Hive笔记 —— 表加载数据的四种方式
目录
-
-
-
- 建表
- 内部表,外部表删除表的区别
- 利用location改变表的存储位置
- truncate 清空表数据的情况
- 加载数据的四种方式
-
-
- hadoop dfs -put linux本地路径 hdfs路径
- dfs -put linux本地路径 hdfs路径
- load data inpath 'hdfs路径' into table 表名
- load data local inpath 'linux本地路径' into table 表名
-
-
-
建表
create table students(
id bigint comment '学生id',
name string comment '学生姓名',
age int comment '学生年龄',
gender string comment '学生性别',
clazz string comment '学生班级'
) comment '学生信息表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
创建一个内部表,表名为 students
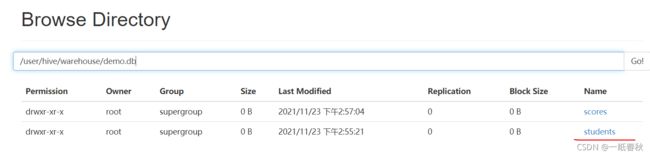
在hive里面建立数据库后,默认会在hdfs里面的 /user/hive/warehouse下面生成一个数据库文件夹,这里创建的数据库名字叫demo,生成的文件夹名字为 demo.db
之后在这个数据库里面建表,建表成功后会在 demo.db 文件夹下面创建一个新的文件夹,文件夹名字就是表名(前提是没有使用location语句)
将本地存放数据的students.txt文件上传到这个文件夹里面,hadoop dfs -put students.txt /user/hive/warehouse/demo.db/students
然后就可以直接在hive中操作,hive> select * from students;

发现数据被成功读取,说明将文件上传到 hive的表的对应路径下,hive会自动加载文件进入表中
另外,文件名不需要与表名相同,我建立了一个表名为scores的表,传入文件夹里面的文件名为score.txt,一样能正常读取数据
但是要求字段要一样,比如建表语句里面只设置了三个字段,但是文件中一行有五个字段,那么读取的时候就会出现问题
内部表,外部表删除表的区别
内部表删除表的同时会删除存储数据
拿上面创建的students内部表举例,还没有删表时,可以在hdfs中查找到传入的数据文件students.txt
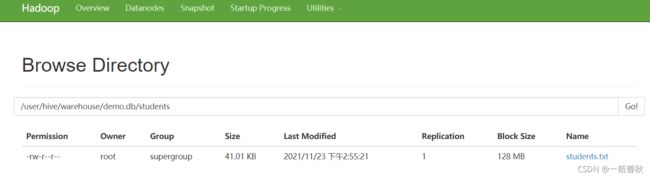
执行删表语句,drop table students;

在返回看hdfs中的students表对应的数据文件位置,会发现报错,不仅students表被删除了,hdfs中存储的数据文件也被删除了
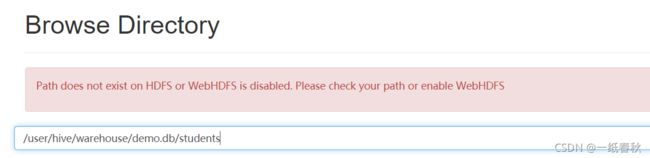
外部表删除表的同时不会删除存储数据
删除之前的students内部表后,创建一张名为students的外部表
外部表的建表语句就比内部表多了一个 external
create external table students(
id bigint comment '学生id',
name string comment '学生姓名',
age int comment '学生年龄',
gender string comment '学生性别',
clazz string comment '学生班级'
) comment '学生信息表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
没有location语句,默认在/user/hive/warehouse/库名 创建新的文件夹students用于存放数据

同样,利用hadoop dfs -put语句将数据文件传送到students表对应的存储位置下。然后执行删表语句

会发现外部表的删表语句只有一个OK提示,而内部表的删除语句会提示将hdfs中的数据文件移入了回收站

刷新,发现students文件还在,没有被删除
利用location改变表的存储位置
在hdfs的根目录下面创建一个新的文件夹 hadoop dfs -mkdir /test
然后是建表语句
create table students(
id bigint comment '学生id',
name string comment '学生姓名',
age int comment '学生年龄',
gender string comment '学生性别',
clazz string comment '学生班级'
) comment '学生信息表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
location '/test';
此时students表的存储位置不再是默认的 /user/hive/warehouse/库名 下面,而是被改为了 /test 文件夹下
现在将students.txt 数据文件传送到 /test 文件夹下面,hadoop dfs -put students.txt /test
文件传送完成后,执行一下查询语句 select * from students;
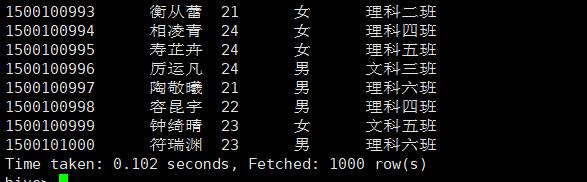
查询成功,说明 students表从指定的存储位置 /test 里面获取到了数据
最后再执行一下删表语句,drop table students;

之前在hdfs的根目录下创建的 test文件被整个删除了
所以操作比较重要的数据时,建议使用外部表,避免不小心删表,连同数据文件一起删除的情况。
truncate 清空表数据的情况
之前都是用drop直接删除表,现在来看一下用truncate清空表数据的情况
内部表
hive> truncate table students;
OK
Time taken: 0.201 seconds

表格存储位置的文件被删除
外部表
hive> truncate table students;
FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table students.
外部表清空表数据会直接报错,不允许清空表数据
加载数据的四种方式
hadoop dfs -put linux本地路径 hdfs路径
前面都用了这第一种方式,就是将数据文件直接从本地传送到 表格在hdfs中的存储位置
这里就不再举例了
特点:
- 需要两个终端,一个终端用来操作hive,一个终端用来向hdfs上传数据文件
- 数据文件经历了从 linux本地 到 hdfs 的跨越
- 文件上传速度较慢
dfs -put linux本地路径 hdfs路径
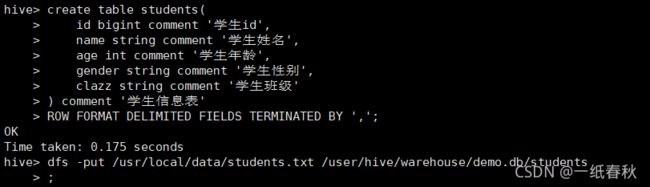
dfs -put /usr/local/data/students.txt /user/hive/warehouse/demo.db/students;

文件同样上传成功,并且可以正常执行 select 语句
特点:
- 只需要一个终端,在hive命令行即可完成全部操作
- 数据文件经历了从 linux本地 到 hdfs 的跨越
- 文件上传速度较快
load data inpath ‘hdfs路径’ into table 表名
这里注意要开始在路径上加引号了
首先在hdfs的根目录下创建一个文件夹 data,用来存放数据文件,然后将linux里面的数据文件先传送到这个文件夹下面
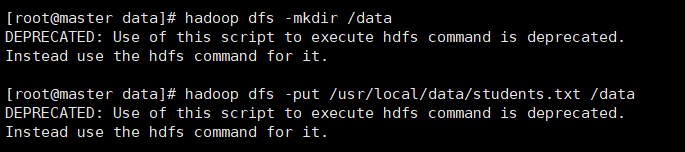
接着执行建表语句,与上面都一样,这里就不再写了
接着执行load语句从hdfs中加载数据
hive> load data inpath '/data/students.txt' into table students;
Loading data to table demo.students
Table demo.students stats: [numFiles=1, totalSize=41998]
OK
Time taken: 0.753 seconds


加载完数据后发现students.txt原先存放的路径 /data 下为空,而相对应的students的存储位置多出了一个students.txt数据文件
特点:
- 只需要一个终端,在hive命令行即可完成全部操作
- 从hdfs中加载数据,数据文件仅在hdfs中进行转移
注意这里, load data inpath 会将数据文件从原来的hdfs路径 剪贴 到自己的存储路径下
load data local inpath ‘linux本地路径’ into table 表名
hive> drop table students;
Moved: 'hdfs://master:9000/user/hive/warehouse/demo.db/students' to trash at: hdfs://master:9000/user/root/.Trash/Current
OK
Time taken: 0.456 seconds
hive> create table students(
> id bigint comment '学生id',
> name string comment '学生姓名',
> age int comment '学生年龄',
> gender string comment '学生性别',
> clazz string comment '学生班级'
> ) comment '学生信息表'
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
OK
Time taken: 0.072 seconds
hive> load data local inpath '/usr/local/data/students.txt' into table students;
Loading data to table demo.students
Table demo.students stats: [numFiles=1, totalSize=41998]
OK
Time taken: 0.199 seconds

特点:
- 只需要一个终端,在hive命令行即可完成全部操作
- 从linux本地加载数据,数据文件经历了从 linux本地 到 hdfs 的跨越