我的Hadoop之旅---启程
Hadoop集群式搭建的旅途
在这里,我将进行我的Hadoop搭建路程
搭建前期的准备工作
我们要进行Hadoop伪分布式搭建需要做的一些小小的准备工作:
- 下载VMware任意版本,并创建三台虚拟机,我这里选择的是使用带GUI的服务器(仅仅勾了这一个选项,其他的附加服务并没有勾选),你可以根据自己的需求进行建立;
- 下载相应的CentOs7的版本,或者相应你需要使用的版本;
- 从Oracle的JDK里面下载你需要用的JDK版本,在这里我下载的是jdk-8u281-linux-x64.tar;
- 去国内镜像网址下载对应的Hadoop安装包,在这里我下载的是hadoop-2.10.1.tar,这个是对应的下载地址http://debian.ustc.edu.cn/apache,尽力下载稳定版的;
- 下载一个远程访问软件,我这里使用的是FinalShell,需要的同学可以去http://www.hostbuf.com/?install_fs这个地方下载,安装和使用教程也在里面
安装虚拟机,并进行网络设置
- 正常安装3台虚拟机,或者安装1台虚拟机,在将文件配置好以后,复制另外两台,并修改相关操作
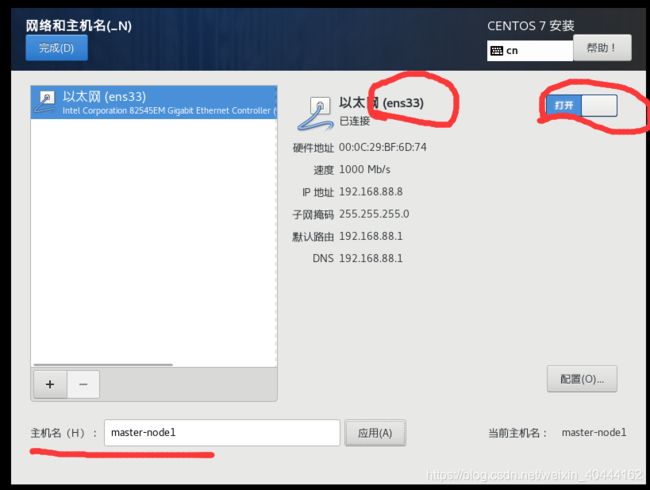
- 在安装过程中,在网络和主机名这个地方,有如图几个注意点:
在这里地方,可以将主机名改掉,改成你需要的那个,然后将以太网打开,记好以太网后面那个名字,我这里就是ens33,在后面配置静态IP的时候会用到的
- 后面按照正常的Linux安装步骤继续进行就可以了。
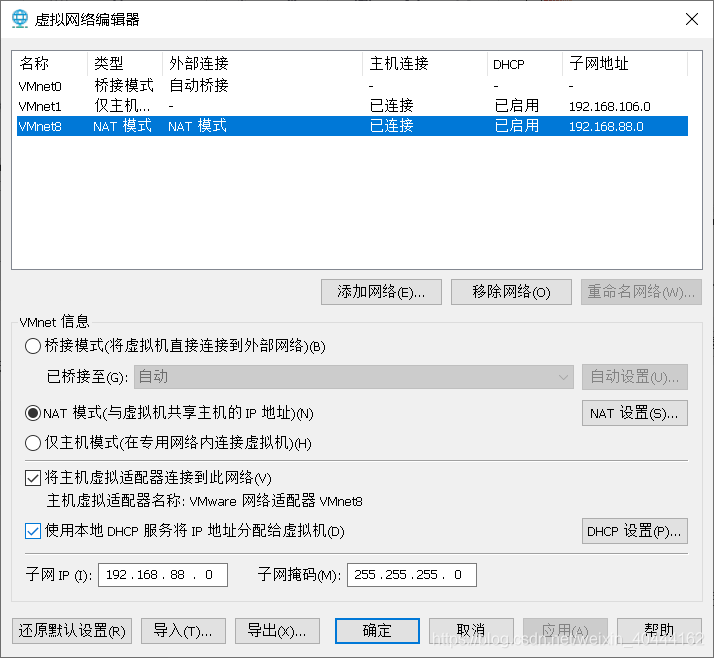
- 在VMware的工具栏中的编辑上选择虚拟网络编辑器,选择其中的VMnet8,然后点击下方的更改设置(如图),

- 进入更改设置后,此页面的VMnet如图设置,其中子网ip的第三位(192.168.***.0),可以按照你的电脑实际情况或者你的喜欢设置,子网掩码要如图设置
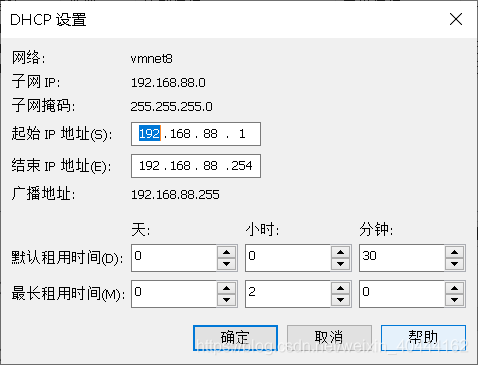
- 设置完成后,点击上图的那个DHCP设置,进入如图设置,这里地方上一步你设置的第三位是啥,你就写什么就好。设置好后,点击NAT设置,将里面的默认网关更改一下,前三位与你之前填的相同。最后一位填一位数,并记住。
- 这些都设置好后,你需要去改一下电脑的网络适配器,点击电脑的设置(win10),选择网络和Internet,在状态中找到更改适配器选项,点进去,找到VMware Network Adapter VMnet8(如图),右键点击一下,然后选择属性,在属性中找到Internet协议版本4(TCP/IPv4),进行如图所示的设置。

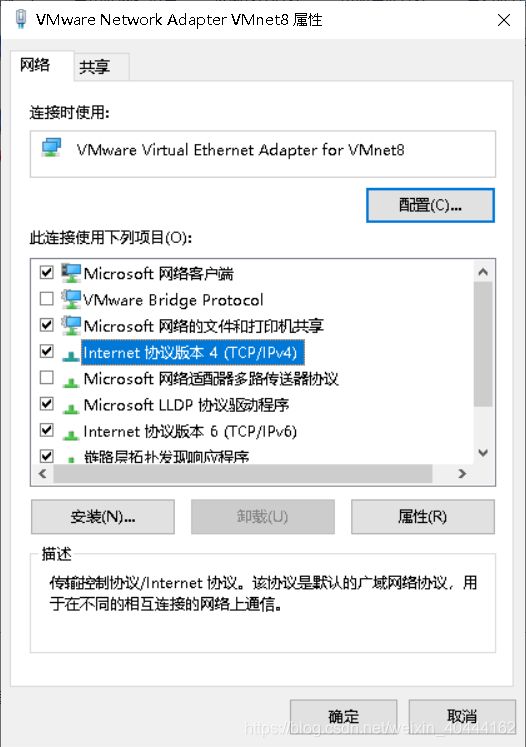

这个时候IP地址前三位要和前面相同,第四位你可以随便填(1-254),这个是指你以后启用这个ip时,默认给你分配的地址。这里的默认网关请和前面的保持一直。
进行第一台虚拟机的设置
使用带GUI界面的服务器创建的虚拟机时,会在你进入的时候让你创建用户,请切换到root用户,我们接下来的操作都是基于root用户进行的。
- 修改主机名:分别设置3台主机的名字(master,slave1,slave2):
vi /etc/hostname
进入编辑状态后按"O"直接修改主机名,完成后,按"ESC",然后按住Shift 按两次Z保存退出
- 修改IP地址(分别在3台虚拟机修改为:192.168.88.200,192.168.88.201,192.168.88.202):
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#这个地方就需要用到我说的需要记录的那个网关英文名,比如我的是ens33,所以我打开的文件就是ifcfg-ens33
增加(或修改)以下内容:
BOOTPROTO=static #设置为静态IP
ONBOOT=yes #打开网卡
IPADDR=192.168.88.200 #设置IP,对应上面给出的三个IP地址,这里是master的IP
NETMASK=255.255.255.0 #设置子网掩码
GATEWAY=192.138.88.0 #设置网关
- 配置Hosts文件,通过下列命令打开hosts文件,修改hosts配置,3台机器都需要
vi /etc/hosts
加入下列代码:
192.168.88.200 master
192.168.88.201 slave1
192.168.88.202 slave2
在完成以上步骤后reboot重启3台虚拟机:reboot
- .每台机器可以生成自己的一对公司钥,私钥自己保存。将本机作为服务器,要通过无密钥SSH访问本机的机器作为客户端,首先将服务器的公钥放到客户端,客户端将此公钥放到authorized_keys中,可以将authorized_keys认为是公钥的字典文件,因为可以放多个服务器的公钥进去,即可实现无密钥SSH访问。
Hadoop运行过程中,需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到NameNode。
在各节点上生成各自SSH秘钥对(这里秘钥类型为rsa,也可以设置为安全性更高的dsa),以master为例。
创建秘钥文件使用下列命令
ssh-keygen -t rsa
截图说明如下:
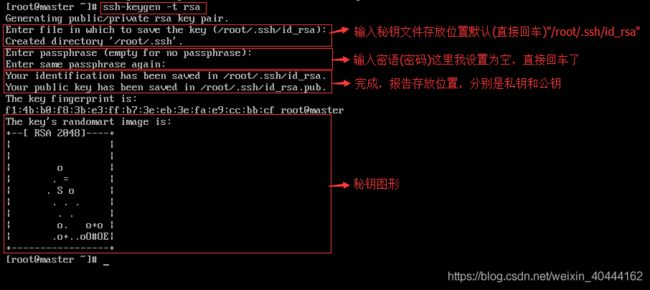
在本机上生成authorized_keys,并验证能否对本机进行SSH无密码登陆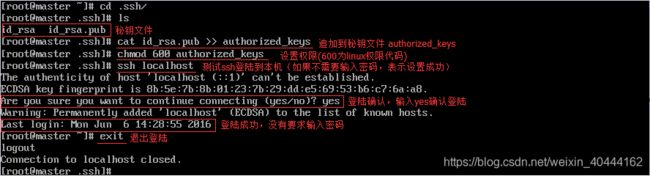
在其余所有节点都生成自己的authorized_keys之后,通过ssh-copy-id命令拷贝各自的公钥到其他节点,公钥会加入到对方机器的authorized_keys文件中,可以将authorized_keys认为是公钥的字典文件,因为可以放多个服务器的公钥进去,即可实现无密钥SSH访问。下面以slave1节点为例,将master节点的公钥复制到slave1节点中并加入到授权的key中,并验证是否配置成功。
在slave1中生成秘钥文件

将master节点的公钥复制到slave1节点中并测试连接。(如果你是只搭建了一台,然后克隆的其他两台,这个时候,你最好重新生成一下这个文件,然后重命名。此时好像就省略了由master向slave传输的过程)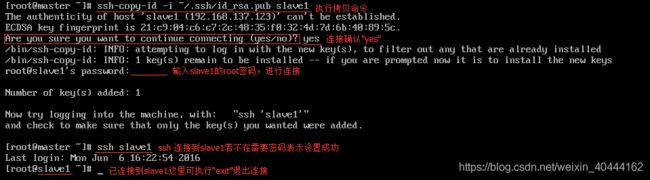
在slave中使用 more 查看完成公钥复制后的文件

在这些都完成后,同时要用slave1向slave2传输一次公匙,再由slave2向slave1传输一次
自此便可以实现master登入slave1,slave2和slave1和slave2互相登入了
安装JDK
- 卸载原有JDK
我是按照下面这个链接的步骤进行操作了,可以仿照操作一下,然后进行卸载。
链接:https://blog.csdn.net/li_xiao_ning/article/details/84227090 - 上传新版本的JDK(或者你需要的版本)
利用FinalShell登入你创建好的虚拟机(一定要有固定的IP地址,最好是静态的),连接步骤如下:
1、安装好软件,然后点击
然后点击工具栏第一个,点击SSH连接(Linux),
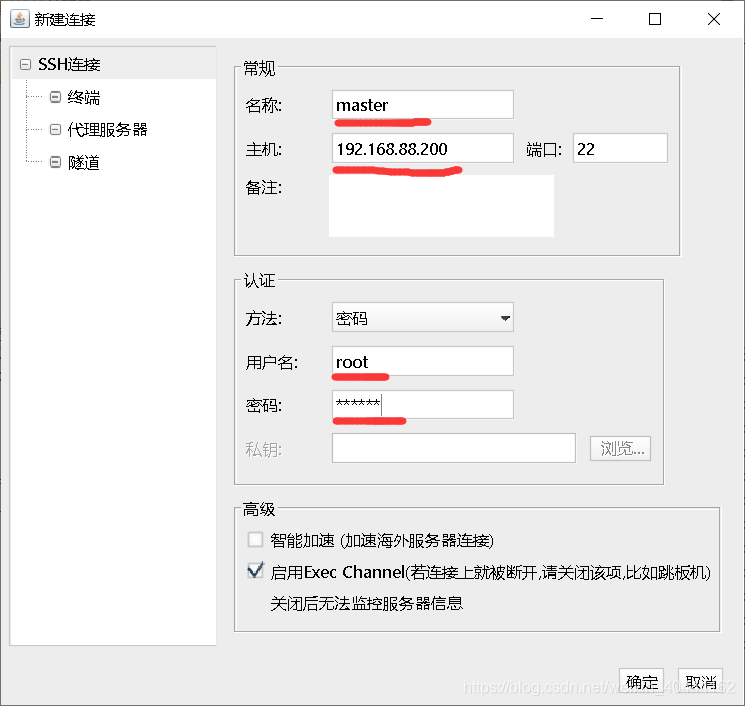
名称这里有你设置的虚拟机名称,主机填写你的虚拟机的IP地址,用户名选择root,密码填你的root的密码
2、设置好后点击登入,在你模拟机开启的情况下,是可以正常连接的。如果报错,显示连接不上,可能的原因是你虚拟机IP地址改变了,或者是你的VM的5大项服务没有开启,你可以去任务管理器里面开启VM对应的五项服务。
3、连接好后,会显示登入成功。在此之后,在下面的文件夹选项中找到opt,点击然后选择新建文件夹software,以后你需要的上传的软件安装包可以都放在这个地方。将开头要准备的JDK和HADOOP压缩文件上传,直接拖动到下方的文件夹中就可以上传了。 - 解压安装
使用如下命令进行解压
#先进行文件夹跳转
cd /opt/software
#然后解压文件夹
tar -zvxf jdk-8u91-lunux-x64.tar.gz -C /opt/apps
#如果你没有apps可以新建一个,以后可以把所有要安装的软件都放在这里
#通过mv命令或者FinalShell直接点击文件夹进行重命名
mv jdk1.8.2_81 jdk
- 配置jdk环境(当然这里也可以使用FinalShell在windows 中修改。)
vim /etc/profile
在尾部加入
#set java environment
export JAVA_HOME=/opt/apps/jdk
export JRE_HOME=/opt/apps/jdk/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
保存退出后,执行下列命令 让更改及时生效
source /etc/profile
然后,执行下列命令验证安装成功
java -version

如果显示的如安装版本相同,则证明安装成功。如果不成功,请查看是否未卸载原先装的JDK
安装Hadoop,并且配置环境
- 解压安装
使用如下命令进行解压
#先进行文件夹跳转
cd /opt/software
#然后解压文件夹
tar -zvxf hadoop-2.10.1.tar.gz -C /opt/apps
#如果你没有apps可以新建一个,以后可以把所有要安装的软件都放在这里
#通过mv命令或者FinalShell直接点击文件夹进行重命名
mv hadoop-2.10.1 hadoop
- 配置hadoop环境(当然这里也可以使用FinalShell在windows 中修改。)
vim /etc/profile
在尾部加入
#set hadoop path
export HADOOP_HOME=/opt/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
保存退出后,执行下列命令 让更改及时生效
source /etc/profile
然后,执行下列命令验证安装成功
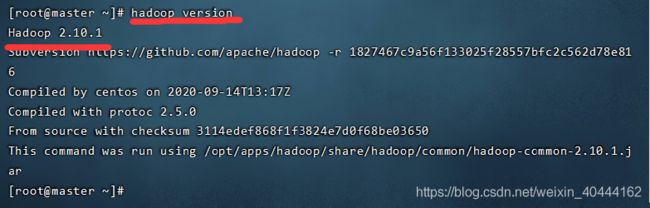
hadoop version
安装无误则会显示版本信息
- 配置 ~/hadoop/etc/hadoop下的hadoop-env.sh、yarn-env.sh、mapred-env.sh(当然这里也可以使用FinalShell在windows 中修改。)
使用命令如下:
#打开hadoop-env.sh文件,用FinalShell可以直接找到打开
vi /opt/apps/hadoop/etc/hadoop/hadoop-env.sh
#进行如下修改,先找到对应文字,如果export那行有#号,将#去除即可,然后jdk位置改为你的位置
# The java implementation to use.
export JAVA_HOME=/opt/apps/jdk
#打开yarn-env.sh文件,用FinalShell可以直接找到打开
vi /opt/apps/hadoop/etc/hadoop/yarn-env.sh
#进行如下修改,先找到对应文字,如果export那行有#号,将#去除即可,然后jdk位置改为你的位置
# some Java parameters
export JAVA_HOME=/opt/apps/jdk/
#打开mapred-env.sh文件,用FinalShell可以直接找到打开
vi /opt/apps/hadoop/etc/hadoop/mapred-env.sh
#进行如下修改,先找到对应文字,如果export那行有#号,将#去除即可,然后jdk位置改为你的位置
# limitations under the License.
export JAVA_HOME=/opt/apps/jdk/
- 配置系统目录:Hadoop程序存放目录为/opt/apps/hadoop/,可以将程序和数据目录分开,可以更加方便的进行配置的同步,具体目录的配置如下所示:
l 在每个节点上创建程序存储目录/opt/apps/hadoop/,用来存放Hadoop程序文件。
l 在每个节点上创建数据存储目录/opt/apps/hadoop/hdfs,用来存放集群数据。
l 在主节点node上创建目录/opt/apps/hadoop/hdfs/name,用来存放文件系统元数据。
l 在每个从节点上创建目录/opt/apps/hadoop/hdfs/data,用来存放真正的数据。
l 所有节点上的日志目录为/opt/apps/hadoop/logs。
l 所有节点上的临时目录为/opt/apps/hadoop/tmp。
执行命令mkdir -p //opt/apps/hadoop/logs,为还没有的目录创建,后面以此类推
修改Hadoop配置文件
Hadoop配置文件在hadoop/etc/hadoop目录下,配置文件也被分成了4个主要的配置文件需要配置其中包含:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
此处,我是照抄网上的修改,如果需要特别的设置,请自行查找其他的设置,进行对应的修改
1、core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:8020value>
<description> 设定 namenode 的 主机名 及 端口 description>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
<description> 设置缓存大小 description>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/opt/apps/hadoop/tmpvalue>
<description> 存放临时文件的目录 description>
property>
configuration>
2、hdfs-site.xml
这个地方记得改为你的目录文件
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/opt/apps/hadoop/hdfs/namevalue>
<description> namenode 用来持续存放命名空间和交换日志的本地文件系统路径 description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/opt/apps/hadoop/hdfs/datavalue>
<description> DataNode 在本地存放块文件的目录列表,用逗号分隔 description>
property>
<property>
<name>dfs.replicationname>
<value>3value>
<description> 设定 HDFS 存储文件的副本个数,默认为3 description>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
3、mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<final>truefinal>
property>
<property>
<name>mapreduce.jobtracker.http.addressname>
<value>master:50030value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
<property>
<name>mapred.job.trackername>
<value>http://master:9001value>
property>
configuration>
4、yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>
设置Hadoop集群
master上配置好的hadoop所在文件夹"/opt/apps/hadoop"复制到所有的Slave的"/opt/apps"目录下,而不必每台机器都要安装设置,用下面命令格式进行。
例如:从"master"到"slave1"复制配置Hadoop的文件:
#先cd回主界面在进行
cd
scp –r /opt/apps/hadoop root@slave1:/opt/apps/
复制完成后在master上配置节点信息(其余节点不需要),使用下列命令
vi /opt/apps/hadoop/etc/hadoop/slaves
#去掉"localhost",每行只添加一个主机名或者IP地址
slave1
slave2
***注:***如果此处你只是设置了一台机器,打算将另外两台机器进行克隆的话,请在修改‘slaves’文件前进行克隆
克隆后,进行如下操作:
1、修改主机名
2、修改IP地址
3、重新设置公匙,并验证登入
4、在克隆结束后,便可以按照上述步骤在master中进行‘slaves’的修改
格式化HDFS文件系统
输入命令:
#先移动
cd /opt/apps/hadoop
#再运行程序
hadoop namenode -format
如果不出错大致会显示如下信息:
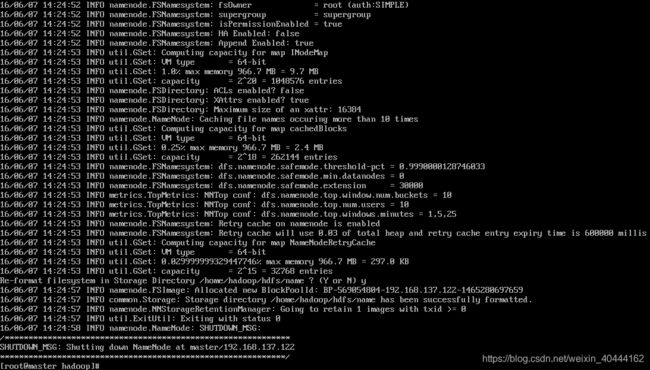
次数如产生错误,基本都是配置文件的问题,诸如不识别中文,配置文件中指定的路径不存在,等等,请认真检查配置文件
启动Hadoop
cd /opt/apps/hadoop
sbin/start-all.sh
如无异常显示如下内容:
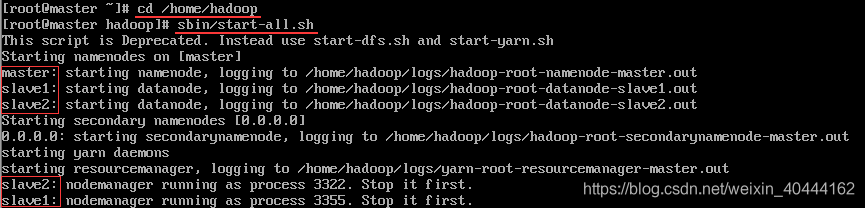
命令“sbin/stop-all.sh”停止hadoop服务
服务验证
- java自带的小工具jps查看进程
在master应该输出以下信息(端口号仅供参考)
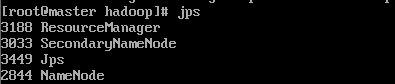
在slave应该输出以下信息(端口号仅供参考)

由于我并没有报错和启动错误,就不列举,如果出错,请自行百度查找解决方法
- 通过网页查看
请先关闭防火墙
systemctl stop firewalld
输入以下网页, http://192.168.88.200:50070/dfshealth.html#tab-overview 进入hadoop管理首页
如果需要彻底关闭防护墙,请使用如下代码
#查看防火墙状态
systemctl status firewalld
#彻底关闭防火墙
systemctl disable firewalld
#在彻底关闭防火墙后,还需要关闭selinux,使用如下命令进行修改
vi /etc/sysconfig/selinux
#找到对应代码,进行如下修改:
SELINUX=disabled
#之后重启机器就好