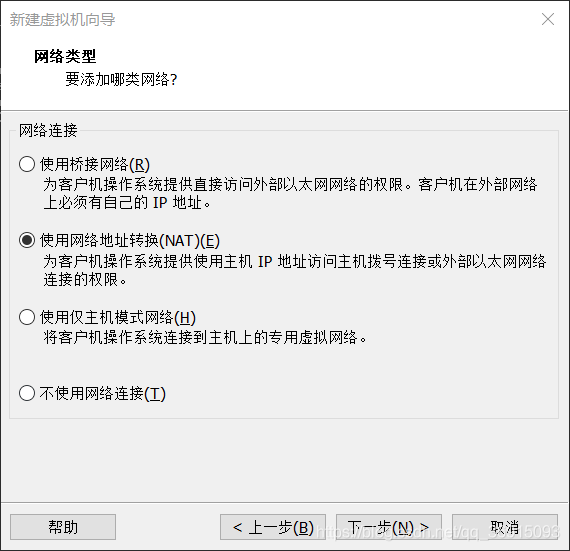 8.直接下一步
8.直接下一步
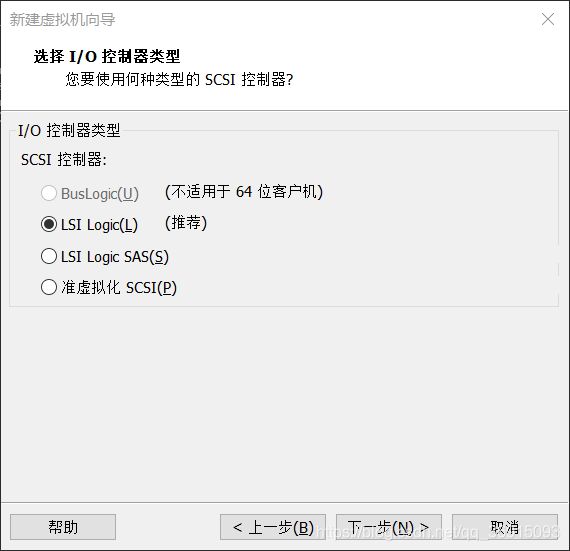
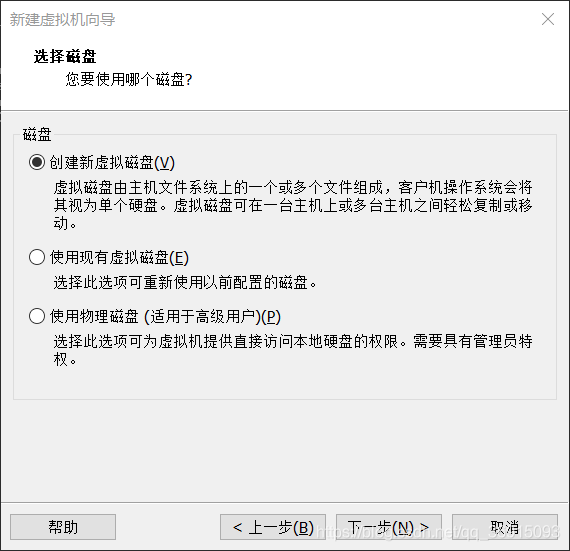
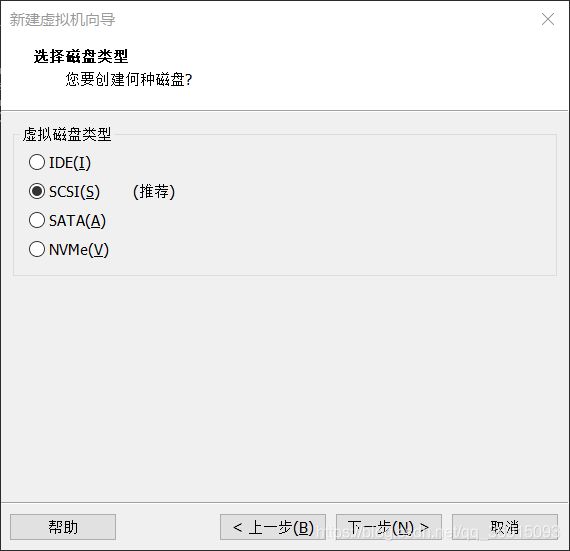 9.选择创建新的虚拟磁盘,注意不要点击立即分配磁盘空间
9.选择创建新的虚拟磁盘,注意不要点击立即分配磁盘空间
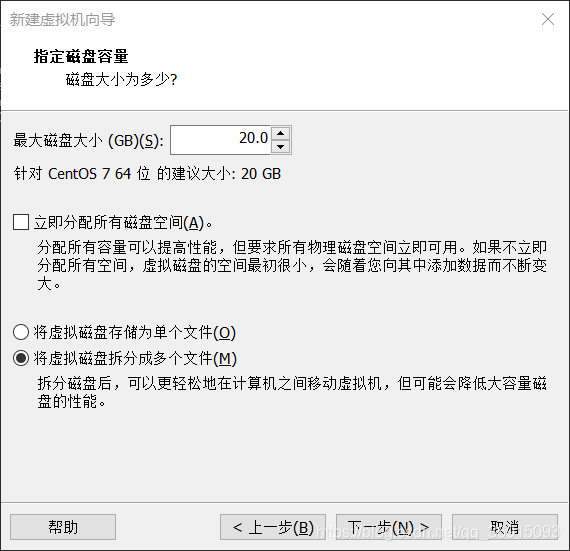 10.直接下一步,然后完成
10.直接下一步,然后完成
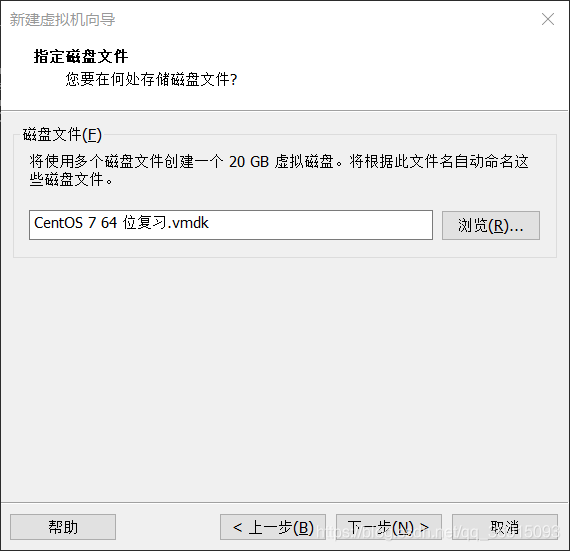
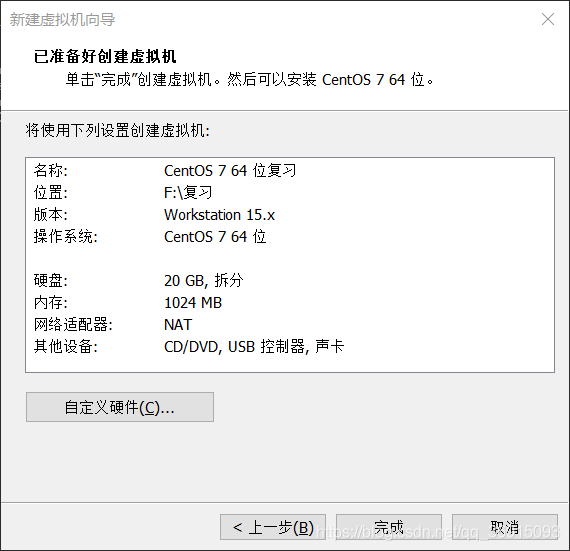 11.完成后先不要着急启动,需要先进行设置,点击CD/DVD,使用IOS映射文件(这里的文件需要下载,我用的是CentOS-7-x86_64-Minimal-1804.iso)
11.完成后先不要着急启动,需要先进行设置,点击CD/DVD,使用IOS映射文件(这里的文件需要下载,我用的是CentOS-7-x86_64-Minimal-1804.iso)
 12.点击确定,然后启动虚拟机,进入到这个界面,直接点回车
12.点击确定,然后启动虚拟机,进入到这个界面,直接点回车
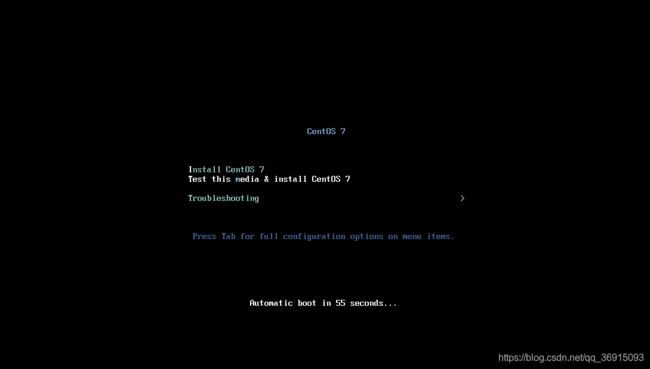
 13.选择简体中文,然后继续
13.选择简体中文,然后继续
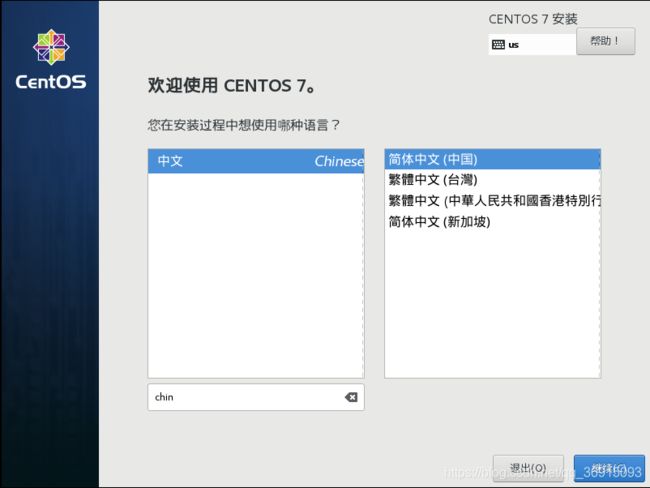 14.在安装位置上会有感叹号,直接点击进去然后点完成,就可以进行安装了
14.在安装位置上会有感叹号,直接点击进去然后点完成,就可以进行安装了

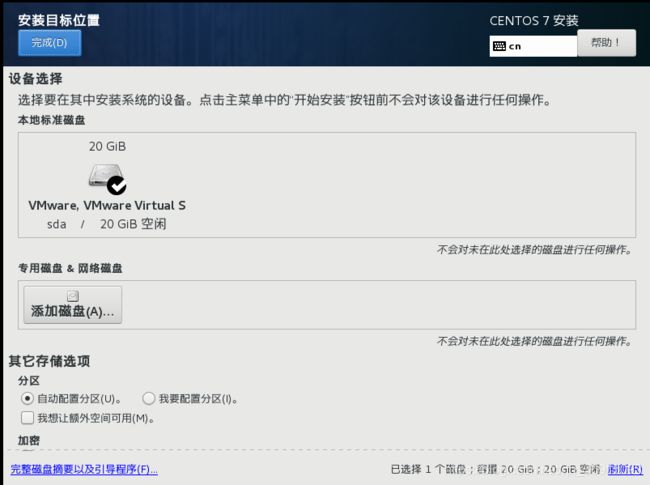
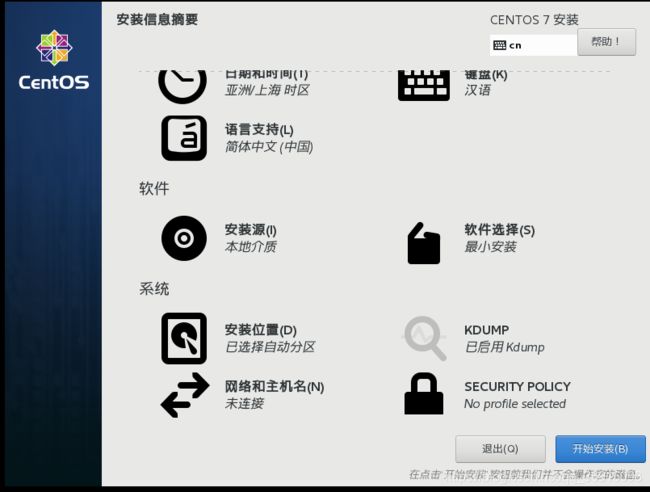 15.之后设置root密码,点击完成(两次),之后等待安装完成
15.之后设置root密码,点击完成(两次),之后等待安装完成
 16.重启
16.重启
 17.使用root用户登录进行修改网络动态获取,修改属性ONBOOT=yes
17.使用root用户登录进行修改网络动态获取,修改属性ONBOOT=yes
vim /etc/sysconfig/network-scripts/ifcfg-ens33

刷新网络配置
systemctl restart network
重新查看虚拟机ip
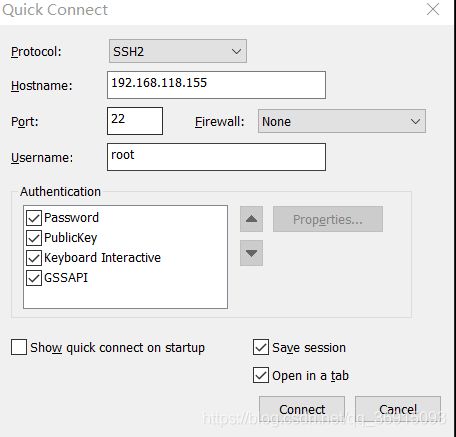
 18.使用CRT连接诶到centos7
18.使用CRT连接诶到centos7
二.在虚拟机中安装jdk
1.修改主机名以及ip映射
vi /etc/hostname

vi /etc/hosts
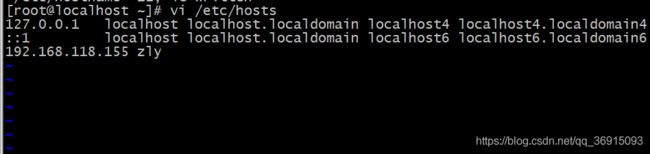 注意要重启
注意要重启
![]()
测试成功
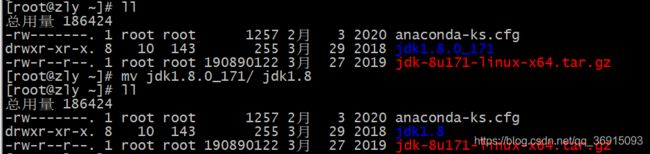
 2.alt+p上传jdk的tar包,之后进行解压,并将名字改为jdk1.8
2.alt+p上传jdk的tar包,之后进行解压,并将名字改为jdk1.8
tar -zxvf jdk-8u171-linux-x64.tar.gz
mv jdk1.8.0_171/ jdk1.8
 3.将常用软件移动到共享目录(不仅root可以访问这个目录)
3.将常用软件移动到共享目录(不仅root可以访问这个目录)
cd /usr
mkdir soft
mv jdk1.8/ /usr/soft/
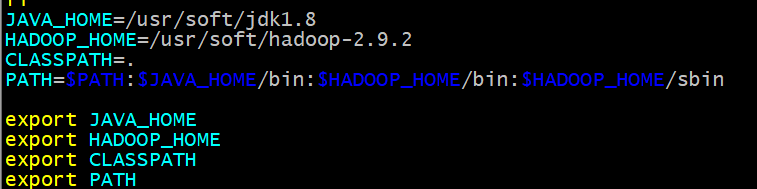
4.配置当前用户的jdk的环境变量
vim .bashrc
JAVA_HOME=/usr/soft/jdk1.8
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
5.重新加载配置文件使其生效
source .bashrc
6.测试,jdk安装成功
![]()
三.安装hdfs与yarn
1.安装hdfs
注意:使用hadoop必须安装jdk
1.上传hadoop的tar包并解压
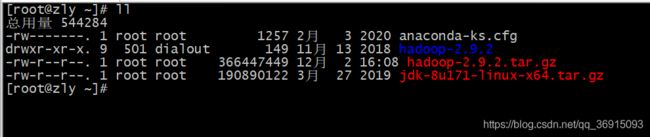 2.将文件移动到指定目录并配置环境变量,之后重新加载配置
2.将文件移动到指定目录并配置环境变量,之后重新加载配置
mv hadoop-2.9.2 /usr/soft/hadoop-2.9.2
source .bashrc
3.在家目录下进行测试成功
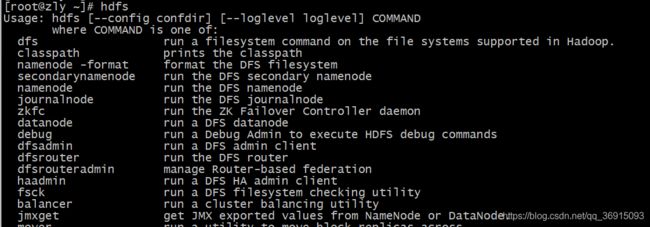 4.配置hadoop-env.sh,在文件中配置jdk环境变量
4.配置hadoop-env.sh,在文件中配置jdk环境变量
vim /usr/soft/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
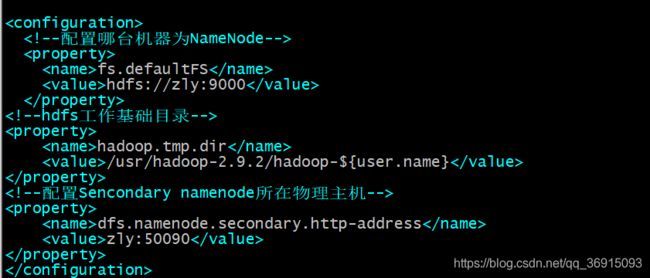
 5.配置core-site.xml,用来对hdfs集群核心进行配置
5.配置core-site.xml,用来对hdfs集群核心进行配置
vim /usr/soft/hadoop-2.9.2/etc/hadoop/core-site.xml
6.配置hdfs-site.xml,用来对hdfs文件系统进行配置
vim /usr/soft/hadoop-2.9.2/etc/hadoop/hdfs-site.xml

7.配置slaves配置文件,决定哪台机器为DateNode
vim /usr/soft/hadoop-2.9.2/etc/hadoop/slaves

8.注意:启动hdfs前要先格式化NameNode,把当前机器格式化成hadoop可以识别的文件系统
hdfs namenode -format
 9.启动hdfs,并检测是否成功,这里因为没有配置免密登录,所以要输出三次密码,一次是登录NameNode,一次为DateNode,一次为SecondNameNode
9.启动hdfs,并检测是否成功,这里因为没有配置免密登录,所以要输出三次密码,一次是登录NameNode,一次为DateNode,一次为SecondNameNode
start-dfs.sh

9.为了能访问网页端,需要关闭防火墙,开启不自动启动防火墙
systemctl stop firewalld
systemctl disable firewalld
访问:192.168.118.155:50070
 10.配置免密登录
10.配置免密登录
生成公钥和私钥,一顿按回车
ssh-keygen -t rsa
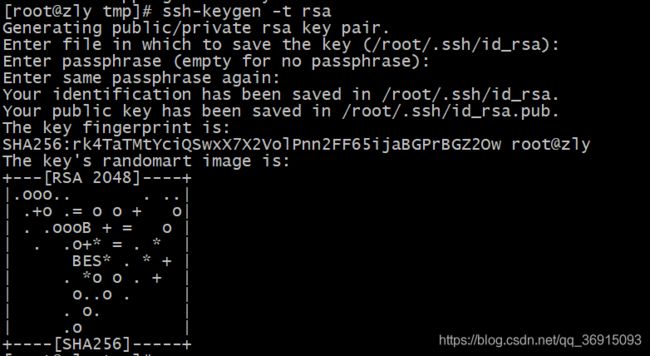
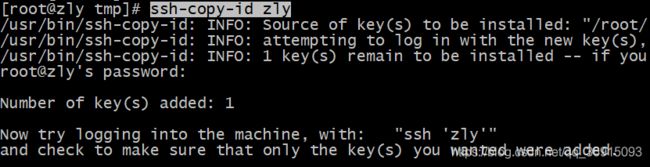
这里需要输出一次密码
ssh-copy-id zly
2.安装yarn
1.修改配置文件
vim /usr/soft/hadoop-2.9.2/etc/hadoop/yarn-site.xml
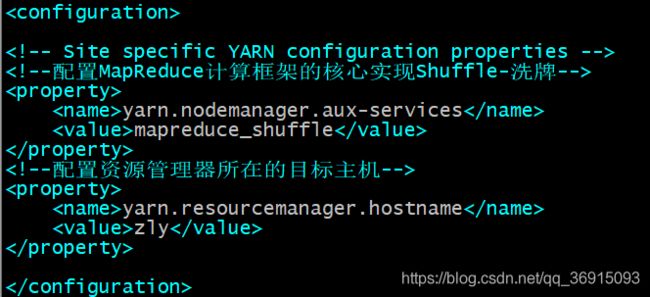
由于没有mapred-site.xml的文件,所以我拷贝了一份,当然你也可以重命名
cp mapred-site.xml.template mapred-site.xml
 2.启动yarn并测试
2.启动yarn并测试
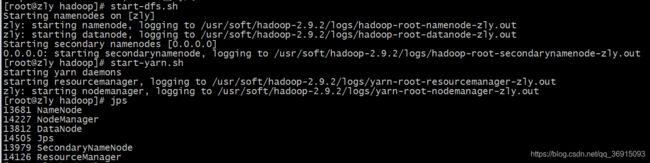 访问:http://192.168.118.155:8088
访问:http://192.168.118.155:8088
