利用Python爬取百度指数中需求图谱的关键词
文章目录
- 需求背景
- 一、使用datetime计算查询的日期
- 二、爬取需求图谱关键词
- 三、扔进csv里
- 总结
需求背景
因为百度指数中需求图谱的关键词只以一周为单位显示,所以为了将更多天数的关键词汇总,写了以下代码帮助大家~
ps:我是工管的,Python是我业余学的,所以代码写的比较丑陋请见谅…
一、使用datetime计算查询的日期
百度指数的params如下所示:
'wordlist[]': '原神',#这里修改关键词
'datelist': str(next_time.strftime('%Y%m%d'))#开始日期
为了计算datelist,所以需要用到datetime库。具体实现代码如下所示:
import datetime
start_time=datetime.date(2020,9,6)#开始爬取日期的上一周
for i in range (10):
next_time=start_time+datetime.timedelta(7)#+一周
print(next_time.strftime('%Y%m%d'))
start_time = next_time
二、爬取需求图谱关键词
它的数据是在XHR里的json格式,所以需要用到request库转换下,具体代码如下所示:
url='http://index.baidu.com/api/WordGraph/multi'
params = {
'wordlist[]': '原神',
'datelist': str(next_time.strftime('%Y%m%d'))
}
res_index = requests.get(url, params=params)
json_index = res_index.json()
list_index = json_index['data']['wordlist'][0]['wordGraph']
for index in list_index:
keyword_list = index['word']
三、扔进csv里
因为扔进一个csv里比较简单且会导致数据颗粒度太粗,所以我这里想的是将一个月的所有关键词放进一个csv文件里,然后下个月的所有关键词放到新的csv文件里,并且在文档名称中加上月份区分下,具体实现代码就直接给全部的了:
#coding=gbk
import csv,datetime
import requests
url='http://index.baidu.com/api/WordGraph/multi'#百度指数-需求图谱的url
start_time=datetime.date(2020,9,6)#开始爬取日期的上一周
while True:#这里不想爬太多可以改为for循环
next_time = start_time + datetime.timedelta(7)#+一周
if next_time.month ==3 and next_time.day==14:#因为目前这里截止到3.7号,所以3.14时停止循环
break
else:
if next_time.month == start_time.month :#如果月份都是一样的,扔进一个csv文件
with open('baiduzhishu' + str(start_time.month) + '.csv', 'a', newline='', encoding='gbk') as f:
writer = csv.writer(f)
params = {
'wordlist[]': '原神',#这里修改关键词
'datelist': str(next_time.strftime('%Y%m%d'))#开始日期
}
res_index = requests.get(url, params=params)
json_index = res_index.json()
list_index = json_index['data']['wordlist'][0]['wordGraph']
for index in list_index:
keyword_list = index['word']
writer.writerow([keyword_list])
else:
with open('baiduzhishu' + str(next_time.month) + '.csv', 'a', newline='', encoding='gbk') as f:#进入新的月份时新建一个csv文件
writer = csv.writer(f)
params = {
'wordlist[]': '原神',
'datelist': str(next_time.strftime('%Y%m%d'))
}
res_index = requests.get(url, params=params)
json_index = res_index.json()
list_index = json_index['data']['wordlist'][0]['wordGraph']
for index in list_index:
keyword_list = index['word']
writer.writerow([keyword_list])
start_time = next_time
总结
最终实现的结果如图所示:
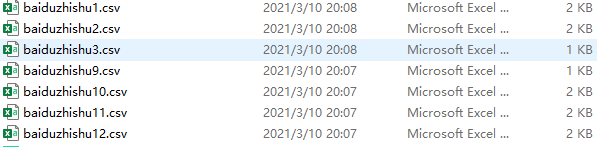
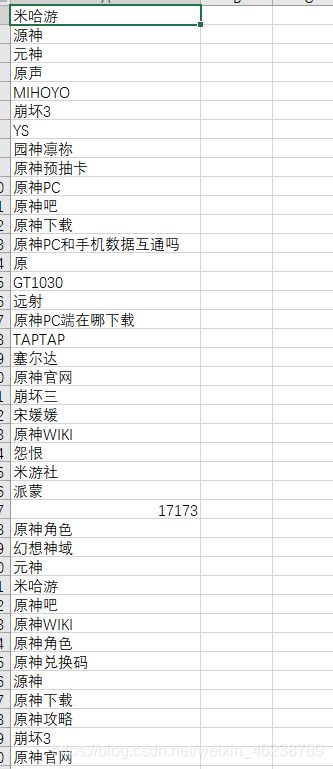
后续这些数据可以直接利用excel分析,也可以分开或者汇总放入https://wordart.com/这个网站里制作词云。