- 简介
- 散列表的关键概念
- 数组和散列表
- 数组的问题
- hash的问题
- 线性探测
- 二次探测
- 双倍散列
- 分离链接
- rehash
简介
java中和hash相关并且常用的有两个类hashTable和hashMap,两个类的底层存储都是数组,这个数组不是普通的数组,而是被称为散列表的东西。
散列表是一种将键映射到值的数据结构。它用哈希函数来将键映射到小范围的指数(一般为[0..哈希表大小-1])。同时需要提供冲突和对冲突的解决方案。
今天我们来学习一下散列表的特性和作用。
文末有代码地址,欢迎下载。
散列表的关键概念
散列表中比较关键的三个概念就是散列表,hash函数,和冲突解决。
散列是一种算法(通过散列函数),将大型可变长度数据集映射为固定长度的较小整数数据集。
散列表是一种数据结构,它使用哈希函数有效地将键映射到值,以便进行高效的搜索/检索,插入和/或删除。
散列表广泛应用于多种计算机软件中,特别是关联数组,数据库索引,缓存和集合。
散列表必须至少支持以下三种操作,并且尽可能高效:
搜索(v) - 确定v是否存在于散列表中,
插入(v) - 将v插入散列表,
删除(v) - 从散列表中删除v。
因为使用了散列算法,将长数据集映射成了短数据集,所以在插入的时候就可能产生冲突,根据冲突的解决办法的不同又可以分为线性探测,二次探测,双倍散列和分离链接等冲突解决方法。
数组和散列表
考虑这样一个问题:找到给定的字符串中第一次重复出现的的字符。
怎么解决这个问题呢?最简单的办法就是进行n次遍历,第一次遍历找出字符串中是否有和第一个字符相等的字符,第二次遍历找出字符串中是否有和第二个字符相等的字符,以此类推。
因为进行了n*n的遍历,所以时间复杂度是O(n²)。
有没有简单点的办法呢?
考虑一下字符串中的字符集合其实是有限的,假如都是使用的ASCII字符,那么我们可以构建一个256长度的数组一次遍历即可。
具体的做法就是遍历一个字符就将相对于的数组中的相应index中的值+1,当我们发现某个index的值已经是1的时候,就知道这个字符重复了。
数组的问题
那么数组的实现有什么问题呢?
数组的问题所在:
键的范围必须很小。 如果我们有(非常)大范围的话,内存使用量会(非常的)很大。
键必须密集,即键值中没有太多空白。 否则数组中将包含太多的空单元。
我们可以使用散列函数来解决这个问题。
通过使用散列函数,我们可以:
将一些非整数键映射成整数键,
将大整数映射成较小的整数。
通过使用散列函数,我们可以有效的减少存储数组的大小。
hash的问题
有利就有弊,虽然使用散列函数可以将大数据集映射成为小数据集,但是散列函数可能且很可能将不同的键映射到同一个整数槽中,即多对一映射而不是一对一映射。
尤其是在散列表的密度非常高的情况下,这种冲突会经常发生。
这里介绍一个概念:影响哈希表的密度或负载因子α= N / M,其中N是键的数量,M是哈希表的大小。
其实这个冲突的概率要比我们想象的更大,举一个生日悖论的问题:
一个班级里面有多少个学生会使至少有两人生日相同的概率大于 50%?
我们来计算一下上面的问题。
假设Q(n)是班级中n个人生日不同的概率。
Q(n)= 365/365×364/365×363/365×...×(365-n + 1)/ 365,即第一人的生日可以是365天中的任何一天,第二人的生日可以是除第一人的生日之外的任何365天,等等。
设P(n)为班级中 n 个人的相同生日的概率,则P(n)= 1-Q(n)。
计算可得,当n=23的时候P(23) = 0.507> 0.5(50%)。
也就是说当班级拥有23个人的时候,班级至少有两个人的生日相同的概率已经超过了50%。 这个悖论告诉我们:个人觉得罕见的事情在集体中却是常见的。
好了,回到我们的hash冲突,我们需要构建一个好的hash函数来尽量减少数据的冲突。
什么是一个好的散列函数呢?
能够快速计算,即其时间复杂度是O(1)。
尽可能使用最小容量的散列表,
尽可能均匀地将键分散到不同的基地址∈[0..M-1],
尽可能减少碰撞。
在讨论散列函数的实现之前,让我们讨论理想的情况:完美的散列函数。
完美的散列函数是键和散列值之间的一对一映射,即根本不存在冲突。 当然这种情况是非常少见的,如果我们事先知道了散列函数中要存储的key,还是可以办到的。
好了,接下来我们讨论一下hash中解决冲突的几种常见的方法。
线性探测
先给出线性探测的公式:i描述为i =(base + step * 1)%M,其中base是键v的散列值,即h(v),step是从1开始的线性探测步骤。
线性探测的探测序列可以正式描述如下:
h(v)//基地址
(h(v)+ 1 * 1)%M //第一个探测步骤,如果发生碰撞
(h(v)+ 2 * 1)%M //第二次探测步骤,如果仍有碰撞
(h(v)+ 3 * 1)%M //第三次探测步骤,如果仍有冲突
...
(h(v)+ k * 1)%M //第k个探测步骤等...
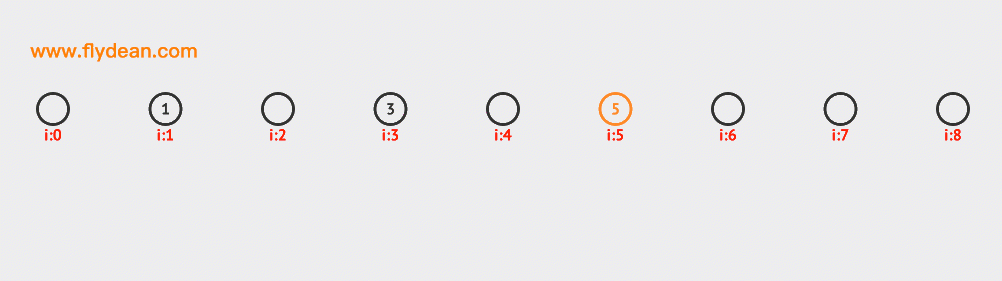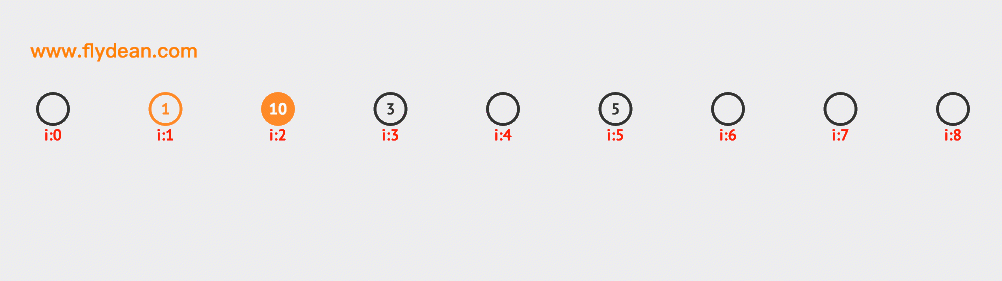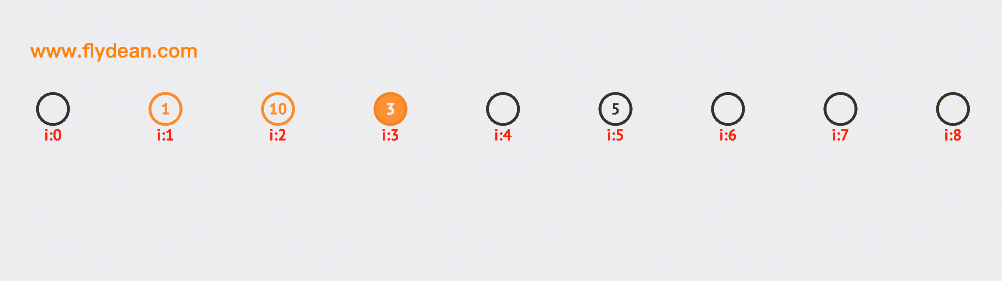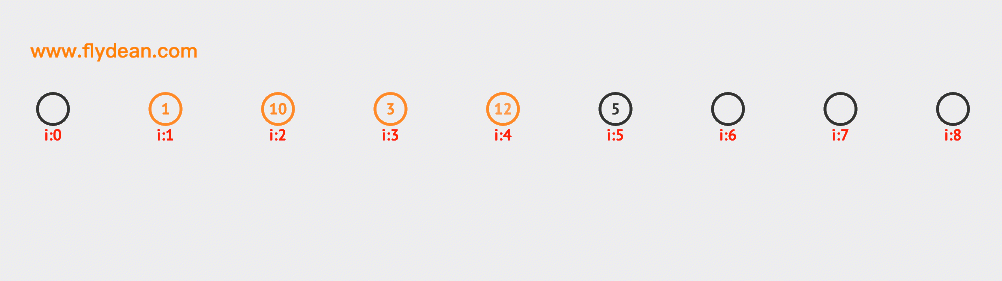
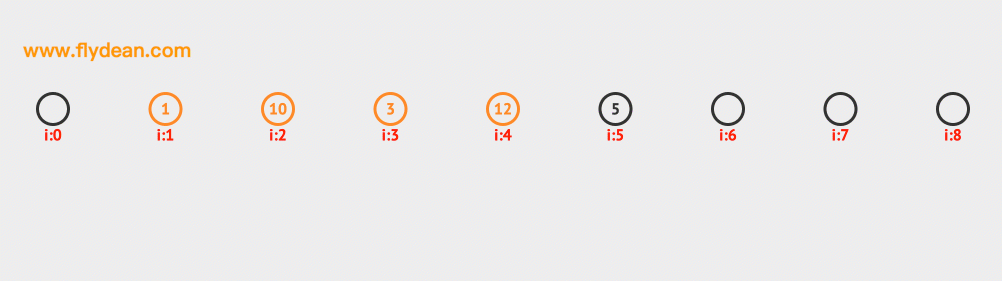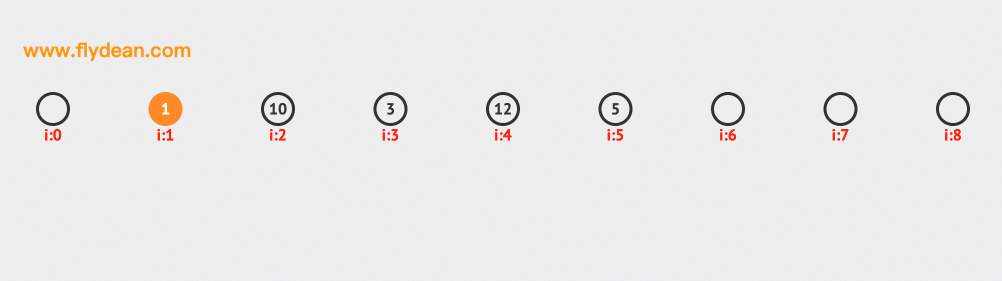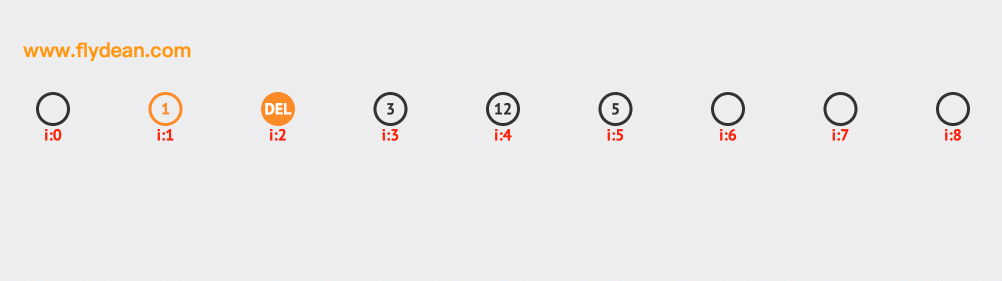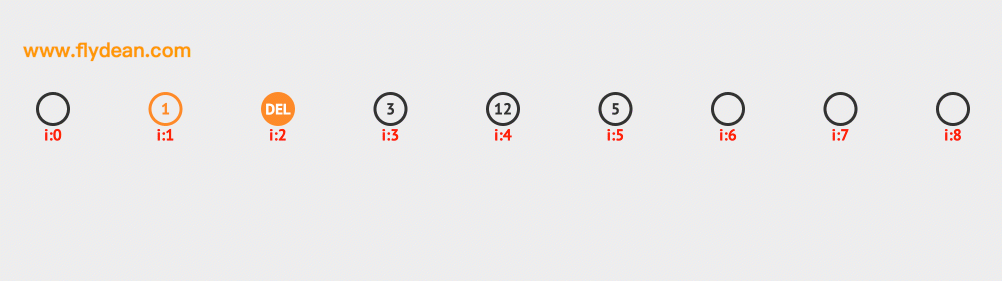
先看个例子,上面的数组中,我们的基数是9,数组中已经有1,3,5这三个元素。
现在我们需要插入10和12,根据计算10和12的hash值是1和3,但是1和3现在已经有数据了,那么需要线性向前探测一位,最终插入在1和3的后面。
上面是删除10的例子,同样的先计算10的hash值=1,然后判断1的位置元素是不是10,不是10的话,向前线性探测。
看下线性探测的关键代码:
//插入节点
void insertNode(int key, int value)
{
HashNode temp = new HashNode(key, value);
//获取key的hashcode
int hashIndex = hashCode(key);
//find next free space
while(hashNodes[hashIndex] != null && hashNodes[hashIndex].key != key
&& hashNodes[hashIndex].key != -1)
{
hashIndex++;
hashIndex %= capacity;
}
//插入新节点,size+1
if(hashNodes[hashIndex] == null || hashNodes[hashIndex].key == -1) {
size++;
}
//将新节点插入数组
hashNodes[hashIndex] = temp;
}
如果我们把具有相同h(v)地址的连续存储空间叫做clusters的话,线性探测有很大的可能会创建大型主clusters,这会增加搜索(v)/插入(v)/删除(v)操作的运行时间。
为了解决这个问题,我们引入了二次探测。
二次探测
先给出二次探测的公式:i描述为i =(base + step * step)%M,其中base是键v的散列值,即h(v),step是从1开始的线性探测步骤。
h(v)//基地址
(h(v)+ 1 * 1)%M //第一个探测步骤,如果发生碰撞
(h(v)+ 2 * 2)%M //第2次探测步骤,如果仍有冲突
(h(v)+ 3 * 3)%M //第三次探测步骤,如果仍有冲突
...
(h(v)+ k * k)%M //第k个探测步骤等...
就是这样,探针按照二次方跳转,根据需要环绕哈希表。

看一个二次探测的例子,上面的例子中我们已经有38,3和18这三个元素了。现在要向里面插入10和12。大家可以自行研究下探测的路径。

再看一个二次探索删除节点的例子。
看下二次探测的关键代码:
//插入节点
void insertNode(int key, int value)
{
HashNode temp = new HashNode(key, value);
//获取key的hashcode
int hashIndex = hashCode(key);
//find next free space
int i=1;
while(hashNodes[hashIndex] != null && hashNodes[hashIndex].key != key
&& hashNodes[hashIndex].key != -1)
{
hashIndex=hashIndex+i*i;
hashIndex %= capacity;
i++;
}
//插入新节点,size+1
if(hashNodes[hashIndex] == null || hashNodes[hashIndex].key == -1) {
size++;
}
//将新节点插入数组
hashNodes[hashIndex] = temp;
}
在二次探测中,群集(clusters)沿着探测路径形成,而不是像线性探测那样围绕基地址形成。 这些群集称为次级群集(Secondary Clusters)。
由于在所有密钥的探测中使用相同的模式,所以形成次级群集。
二次探测中的次级群集不如线性探测中的主群集那样糟糕,因为理论上散列函数理论上应该首先将键分散到不同的基地址∈[0..M-1]中。
为了减少主要和次要clusters,我们引入了双倍散列。
双倍散列
先给出双倍散列的公式:i描述为i =(base + step * h2(v))%M,其中base是键v的散列值,即h(v),step是从1开始的线性探测步骤。
h(v)//基地址
(h(v)+ 1 * h2(v))%M //第一个探测步骤,如果有碰撞
(h(v)+ 2 * h2(v))%M //第2次探测步骤,如果仍有冲突
(h(v)+ 3 * h2(v))%M //第三次探测步骤,如果仍有冲突
...
(h(v)+ k * h2(v))%M //第k个探测步骤等...
就是这样,探测器根据第二个散列函数h2(v)的值跳转,根据需要环绕散列表。
看下双倍散列的关键代码:
//插入节点
void insertNode(int key, int value)
{
HashNode temp = new HashNode(key, value);
//获取key的hashcode
int hashIndex = hash1(key);
//find next free space
int i=1;
while(hashNodes[hashIndex] != null && hashNodes[hashIndex].key != key
&& hashNodes[hashIndex].key != -1)
{
hashIndex=hashIndex+i*hash2(key);
hashIndex %= capacity;
i++;
}
//插入新节点,size+1
if(hashNodes[hashIndex] == null || hashNodes[hashIndex].key == -1) {
size++;
}
//将新节点插入数组
hashNodes[hashIndex] = temp;
}
如果h2(v)= 1,则双散列(Double Hashing)的工作方式与线性探测(Linear Probing)完全相同。 所以我们通常希望h2(v)> 1来避免主聚类。
如果h2(v)= 0,那么Double Hashing将会不起作用。
通常对于整数键,h2(v)= M' - v%M'其中M'是一个小于M的质数。这使得h2(v)∈[1..M']。
二次散列函数的使用使得理论上难以产生主要或次要群集问题。
分离链接
分离链接法(SC)冲突解决技术很简单。如果两个键 a 和 b 都具有相同的散列值 i,那么这两个键会以链表的形式附加在要插入的位置。
因为键(keys)将被插入的地方完全依赖于散列函数本身,因此我们也称分离链接法为封闭寻址冲突解决技术。
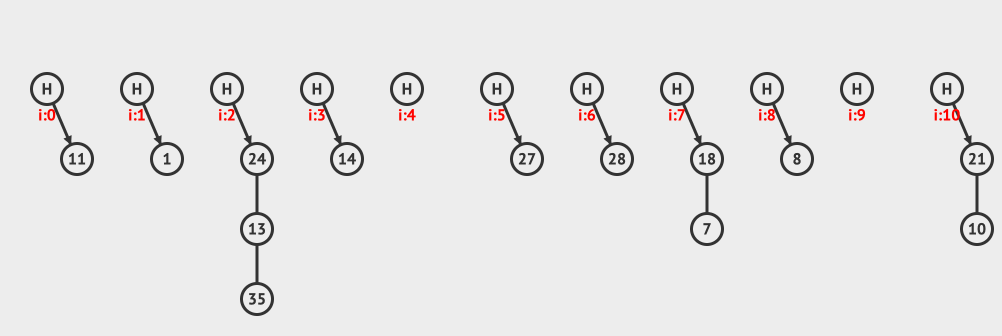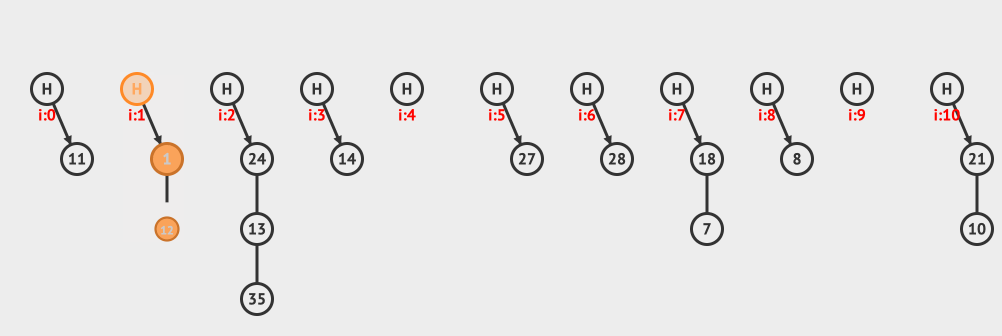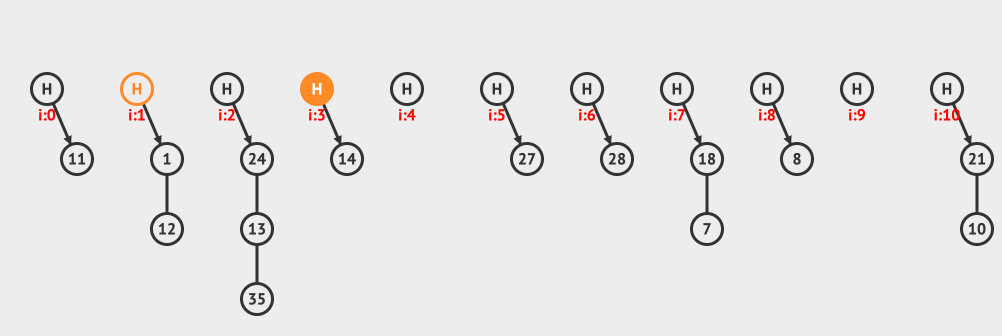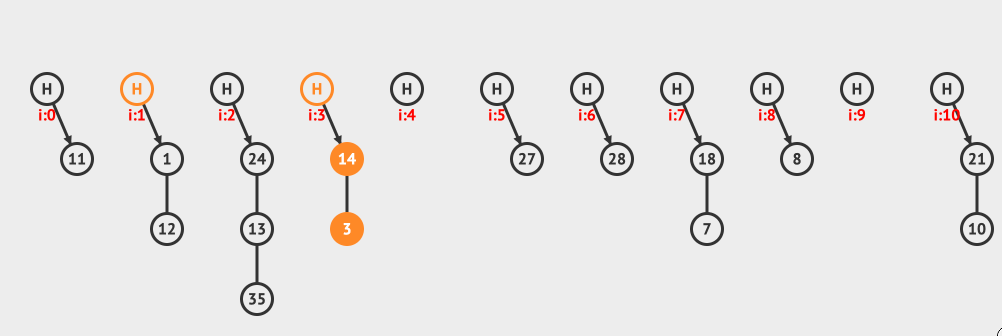
上面是分离链接插入的例子,向现有的hashMap中插入12和3这两个元素。
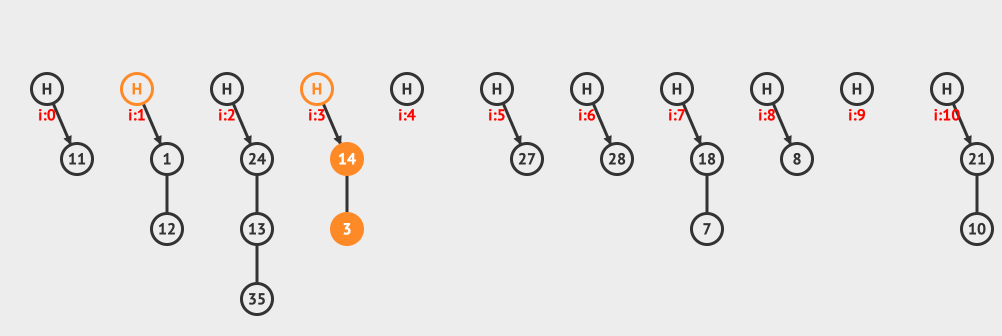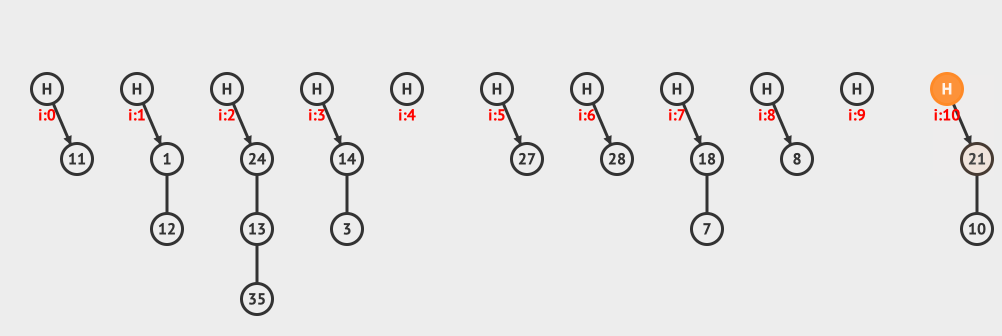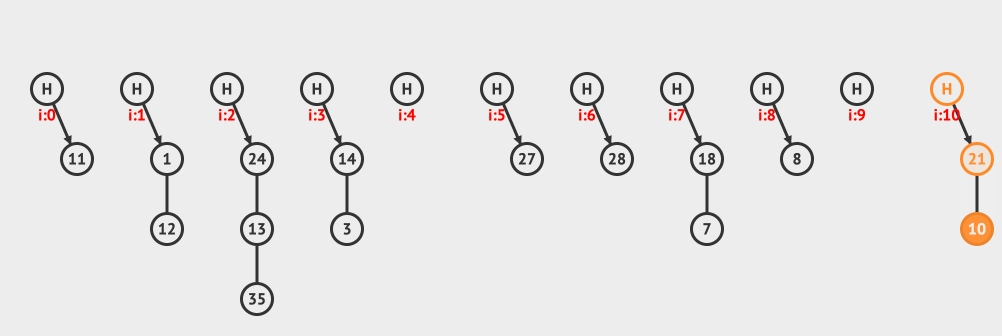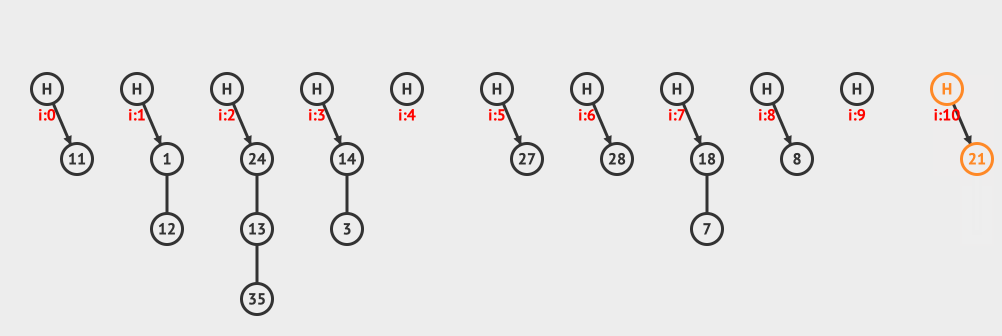
上面是分离链接删除的例子,从链接中删除10这个元素。
看下分离链接的关键代码:
//添加元素
public void add(int key,int value)
{
int index=hashCode(key);
HashNode head=hashNodes[index];
HashNode toAdd=new HashNode(key,value);
if(head==null)
{
hashNodes[index]= toAdd;
size++;
}
else
{
while(head!=null)
{
if(head.key == key )
{
head.value=value;
size++;
break;
}
head=head.next;
}
if(head==null)
{
head=hashNodes[index];
toAdd.next=head;
hashNodes[index]= toAdd;
size++;
}
}
//动态扩容
if((1.0*size)/capacity>0.7)
{
HashNode[] tmp=hashNodes;
hashNodes=new HashNode[capacity*2];
capacity=2*capacity;
for(HashNode headNode:tmp)
{
while(headNode!=null)
{
add(headNode.key, headNode.value);
headNode=headNode.next;
}
}
}
rehash
当负载因子α变高时,哈希表的性能会降低。 对于(标准)二次探测冲突解决方法,当哈希表的α> 0.5时,插入可能失败。
如果发生这种情况,我们可以重新散列(rehash)。 我们用一个新的散列函数构建另一个大约两倍的散列表。 我们遍历原始哈希表中的所有键,重新计算新的哈希值,然后将键值重新插入新的更大的哈希表中,最后删除较早的较小哈希表。
本文的代码地址:
learn-algorithm
本文已收录于 http://www.flydean.com/14-algorithm-hashtable/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!