hadoop配置文件
安装前的工作:
- jdk
- 集群中节计算机互联互通
- 关闭防火墙
- 节点间的计算机免密码登录(authorized_keys认证文件root用户存放在/root/.ssh/)
(User用户 /home/user/.ssh/)
A计算机免密码登录B计算机,将A计算机的公钥存放在B计算机的认证文件authorized_keys
产生
安装hadoop
Bin目录-命令eg : hadoop namenode -format
Sbin目录-各种启动文件\停止服务
Etc/hadoop/ 各种配置文件

1.hadoop-env.sh 环境配置
export JAVA_HOME=${
JAVA_HOME}
[root@NAME250 hadoop]# echo $JAVA_HOME
/software/jdk1.8.0_65
[root@NAME250 hadoop]#
2.core-site.xml 核心配置
3.hdfs-site.xml
4.yarn-site.xml
5. mapred-site.xml cp mapred-site.xml.template mapred-site.xml
6. slaves 从节点计算机
7. masters主节点配置
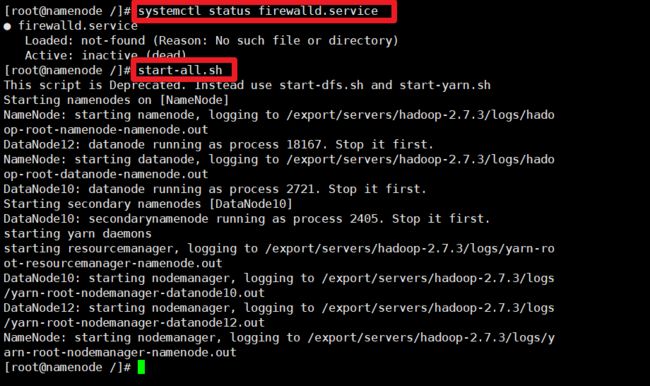
配置core-site.xml(如图1-60所示)。
[root@master hadoop]# vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>//master是主节点namenode主机名:9000端口号
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
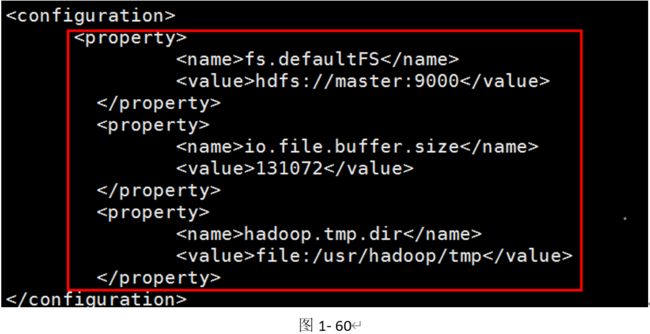
7)配置hdfs-site.xml(如图1-61所示)。
[root@master hadoop]# vi hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name> //复本数量
<value>3</value>
</property>
修改Hadoop中HDFS的配置,配置的备份方式默认为3
8)配置yarn-site.xml(如图1-62所示)。
[root@master hadoop]# vi yarn-site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>//
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>

9)配置mapred-site.xml(如图1-63所示)。
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
10)配置masters文件(如图1-64所示)。
[root@master hadoop]# vi masters #加入以下内容 主节点的IP地址

11)配置slaves文件(如图1-65所示)。
[root@master hadoop]# vi slaves #删除localhost,加入以下内容 从节点的IP地址

至此 配置文件基本配置完毕。
12)新建目录。
[root@master hadoop]# mkdir /usr/hadoop/tmp
[root@master hadoop]# mkdir /usr/hadoop/dfs/name -p
[root@master hadoop]# mkdir /usr/hadoop/dfs/data -p
13)修改/usr/hadoop目录的权限。
[root@master hadoop]# chown -R hadoop:hadoop /usr/hadoop/
14)将master上的hadoop安装文件同步到slave1 slave2 slave3。
[root@master hadoop]#cd
[root@master ~]# scp -r /usr/hadoop/ root@slave1:/usr/
[root@master ~]# scp -r /usr/hadoop/ root@slave2:/usr/
[root@master ~]# scp -r /usr/hadoop/ root@slave3:/usr/
15)在每个slave节点上配置hadoop的环境变量(所有slave节点)。
[root@master ~]# vi /etc/profile #文件末尾添加
# set hadoop environment
export HADOOP_HOME=/usr/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
16)使配置的hadoop的环境变量生效(所有slave节点)。
[root@master ~]# source /etc/profile
17)修改/usr/hadoop目录的权限(所有slave节点)。
[root@master ~]# chown -R hadoop:hadoop /usr/hadoop/
18)切换到hadoop用户(所有slave节点)。
[root@master ~]#su - hadoop
19)先格式化(master节点)。
[hadoop@master ~]$ hadoop namenode -format
20)启动hadoop(master节点)(如图1-66所示)。
[hadoop@master ~]$ start-all.sh
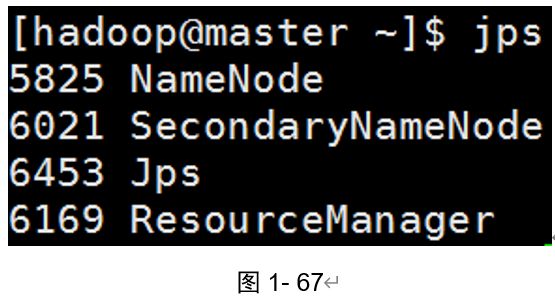
21)查看Java进程(如图1-67所示)。
master节点
[hadoop@master ~]$ jps
Slave1节点(如图1-68所示)。
[hadoop@slave1~]$ jps

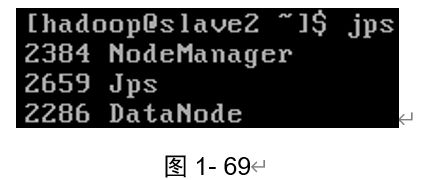
Slave2节点(如图1-69所示)。
[hadoop@slave2~]$ jps
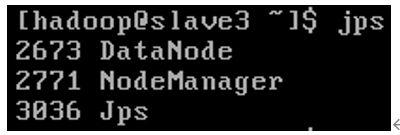
Slave3节点(如图1-70所示)。
[hadoop@slave3~]$ jps
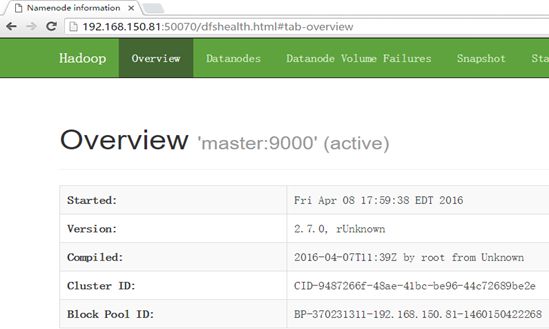
5)使用浏览器浏览Master节点机http://192.168.150.81:50070,查看NameNode节点状态(如图1-71所示)。
6)浏览Datanode数据节点
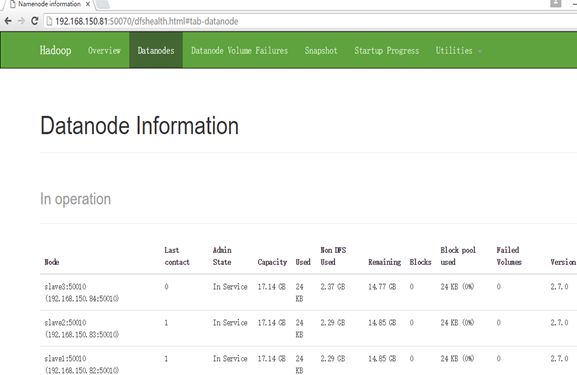
注意:这俩操作是必须执行的,不然浏览器访问不了数据节点