Pandas 最全的使用方式(下)
大家好,作为一名互联网行业的小白,写博客只是为了巩固自己学习的知识,但由于水平有限,博客中难免会有一些错误出现,有不妥之处恳请各位大佬指点一二!
博客主页:链接: https://blog.csdn.net/weixin_52720197?spm=1018.2118.3001.5343
7 整体数据管理
7.1 数据拆分
7.1.1 数据分组
df.groupby(
by :用于分组的变量名/函数
level = None :相应的轴存在多重索引时,指定用于分组的级别
as_index = True :在结果中将组标签作为索引
sort = True :结果是否按照分组关键字逬行排序
)#生成的是分组索引标记,而不是新的 df
单个数据分组
# 数据分组
dfg = df.groupby('开设')
dfg
# 查看dfg里面的数据
dfg.groups
# 查看具体描述
dfg.describe()
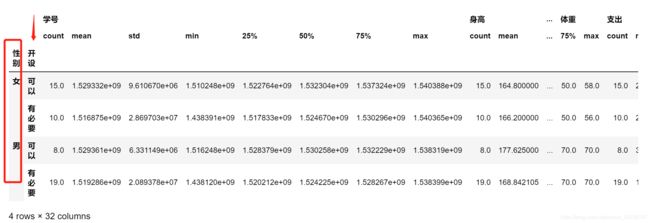
多个数据分组
dfg2 = df.groupby(['性别','开设'])
dfg2.describe()
7.1.2 基于拆分进行筛选
筛选出其中一组
dfgroup.get_group()
# 查看均值
dfg.get_group (‘课程').mean ()
筛选出所需的列
该操作也适用于希望对不同的变量列进行不同操作时
dfg[‘身高'].max()
7.2 分组汇总
在使用 groupby 完成数据分组后,就可以按照需求进行分组信息汇总,此时可以使用其它专门的汇总命令,如 agg 来完成汇总操作
7.2.1 使用 agg 函数进行汇总
df.aggregate( )
名称可以直接简写为 agg
可以用 axis 指定汇总维度
可以直接使用的汇总函数


# 引入非内置函数
import numpy as np
df2 .身高. agg (np. sum)
df2g.身高. agg (np. sum)
引用自定义函数
def mymean(x):
return x.mean()
df2 .身高.agg (mymean)
df2g.agg(mymean)
7.2.2 其他分组汇总方法
在生成交叉表的同时对单元格指定具体的汇总指标和汇总函数
df.pivot_table()
pd.crosstab()
pd.crosstab (df .性别,df.身高)
7.3 长宽格式转换
基于多重索引,Pandas 可以很容易地完成长型、宽型数据格式的相互转换。
7.3.1 转换为最简格式
df.stack(
level = -1 :需要处理的索引级别,默认为全部,int/string/list
dropna = True :是否删除为缺失值的行
)#转换后的结果可能为 Series
7.3.2 长宽型格式的自由互转
df.unstack(
level = -1 :需要处理的索引级别,默认为全部,int/string/list
fill_value :用于填充缺失值的数值
)
# 行列互相转换
数据转置: df.T
7.4 多个数据源的合并
7.4.1 数据的纵向合并
df.append(
other :希望添加的 DF/Series/字典/上述对象的列表 使用列表方式,就可以实现一次合并多个新对象
ignore_index = False :添加时是否忽略索引
verify_integrity = False :是否检查索引值的唯一性,有重复时报错
)
df = df.append( [df2, df3, df4])
7.4.2 数据的横向合并
merge 命令使用像 SQL 的连接方式
pd.merge(
需要合并的 DF
left :需要合并的左侧 DF
right :需要合并的右侧 DF
how = ' inner':具体的连接类型
{
left、right 、outer 、 inner、)
两个 DF 的连接方式
on :用于连接两个 DF 的关键变量(多个时为列表),必须在两侧都出现
left_on :左侧 DF 用于连接的关键变量(多个时为列表)
right_on :右侧 DF 用于连接的关键变量(多个时为列表)
left_index = False :是否将左侧 DF 的索引用于连接
right_index = False :是否将右侧 DF 的索引用于连接
其他附加设定
sort = False :是否在合并前按照关键变量排序(会影响合并后的案例顺序)
suffixes :重名变量的处理方式,提供长度为 2 的列表元素,分别作为后缀
suffixes=(‘_x' 、‘_y')
copy = True
indicator = False :在结果 DF 中增加'_merge ' 列,用于记录数据来源 也可以直接提
供相应的变量列名
Categorical 类型,取值: left_only 、 right_only 、both
validate = None :核查合并类型是否为所指定的情况
one_to_one or 1:1
one_to_many or 1:m
many_to_one or m:1
many_to_many or m:m
7.4.3 Concat 命令简介
同时支持横向合并与纵向合并
pd.concat(
objs :需要合并的对象,列表形式提供
axis = 0 :对行还是对列方向逬行合并
(0 index 、 1 columns )
join = outer :对另一个轴向的索引值如何逬行处理
(inner 、outer )
ignore_index = False
keys = None :为不同数据源的提供合并后的索引值
verify_integrity = False
copy = True
)
纵向合并
df1 = pd.read_excel("stu_data.xlsx", sheet_name = ‘new1' )
df2 = pd.read_excel("stu_data.xlsx", sheet_name = ‘new2' )
pd.concat([df1,df2])
pd.concat([df1,df2], key=[‘a','b'])
横向合并
df1 = pd.read_excel("stu_data.xlsx", sheet_name = ‘new4' )
df2 = pd.read_excel("stu_data.xlsx", sheet_name = ‘new5' )
pd.concat([df1,df2 ], axis = 1)
8.1 处理缺失值
8.1.1 系统默认的缺失值
系统默认的缺失值
None 和 np. nan
确定数值是否是缺失值
df. isna () # 别名为 isnull, 反函数为 notna
None 和 np.nan 的区别:能否进行比较
None == None
np.nan == np.nan
设定 in 和 inf 是否被认定为缺失值
# 查看是无穷大与无穷小是否为缺失值
pandas.options.mode.use_inf_as_na
8.1.2 处理自定义缺失值
目前 Pandas 不支持设定自定义缺失值,因此只能考虑将其替换为系统缺失值
df.replace('自定义值',np.nan)
df .开设.replace ("不清楚",np.nan)
设定为 None 后的效果完全不同
df .开设,replace ("不清楚",None)
df2 = df .replace ( [“不清楚”,171] ,[np.nan, np.nan] ) # 后面的中括号可以简写 np.nan
8.1.3 标识缺失值
df.isna(): 检查相应的数据是否为缺失值 同 df.isnull()
df2 = df .replace ( [“不清楚”,171] ,np.nan )
检查多个单元格的取值是否为指定数值
df.any(
axis : index (0), columns (1)
skipna = True :检查时是否忽略缺失值
level = None :多重索引时指定具体的级别
df.all(
axis : index (0), columns (1)
skipna = True :检查时是否忽略缺失值
level = None :多重索引时指定具体的级别
)
用法:
# 默认检测的是列值
df2.isna().any()

df2.isna().all()

8.1.4 填充缺失值
df.fillna(
value :用于填充缺失值的数值,也可以提供dict/Series/DataFrame 以进—步指明哪些索引/列会被替换 不能使用 list
method = None :有索引时具体的填充方法,向前填充,向后填充等
limit = None :指定了 method 后设定具体的最大填充步长,此步长不能填充
axis : index (0), columns (1)
inplace = False
)
df .replace ( [“不清楚”,171] ,np.nan ). fillna (‘未知')
df .replace ( [“不清楚”,171] ,np.nan ) .fillna(df2.mean( ))
8.1.5 删除缺失值
df.dropna(
axis = 0 : index (0), columns (1)
how = any : any、all
any :任何一个为 NA 就删除
all :所有的都是 NA 删除
thresh = None :删除的数量阈值,int
subset :希望在处理中包括的行/列子集
inplace = False :
)
8.2 数据查重
8.2.1 标识出重复的行
标识出重复行的意义在于进一步检査重复原因,以便将可能的错误数据加以修改
Duplicated
df[‘dup' ] = df.duplicated( [‘课程','开设'])
利用索引进行重复行标识
df.index.duplicated()
df2 = df.set_index ( [‘课程','开设'] )
df2.index. duplicated ()
8.2.2 直接删除重复的行
drop_duplicates (
subset=“ ”按照指定的行逬行去重
keep='first' 、 'last' 、 False 是否直接删除有重复的所有记录
)
df. drop_duplicates ( [‘课程', '开设' ] )
df. drop_duplicates ( [‘课程', '开设' ] , keep = False )
利用査重标识结果直接删除
df[~df.duplicated( )
df[~df . duplicated ( [‘课程', '开设' ] )
9 日期时间变量
9.1 Timestamp 与 Period
9.1.1 Timestamp
from datetime import datetime
import pandas as pd
# 获取当前时间
pd.Timestamp(datetime.now())
# 获取指定时间
pd.Timestamp(datetime(2022,1,1))
# 指定时分秒
pd.Timestamp(datetime(2022,1,1,1,2,3))
pd.Timestamp(2022,1,1)
# 给字符串
pd.Timestamp('2022-01-01 1:2:3')
9.1.2 Peroid
可以被看作是简化之后的 Timestamp 对象
由于详细数据的不完整,而表示的是一段时间,而不是一个时点
但是实际使用中很可能是按照时点在使用
很多使用方法和 Timestamp 相同,不再详细介绍
# 精确到——月
pd.Period('2022-01')
# 精确到——天
pd.Period('2022-01',freq='D')
9.2 数据转换 Timestamp 类
9.2.1 使用 pd.Timestamp()直接转换
pd.Timestamp(df[‘date'] [0])
df[‘date'].apply(pd.Timestamp)
9.2.2 用 to_datetime 进同比量转换
pd.to_datetime(
arg :需要转换为 Timestamp 类的数值
Integer, float, string, datetime, list, tuple, 1-d array, Series,
errors = ‘raise' : (‘ ignore' , ‘raise' , 'coerce' )
‘raise ' 抛出错误
‘coerce' 设定为 NaT
‘ignore' 返回原值
短日期的解释方式:类似 '10/11/12"这样的数据如何解释
dayfirst = ‘False' : 数值是否 day 在前
yearfirst = 'False':数值是否 year 在前,该设定优先
box = True :是否返回为 DatetimeIndex, False 时返回 ndarray 数组
format = None :需要转换的字符串格式设定)
代码如下:
# 传递datetime
pd.to_datetime(datetime(2022, 1, 2, 3, 4, 5))
# 传递str
pd.to_datetime('2022-01-02 3:4:5')
# 传递list
pd.to_datetime(['2022/01/02' , '2022.01.03'])
# pd.to_datetime(df[['Year','Month','Day','Hour']])
pd.to_datetime(df[ 'date' ], format = '%Y-%m-%d %H:%M')
9 2.3 基于所需的变量列合成 Timestamp 类
pd.to_datetime(df[ [‘Year' , 'Month' , ‘Day' , ‘Hour']])
9.3 使用 DatetimeIndex 类
Datetimeindex 类对象除了拥有 Index 类对象的所有功能外,还针对日期时间的特点有如下增强:
1.基于日期时间的各个层级做快速索引操作
2.快速提取所需的时间层级
3.按照所指定的时间范围做快速切片
9.3.1 建立 Datetimeindex 对象
1. 建立素引时自动转换
使用 Timestamp 对象建立索引,将会自动转换为 DatetimeIndex 对象
df_index = df.set_index(pd.to_datatime(df[‘data1']))
2. 通过 date_range 建立
这种建立方式主要是和 reindx 命令配合使用,以快速完成对时间序列中缺失值的填充工作
pd.date_range(
start /end = None :日期时间范围的起点/终点,均为类日期时间格式的字符串/数据
periods = None :准备生成的总记录数
freq = 'D':生成记录时的时间周期,可以使用字母和数值倍数的组合,如'5H'
name = None :生成的 DatetimeIndex 对象的名称
)
pd.bdate_range(
主要参数和 pd.date_range 几乎完全相同,但默认 freq = 'B' (business daily) 另外附加了几个针对工作日/休息日筛选的参数
)
pd.date_range('2/1/2022', periods=5, freq='M')
9.4 时间序列做基本使用
9.4.1 序列的分组汇总
9.4.1.1 直接取出素引的相应层级
DatetimeIndex 对象可直接引用的属性


df.index.year
9.4.1.2 直接使用 groupby 方法进行汇总
df.groupby(df2.index.year).max( )
9.4.1.3 resample( )
使用上比 groupby 更简单(输入更简洁)
可以将数值和汇总单位进行组合,实现更复杂的汇总计算
df.resample(‘3M').mean( )
9.4.2 时间缺失值的处理
时间序列要求记录的时间点连贯无缺失,因此需要:
首先建立针对整个时间范围的完整序列框架
随后针对无数据的时间点进行缺失值处理
df = pd.read_excel(‘stu_data.xlsx', index_col = 2)
Index2 = pd.date_range(‘2005-01-01', '2018-01-01' )
df.reindex(index2)
9.4.3 序列数值平移
df.shift(
periods = 1: 希望移动的周期数
freq :时间频度字符串
axis =0
)
df.shift( 3 )
10 数据的图形展示
10.1 配置绘图系统环境
df [‘数据’].plot .box (title=‘标题’,ylim= (60,80))
#中文字符兼容问题
import matplotlib
matplotlib.reParams[‘font.sans-serif'] = [‘SimHei']
#绘图功能的逬一步美化和功能增强包,参考 http: //seaborn .pydata. org/
import seaborn
seaborn.set_style(‘whitegrid')
#注意有中文兼容问题,需要重新导入中文设定!
逬一步在一些细节上的美化和优化
import matplotlib.pyplot as plt
pit.figure ()
df.plot(
绘图用数据
data :数据框
x = None:行变量的名称/顺序号
y = None :列变量的名称/顺序号
kind = 'line':需要绘制的图形种类
line : line plot (default)
bar : vertical bar plot
barh : horizontal bar plot
hist : histogram
box : boxplot
kde : Kernel Density Estimation plot
density : same as kde
area : area plot
pie : pie plot
scatter : scatter plot
hexbin : hexbin plot
各种辅助命令
figsize : a tuple (width, height) in inches
xlim / ylim : X/Y 轴的取值范围,2-tuple/list 格式
logx / logy / loglog = False :对 X/Y/双轴同时使用对数尺度
title : string or list
Alpha :图形透明度,0-1
图组命令
subplots = False :是否分图组绘制图形
sharex :是否使用相同的 X 坐标
ax = None 时,取值为 True,否则取值为 False
sharey = False :是否使用相同的 Y 坐标
ax = None :需要叠加的 matplotlib 绘图对象
图形种类的等价写法
df.plot.kind()
df [‘身高'].plot .box (title='第一个图',ylim= (60,80))
df.体重.plot(figsize = (12,8 ))
df.groupby(df.性别).体重.plot( )
10.2 条图
pd.value_counts(df.课程).plot.bar()
pd.value_counts(df.课程).plot.barh()
import numpy as np
df2 = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d'])
df2.plot.bar( )
df2.plot.bar( stacked= True )
10.3 直方图
plot.hist(
by :在 df 中用于分组的变量列(绘制为图组)
bins = 10 :需要拆分的组数)
hist(by :在 df 中用于分组的变量列(绘制为图组))
10.4 饼图
plot.pie(
y :指定需要绘制的变量列名称
subplots = False :多个变量列时要求分组绘图)
10.5 箱图
plot.box(
vert = True :是否纵向绘图)
10.6 散点图
plot.scatter(
S :控制散点大小的变量列,不能使用 df 中的简写方式指定
C :控制散点颜色的变量列)
11 数据特征的分析探索
11.1 数值变量的基本描述
df.describe(
percentiles :需要输出的百分位数,列表格式提供,如[.25, .5, .75]
include = 'None ':要求纳入分析的变量类型白名单
None (default):只纳入数值变量列
A list-like of dtypes :列表格式提供希望纳入的类型
all :全部纳入
exclude :要求剔除出分析的变量类型黑名单,选项同上
)
df.describe( )
df.describe(include = ‘all’ )
11.2 分类变量的频数统计
Series.value_counts(
normalize = False :是否返回构成比而不是原始频数
sort = True :是否按照频数排序(否则按照原始顺序排列)
ascending = False : 是否升序排列
bins :对数值变量直接进行分段,可看作是 pd.cut 的筒便用法
dropna = True :结果中是否包括 NaN
)
pd. value_counts (df2 .体重)
pd. value_counts (df2 .体重,normalize=True)
pd. value_counts (df2 .体重,sor
11.3 交叉表/数据透视表
df.pivot_table(
行列设定
index / columns :行变量/列变量,多个时以 list 形式提供
单元格设定
values :在单元格中需要汇总的变量列,可不写
aggfunc = numpy.mean : 相应的汇总函数
汇总设定
margins = False :是否加入行列汇总
margins_name = 'All':汇总行/列的名称
缺失值处理
fill_value = None :用于替换缺失值的数值
dropna = True :
)
pd.crosstab(
选项和 pivot_table 几乎相同相对而言需要打更多字母,因此使用更麻烦但是计算频数最方便输出格式为数据框 )
df.pivot_table(index =['课程','性别'],columns='软件',aggfunc = sum)
pd.crosstab(index =[df.课程],columns=df.软件,values=df.体重,aggfunc=sum)
12 如何优化 Pandas
除非对相应的优化手段已经非常熟悉,否则代码的可读性应当被放在首位。过早优化是万
恶之源!
pandas 为了易用性,确实牺牲了一些效率,但同时也预留了相应的优化路径。因此如果
要进行优化,熟悉并优先使用 pandas 自身提供的优化套路至关重要。
尽量使用 pandas(或者 numpy)内置的函数进行运算,一般效率都会更高。
在可以用几种内部函数实现相同需求时,最好进行计算效率的比较,差距可能很大。
12.1 学会使用各种计时工具
%time 和%timeit,以及%%timeit(需要在 IPython 下才可以使用)
# 统计程序所需的时间
%time df['new_col'] = df.体重-df.支出
%timeit df['new_col'] = df.体重-df.支出
%%timeit
df['new_col'] = df.体重-df.支出
df['new_col'] = df.体重-df.支出
df['new_col'] = df.体重-df.支出
df['new_col'] = df.体重-df.支出
python 时间方式
from datetime import datetime
import time
t1 = datetime.now()
t2 = time.time()
time.sleep(1)
print(datetime.now()- t1)
print(time.time()-t2)
用 line_profiler 做深入分析
from line_profiler import LineProfiler
import random
def m_test(numbers):
s = sum(numbers)
l = [numbers[i]/50 for i in range(len(numbers))]
m = ['hello' + str(numbers[i]) for i in range(len(numbers))]
lp = LineProfiler() # 定义一个 LineProfiler 对象
lp_wrapper = lp(m_test) # 用 LineProfiler 对象监控需要分析的函数
12.2 超大数据文件的处理
超大数据文件在使用 pandas 进行处理时可能需要考虑两个问题:读取速度,内存用量。
一般情况会考虑读入部分数据进行代码编写和调试,然后再对完整数据进行处理。
在数据读入和处理时需要加快处理速度,减少资源占用。
12.2.1 一些基本原则
当明确知道数据列的取值范围时,读取数据时可以使用 dtype 参数来手动指定类型,
如 np.uint8 或者 np.int16,否则默认的 np.int64 类型等内存开销明显非常大。
尽量少用类型模糊的 object,改用更明确的 category 等(用 astype()转换)。
对类别取值较少,但案例数极多的变量,读入后尽量转换为数值代码进行处理。
data = pd.DataFrame({
"a" : [0,1, 2, 3, 4, 5, 6, 7, 8, 9],
"b" : ["祖安狂人","祖安狂人","冰晶凤凰","冰晶凤凰",
"祖安狂人","祖安狂人","祖安狂人","冰晶凤凰", "冰晶凤凰","祖安狂人"]})
print(data)
data.info()
# 把内存变小——downcast 降级
data['a'] = pd.to_numeric(data['a'], downcast = 'integer')
data['b'] = data['b'].astype('category')
print(data)
data.b.head() # category 格式明显更节省内存
data.info()
data.b.astype('str') # 必要时 category 也可以转换回 str
12.2.2 对文件进行分段读取
使用 chunksize 参数
dftmp = pd.read_csv('stu_date.csv', usecols = [0,2,3,4,5,6,7], chunksize = 5)
type(dftmp) # 注意得到的并不是一个数据框,而是 TextFileReader
n = 0
for item in dftmp: # 注意重复运行之后的效果
print(item)
n += 1
if n > 2:
break
使用 iterator 参数和 get_chunk()组合
dftmp = pd.read_csv('stu_date.csv', usecols = [0,2,3,4,5,6,7], iterator = True)
type(dftmp) # 注意得到的并不是一个数据框,而是 TextFileReader
dfiter.get_chunk(10) # 注意重复运行之后的效果
12.3 如何优化 pandas 的代码
12.3.1 简单优化
尽量不要在 pandas 中使用循环
如果循环很难避免,尽量在循环体中使用 numpy 做计算。
# 代码运算的时间
%%timeit
#标准的行/列遍历循环方式效率最差,
df['new'] = 0
for i in range(df.shape[0]):
# df.iloc[行,列]
# 新建第8列 = 第4列+10
df.iloc[i, 8] = df.iloc[i, 4] + 10
#apply 自定义函数/外部函数效率稍差
def m_add(x):
return x + 10
%timeit df["new"] = df.支出.apply(lambda x : m_add(x))
#在 apply 中应用内置函数方式多数情况下速度更快
%timeit df["new"] = df.支出.apply(lambda x: x + 10)
直接应用原生内置函数方式速度最快
%timeit df["new"] = df.支出 + 10
12.3.2 如何进行多列数据的计算
同时涉及多列数据的计算不仅需要考虑速度优化问题,还需要考虑代码简洁性的问题。
%%timeit
def m_add(a, b, c):
return a + b + c
df['new'] = df.apply(lambda x :m_add(x['支出'], x['体重'], x['身高']), axis = 1)
%%timeit
# 使用内置函数 5.33 ms
#lambda 多参方式可能效率反而更低
df['new'] = df[['支出', '体重', '身高']].apply(lambda x :x[0] + x[1] + x[2], axis = 1)
# 使用pandas内置 664 µs
# 最香
%timeit df['new'] = df['支出'] + df['体重'] + df['身高']
pd.eval()命令
pd.eval()的功能仍是给表达式估值,但是基于 pandas 时,就可以直接利用列名等信息用于计算。
#eval()默认会使用 numexpr 而不是 python 计算引擎,复杂计算时效率很高
#engine 参数在调用 numexpr 失败时会切换为 python 引擎,一般不用干涉
%timeit df.eval('new = 支出 + 体重 + 身高', inplace = True)
#eval()默认会使用 numexpr 而不是 python 计算引擎,复杂计算时效率很高
%timeit df.eval('new = 支出 + 体重 + 身高', engine = 'python', inplace = True)
%%timeit
df['n1'] = df.支出 + 1 df['n2'] = df.支出 + 2 df['n3'] = df.体重 + 3
df.head()
pd.在 eval()表达式中进一步使用局部变量
@varname:在表达式中使用名称为 varname 的 Python 局部变量。该@符号在 query()和
eval()中均可使用。
%%timeit
arg = 3
bj.eval('new = 支出 + 体重 + 身高 + @arg').head()
12.4 利用各种 pandas 加速外挂
大部分外挂包都是基于 linux 环境,windows 下能用的不多。大部分外挂包还处于测试阶段,功能上并未完善。
12.4.1 numba
对编写的自定义函数进行编译,以提高运行效率。
A Just-In-Time Compiler for Numerical Functions in Python 具体使用的是 C++编写的
LLVM(Low Level Virtual Machine) compiler 实际上主要是针对 numpy 库进行优化编译,并不仅限于 pandas
import random
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = random.random()
y = random.random()
if (x ** 2 + y ** 2) < 1.0:
acc += 1
return 4.0 * acc / nsamples
%timeit monte_carlo_pi(20) # 运行被监控的函数,获取各部分占用的运行时间数据

# 注意安装 pip install numba
from numba import jit
@jit(nopython = True) # nopython模式下性能最好
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = random.random()
y = random.random()
if (x ** 2 + y ** 2) < 1.0:
acc += 1
return 4.0 * acc / nsamples
%timeit monte_carlo_pi(20)

from numba import jit
@jit
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = random.random()
y = random.random()
if (x ** 2 + y ** 2) < 1.0:
acc += 1
return 4.0 * acc / nsamples
%timeit monte_carlo_pi(20)

12.4.2 swifter
对 apply 函数进行并行操作是专门针对 pandas 进行优化的工具包
df = pd.DataFrame({
'x': [1, 2, 3, 4], 'y': [5, 6, 7, 8]})
# runs on single core
%timeit df['x2'] = df['x'].apply(lambda x: x**2)
import swifter
# runs on multiple cores
%timeit df['x2'] = df['x'].swifter.apply(lambda x: x**2)
%timeit df['agg'] = df.apply(lambda x: x.sum() - x.min())
%timeit df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())