分布式事务以及Seata
事务
事务:保证多条sql 语句执行的一致性, 同一个事务中执行的sql 语句都是使用了同一个 sqlsession
sqlsession.setAutoCommit(false) // 关闭自动提交,开启事务
sqlSession.commit() 提交事务 //
四大特性:
-
原子性 不可以分割,要么成功,都成功,有一个失败,其他全部失败
-
一致性 举例:同一表中转账,一个用户给另外一个用户专账,整体钱数不能多,也不能少
-
隔离性 多个事务(sqlSession)是否能够看到另外一个 事务未提交的数据
-
持久性 提交事务后,掉电不丢失
隔离级别:
一个事务 看到两外一个事务 是否提交数据的程度,允许脏数据的程度
脏读数据程度:
脏读:一个事务 看到另外一个事务 未提交的数据
不可重复读:同一事务中读取 两次同一行数据,结果不一致
幻读:同一事务中同一sql 查选多条数据,执行两次,查询结果数量不一致
隔离级别
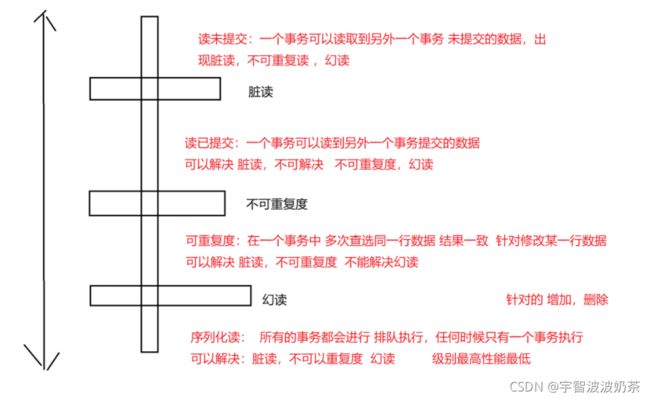
MySQL 默认的隔离级别:可重复读,也可以解决幻读的问题
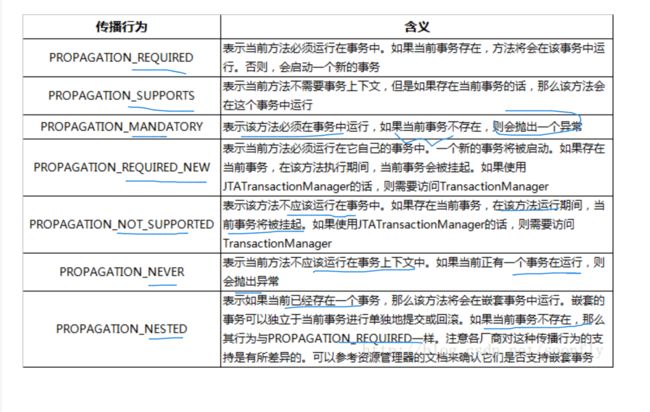
传播行为
传播行为,就是在多个方法调用过程中,是否共享 同一个 sqlsession
传播行为(7种):
support :如果调用者有事务,就是使用调用者(外部)的事务,调用者没有开启,则不开启
required: :如果调用者有事务,则使用外部的事务,调用者没有开启,则自己开启
requirednew:不管调用者有没有事务,我都开启新的事务
1.分布式事务
分布式事务:就是在我们微服务的业务中,跨应用调用,保证数据一致性
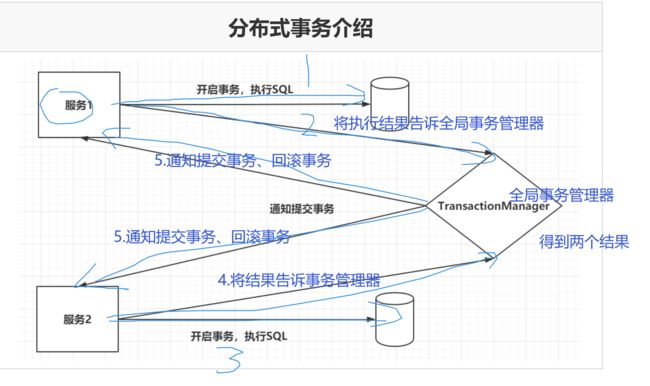
在分布式业务中的基本知识
CAP
CAP理论一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)
一致性:没时每刻从 每一个结点读取到的数据都是一致
可用性:如果有部分结点挂了,不影响整个集群
分区容错性:数据可以有分区隔离,每一个分区都有备份
在分布式业务不肯能同时满足 三个特性CAP,只能满足其中两个
CP:
AP:
- Eureka:AP,保证了可用性,舍弃了一致性。
- Zookeeper:CP,每一个节点必须能够找到Master才能对外提供服务,舍弃了可用性。
Base理论
BA:基本可用,S:中间状态,E:最终一致性。
Base 是对cap 的妥协,暂时丢失一致性获取的可用性 和分区容错,从而达到最终的一致性
-
基于CAP理论演化而来的,是对CAP定理中一致性和可用性的一个权衡结果。
-
核心思想:我们无法做到强一致性,但是每一个应用都可以根据自身的业务特点,采用一些适当的方式来权衡,最终达到一致性。
-
S:允许系统之间存在一个中间状态,并不会影响正常的去使用整个系统,允许数据的同步存在延迟。
-
E:系统中所有的数据副本经过一定时间后,最终能够达到一致的状态,不需要保证系统数据强一致性。
2.分布式事务解决方案【重点】
2PC两段提交
两段提交分为两个阶段:
第一个阶段是准备阶段,参与者需要开启事务,执行SQL,保证数据库中已经存在相应的数据。参与者会向TransactionManager准备OK。
第二个阶段当TransactionManager收到了所有的参与者的通知之后,向所有的参与者发送Commit请求。
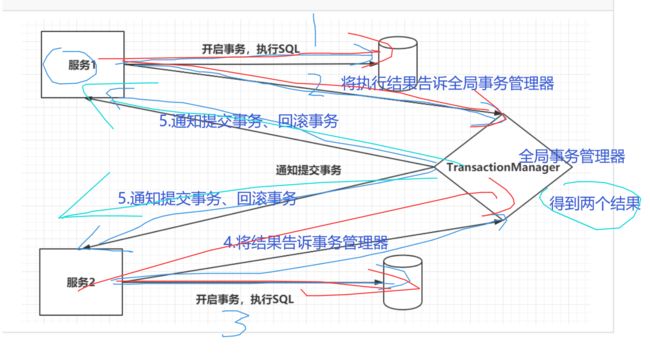
缺陷:
问题1:执行的性能是很低的。一般是传统事务的10倍以上。
问题2:TransactionManager是没有超时时间的。
问题3:TransactionManager存在单点故障的问题
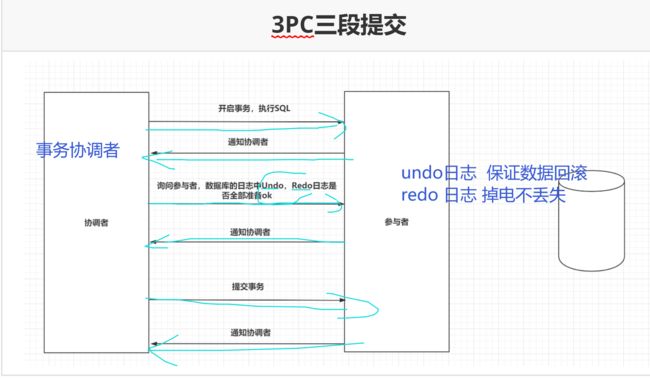
3pc
三段提交在二段提交的基础上,引入了超时时间机制,并且在二段提交的基础上,又多了一个步骤,在提交事务之前,再询问一下,数据库的日志信息,是否已经完善。
优化:
-
1.引入超时机制
-
2.引入sql 日志,便于回滚
TCC机制
TCC(Try,Confirm,Cancel),和你的业务代码切合在一起。
Try:尝试去预执行具体业务代码。 下单订ing。。。
try成功了:Confirm:再次执行Confirm的代码。
try失败了:Cancel:再次执行Cancel的代码。
TCC 一般需要我们自己实现对应的 try Confirm cancel 接口
TCC 使用起来非常麻烦,但是性能非常好,适合高并发场合
Try:包含资源的预留,锁定 ,执行sql
Confirm:提交数据
Cancel:回滚 已执行的sql,释放锁定的资源
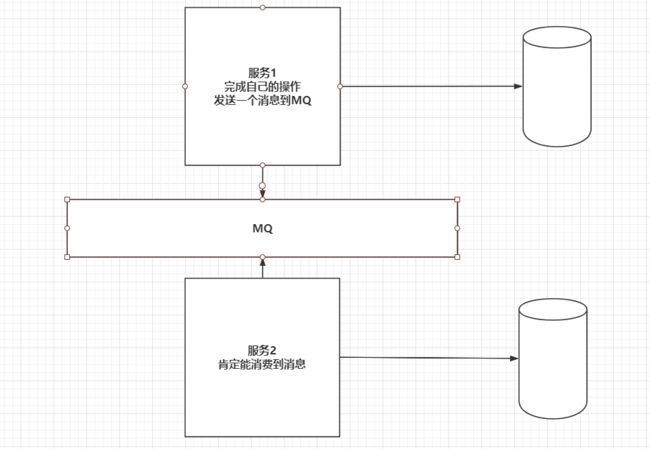
MQ分布式事务
RabbitMQ在发送消息时,confirm机制,可以保证消息发送到MQ服务中,消费者有手动ack机制,保证消费到MQ中的消息。
| MQ分布式事务 |
|---|
|
|
3.Seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
Seata
AT 模式
前提
-
基于支持本地 ACID 事务的关系型数据库。
-
Java 应用,通过 JDBC 访问数据库。
整体机制
两阶段提交协议的演变:
-
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
-
二阶段:
-
提交异步化,非常快速地完成。
-
回滚通过一阶段的回滚日志进行反向补偿。
-
TCC 模式
回顾总览中的描述:一个分布式的全局事务,整体是 两阶段提交 的模型。全局事务是由若干分支事务组成的,分支事务要满足 两阶段提交 的模型要求,即需要每个分支事务都具备自己的:
-
一阶段 prepare 行为 资源的预留,锁定
-
二阶段 commit 或 rollback 行为
AT 模式(参考链接 TBD)基于 支持本地 ACID 事务 的 关系型数据库:
-
一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
-
二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
-
二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
相应的,TCC 模式,不依赖于底层数据资源的事务支持:
-
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
-
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
-
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
Saga 模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
长事务:就是执行该事务,占用时间很长,造成占用数据连接资源,造成mysql主从 数据不同不问题
适用场景:
-
业务流程长、业务流程多
-
参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
XA
XA模式 是 AT 模式的升级版。
4.Seata原理和设计
定义一个分布式事务
我们可以把一个分布式事务理解成一个包含了若干分支事务的全局事务,全局事务的职责是协调其下管辖的分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个满足ACID的本地事务。这是我们对分布式事务结构的基本认识,与 XA 是一致的。
协议分布式事务处理过程的三个组件
-
Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
事务协调器: 他是通信员,秘书 负责跑腿传递消息
-
Transaction Manager

: 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
全局事务管理器: 就是大boss,决策者
-
Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
资源管理器: 负责接收 TC 的命令, 并协调本地事务的提交和回滚
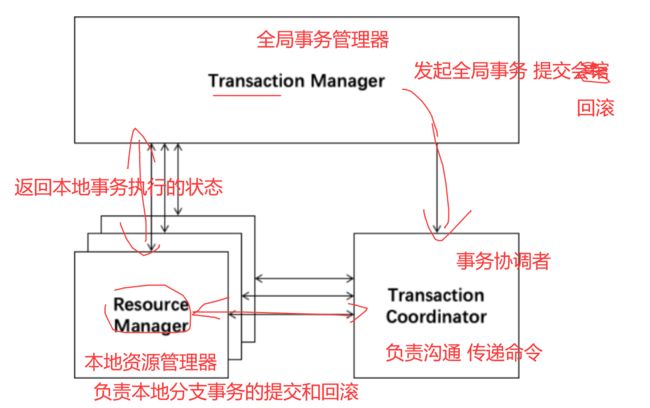
一个典型的分布式事务过程
-
TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID;
-
XID 在微服务调用链路的上下文中传播;
-
RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖;
-
TM 向 TC 发起针对 XID 的全局提交或回滚决议;
-
TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
5.案例分析
可以从gitee上拉下来我写好的代码,配好数据库之后运行
一杯香菜汁儿/springcloudtxhttps://gitee.com/Qian12581/springcloudtx.git
6.使用seata 的AT 模式解决数据不一致问题
1.解压seata
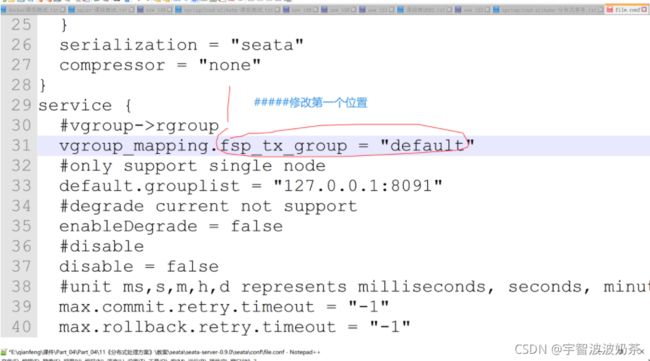
2.修改配置文件
配置文件conf/file.conf,要修改三处
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
service {
#vgroup->rgroup
vgroup_mapping.fsp_tx_group = "default"
#only support single node
default.grouplist = "127.0.0.1:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
client {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
}
report.retry.count = 5
tm.commit.retry.count = 1
tm.rollback.retry.count = 1
}
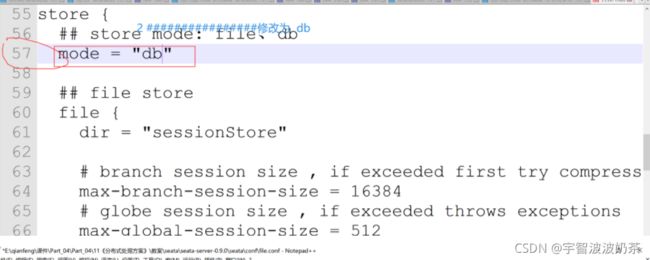
## transaction log store
store {
## store mode: file、db
mode = "db"
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
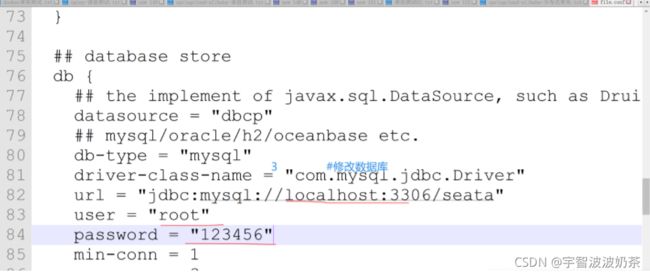
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
driver-class-name = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://localhost:3306/seata"
user = "root"
password = "123456"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
lock {
## the lock store mode: local、remote
mode = "remote"
local {
## store locks in user's database
}
remote {
## store locks in the seata's server
}
}
recovery {
#schedule committing retry period in milliseconds
committing-retry-period = 1000
#schedule asyn committing retry period in milliseconds
asyn-committing-retry-period = 1000
#schedule rollbacking retry period in milliseconds
rollbacking-retry-period = 1000
#schedule timeout retry period in milliseconds
timeout-retry-period = 1000
}
transaction {
undo.data.validation = true
undo.log.serialization = "jackson"
undo.log.save.days = 7
#schedule delete expired undo_log in milliseconds
undo.log.delete.period = 86400000
undo.log.table = "undo_log"
}
## metrics settings
metrics {
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
}
support {
## spring
spring {
# auto proxy the DataSource bean
datasource.autoproxy = false
}
}
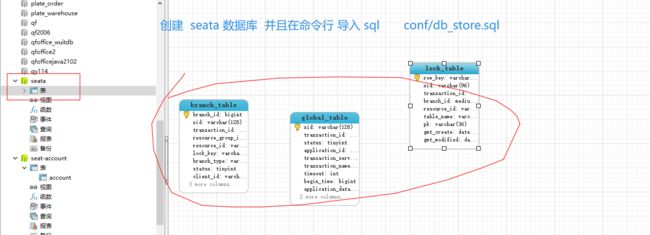
创建数据库
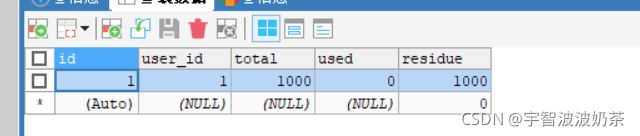
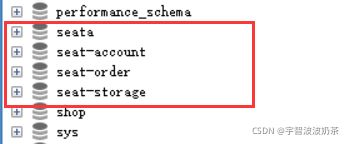
创建seat-account、seat-order、seat-storage三个数据库,并分别创建表
CREATE TABLE `account` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_id` bigint(11) DEFAULT NULL COMMENT '用户id',
`total` decimal(10,0) DEFAULT NULL COMMENT '总额度',
`used` decimal(10,0) DEFAULT NULL COMMENT '已用余额',
`residue` decimal(10,0) DEFAULT '0' COMMENT '剩余可用额度',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO `seat-account`.`account` (`id`, `user_id`, `total`, `used`, `residue`) VALUES ('1', '1', '1000', '0', '1000');
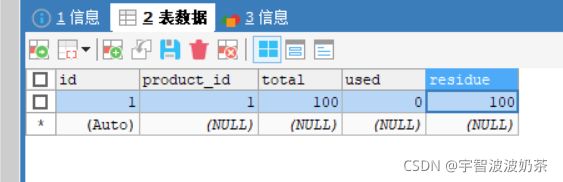
CREATE TABLE `order` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(11) DEFAULT NULL COMMENT '用户id',
`product_id` bigint(11) DEFAULT NULL COMMENT '产品id',
`count` int(11) DEFAULT NULL COMMENT '数量',
`money` decimal(11,0) DEFAULT NULL COMMENT '金额',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
ALTER TABLE `order` ADD COLUMN `status` int(1) DEFAULT NULL COMMENT '订单状态:0:创建中;1:已完结' AFTER `money` ;
CREATE TABLE `storage` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`product_id` bigint(11) DEFAULT NULL COMMENT '产品id',
`total` int(11) DEFAULT NULL COMMENT '总库存',
`used` int(11) DEFAULT NULL COMMENT '已用库存',
`residue` int(11) DEFAULT NULL COMMENT '剩余库存',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO `seat-storage`.`storage` (`id`, `product_id`, `total`, `used`, `residue`) VALUES ('1', '1', '100', '0', '100');
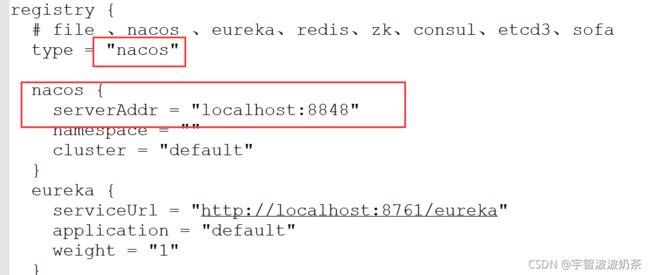
配置文件conf/registry.conf 修改
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
serverAddr = "localhost:8848"
namespace = ""
cluster = "default"
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
3.启动seata
注册到nacos
4.在三个应用分别引入seata
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
seata-all
io.seata
io.seata
seata-all
${seata.version}
5.在三个配置文件中配置
spring:
application:
name: seata-order-service
cloud:
nacos:
discovery:
server-addr: localhost:8848
alibaba:
seata:
tx-service-group: fsp_tx_group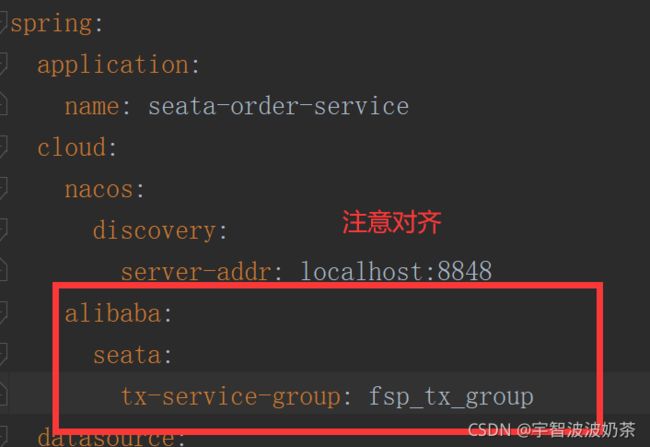
6.讲seata 中的conf/file.conf registry.conf 分别拷贝到三个应用的resources 中
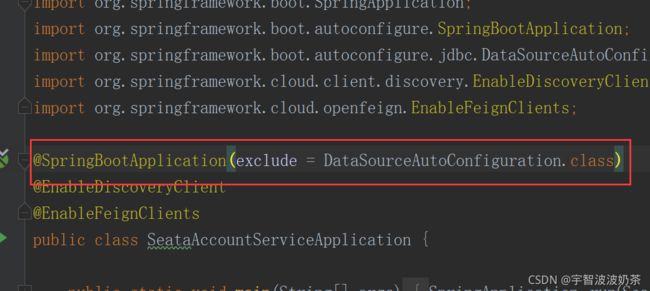
7.在三个应用都取消自动装配
// 排除数据源的自动装配,自己手动装配
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
@EnableDiscoveryClient
@EnableFeignClients
public class SeataAccountServiceApplication {
public static void main(String[] args) {
SpringApplication.run(SeataAccountServiceApplication.class, args);
}
}
配置自定数据源装配
package com.qfedu.cloud.config;
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.transaction.SpringManagedTransactionFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
@Configuration
public class DataSourceProxyConfig {
@Value("${mybatis.mapperLocations}")
private String mapperLocations;
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource(){
return new DruidDataSource();
}
@Bean// DataSourceProxy代理类代理 druid数据源,因为RM 管理提交本地事务都是通过 DataSourceProxy
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(mapperLocations));
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}
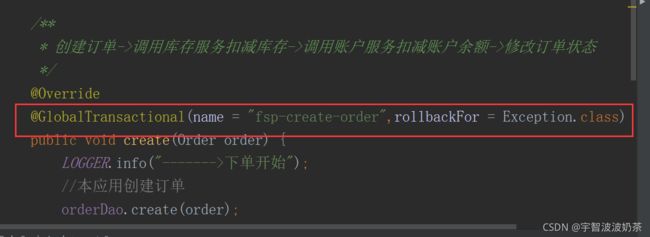
8.开启全局事务
只在order 应用中开启
9.我们需要在三个应用的数据库中 都创建 undo_log
来源于 conf/db_undo_log.sql
-
重启三个应用,在此时分布式事务是否有效
经测试,可以发现 数据可以保持一致性
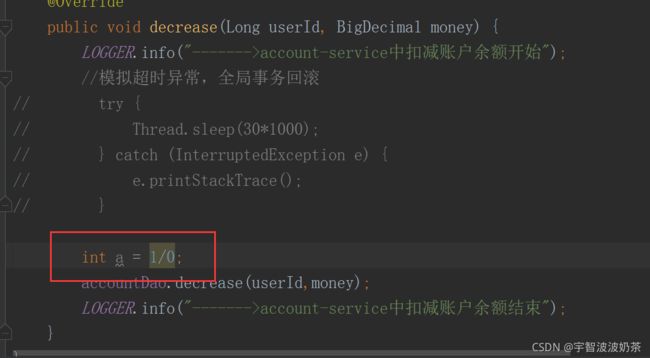
在扣款这里加上算数异常
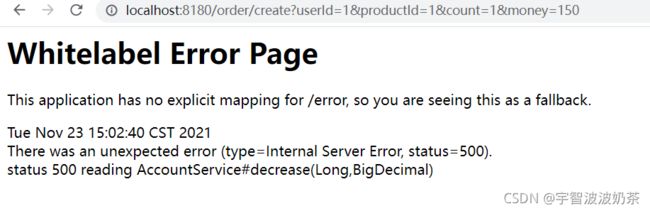
访问创建的url会报500
查看数据库发现数据都不会改变,说明产生了回滚