清华大学唐杰教授:认知图谱是人工智能的下一个瑰宝(附PPT下载)

来源:学术头条
本文约6300字,建议阅读10分钟
如何以计算机的方式做认知?
公众号(DatapiTHU)后台回复“20201224”获取完整PPT下载
AI 的下一次机遇在哪里?
自 1956 年 AI 的概念首次被提出,至今已有 60 多年的发展史。如今,随着相关理论和技术的不断革新,AI 在数据、算力和算法“三要素”的支撑下越来越多地走进我们的日常生活。
但是,这一系列惊喜的背后,却是大多数 AI 在语言理解、视觉场景理解、决策分析等方面的举步维艰:这些技术依然主要集中在感知层面,即用 AI 模拟人类的听觉、视觉等感知能力,却无法解决推理、规划、联想、创作等复杂的认知智能化任务。
当前的 AI 缺少信息进入“大脑”后的加工、理解和思考等,做的只是相对简单的比对和识别,仅仅停留在“感知”阶段,而非“认知”,以感知智能技术为主的 AI 还与人类智能相差甚远。
究其原因在于,AI 正面临着制约其向前发展的瓶颈问题:大规模常识知识库与基于认知的逻辑推理。而基于知识图谱、认知推理、逻辑表达的认知图谱,则被越来越多的国内外学者和产业领袖认为是“目前可以突破这一技术瓶颈的可行解决方案之一”。
近日,清华大学计算机系教授、系副主任,智谱·AI 首席科学家唐杰在 MEET 2021 智能未来大会上作了题为《认知图谱——人工智能的下一个瑰宝》的精彩演讲。

唐杰,清华大学计算机系教授、系副主任,智谱·AI 首席科学家
MEET 2021 智能未来大会由量子位举办,大会邀请到了唐杰、李开复、谭建荣、崔宝秋等 AI 学术界、产业界的知名人物,围绕“重启”、“重塑”、“重构”三大主题,探讨未来的智能产业发展之路。
唐教授在演讲中首先简单介绍了人工智能的三个时代:符号智能 —— 感知智能 —— 认知智能。
提出现在需要探讨的问题是:计算机有没有认知?计算机能不能做推理?甚至计算机到未来有没有意识能够超过人类?
唐教授表示,当前认知 AI 还没有实现,我们急需做的是一些基础性的东西(AI 的基础设施),比如知识图谱的构建,知识图谱的一些认知逻辑,包括认知的基础设施等。
从 1950 年开始创建人工智能系统,到 1970 年开始深入的让计算机去模仿人脑,再到 1990 年计算机学家意识到计算机是 “参考” 人脑而不是完全的 “模仿”。现在我们更是处于一个计算机的变革时代,我们应该用更多的计算机思维来做计算机的思考,而不是人的思考。
现在人们需要思考的是:如何以计算机的方式做认知?唐教授谈到,可以结合两种方法去实现。
第一个从大数据的角度上做数据驱动,把所有的数据进行建模,并且学习数据之间的关联关系,学习数据的记忆模型;第二个是要用知识渠道,构建知识图谱。
不过,只这两个方面还是远远不够的。唐教授指出:真正的通用人工智能,我们希望它有持续学习的能力,能够从已有的事实、从反馈中学习到新的东西,能够完成一些更加复杂的任务。
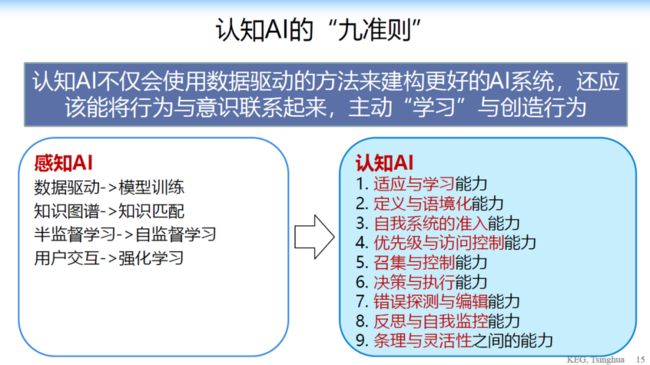
唐教授从人的认知和意识中抽象出来了 9 个认知 AI 的准则:
适应与学习能力
定义与语境化能力
自我系统的准入能力
优先级与访问控制能力
召集与控制能力
决策与执行能力
错误探测与编辑能力
反思与自我监控能力
条理与灵活性之间的能力
在这 9 个准则的基础上,提出了一个全新的认知图谱的概念,包括三个核心:
常识图谱。比如说高精度知识图谱的构建,领域制度的应用系统,超大规模城市知识图谱的构建,还有基于知识图谱的搜索和推荐等。
逻辑生成。与计算模型相关,需要超大规模的预训练模型,并且能够自动进行内容生成。
认知推理。即让计算机有逻辑推理和思维能力,像人一样思考。
唐教授表示,知识图谱+深度学习+认知心理,打造知识和认知推理双轮驱动的框架,将是接下来一个重要的研究方向。
以下为唐教授演讲实录(稍有删减):
非常感谢大会的邀请,有机会到这里来跟大家分享一下我们最近的一些研究。
为什么叫认知图谱?首先来看一下人工智能发展的脉络,从最早的符号智能,再到后面的感知智能,再到最近,所有人都在谈认知智能。我们现在需要探讨计算机有没有认知,计算机能不能做认知,计算机能不能做推理,甚至计算机到未来有没有意识,能够超过人类。
人工智能发展到现在已经有三个浪潮,我们把人工智能叫做三个时代,三个时代分别是符号 AI、感知 AI 和认知 AI。认知 AI 到现在没有实现,我们正在路上。
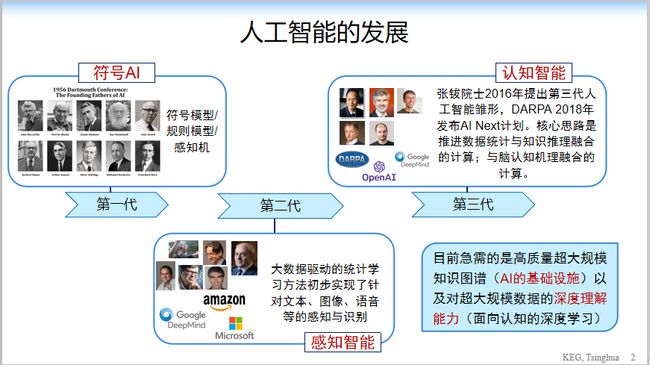
那现在急需的东西是什么?是一些基础性的东西,比如说里面的认知图谱怎么构建,里面认知的一些逻辑,包括认知的基础设施怎么建,这是我们特别想做的一件事情。
做这个之前,我们首先回顾一下机器学习。提到机器学习,很多人立马就说我知道机器学习有很多分类模型,比如说决策树,这里最左边列出了分类模型、序列模型、概率图模型,再往右边一点点就是最大化边界,还有深度学习,甚至再往下循环智能,再往右就是强化学习,深度强化学习,以及最近我们大家提到更多的无监督学习,这是机器学习的一个档位。那么,机器学习离我们的认知,到底还有多远呢?我们要看一看这个认知以及人的思考,包括人的认知到底怎么回事。
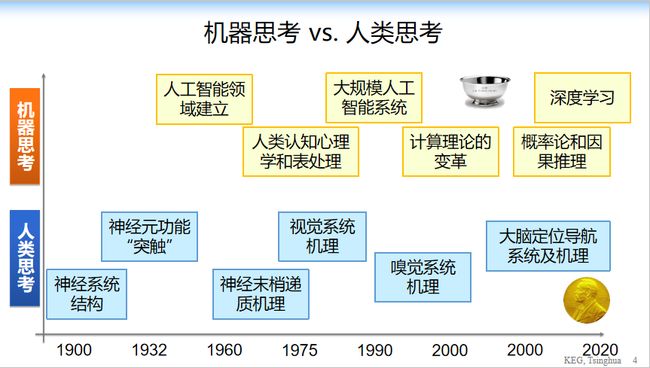
于是,我看了很多诺贝尔奖和图灵奖得主的资料,大概整理出了这样一页 PPT。下面是人的思考,在人的思考中得到所有的模型,上面是计算机图灵奖跟认知相关的信息。在 1900 年初的时候,就有神经系统结构。后来到 1932 年左右有神经元突触的一个诺奖,再到 60 年代有神经末梢传递机制,到 1975 年左右有了视觉系统,到近年也就是 20 年前才有了嗅觉系统,直到二零一几年的时候我们才有了大脑怎么定位导航,以及大脑的机理是怎么回事,这是诺奖。
我们看一下计算机怎么思考的,即机器思考。在 1950 年左右创立了人工智能系统,但是 1970 年左右大家开始拼命去模仿人脑,我们要做一个计算机,让他跟人脑特别相同。但到 1990 年左右,计算机学家们突然发现我们没有必要模仿,我们更多的是要参考人脑,参考脑系统,做一个让计算机能做更多的机器思考,机器思维。所以我们在这个时代,可以说是一个计算机革命的一个变革,我们用更多的计算机思维来做计算,来做计算机的思考,而不是人的思考。
最后,我们出现了概率图模型、概率与因果推理还有最近的深度学习。当然,有人会说,到最后你还在讲机器学习,在讲一个模型,这个离我们真正的是不是太远了?
我举另外一个例子,Open AI。我们要建造一个通用人工智能,让计算机系统甚至能够超越人,在过去几年连我自己都不信,我觉得通用人工智能很难实现。Open AI 做了几个场景,在受限场景下,比如游戏环境下已经打败了人类。上面的几个案例甚至开放了一些强化学习的一些框架,让大家可以在框架中进行编程。
下面就是最近几年最为震撼的。两年前 Open AI 做了 GPT,很简单,所有人就觉得是语言模型,并没有做什么事情;去年做的 GPT-2,这时候做出来的参数模型也没有那么大,几十亿的参数模型做出来的效果,我估计很多人都玩过,有一个 Demo,叫 talk to transformer,就是跟翻译来对话,你可以输入任何文本,transformer 帮你把文本补齐。
但是今年 6 月份的时候,Open AI 发布了一个 GPT-3,这个模型,参数规模一下子达到了 1750 亿,数量级接近人类的神经元的数量,这个时候给我们一个震撼的结果,计算机的参数模型,至少它的表示能力已经接近人类了。有可能效果还不如,但是它的表示能力已经接近人类了,也就是说在某种理论证明下,如果我们能够让计算机的参数足够好足够充足的话,他可能就能跟人的这种智商表现差不多。
这时候给我们另外一个启示,我们到底是不是可以直接通过计算机的结果,也就是计算的方法得到一个超越人类的通用人工智能?
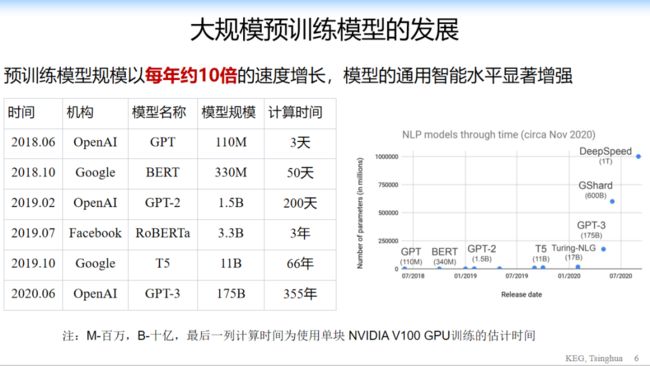
我们来看一下,这是整个模型过去几年发展的结果。几乎每年参数规模是 10 倍左右的增长,右边的图给出了自然语言处理中最近几年的快速变化,几乎是一个指数级的变化,可以看到,前几年变化相对比较小,今年出了 GPT-3,谷歌到了 6000 亿的产出规模,明年可能还会到万亿级别。所以这是一个非常快速的增长。
现在给我们另外一个问题,我们到底能不能用这种大规模、大算力的方法,大计算的方法,来实现真正的人工智能呢?这是一个问题。
当然另外一方面,大家看到也是另外一个痛点,所有训练的结果,大家看一下,GPT-3 如果用单卡的训练需要 355 年,整个训练的成本达到几亿的人民币,一般的公司也做不起来。现在另外一个问题就是,就算是有美团这样的大公司做了这个模型,是不是大家都可以用了,是不是就够了?
这是一个例子,左边是模型,右边是结果。第一个是长颈鹿有几个眼睛?GPT-3 说有两个眼睛,没有问题。第二个,我的脚有几个眼睛?结果是也有两个眼睛,这就错了。第三个是蜘蛛有几个眼睛?8 个眼睛。第四个太阳有几个眼睛?一个眼睛。最后一个呢,一根草有几个眼睛?一个眼睛。
可以看到,GPT-3 很聪明,可以生成所有的结果,这个结果是生成的,自动生成出来的,但是它有一个阿喀琉斯之踵,它其实没有常识。
我们需要一个常识的知识图谱。
2012 年的时候谷歌发出了一个 Knowledge Graph,就是知识图谱,当时概念就是,我们利用大量的数据能不能建一个图谱?于是在未来的搜索中,我们自动把搜索结果结构化,自动结构化的数据反馈出来。知识图谱不仅可以包括搜索引擎,另外一方面可以给我们计算带来一些常识性的知识,能不能通过这个方法帮助我们未来的计算呢,这给我们引出了另外一个问题。
其实知识图谱在很多年前就已经发展,从第一代人工智能,就是符号 AI 的时候就开始在做,当时就在定义知识图谱,就在定义这个符号 AI 的逻辑表示,70 年代叫知识工程,但是为什么到现在知识图谱还没有大规模的发展起来?
第一,构建的成本非常的高,如果你想构建得很准的话,人工成本非常高。你看 CYC 在 90 年代发展起来的,定义一个知识断言的成本,就是一个 ABC 三元组,A 就是主体,B 就是关系,C 是受体,比如说人有手,人就是主体,有就是关系,手就是受体,就是这么简单的一个问题,当时的成本就是 5.7 美元。另外一个项目,用互联网完全自动方法的生成出来,错误率一下提高的 10 倍,这两个项目目前基本上处于半停滞状态。
那怎么办呢?我们现在就在思考,从计算角度上看认知,究竟应该怎么做?如果还用计算做认知,该怎么实现?如果把刚才两个东西结合起来应该有这么一个模型。
第一,从大数据的角度,做数据驱动,我们用深度学习举十反一的方法,把所有的数据进行建模,并且学习数据之间的关联关系,学习数据的记忆模型。
第二,我们要用知识驱动,构建一个知识图谱,用知识驱动整个事情。我们把两者结合起来,这也许是我们解决未来认知 AI 的一个关键。
那够不够呢?答案是不够,我们的未来是需要构建一个真正能够超越原来的,超越已有模型的一个认知模型。这样的认知模型,它首先要超越 GPT-3 这样的预设模型,我们需要一个全新的架构框架,也需要一个全新的目标函数,这时候我们才有可能超过这样的预训练模型,否则我们就是在跟随。

举几个例子,这是我们最近尝试做的一件事情。这两个,大家觉得哪个是人做的?哪个是机器做的?其实这两个都是机器做出来的,这是我学生做出来的一个来给大家娱乐的。其实下面这个结果都不大对,内容也是不对的,上面这个结果也是完全由机器生成出来的。但是你看一下逻辑基本上可行,就是目前我们需要做的是,让机器有一定的创造能力,光文本还不够,我们希望创造出真正的图片,它是创造,不是查询。
这里有一篇文字,我们希望通过这篇文字能够把原来的原图自动生成新的图片,这个图片是生成出来的,我们希望这个机器有创造能力。当然,光创造还不够,我们离真正通用的人工智能还有多远?我们希望真正的通用人工智能能有持续学习的能力,能够从已有的事实,从反馈中学习到新的东西,能够完成一些更加复杂的任务。
这时候一个问题来了,什么叫认知?只要做出可持续学习就是认知吗?如果这样的话 GPT-3 也有这种学习的能力,知识图谱也有学习的能力,因为它在不停的更新。如果能完成一些复杂任务就是认知吗?也不是,我们有些系统已经可以完成非常复杂的问题。什么是认知呢?于是我们最近通过我们的一些思考,我们定义了认知 AI 的九准则。这九个准则是我从人的认知和意识中抽象出来的九个准则。
第一个,叫适应与学习能力,当一个机器在特定的环境下,比如说我们今天的 MEET 大会,这个机器人自动的学习,它能知道我们在这种模型下,在这个场景下应该做什么事情。
第二个,叫定义与语境能力,这个模型它能够在这个环境下感知上下文,能做这样的一个环境的感知。
第三个,叫自我系统的准入能力,我们描述的是这个机器它能够自定义什么是我,什么是非我,这叫人设。如果这个机器能知道自己的人设是什么,那么我们认为它有一定的认知能力。
第四个,优先级与访问控制能力,在一定的特定场景下它有选择的能力。我们人都可以在双十一选择购物,如果机器在双十一的时候能选择我今天想买点东西,明天后悔了,不应该买,这时候这个机器有一定的优先级和访问控制。
第五个,召集与控制能力,这个机器应该有统计和决策的能力。
第六个,决策与执行能力,这个机器人在感知到所有的数据以后它可以做决策。
第七个,错误探测与编辑能力,这个非常重要,人类的很多知识,其实是在试错中发现的,比如我们现在学的很多知识,我们并不知道什么知识是最好的,我们在不停的试错,也许我们今天学到了 1+1 等于 2 是很好,但是你尝试1+1 等于 3,1+1 等于 0,是不是也可以呢?你尝试完了发现都不对,这叫做错误探测与编辑,让机器具有这个能力,非常地重要。
第八个,反思与自我控制、自我监控,如果这个机器人在跟你聊天的过程中,聊了很久,说“不好意思我昨天跟你说的一句话说错了,我今天纠正了。”这时候机器具有反思能力。
最后,这个机器一定要有条理和理性。
我们把这些叫做认知 AI 的九准则。在九个准则的基础上,我们提出一个全新的认知图谱的概念。
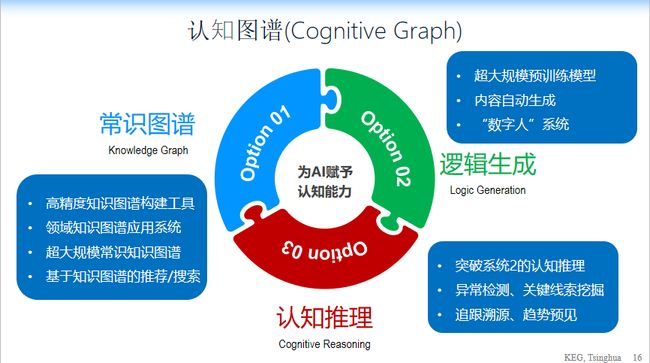
常识图谱有三个核心的要素。第一,常识图谱,比如说高精度知识图谱的构建、领域知识图谱的应用系统、超大规模知识图谱的构建,还有基于知识图谱的搜索和推荐,这是传统的一些东西。
第二,跟我们计算模型非常相关,我们叫逻辑生成,这时候需要超大规模的预训练模型,并且能够自动进行内容生成。同时我们在未来可以构建一个数字人的系统,它能够自动的在系统中,能够生成相关的东西,能够做得像人一样的数字人。
第三,需要认知推理,需要有认知推理的能力,让计算机有推理、有逻辑的能力。说起来比较虚,大家会问什么叫推理逻辑?人的认知有两个系统,一个叫系统 1,一个叫系统 2,系统 1 就是计算机做的匹配,你说清华大学在哪,它立刻匹配出来在北京,但是你说清华大学在全球计算机里面到底排在第几?以及为什么排在第几?这时候就需要一些逻辑推理,这时候计算机就回答不了,这时候需要做逻辑推理,我们要思考优势在哪,人思考的时候叫系统 2,慢系统,里面要做更多复杂的逻辑思考。我们当前所有的深度学习都是做系统 1,解决了系统 1 问题,是直觉认知,而不是逻辑认知。我们未来要做更多的就是系统 2 的事情。
我们从脑科学来看,相对现在做的事情有两个最大的不同,第一,就是记忆,第二就是推理。记忆是通过海马体实现,认知是前额叶来实现,这两个系统非常关键,怎么实现呢?我们看记忆模型,巴德利记忆模型分三层,短期记忆就是一个超级大的大数据模型,在大数据模型中,我们怎么把大数据模型中有些信息变成一个长期记忆,变成我们知识,这就是记忆模型要做的事情。
当然从逻辑推理下,还有更多的事情要做,那我们现在怎么办?认知图谱核心的东西就变成我们需要知识图谱,也需要深度学习,我们还要把认知心理的一些东西结合进来,来构造一个新的模型。
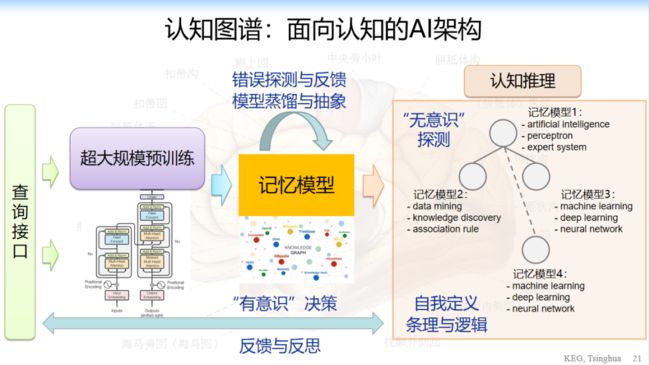
于是,最后一页,我们构建了这样一个框架,这个框架左边是一个查询接口,这是输入,你可以说用户端,中间是一个超大规模的预训练模型,一个记忆模型,记忆模型通过试错、蒸馏,把一些信息变成一个长期记忆存在长期记忆模型中,长期记忆模型中会做无意识的探测,也会做很多自我定义和条例的逻辑,并且做一些认知的推理。
在这样的基础上我们构建一个平台,目标是打造一个知识和认知推理双轮驱动的一个框架。底层是分布式的存储和管理,中间是推理、决策、预测,再上面是提供各式各样的 API。
公众号(DatapiTHU)后台回复“20201224”获取完整PPT下载
唐杰教授介绍:

唐杰,清华大学计算机系教授、系副主任,获杰青、IEEE Fellow。研究人工智能、认知图谱、数据挖掘、社交网络和机器学习。发表论文 300 余篇,引用 16000 余次,获 ACM SIGKDD Test-of-Time Award(十年最佳论文)。主持研发了研究者社会网络挖掘系统 AMiner,吸引全球 220 个国家/地区 2000 多万用户。担任 IEEE T. on Big Data、AI OPEN 主编以及 WWW’21、CIKM’16、WSDM’15 的 PC Chair。获北京市科技进步一等奖、人工智能学会一等奖、KDD 杰出贡献奖。
编辑:于腾凯
校对:林亦霖
