MySQL数据库InnoDB存储引擎底层原理详解
前言
从1996年发布MySQL1.0版本到现在已经历经25年头啦,在这期间不断更新版本,目前最新的版本是8.0。那InnoDB是什么东西?首先它肯定是MySQL的存储引擎并且实现技术相当复杂,如果要描述清楚是怎么实现,可能在烧烤桌上来几打啤酒也讲不完。本文对InnoDB存储引擎底层原理详解仅限目前所掌握的知识进行讲述。
一、InnoDB是什么?
InnoDB引擎是由InnobaseOy公司开发,是现在MySQL数据库默认引擎,具体发展历程不在本文讨论范围内。其实MySQL还有其他引擎如NDB、Memory、Archive、MyISAM等它们被设计应用在不同业务场景,InnoDB存储引擎的设计目标是面向在线事务处理(OLTP)的应用。以下是我从官网摘下来的InnoDB存储引擎功能清单。
| Feature | Support |
|---|---|
| B-tree indexes | Yes |
| Backup/point-in-time recovery (Implemented in the server, rather than in the storage engine.) | Yes |
| Cluster database support | No |
| Clustered indexes | Yes |
| Compressed data | Yes |
| Data caches | Yes |
| Encrypted data | Yes (Implemented in the server via encryption functions; In MySQL 5.7 and later, data-at-rest encryption is supported.) |
| Foreign key support | Yes |
| Full-text search indexes | Yes (Support for FULLTEXT indexes is available in MySQL 5.6 and later.) |
| Geospatial data type support | Yes |
| Geospatial indexing support | Yes (Support for geospatial indexing is available in MySQL 5.7 and later.) |
| Hash indexes | No (InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature.) |
| Index caches | Yes |
| Locking granularity | Row |
| MVCC | Yes |
| Storage limits | 64TB |
| Transactions | Yes |
| Update statistics for data dictionary | Yes |
二、InnoDB架构
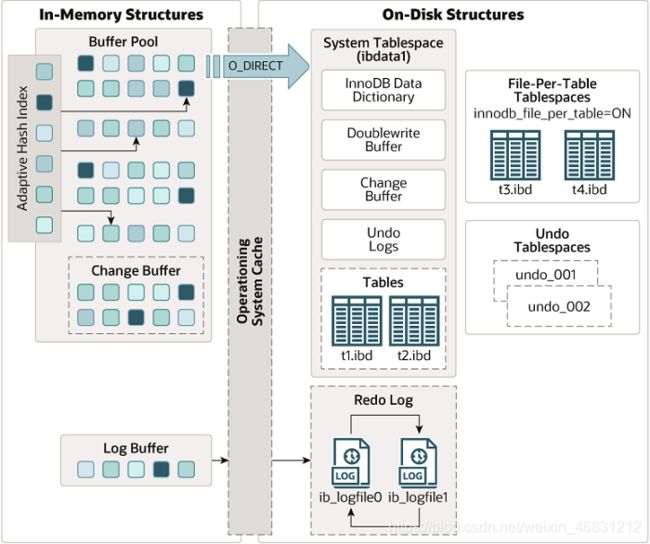
为了更好了解InnoDB存储引擎是如何工作,我把InnoDB的架构图展示出来,如下图显示了构成InnoDB存储引擎体系结构的内存和磁盘设计。(架构图摘自MySQL官网)
三、 InnoDB后台工作线程
InnoDB存储引擎是多线程模型,其后台运行着多个线程负责处理不同任务,主要有以下几大类。
Master Thread
Master thread是后台工作线程非常重要的核心线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,如将缓存池的脏页和日志缓存刷新到磁盘,合并插入缓冲。
IO Thread
InnoDB存储引擎为了提高数据库的性能,使用了AIO来处理IO读写的请求,在Innodb1.0版本之前有4个AIO分别是read、writer、insert buffer、log IO thread。
刚开始我也觉得奇怪,为什么使用AIO能够提升系统性能?继续了解才知道,假设用户发起一条select语句这条语句需要扫描多个索引页,需要多次磁盘IO操作,在每扫描一个页并等待它完成后才进行下一个,这样是非常耗时的。因此可以当用户发起一个IO请求后,不用等它完成,在发起下一个IO请求,等待所有的IO操作完成这就是AIO。
另外AIO还有另外一个作用,就是可以进行IO Merge操作,就是将多个IO合并成一个。
Purger Thread
Purger Thread的作用是回收已使用undo页。
Pager cleaner Thread
Pager cleaner Thread的作用是将缓存的脏页刷新到磁盘,减少Master Thread的工作负担。
四、内存
InnoDB访问磁盘获取数据时会进行高速缓存,以后再次使用直接从内存读取,这样极大的提升数据库整体性能。如InnoDB架构图所示,InnoDB内存结构有Buffer Pool、 Change Buffer、Adaptive Hash Index、Log Buffer,本文主要讲述Buffer Pool和Changer Buffer。
Buffer Pool
Buffer Pool是一块内存区域,操作数据库时需要从磁盘将数据加载到这块区域,之后数据的增删查改都是在这块内存区域进行,被修改的数据会通过CheckPoint机制刷新到磁盘,保证数据的一致性。
Buffer Pool初始化大小默认是128M,因InnoDB存储引擎默认的数据页是16K,Buffer Pool会被划分为8192数据页。数据页是最小的存储单位,数据页类型有数据页、索引页、Adaptive Hash Index、Change Buffer等
Free List、Flush List和LRU List
Buffer Pool是一块内存区域存放着各种类型的数据页,因此就需要进行管理,InnoDB的Buffer Pool是通过Free List、Flush List和LRU List来管理。
Free List
Buffer Pool初始化的时候每个数据页都是空闲的,随着后续对数据库的增删查改等操作,空闲的页就会被填充或者没有价值的页会被释放。此时Buffer Pool不知道那些数据页是空闲,所以需要Free列表进行管理,需要空闲页只需要从Free列表查找即可。
Free List是双向链表,链表的节点存储是空闲数据页的描述信息块。当需要从磁盘加载数据页到内存时会先从Free列表中找到空闲页,把数据页的表空间号和数据页号写入描述信息块,加载数据页写入空闲页后,该空闲页的描述信息块会从Free列表中移除。
Flush List
Flush列表和Free列表一样都是双向链表,只是Flush列表存放着脏页。在Buffer Pool里被修改的数据页称为脏页,需要Flush列进行管理。当需要将脏页刷到磁盘时从Flush列表查找。脏页被刷新到磁盘后描述信息块会从Flush列表移除变成空闲页,添加到Free列表中。
LRU List
LRU列表是用来管理从磁盘读取的数据页,在讲LRU列表之前我们先理解LRU算法(Latest Recent Used)。内存区域的数据页就是通过该算法来管理,通常频繁使用的数据页放在LRU列表头部,最少使用的页放在尾部,当内存区域不能存放新读取页时就会淘汰尾端的数据页。
但是这样会存在“缓存页污染”,当用户操作全表扫描时从磁盘读取大量数据页会把缓存中频繁使用数据页淘汰掉。为了解决这个问题InnoDB对LRU进行优化,下图是LRU列表优化后的结构图。
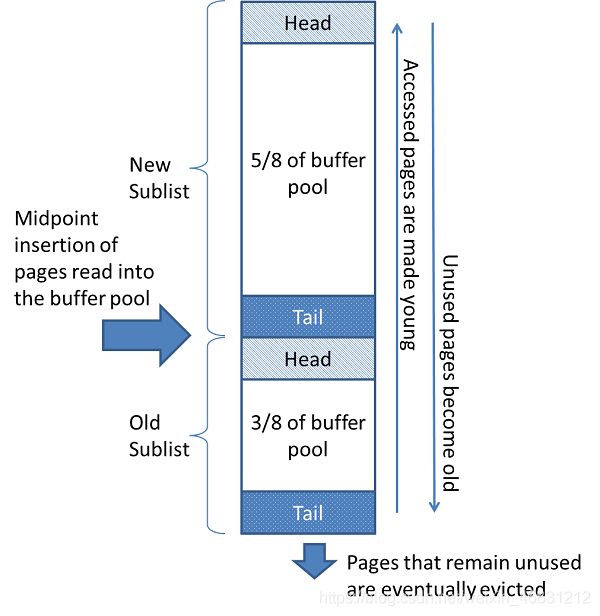
New Sublist表示存放热点数据页站用Buffer Pool内存大小63%,Old Sublist表示存放冷数据页站用Buffer Pool内存大小37%。
从磁盘读取数据页会先放到Old列表头部,如头部已存在数据页,该页会向后移动一个节点,最后空间不足存放新页就淘汰尾部的数据页。LRU列表还有一个设置参数innodb_old_blocks_time。这个参数的作用是,当再次访问Old列表数据页的时间T2减去该数据页开始存放的时间T1大于innodb_old_blocks_time时,把该数据页移动到New列头部,这样好处是即使全表扫描也不会把热点数据淘汰掉。
Change Buffer
Change Buffer也是Buffer Pool一部分,只是作用的对象不同。使用Chang Buffer必须满足两个条件:
1.索引是辅助索引
2.索引不是唯一
也就是说Change Buffer只存放辅助索引数据,当我们对辅助索引进行插入、删除、修改操作时,这些操作不会马上更新到Buffer Pool的辅助索引页,而是先判断这个辅助索引页是否存在Buffer Pool中,若存在直接更新,不在则先将操作记录放到Change Buffer一颗B+树中,等待合适时机将Change Buffer的记录合并到真正的辅助索引中,以下是Change Buffer关系图(摘自MySQL官网)

合并Chang Buffer的操作可能发生在以下几种情况:
第一种情况既当辅助索引页被读取到缓存时,通过检查Change Buffer Bitmap页,然后确认该辅助索引页是否有效记录存储在 Change Buffer B+树中,若有则将B+树中该页的记录合并到辅助索引页中,可见对该页的多次记录操作只要一次合并,大大提升了数据库性能。
第二种情况Master Thread。
第三种情况,当Change Buffer Bitmap页追踪到对应的辅助索引页无可用空间时,也就是可用空间少于1/32页时,会强制读取辅助索引页到缓存池中进行合并。
上面讲了合并 Change Buffer几种情况,但是关于Change Buffer还有两个问题值得思考:
1.为什么Innodb特别设计Change Buffer用来缓存辅助索引的操作记录。
摘自MySQL官网意思是二级索引插入相对随机无顺序的,同样二级索引删除和更新操作可能会影响索引树中不相邻的二级索引页,当通过其他操作将影响页读取到缓存时,在merge change buffer到该影响页,这样会避免从磁盘读取二级索引页到缓存池中造成大量随机访问IO。
对于上面的解释可以这么理解比如聚簇索引的主键id一般是顺序,自增长,插入记录只要记录在上一条记录后面,当主键页满时继续记录到新页。辅助索引是相对无序的,不一定就是记录在上一条记录后面,通常要根据大小插入相应位置,还有可能插入目标页不在缓存池里又要从磁盘读取,这样就会造成随机访问IO。
2.为什么Change Buffer不适合主键索引和唯一索引。
首先主键索引和唯一索引有共同特性就是索引值唯一,因此插入数据时需要从磁盘读取索引页到缓存池,也就是索引页都在缓存池了,直接更改就行,没必要在使用Change Buffer。
五、Double Write
Double Wite(两次写)是为了提升脏页刷新到磁盘时的可靠性,如上面所说InnoDB存储引擎默认的页大小16k,而操作系统的页一般是4k。假如刷到8k时,之后就出现宕机,就会造成部分写失效。下图展示的是Double Wite架构图(摘自MySQL技术内幕InnoDB存储引擎第2版)
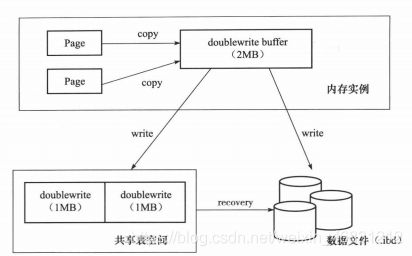
Double Write由两部分组成,一部分是内存doublewrite buffer大小为2M,另一部分是物理磁盘上共享表空间中连续的128个页,两个区总共大小也是2MB。
Double Write具体步骤如下:
- 将要刷新的脏页复制写入到doublewrite buffer。
- 将doublewrite buffer的数据页,分两次写入磁盘共享空间表文件,每次写入大小为1MB。因doublewrite buffer的页是顺序的,这个过程写入会很快。
- 待第二步骤完成后,会将doublewrite buffer的脏页写入到实际各个表空间中。
上面的操作步骤看起来很完美,也许会想对于上面执行过程中出现宕机怎么办。其实不必担忧,对于执行第一、二步骤出现故障时,待重启数据库redo log机制会帮忙恢复缓存池中没有刷新到磁盘的脏页。
对于第三步出现故障,可以从共享空间表文件找到该页的一个副本,然后复制到其表空间文件,在应用redo log机制就可以恢复。
总结
本文主要讲述了InnoDB存储引擎的后台工作线程和内存结构如Buffer Pool、Change Buffer里面的一些运行机制,实际上它们实现原理是非常复杂的,还有很多原理和细节本文没有提到。此外InnoDB存储引擎的内存结构只是它的一部分,还有事务、锁、日志等重要的功能它们是非常庞大,个人掌握知识有限,无法一五一十的讲。
参数资料
MySQL技术内幕InnoDB存储引擎第2版
MySQL官网InnoDB存储引擎