在虚拟机或Docker中搭建大数据伪分布式集群(一):hadoop基础功能——hdfs 与 yarn
在虚拟机或Docker中搭建大数据伪分布式集群(一):hadoop基础功能——hdfs 与 yarn
参考官网教程:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
参考教程:使用Docker搭建Hadoop集群环境 - 简书
目录
环境准备
一、集群搭建
1、VM虚拟机
2、Docker集群搭建
(1)拉去Centos镜像
(2)创建容器
(3)启动控制台并进入docker容器中:
3、安装OpenSSH免密登录
(1)各节点分别安装
(2)生成公钥
(3)公钥分发
二、软件安装与环境配置
1、宿主机向Docker容器传送软件安装包
2、软件环境配置
三、配置hadoop运行所需文件
1、修改core-site.xml
2、修改hdfs-site.xml
3、修改mapred-site.xml
4、修改yarn-site.xml
5、在hadoop-env.sh中设JAVA_HOME
6、修改etc/hadoop/workers 配置 需要启动DataNode的机器名
7、修改Hadoop启动文件
8、hadoop复制分发
四、Hadoop 启动
1、格式化namenode
2、启动集群
主节点 JPS
从节点
3、问题注意
问题一: tput: command not found
问题二:hadoop java.lang.IllegalArgumentException: Does not contain a valid host:port 8020
问题三:在安装配置hadoop的过程中,很可能发生错误导致datanode或者namenode 启动失败,这时我们可以选择重新格式化 namenode。
问题四:时间同步问题
4、验证服务
hadoop
yarn
5、基准测试
环境准备
虚拟机软件下载地址请自行搜索: VMWare 软件(建议使用16.0以上版本,与 docker 不冲突)或 Docker
开发软件清华镜像下载地址:清华大学开源软件镜像站 | Tsinghua Open Source Mirror
centos7、OpenJDK8、hadoop-3.2.2.tar.gz
注意软件版本,以上是我多次踩坑后,得出的最佳版本配方(jdk必须是8以上),不然安装时总一些奇怪的问题解决不了,很让人崩溃的。
建议使用docker的镜像生成,或者使用VMWare的快照功能,每到一个环节就保存一次,这样随时可回退,重新开始。
Docker 或 VMWare 的搭建方式只有前期有所不同,后面的基本一致。
一、集群搭建
1、VM虚拟机
具体可参考:通过VMware搭建分布式集群基础环境_老农小江的博客-CSDN博客
虚拟机克隆后,记得修改机器的相关配置
# 修改虚拟机网卡文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
将BOOTPROTO=dhcp修改为BOOTPROTO=static
将ONBOOT=no 修改为 ONBOOT=yes
添加配置: 网关与子网掩码必须与虚拟网卡中的配置一致,ip必须在设定的范围中
IPADDR=192.168.78.128
NETMASK=255.255.255.0
GATEWAY=192.168.78.2
# 修改完成保存
# 配置hosts
vi /etc/hosts
192.168.78.128 node1
192.168.78.129 node2
192.168.78.130 node3
# 重启网络服务
service network restart
# 关闭并禁用防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
# 修改主机名
vi /etc/hostname
hadoop-master
# 重启
reboot搞定的话,直接看第3步
2、Docker集群搭建
(1)拉去Centos镜像
docker pull centos:latest
使用docker images 查看下载的镜像

(2)创建容器
按照集群的架构,创建容器时需要设置固定IP,所以先要在docker使用如下命令创建固定IP的子网
network create --subnet=172.19.0.0/16 hadoop-groupdocker的子网创建完成之后就可以创建固定IP的容器了
当然,对docker比较熟悉的同学,可以先建立基础容器,安装配置后,再生成镜像,最后使用新镜像来搭建集群
嫌麻烦的,可直接拉取相关镜像:hermesfuxi/centos-hadoop-base
Docker Hub 地址:Docker Hub
# node1
# -p 设置docker映射到容器的端口 后续查看web管理页面使用
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name hadoop-master -h hadoop-master -p 18088:18088 -p 9870:9870 -p 16010:16010 --net hadoop-group --ip 172.19.0.2 centos /usr/sbin/init
# node2 备用主节点,端口号: master映射端口 + 1
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name hadoop-master -h hadoop-master -p 18081:18088 -p 9871:9870 -p 16011:16010 --net hadoop-group --ip 172.19.0.3 centos /usr/sbin/init
# node3 端口号: master映射端口 + 1
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name hadoop-slave1 -h hadoop-slave1 --net hadoop-group --ip 172.19.0.4 centos /usr/sbin/init
(3)启动控制台并进入docker容器中:
docker exec -it hadoop-master /bin/bash3、安装OpenSSH免密登录
(1)各节点分别安装
#安装openssh
[root@hadoop-slave1 /]#yum -y install openssh openssh-server openssh-clients
[root@hadoop-slave1 /]# systemctl start sshd
(2)生成公钥
分别在各机器上执行
ssh-keygen -t rsa
#一路回车
# 将公钥导入到认证文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 查看 authorized_keys 文件内容
cat ~/.ssh/authorized_keys
chmod 0700 /root -R
(3)公钥分发
文件生成之后用scp将公钥文件分发到集群slave主机
[root@node2 /]# ssh-copy-id -i ~/.ssh/id_rsa.pub node1
[root@node3 /]# ssh-copy-id -i ~/.ssh/id_rsa.pub node1
[root@node1 /]# scp ~/.ssh/authorized_keys root@node2:~/.ssh
[root@node1 /]# scp ~/.ssh/authorized_keys root@node3:~/.ssh
分发完成之后测试(ssh node2 等)是否已经可以免输入密码登录
二、软件安装与环境配置
1、宿主机向Docker容器传送软件安装包
格式:
docker cp 本地文件的路径 container_id:
比如:
docker cp /Volues/Linux/jdk1.8.0_231.tar.gz node1r:/opt/
docker cp /Volumes/Linux/hadoop-3.2.2.tar.gz node1:/opt/
2、软件环境配置
解压OpenJDK8U-jdk_x64_linux_hotspot_8u275b01.tar.gz、hadoop-3.2.2.tar.gz至/opt 目录下,并创建链接文件
tar -xzvf OpenJDK8U-jdk_x64_linux_hotspot_8u275b01.tar.gz
mv jdk8u275-b01 jdk8
tar -xzvf hadoop-3.2.2.tar.gz
mv hadoop-3.2.2 hadoop
配置java和hadoop环境变量:编辑 /etc/profile文件
# hadoop
export HADOOP_HOME=/opt/hadoop/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#java
export JAVA_HOME=/opt/jdk8/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=.:$JAVA_HOME/bin:$PATH
使文件生效:
source /etc/profile
三、配置hadoop运行所需文件
cd $HADOOP_HOME/etc/hadoop/
1、修改core-site.xml
hadoop.tmp.dir
/opt/hadoop/tmp
A base for other temporary directories.
fs.default.name
hdfs://node1:8020
fs.trash.interval
4320
fs.trash.checkpoint.interval
4320
2、修改hdfs-site.xml
dfs.namenode.name.dir
/opt/hadoop/name
dfs.datanode.data.dir
/opt/hadoop/data
dfs.replication
3
dfs.webhdfs.enabled
true
dfs.permissions.superusergroup
supergroup
dfs.permissions.enabled
false
3、修改mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=$HADOOP_HOME
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
4、修改yarn-site.xml
yarn.resourcemanager.hostname
node1
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
spark.shuffle.service.port
7338
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
yarn.resourcemanager.address
node1:18040
yarn.resourcemanager.scheduler.address
node1:18030
yarn.resourcemanager.resource-tracker.address
node1:18025
yarn.resourcemanager.admin.address
node1:18141
yarn.resourcemanager.webapp.address
node1:18088
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
86400
yarn.log-aggregation.retain-check-interval-seconds
86400
yarn.nodemanager.remote-app-log-dir
/yarn/remotelogs
yarn.nodemanager.remote-app-log-dir-suffix
logs
5、在hadoop-env.sh中设JAVA_HOME
// 应当使用绝对路径。
export JAVA_HOME=$JAVA_HOME //错误,不能这么改
export JAVA_HOME=/opt/jdk8 //正确,应该这么改6、修改etc/hadoop/workers 配置 需要启动DataNode的机器名
vim $HADOOP_HOME/etc/hadoop/workers
# 添加DataNode
node1
node2
node37、修改Hadoop启动文件
在Hadoop安装目录下找到sbin文件夹
cd $HADOOP_HOME/sbin在里面修改文件
对于start-dfs.sh、stop-dfs.sh、start-all.sh、stop-all.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root8、hadoop复制分发
scp -r /opt/hadoop node2:/opt/
scp -r /opt/hadoop node3:/opt/
scp -r /opt/jdk8 node2:/opt/
scp -r /opt/jdk8 node3:/opt/
scp /etc/profile node2:/opt/
scp /etc/profile node3:/etc/
# 注意还需要激活各机器的环境变量 /etc/profile
ssh node2 source /etc/profile
ssh node3 source /etc/profile四、Hadoop 启动
1、格式化namenode
hadoop namenode -format
如果看到storage format success等字样,即可格式化成功
2、启动集群
cd $HADOOP_HOME/sbin
./start-all.sh
# 只起hdfs
./start-dfs.sh
# hdfs 启动后,还可以启动 yarn
./start-yarn.sh启动后可使用jps命令查看是否启动成功
主节点 JPS

从节点


3、问题注意
问题一: tput: command not found
yum install ncurses问题二:hadoop java.lang.IllegalArgumentException: Does not contain a valid host:port 8020
大概率:主机的hostname不合法,修改为不包含着‘.’ '/' '_'等非法字符。
问题三:在安装配置hadoop的过程中,很可能发生错误导致datanode或者namenode 启动失败,这时我们可以选择重新格式化 namenode。
1.停止正在运行的集群部分(停止集群集成脚本)
$HADOOP_HOME/sbin/stop-all.sh
2.删除/opt/hadoop/ 下的data、tmp、jobhistory文件夹,并清空logs里的日志(参数是自己配置在core-site.xml、hdfs-site.xml中的文件路径 )
cd $HADOOP_HOME
rm -rf name data tmp jobhistory logs/*3.重新格式化
hadoop namenode -format4.启动集群
$HADOOP_HOME/sbin/start-all.sh问题四:时间同步问题
Centos 7 直接使用
# 若无ntpdate,请先安装
ntpdate time.nist.govCentOS 8中已经无法安装ntpdate,而是使用了chrony模块,安装后修改配置与时区设置即可完成时间同步。具体可见:Centos使用chrony做时间同步 - 驴得水 - 博客园
# yum 下载过慢的话,可更换阿里源
# 下载阿里云源文件
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo
# 替换 阿里云镜像地址
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
# 建立缓存
yum makecache
# 安装chrony
yum install -y chrony
# 修改配置文件
vim /etc/chrony.conf
# 添加如下配置
server 210.72.145.44 iburst
server ntp.aliyun.com iburst
allow 192.168.0.0/16
local stratum 10
# 启动chrony服务
systemctl start chronyd.service
# 设置开机同步时间
systemctl enable chronyd.service
# 查看服务状态
systemctl status chronyd.service
# 更改时区为上海
timedatectl set-timezone Asia/Shanghai
# 开始时间同步
chronyc sources -v
# 查看
date4、验证服务
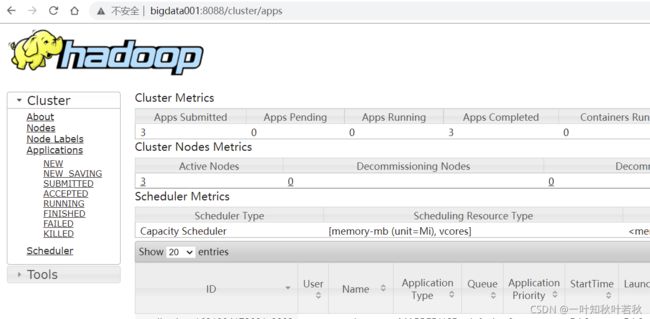
访问组件 webUI 地址(主机没有配置host映射的,请用虚拟机 ip 访问,端口号不变,docker用localhost,端口用映射后的)来查看服务是否启动
hadoop
http://node1:9870/

查看相关的dataNode

yarn
http://node1:8088/cluster/apps
5、基准测试
参考:
hadoop基准性能测试_dgqg1223-CSDN博客
或使用hibench:https://github.com/Intel-bigdata/HiBench