1.动机
很多优秀的框架都用到filter,之前的认识比较模糊,希望本次有所突破。
2.demo
先动手写一个简单的demo
@Component
public class MyFilter extends FilterEventAdapter {
@Override
protected void statementExecuteBefore(StatementProxy statement, String sql){
System.out.println(sql + "----------MyFilter--------执行开始前!------");
super.statementExecuteBefore(statement,sql);
}
@Override
protected void statementExecuteAfter(StatementProxy statement, String sql, boolean result) {
System.out.println(sql + "----------MyFilter--------执行结束后!------");
super.statementExecuteAfter(statement, sql, result);
}
}继承FilterEventAdapter,复写俩个方法,打两段日志,代码非常简单。执行测试用例:
@Test
void insertTest() {
String sql = "insert into t_druid_test (id,firstname) " +
"VALUES (1,'JINX')";
jdbcTemplate.execute(sql);
}结果如下: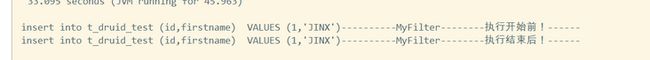
一个简单的自定义filter已完成
3.解析
3.1 Filter
先看filter类图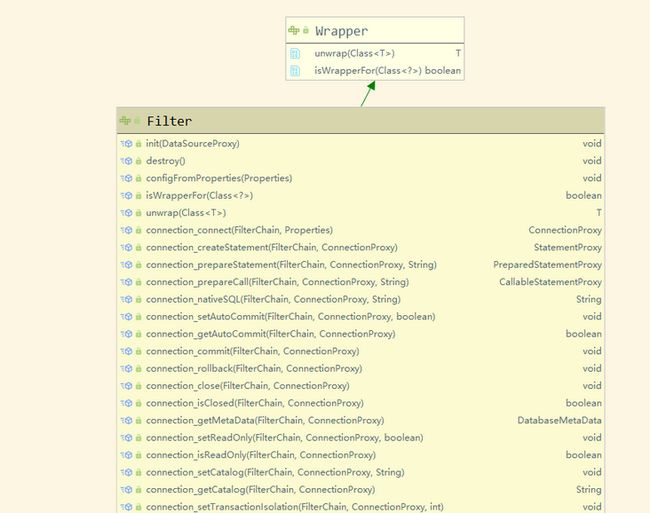
呃,太长了,看不了...总结一下,针对connection_xxx,resultSet_xxx,statement_xxx,preparedStatement_xxx,callableStatement_xxx,另外还有init,destroy等方法,基本参与了JDBC的全生命周期(datasource->connection->(Prepared)Statement->resultSet),果然是为监控而生。
抽象类FilterAdapter实现了filter接口,提供了基本的实现,大大减少了重复编码。
FilterEventAdapter继承FilterAdapter,在filter的基础上新增了xxxx_before,xxxx_after方法,可以用来做更多的事。
3.2 FilterChain
看类图,接口方法基本和filter一致,主要承担串联filter和传递调用事件的职责。该接口的实现类FilterChainImpl,随便找一个方法实现看一下:
public ConnectionProxy connection_connect(Properties info) throws SQLException {
// 将调用事件不断往下传递,直至this.pos == filterSize
if (this.pos < filterSize) {
return nextFilter()
.connection_connect(this, info);
}
// 本方法的职责处理
Driver driver = dataSource.getRawDriver();
String url = dataSource.getRawJdbcUrl();
Connection nativeConnection = driver.connect(url, info);
if (nativeConnection == null) {
return null;
}
return new ConnectionProxyImpl(dataSource, nativeConnection, info, dataSource.createConnectionId());
}此类的方法基本都是这种结构,分为传递调用和本方法的职责处理。
4.filter如何工作
4.1 初始化
DruidDataSource类init方法中有下面一段代码
for (Filter filter : filters) {
filter.init(this);
}4.2 如何工作
对于配置的filter以及自定义的filter都会在此初始化,如果有需要可以持有该datasource的引用。再看一下getConnection方法:
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
init();
// init初始化后,filters不会为空
if (filters.size() > 0) {
// 初始化chain
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
return getConnectionDirect(maxWaitMillis);
}
}可以看到,每次调用链中的方法,链总是在调用时初始化。再贴一下connection_connect方法
public DruidPooledConnection dataSource_connect(DruidDataSource dataSource, long maxWaitMillis) throws SQLException {
// 将调用事件不断往下传递,直至this.pos == filterSize
if (this.pos < filterSize) {
DruidPooledConnection conn = nextFilter().dataSource_getConnection(this, dataSource, maxWaitMillis);
return conn;
}
// 本职工作,获取Connection
return dataSource.getConnectionDirect(maxWaitMillis);
}
private Filter nextFilter() {
return getFilters()
.get(pos++);// 注意这里pos++
}FilterAdapter类的dataSource_getConnection方法
public DruidPooledConnection dataSource_getConnection(FilterChain chain, DruidDataSource dataSource,
long maxWaitMillis) throws SQLException {
return chain.dataSource_connect(dataSource, maxWaitMillis);// 将调用关系转接给chain对象,又回到上面的dataSource_connect方法
}贴一下调试截图

- 当this.pos == filterSize时,会执行真正的逻辑
chain通过持有的的Filter对象去调用真正的方法,Filter对象执行时,又将调用关系转接给chain,这样就能不断推进下去
流程图如下:
5.参考链接
druid源码研究之Filter: https://blog.csdn.net/lqzkcx3...
druid 源码分析与学习(含详细监控设计思路的彩蛋: https://www.iteye.com/blog/he...