Centos7上Hadoop 3.3.1的高可用HA安装过程
目录
- 1. 集群规划
- 2. 下载(在bigdata001操作)
- 3. 配置文件修改(在bigdata001操作)
-
- 3.1 hadoop-env.sh
- 3.2 core-site.xml
- 3.3 hdfs-site.xml
- 3.4 mapred-site.xml
- 3.5 yarn-site.xml
- 3.6 修改workers文件
- 4. hadoop目录分发(在bigdata001操作)
- 5. 初始化和启动(在bigdata001操作)
-
- 5.1 添加环境变量
- 5.2 HDFS
- 5.3 YARN
1. 集群规划
- 每台服务器相互设置ssh无密码登录,注意authorized_keys权限为600
| 服务名 | 安装服务器 | 服务作用 | 安装教程 | 备注 |
|---|---|---|---|---|
| java8 | bigdata001/2/3 | |||
| zookeeper | bigdata001/2/3 | 基于Centos7分布式安装Zookeeper3.6.3 | ||
| NameNode | bigdata001/2/3 | |||
| DataNode | bigdata001/2/3 | |||
| JournalNodes | bigdata001/2/3 | active Namenode写入edit logs到JournalNodes,standby NameNode从JournalNodes读取edit logs | ||
| ZKFC | bigdata001/2/3 | NameNode和zookeeper通信的客户端 | ||
| ResourceManager | bigdata001/2/3 | 不用JournalNodes,直接用zookeeper进行state-store;不用ZKFC,内置了zookeeper的客户端 | ||
| NodeManager | bigdata001/2/3 |
2. 下载(在bigdata001操作)
执行下面的命令进行下载和解压
curl -O https://ftp.nluug.nl/internet/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar -zxvf hadoop-3.3.1.tar.gz
进入hadoop目录
[root@bigdata001 opt]#
[root@bigdata001 opt]# cd hadoop-3.3.1
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# pwd
/opt/hadoop-3.3.1
[root@bigdata001 hadoop-3.3.1]#
3. 配置文件修改(在bigdata001操作)
3.1 hadoop-env.sh
创建pids和logs文件
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# mkdir pids
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# mkdir logs
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# ls
bin etc include lib libexec LICENSE-binary licenses-binary LICENSE.txt logs NOTICE-binary NOTICE.txt pids README.txt sbin share
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# pwd
/opt/hadoop-3.3.1
[root@bigdata001 hadoop-3.3.1]#
修改etc/hadoop/hadoop-env.sh文件
修改部分:
export JAVA_HOME=/opt/jdk1.8.0_201
export HADOOP_PID_DIR=/opt/hadoop-3.3.1/pids
export HADOOP_LOG_DIR=/opt/hadoop-3.3.1/logs
export HDFS_NAMENODE_USER=root
添加部分
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
3.2 core-site.xml
修改etc/hadoop/core-site.xml
添加部分:
fs.defaultFS
hdfs://nnha
io.file.buffer.size
131072
ha.zookeeper.quorum
bigdata001:2181,bigdata002:2181,bigdata003:2181
3.3 hdfs-site.xml
修改etc/hadoop/hdfs-site.xml
添加namenode和datanode文件夹
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# mkdir namenode
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# mkdir datanode
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# mkdir journalnode
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# pwd
/opt/hadoop-3.3.1
[root@bigdata001 hadoop-3.3.1]#
添加部分:
dfs.replication
1
dfs.namenode.name.dir
/opt/hadoop-3.3.1/namenode
dfs.blocksize
268435456
dfs.namenode.handler.count
100
dfs.datanode.data.dir
/opt/hadoop-3.3.1/datanode
dfs.ha.automatic-failover.enabled
true
dfs.nameservices
nnha
dfs.ha.namenodes.nnha
nn1,nn2,nn3
dfs.namenode.rpc-address.nnha.nn1
bigdata001:8020
dfs.namenode.rpc-address.nnha.nn2
bigdata002:8020
dfs.namenode.rpc-address.nnha.nn3
bigdata003:8020
dfs.namenode.http-address.nnha.nn1
bigdata001:9870
dfs.namenode.http-address.nnha.nn2
bigdata002:9870
dfs.namenode.http-address.nnha.nn3
bigdata003:9870
dfs.namenode.shared.edits.dir
qjournal://bigdata001:8485;bigdata002:8485;bigdata003:8485/nnha
dfs.client.failover.proxy.provider.nnha
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/opt/hadoop-3.3.1/journalnode
dfs.ha.nn.not-become-active-in-safemode
false
3.4 mapred-site.xml
修改etc/hadoop/mapred-site.xml
添加部分:
mapreduce.framework.name
yarn
3.5 yarn-site.xml
修改etc/hadoop/yarn-site.xml
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# pwd
/opt/hadoop-3.3.1
[root@bigdata001 hadoop-3.3.1]#
[root@bigdata001 hadoop-3.3.1]# mkdir nm-local-dir
[root@bigdata001 hadoop-3.3.1]# mkdir nm-log-dir
[root@bigdata001 hadoop-3.3.1]# mkdir nm-remote-app-log-dir
[root@bigdata001 hadoop-3.3.1]#
添加部分:
yarn.acl.enable
false
yarn.log-aggregation-enable
false
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.resourcemanager.hostname
bigdata001
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
yarn.scheduler.minimum-allocation-mb
1024
yarn.scheduler.maximum-allocation-mb
8192
yarn.resourcemanager.nodes.include-path
yarn.nodemanager.resource.memory-mb
8192
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.local-dirs
/opt/hadoop-3.3.1/nm-local-dir
yarn.nodemanager.log-dirs
/opt/hadoop-3.3.1/nm-log-dir
yarn.nodemanager.log.retain-seconds
10800
yarn.nodemanager.remote-app-log-dir
/opt/hadoop-3.3.1/nm-remote-app-log-dir
yarn.nodemanager.remote-app-log-dir-suffix
logs
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
rmha
yarn.resourcemanager.ha.rm-ids
rm1,rm2,rm3
yarn.resourcemanager.hostname.rm1
bigdata001
yarn.resourcemanager.hostname.rm2
bigdata002
yarn.resourcemanager.hostname.rm3
bigdata003
yarn.resourcemanager.webapp.address.rm1
bigdata001:8088
yarn.resourcemanager.webapp.address.rm2
bigdata002:8088
yarn.resourcemanager.webapp.address.rm3
bigdata003:8088
hadoop.zk.address
bigdata001:2181,bigdata002:2181,bigdata003:2181
3.6 修改workers文件
bigdata001
bigdata002
bigdata003
4. hadoop目录分发(在bigdata001操作)
将bigdata001上配置的hadoop目录分发到其余两台服务器
[root@bigdata001 opt]# scp -r /opt/hadoop-3.3.1 root@bigdata002:/opt
[root@bigdata001 opt]# scp -r /opt/hadoop-3.3.1 root@bigdata003:/opt
5. 初始化和启动(在bigdata001操作)
5.1 添加环境变量
- /etc/profile添加内容如下:
export HADOOP_HOME=/opt/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 使环境变量生效
[root@bigdata001 ~]#
[root@bigdata001 ~]# source /etc/profile
[root@bigdata001 ~]#
5.2 HDFS
注意:初始化后,只需在bigdata001上执行
start-dfs.sh和stop-dfs.sh
- 启动journalnode(在bigdata002/3也要执行)
[root@bigdata001 opt]#
[root@bigdata001 opt]# /opt/hadoop-3.3.1/bin/hdfs --daemon start journalnode
[root@bigdata001 opt]#
- hdfs初始化
[root@bigdata001 opt]#
[root@bigdata001 opt]# hdfs namenode -format
[root@bigdata001 opt]#
- 启动bigdata001上的NameNode
[root@bigdata001 opt]#
[root@bigdata001 opt]# hdfs --daemon start namenode
[root@bigdata001 opt]#
- 启动bigdata002和bigdata003上的NameNode, 并同步active NameNode的数据(只在bigdata002和bigdata003上执行)
[root@bigdata002 opt]#
[root@bigdata002 opt]# /opt/hadoop-3.3.1/bin/hdfs namenode -bootstrapStandby
[root@bigdata002 opt]#
- 初始化zookeeper中NameNode的数据
[root@bigdata001 opt]#
[root@bigdata001 opt]# hdfs zkfc -formatZK
[root@bigdata001 opt]#
- stop hdfs相关的服务
[root@bigdata001 opt]#
[root@bigdata001 opt]# stop-dfs.sh
Stopping namenodes on [bigdata001 bigdata002 bigdata003]
上一次登录:三 8月 11 16:15:59 CST 2021pts/0 上
Stopping datanodes
上一次登录:三 8月 11 16:41:30 CST 2021pts/0 上
Stopping journal nodes [bigdata002 bigdata003 bigdata001]
上一次登录:三 8月 11 16:41:32 CST 2021pts/0 上
Stopping ZK Failover Controllers on NN hosts [bigdata001 bigdata002 bigdata003]
上一次登录:三 8月 11 16:41:34 CST 2021pts/0 上
[root@bigdata001 opt]#
- 启动hdfs
[root@bigdata001 opt]#
[root@bigdata001 opt]# start-dfs.sh
Starting namenodes on [bigdata001 bigdata002 bigdata003]
上一次登录:三 8月 11 16:41:37 CST 2021pts/0 上
Starting datanodes
上一次登录:三 8月 11 16:42:17 CST 2021pts/0 上
Starting journal nodes [bigdata002 bigdata003 bigdata001]
上一次登录:三 8月 11 16:42:20 CST 2021pts/0 上
Starting ZK Failover Controllers on NN hosts [bigdata001 bigdata002 bigdata003]
上一次登录:三 8月 11 16:42:24 CST 2021pts/0 上
[root@bigdata001 opt]#
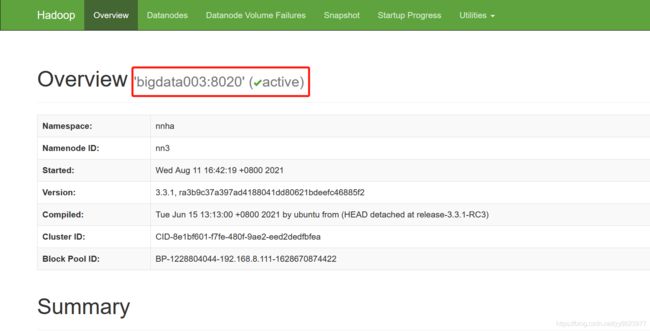
- 通过http://bigdata001:9870、http://bigdata002:9870、http://bigdata003:9870进行访问,只有bigdata003上的NameNode是active状态
5.3 YARN
- 启动yarn
[root@bigdata001 opt]#
[root@bigdata001 opt]# start-yarn.sh
Starting resourcemanagers on [ bigdata001 bigdata002 bigdata003]
上一次登录:三 8月 11 16:42:28 CST 2021pts/0 上
Starting nodemanagers
上一次登录:三 8月 11 17:11:25 CST 2021pts/0 上
[root@bigdata001 opt]#
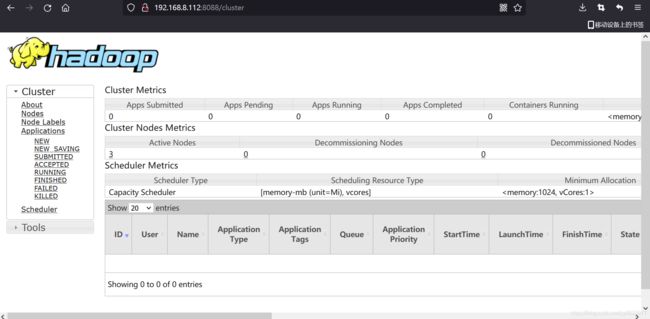
- 通过http://bigdata002:8088/进行访问(只能访问active节点)
- 停止yarn
[root@bigdata001 opt]#
[root@bigdata001 opt]# stop-yarn.sh
Stopping nodemanagers
上一次登录:三 8月 11 17:21:20 CST 2021pts/0 上
Stopping resourcemanagers on [ bigdata001 bigdata002 bigdata003]
上一次登录:三 8月 11 17:25:08 CST 2021pts/0 上
[root@bigdata001 opt]#