本文由HeapDump性能社区首席讲师鸠摩(马智)授权整理发布
第17章-x86-64寄存器
不同的CPU都能够解释的机器语言的体系称为指令集架构(ISA,Instruction Set Architecture),也可以称为指令集(instruction set)。Intel将x86系列CPU之中的32位CPU指令集架构称为IA-32,IA是“Intel Architecture”的简称,也可以称为i386、x86-32。AMD等于Intell提出了x86系列的64位扩展,所以由AMD设计的x86系列的64位指令集架构称为AMD64。后来Intel在自己的CPU中加入和AMD64几乎相同的指令集,称为Intel 64的指令集。AMD64和Intel 64可以统称为x86-64。
x86-64的所有寄存器都是与机器字长(数据总线位宽)相同,即64位的,x86-64将x86的8个32位通用寄存器扩展为64位(eax、ebx、ecx、edx、eci、edi、ebp、esp),并且增加了8个新的64位寄存器(r8-r15),在命名方式上,也从”exx”变为”rxx”,但仍保留”exx”进行32位操作,下表描述了各寄存器的命名和作用。
| 描述 | 32位 | 64位 |
| 通用寄存器组 | eax | rax |
| ecx | rcx | |
| edx | rdx | |
| ebx | rbx | |
| esp | rsp | |
| ebp | rbp | |
| esi | rsi | |
| edi | rdi | |
| - | r8~r15 | |
| 浮点寄存器组 | st0~st7 | st0~st7 |
| XMM寄存器组 | XMM0~XMM7 | XMM0~XMM15 |
其中的%esp与%ebp有特殊用途,用来保存指向程序栈中特定位置的指针。
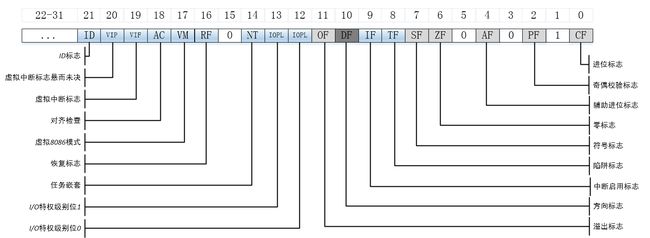
另外还有eflags寄存器,通过位来表示特定的含义,如下图所示。
在HotSpot VM中,表示寄存器的类都继承自AbstractRegisterImpl类,这个类的定义如下:
源代码位置:hotspot/src/share/vm/asm/register.hpp
class AbstractRegisterImpl;
typedef AbstractRegisterImpl* AbstractRegister;
class AbstractRegisterImpl {
protected:
int value() const { return (int)(intx)this; }
};
AbstractRegisterImpl类的继承体系如下图所示。
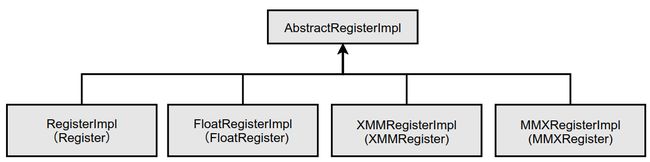
另外还有个ConcreteRegisterImpl类也继承了AbstractRegisterImpl,这个灰与C2编译器的实现有关,这里不做过多讲解。
1、RegisterImpl类
RegisterImpl类用来表示通用寄存器,类的定义如下:
源代码位置:cpu/x86/vm/register_x86.hpp
// 使用Register做为RegisterImpl的简称
class RegisterImpl;
typedef RegisterImpl* Register;
class RegisterImpl: public AbstractRegisterImpl {
public:
enum {
number_of_registers = 16,
number_of_byte_registers = 16
};
// ...
};
对于64位来说,通用寄存器的位宽为64位,也可以将eax、ebx、ecx和edx的一部分当作8位寄存器来使用,所以可以存储字节的寄存器数量为4。
在HotSpot VM中定义寄存器,如下:
源代码位置:hotspot/src/cpu/x86/vm/register_x86.hpp
CONSTANT_REGISTER_DECLARATION(Register, noreg, (-1)); // noreg_RegisterEnumValue = ((-1))
CONSTANT_REGISTER_DECLARATION(Register, rax, (0)); // rax_RegisterEnumValue = ((0))
CONSTANT_REGISTER_DECLARATION(Register, rcx, (1)); // rcx_RegisterEnumValue = ((1))
CONSTANT_REGISTER_DECLARATION(Register, rdx, (2)); // rdx_RegisterEnumValue = ((2))
CONSTANT_REGISTER_DECLARATION(Register, rbx, (3)); // rbx_RegisterEnumValue = ((3))
CONSTANT_REGISTER_DECLARATION(Register, rsp, (4)); // rsp_RegisterEnumValue = ((4))
CONSTANT_REGISTER_DECLARATION(Register, rbp, (5)); // rbp_RegisterEnumValue = ((5))
CONSTANT_REGISTER_DECLARATION(Register, rsi, (6)); // rsi_RegisterEnumValue = ((6))
CONSTANT_REGISTER_DECLARATION(Register, rdi, (7)); // rdi_RegisterEnumValue = ((7))
CONSTANT_REGISTER_DECLARATION(Register, r8, (8)); // r8_RegisterEnumValue = ((8))
CONSTANT_REGISTER_DECLARATION(Register, r9, (9)); // r9_RegisterEnumValue = ((9))
CONSTANT_REGISTER_DECLARATION(Register, r10, (10)); // r10_RegisterEnumValue = ((10))
CONSTANT_REGISTER_DECLARATION(Register, r11, (11)); // r11_RegisterEnumValue = ((11))
CONSTANT_REGISTER_DECLARATION(Register, r12, (12)); // r12_RegisterEnumValue = ((12))
CONSTANT_REGISTER_DECLARATION(Register, r13, (13)); // r13_RegisterEnumValue = ((13))
CONSTANT_REGISTER_DECLARATION(Register, r14, (14)); // r14_RegisterEnumValue = ((14))
CONSTANT_REGISTER_DECLARATION(Register, r15, (15)); // r15_RegisterEnumValue = ((15))
宏CONSTANT_REGISTER_DECLARATION定义如下:
源代码位置:hotspot/src/share/vm/asm/register.hpp
#define CONSTANT_REGISTER_DECLARATION(type, name, value) \
extern const type name; \
enum { name##_##type##EnumValue = (value) }
经过宏扩展后如下:
extern const Register rax;
enum { rax_RegisterEnumValue = ((0)) }
extern const Register rcx;
enum { rcx_RegisterEnumValue = ((1)) }
extern const Register rdx;
enum { rdx_RegisterEnumValue = ((2)) }
extern const Register rbx;
enum { rbx_RegisterEnumValue = ((3)) }
extern const Register rsp;
enum { rsp_RegisterEnumValue = ((4)) }
extern const Register rbp;
enum { rbp_RegisterEnumValue = ((5)) }
extern const Register rsi;
enum { rsi_RegisterEnumValue = ((6)) }
extern const Register rsi;
enum { rdi_RegisterEnumValue = ((7)) }
extern const Register r8;
enum { r8_RegisterEnumValue = ((8)) }
extern const Register r9;
enum { r9_RegisterEnumValue = ((9)) }
extern const Register r10;
enum { r10_RegisterEnumValue = ((10)) }
extern const Register r11;
enum { r11_RegisterEnumValue = ((11)) }
extern const Register r12;
enum { r12_RegisterEnumValue = ((12)) }
extern const Register r13;
enum { r13_RegisterEnumValue = ((13)) }
extern const Register r14;
enum { r14_RegisterEnumValue = ((14)) }
extern const Register r15;
enum { r15_RegisterEnumValue = ((15)) }
如上的枚举类给寄存器指定了一个常量值。
在cpu/x86/vm/register_definitions_x86.cpp文件中定义的寄存器如下:
const Register noreg = ((Register)noreg_RegisterEnumValue)
const Register rax = ((Register)rax_RegisterEnumValue)
const Register rcx = ((Register)rcx_RegisterEnumValue)
const Register rdx = ((Register)rdx_RegisterEnumValue)
const Register rbx = ((Register)rbx_RegisterEnumValue)
const Register rsp = ((Register)rsp_RegisterEnumValue)
const Register rbp = ((Register)rbp_RegisterEnumValue)
const Register rsi = ((Register)rsi_RegisterEnumValue)
const Register rdi = ((Register)rdi_RegisterEnumValue)
const Register r8 = ((Register)r8_RegisterEnumValue)
const Register r9 = ((Register)r9_RegisterEnumValue)
const Register r10 = ((Register)r10_RegisterEnumValue)
const Register r11 = ((Register)r11_RegisterEnumValue)
const Register r12 = ((Register)r12_RegisterEnumValue)
const Register r13 = ((Register)r13_RegisterEnumValue)
const Register r14 = ((Register)r14_RegisterEnumValue)
const Register r15 = ((Register)r15_RegisterEnumValue)
当我们需要使用通用寄存器时,通过rax、rcx等变量引用就可以了。
2、FloatRegisterImpl
在HotSpot VM中,使用FloatRegisterImpl来表示浮点寄存器,此类的定义如下:
源代码位置:hotspot/src/cpu/x86/vm/register_x86.hpp
// 使用FloatRegister做为简称
class FloatRegisterImpl;
typedef FloatRegisterImpl* FloatRegister;
class FloatRegisterImpl: public AbstractRegisterImpl {
public:
enum {
number_of_registers = 8
};
// ...
}
浮点寄存器有8个,分别是st0~st7,这是8个80位寄存器。
这里需要注意的是,还有一种寄存器MMX,MMX并非一种新的寄存器,而是借用了80位浮点寄存器的低64位,也就是说,使用MMX指令集,会影响浮点运算!
3、MMXRegisterImpl
MMX 为一种 SIMD 技术,即可通过一条指令执行多个数据运算,共有8个64位寄存器(借用了80位浮点寄存器的低64位),分别为mm0 – mm7,他与其他普通64位寄存器的区别在于通过它的指令进行运算,可以同时计算2个32位数据,或者4个16位数据等等,可以应用为图像处理过程中图形 颜色的计算。
MMXRegisterImpl类的定义如下:
class MMXRegisterImpl;
typedef MMXRegisterImpl* MMXRegister;
MMX寄存器的定义如下:
CONSTANT_REGISTER_DECLARATION(MMXRegister, mnoreg , (-1));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx0 , ( 0));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx1 , ( 1));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx2 , ( 2));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx3 , ( 3));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx4 , ( 4));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx5 , ( 5));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx6 , ( 6));
CONSTANT_REGISTER_DECLARATION(MMXRegister, mmx7 , ( 7));
宏扩展后如下:
extern const MMXRegister mnoreg;
enum { mnoreg_MMXRegisterEnumValue = ((-1)) }
extern const MMXRegister mmx0;
enum { mmx0_MMXRegisterEnumValue = (( 0)) }
extern const MMXRegister mmx1;
enum { mmx1_MMXRegisterEnumValue = (( 1)) }
extern const MMXRegister mmx2;
enum { mmx2_MMXRegisterEnumValue = (( 2)) }
extern const MMXRegister mmx3;
enum { mmx3_MMXRegisterEnumValue = (( 3)) }
extern const MMXRegister mmx4;
enum { mmx4_MMXRegisterEnumValue = (( 4)) }
extern const MMXRegister mmx5;
enum { mmx5_MMXRegisterEnumValue = (( 5)) }
extern const MMXRegister mmx6;
enum { mmx6_MMXRegisterEnumValue = (( 6)) }
extern const MMXRegister mmx7;
enum { mmx7_MMXRegisterEnumValue = (( 7)) }
MMX Pentium以及Pentium II之后的CPU中有从mm0到mm7共8个64位寄存器。但实际上MMX寄存器和浮点数寄存器是共用的,即无法同时使用浮点数寄存器和MMX寄存器。
cpu/x86/vm/register_definitions_x86.cpp文件中定义的寄存器变量如下:
const MMXRegister mnoreg = ((MMXRegister)mnoreg_MMXRegisterEnumValue)
const MMXRegister mmx0 = ((MMXRegister)mmx0_MMXRegisterEnumValue)
const MMXRegister mmx1 = ((MMXRegister)mmx1_MMXRegisterEnumValue)
const MMXRegister mmx2 = ((MMXRegister)mmx2_MMXRegisterEnumValue)
const MMXRegister mmx3 = ((MMXRegister)mmx3_MMXRegisterEnumValue)
const MMXRegister mmx4 = ((MMXRegister)mmx4_MMXRegisterEnumValue)
const MMXRegister mmx5 = ((MMXRegister)mmx5_MMXRegisterEnumValue)
const MMXRegister mmx6 = ((MMXRegister)mmx6_MMXRegisterEnumValue)
const MMXRegister mmx7 = ((MMXRegister)mmx7_MMXRegisterEnumValue)
当我们需要使用MMX寄存器时,通过mmx0、mmx1等变量引用就可以了。
4、XMMRegisterImpl类
XMM寄存器是SSE指令用的寄存器。Pentium iii以及之后的CPU中提供了xmm0到xmm7共8个128位宽的XMM寄存器。另外还有个mxcsr寄存器,这个寄存器用来表示SSE指令的运算状态的寄存器。在HotSpot VM中,通过XMMRegisterImpl类来表示寄存器。这个类的定义如下:
源代码位置:hotspot/src/share/x86/cpu/vm/register_x86.hpp
// 使用XMMRegister寄存器做为简称
class XMMRegisterImpl;
typedef XMMRegisterImpl* XMMRegister;
class XMMRegisterImpl: public AbstractRegisterImpl {
public:
enum {
number_of_registers = 16
};
...
}
XMM寄存器的定义如下:
CONSTANT_REGISTER_DECLARATION(XMMRegister, xnoreg , (-1));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm0 , ( 0));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm1 , ( 1));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm2 , ( 2));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm3 , ( 3));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm4 , ( 4));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm5 , ( 5));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm6 , ( 6));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm7 , ( 7));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm8, (8));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm9, (9));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm10, (10));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm11, (11));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm12, (12));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm13, (13));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm14, (14));
CONSTANT_REGISTER_DECLARATION(XMMRegister, xmm15, (15));
经过宏扩展后为:
extern const XMMRegister xnoreg;
enum { xnoreg_XMMRegisterEnumValue = ((-1)) }
extern const XMMRegister xmm0;
enum { xmm0_XMMRegisterEnumValue = (( 0)) }
extern const XMMRegister xmm1;
enum { xmm1_XMMRegisterEnumValue = (( 1)) }
extern const XMMRegister xmm2;
enum { xmm2_XMMRegisterEnumValue = (( 2)) }
extern const XMMRegister xmm3;
enum { xmm3_XMMRegisterEnumValue = (( 3)) }
extern const XMMRegister xmm4;
enum { xmm4_XMMRegisterEnumValue = (( 4)) }
extern const XMMRegister xmm5;
enum { xmm5_XMMRegisterEnumValue = (( 5)) }
extern const XMMRegister xmm6;
enum { xmm6_XMMRegisterEnumValue = (( 6)) }
extern const XMMRegister xmm7;
enum { xmm7_XMMRegisterEnumValue = (( 7)) }
extern const XMMRegister xmm8;
enum { xmm8_XMMRegisterEnumValue = ((8)) }
extern const XMMRegister xmm9;
enum { xmm9_XMMRegisterEnumValue = ((9)) }
extern const XMMRegister xmm10;
enum { xmm10_XMMRegisterEnumValue = ((10)) }
extern const XMMRegister xmm11;
enum { xmm11_XMMRegisterEnumValue = ((11)) }
extern const XMMRegister xmm12;
enum { xmm12_XMMRegisterEnumValue = ((12)) }
extern const XMMRegister xmm13;
enum { xmm13_XMMRegisterEnumValue = ((13)) }
extern const XMMRegister xmm14;
enum { xmm14_XMMRegisterEnumValue = ((14)) }
extern const XMMRegister xmm15;
enum { xmm15_XMMRegisterEnumValue = ((15)) }
在cpu/x86/vm/register_definitions_x86.cpp文件中定义的寄存器变量如下:
const XMMRegister xnoreg = ((XMMRegister)xnoreg_XMMRegisterEnumValue)
const XMMRegister xmm0 = ((XMMRegister)xmm0_XMMRegisterEnumValue)
const XMMRegister xmm1 = ((XMMRegister)xmm1_XMMRegisterEnumValue)
const XMMRegister xmm2 = ((XMMRegister)xmm2_XMMRegisterEnumValue)
const XMMRegister xmm3 = ((XMMRegister)xmm3_XMMRegisterEnumValue)
const XMMRegister xmm4 = ((XMMRegister)xmm4_XMMRegisterEnumValue)
const XMMRegister xmm5 = ((XMMRegister)xmm5_XMMRegisterEnumValue)
const XMMRegister xmm6 = ((XMMRegister)xmm6_XMMRegisterEnumValue)
const XMMRegister xmm7 = ((XMMRegister)xmm7_XMMRegisterEnumValue)
const XMMRegister xmm8 = ((XMMRegister)xmm8_XMMRegisterEnumValue)
const XMMRegister xmm9 = ((XMMRegister)xmm9_XMMRegisterEnumValue)
const XMMRegister xmm10 = ((XMMRegister)xmm10_XMMRegisterEnumValue)
const XMMRegister xmm11 = ((XMMRegister)xmm11_XMMRegisterEnumValue)
const XMMRegister xmm12 = ((XMMRegister)xmm12_XMMRegisterEnumValue)
const XMMRegister xmm13 = ((XMMRegister)xmm13_XMMRegisterEnumValue)
const XMMRegister xmm14 = ((XMMRegister)xmm14_XMMRegisterEnumValue)
const XMMRegister xmm15 = ((XMMRegister)xmm15_XMMRegisterEnumValue)
当我们需要使用XMM寄存器时,直接通过xmm0、xmm1等变量引用就可以了。
第18章-x86指令集之常用指令
x86的指令集可分为以下4种:
- 通用指令
- x87 FPU指令,浮点数运算的指令
- SIMD指令,就是SSE指令
- 系统指令,写OS内核时使用的特殊指令
下面介绍一些通用的指令。指令由标识命令种类的助记符(mnemonic)和作为参数的操作数(operand)组成。例如move指令:
| 指令 | 操作数 | 描述 |
| movq | I/R/M,R/M | 从一个内存位置复制1个双字(64位,8字节)大小的数据到另外一个内存位置 |
| movl | I/R/M,R/M | 从一个内存位置复制1个字(32位,4字节)大小的数据到另外一个内存位置 |
| movw | I/R/M, R/M | 从一个内存位置复制2个字节(16位)大小的数据到另外一个内存位置 |
| movb | I/R/M, R/M | 从一个内存位置复制1个字节(8位)大小的数据到另外一个内存位置 |
movl为助记符。助记符有后缀,如movl中的后缀l表示作为操作数的对象的数据大小。l为long的缩写,表示32位的大小,除此之外,还有b、w,q分别表示8位、16位和64位的大小。
指令的操作数如果不止1个,就将每个操作数以逗号分隔。每个操作数都会指明是否可以是立即模式值(I)、寄存器(R)或内存地址(M)。
另外还要提示一下,在x86的汇编语言中,采用内存位置的操作数最多只能出现一个,例如不可能出现mov M,M指令。
通用寄存器中每个操作都可以有一个字符的后缀,表明操作数的大小,如下表所示。
| C声明 | 通用寄存器后缀 | 大小(字节) |
| char | b | 1 |
| short | w | 2 |
| (unsigned) int / long / char* | l | 4 |
| float | s | 4 |
| double | l | 5 |
| long double | t | 10/12 |
注意:通用寄存器使用后缀“l”同时表示4字节整数和8字节双精度浮点数,这不会产生歧义,因为浮点数使用的是完全不同的指令和寄存器。
我们后面只介绍call、push等指令时,如果在研究HotSpot VM虚拟机的汇编遇到了callq,pushq等指令时,千万别不认识,后缀就是表示了操作数的大小。
下表为操作数的格式和寻址模式。
| 格式 | 操作数值 | 名称 | 样例(通用寄存器 = C语言) |
| $Imm | Imm | 立即数寻址 | $1 = 1 |
| Ea | R[Ea] | 寄存器寻址 | %eax = eax |
| Imm | M[Imm] | 绝对寻址 | 0x104 = *0x104 |
| (Ea) | M[R[Ea]] | 间接寻址 | (%eax)= *eax |
| Imm(Ea) | M[Imm+R[Ea]] | (基址+偏移量)寻址 | 4(%eax) = *(4+eax) |
| (Ea,Eb) | M[R[Ea]+R[Eb]] | 变址 | (%eax,%ebx) = *(eax+ebx) |
| Imm(Ea,Eb) | M[Imm+R[Ea]+R[Eb]] | 寻址 | 9(%eax,%ebx)= *(9+eax+ebx) |
| (,Ea,s) | M[R[Ea]*s] | 伸缩化变址寻址 | (,%eax,4)= (eax4) |
| Imm(,Ea,s) | M[Imm+R[Ea]*s] | 伸缩化变址寻址 | 0xfc(,%eax,4)= (0xfc+eax4) |
| (Ea,Eb,s) | M(R[Ea]+R[Eb]*s) | 伸缩化变址寻址 | (%eax,%ebx,4) = (eax+ebx4) |
| Imm(Ea,Eb,s) | M(Imm+R[Ea]+R[Eb]*s) | 伸缩化变址寻址 | 8(%eax,%ebx,4) = (8+eax+ebx4) |
注:M[xx]表示在存储器中xx地址的值,R[xx]表示寄存器xx的值,这种表示方法将寄存器、内存都看出一个大数组的形式。
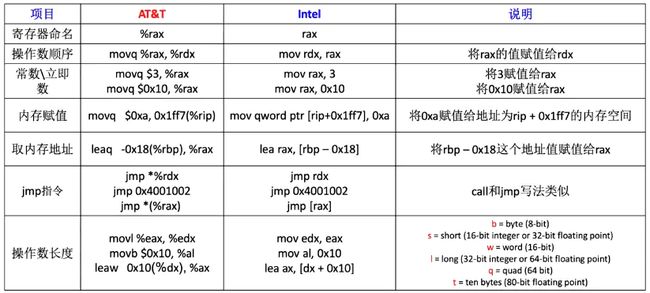
汇编根据编译器的不同,有2种书写格式:
(1)Intel : Windows派系
(2)AT&T: Unix派系
下面简单介绍一下两者的不同。
下面就来认识一下常用的指令。
下面我们以给出的是AT&T汇编的写法,这两种写法有如下不同。
1、数据传送指令
将数据从一个地方传送到另外一个地方。
1.1 mov指令
我们在介绍mov指令时介绍的全一些,因为mov指令是出现频率最高的指令,助记符中的后缀也比较多。
mov指令的形式有3种,如下:
mov #普通的move指令
movs #符号扩展的move指令,将源操作数进行符号扩展并传送到一个64位寄存器或存储单元中。movs就表示符号扩展
movz #零扩展的move指令,将源操作数进行零扩展后传送到一个64位寄存器或存储单元中。movz就表示零扩展
mov指令后有一个字母可表示操作数大小,形式如下:
movb #完成1个字节的复制
movw #完成2个字节的复制
movl #完成4个字节的复制
movq #完成8个字节的复制
还有一个指令,如下:
movabsq I,R
与movq有所不同,它是将一个64位的值直接存到一个64位寄存器中。
movs指令的形式如下:
movsbw #作符号扩展的1字节复制到2字节
movsbl #作符号扩展的1字节复制到4字节
movsbq #作符号扩展的1字节复制到8字节
movswl #作符号扩展的2字节复制到4字节
movswq #作符号扩展的2字节复制到8字节
movslq #作符号扩展的4字节复制到8字节
movz指令的形式如下:
movzbw #作0扩展的1字节复制到2字节
movzbl #作0扩展的1字节复制到4字节
movzbq #作0扩展的1字节复制到8字节
movzwl #作0扩展的2字节复制到4字节
movzwq #作0扩展的2字节复制到8字节
movzlq #作0扩展的4字节复制到8字节
举个例子如下:
movl %ecx,%eax
movl (%ecx),%eax
第一条指令将寄存器ecx中的值复制到eax寄存器;第二条指令将ecx寄存器中的数据作为地址访问内存,并将内存上的数据加载到eax寄存器中。
1.2 cmov指令
cmov指令的格式如下:
cmovxx
其中xx代表一个或者多个字母,这些字母表示将触发传送操作的条件。条件取决于 EFLAGS 寄存器的当前值。
eflags寄存器中各个们如下图所示。
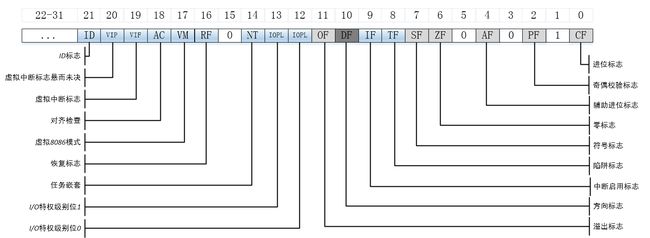
其中与cmove指令相关的eflags寄存器中的位有CF(数学表达式产生了进位或者借位) 、OF(整数值无穷大或者过小)、PF(寄存器包含数学操作造成的错误数据)、SF(结果为正不是负)和ZF(结果为零)。
下表为无符号条件传送指令。
| 指令对 | 描述 | eflags状态 |
| cmova/cmovnbe | 大于/不小于或等于 | (CF或ZF)=0 |
| cmovae/cmovnb | 大于或者等于/不小于 | CF=0 |
| cmovnc | 无进位 | CF=0 |
| cmovb/cmovnae | 大于/不小于或等于 | CF=1 |
| cmovc | 进位 | CF=1 |
| cmovbe/cmovna | 小于或者等于/不大于 | (CF或ZF)=1 |
| cmove/cmovz | 等于/零 | ZF=1 |
| cmovne/cmovnz | 不等于/不为零 | ZF=0 |
| cmovp/cmovpe | 奇偶校验/偶校验 | PF=1 |
| cmovnp/cmovpo | 非奇偶校验/奇校验 | PF=0 |
无符号条件传送指令依靠进位、零和奇偶校验标志来确定两个操作数之间的区别。
下表为有符号条件传送指令。
| 指令对 | 描述 | eflags状态 |
| cmovge/cmovnl | 大于或者等于/不小于 | (SF异或OF)=0 |
| cmovl/cmovnge | 大于/不大于或者等于 | (SF异或OF)=1 |
| cmovle/cmovng | 小于或者等于/不大于 | ((SF异或OF)或ZF)=1 |
| cmovo | 溢出 | OF=1 |
| cmovno | 未溢出 | OF=0 |
| cmovs | 带符号(负) | SF=1 |
| cmovns | 无符号(非负) | SF=0 |
举个例子如下:
// 将vlaue数值加载到ecx寄存器中
movl value,%ecx
// 使用cmp指令比较ecx和ebx这两个寄存器中的值,具体就是用ecx减去ebx然后设置eflags
cmp %ebx,%ecx
// 如果ecx的值大于ebx,使用cmova指令设置ebx的值为ecx中的值
cmova %ecx,%ebx
注意AT&T汇编的第1个操作数在前,第2个操作数在后。
1.3 push和pop指令
push指令的形式如下表所示。
| 指令 | 操作数 | 描述 |
| push | I/R/M | PUSH 指令首先减少 ESP 的值,再将源操作数复制到堆栈。操作数是 16 位的,则 ESP 减 2,操作数是 32 位的,则 ESP 减 4 |
| pusha | 指令按序(AX、CX、DX、BX、SP、BP、SI 和 DI)将 16 位通用寄存器压入堆栈。 | |
| pushad | 指令按照 EAX、ECX、EDX、EBX、ESP(执行 PUSHAD 之前的值)、EBP、ESI 和 EDI 的顺序,将所有 32 位通用寄存器压入堆栈。 |
pop指令的形式如下表所示。
| 指令 | 操作数 | 描述 |
| pop | R/M | 指令首先把 ESP 指向的堆栈元素内容复制到一个 16 位或 32 位目的操作数中,再增加 ESP 的值。如果操作数是 16 位的,ESP 加 2,如果操作数是 32 位的,ESP 加 4 |
| popa | 指令按照相反顺序将同样的寄存器弹出堆栈 | |
| popad | 指令按照相反顺序将同样的寄存器弹出堆栈 |
1.4 xchg与xchgl
这个指令用于交换操作数的值,交换指令XCHG是两个寄存器,寄存器和内存变量之间内容的交换指令,两个操作数的数据类型要相同,可以是一个字节,也可以是一个字,也可以是双字。格式如下:
xchg R/M,R/M
xchgl I/R,I/R、
两个操作数不能同时为内存变量。xchgl指令是一条古老的x86指令,作用是交换两个寄存器或者内存地址里的4字节值,两个值不能都是内存地址,他不会设置条件码。
1.5 lea
lea计算源操作数的实际地址,并把结果保存到目标操作数,而目标操作数必须为通用寄存器。格式如下:
lea M,R
lea(Load Effective Address)指令将地址加载到寄存器。
举例如下:
movl 4(%ebx),%eax
leal 4(%ebx),%eax
第一条指令表示将ebx寄存器中存储的值加4后得到的结果作为内存地址进行访问,并将内存地址中存储的数据加载到eax寄存器中。
第二条指令表示将ebx寄存器中存储的值加4后得到的结果作为内存地址存放到eax寄存器中。
再举个例子,如下:
leaq a(b, c, d), %rax
计算地址a + b + c * d,然后把最终地址载到寄存器rax中。可以看到只是简单的计算,不引用源操作数里的寄存器。这样的完全可以把它当作乘法指令使用。
2、算术运算指令
下面介绍对有符号整数和无符号整数进行操作的基本运算指令。
2.1 add与adc指令
指令的格式如下:
add I/R/M,R/M
adc I/R/M,R/M
指令将两个操作数相加,结果保存在第2个操作数中。
对于第1条指令来说,由于寄存器和存储器都有位宽限制,因此在进行加法运算时就有可能发生溢出。运算如果溢出的话,标志寄存器eflags中的进位标志(Carry Flag,CF)就会被置为1。
对于第2条指令来说,利用adc指令再加上进位标志eflags.CF,就能在32位的机器上进行64位数据的加法运算。
常规的算术逻辑运算指令只要将原来IA-32中的指令扩展到64位即可。如addq就是四字相加。
2.2 sub与sbb指令
指令的格式如下:
sub I/R/M,R/M
sbb I/R/M,R/M
指令将用第2个操作数减去第1个操作数,结果保存在第2个操作数中。
2.3 imul与mul指令
指令的格式如下:
imul I/R/M,R
mul I/R/M,R
将第1个操作数和第2个操作数相乘,并将结果写入第2个操作数中,如果第2个操作数空缺,默认为eax寄存器,最终完整的结果将存储到edx:eax中。
第1条指令执行有符号乘法,第2条指令执行无符号乘法。
2.4 idiv与div指令
指令的格式如下:
div R/M
idiv R/M
第1条指令执行无符号除法,第2条指令执行有符号除法。被除数由edx寄存器和eax寄存器拼接而成,除数由指令的第1个操作数指定,计算得到的商存入eax寄存器,余数存入edx寄存器。如下图所示。
edx:eax
------------ = eax(商)... edx(余数)
寄存器
运算时被除数、商和除数的数据的位宽是不一样的,如下表表示了idiv指令和div指令使用的寄存器的情况。
| 数据的位宽 | 被除数 | 除数 | 商 | 余数 |
| 8位 | ax | 指令第1个操作数 | al | ah |
| 16位 | dx:ax | 指令第1个操作数 | ax | dx |
| 32位 | edx:eax | 指令第1个操作数 | eax | edx |
idiv指令和div指令通常是对位宽2倍于除数的被除数进行除法运算的。例如对于x86-32机器来说,通用寄存器的倍数为32位,1个寄存器无法容纳64位的数据,所以 edx存放被除数的高32位,而eax寄存器存放被除数的低32位。
所以在进行除法运算时,必须将设置在eax寄存器中的32位数据扩展到包含edx寄存器在内的64位,即有符号进行符号扩展,无符号数进行零扩展。
对edx进行符号扩展时可以使用cltd(AT&T风格写法)或cdq(Intel风格写法)。指令的格式如下:
cltd // 将eax寄存器中的数据符号扩展到edx:eax
cltd将eax寄存器中的数据符号扩展到edx:eax。
2.5 incl与decl指令
指令的格式如下:
inc R/M
dec R/M
将指令第1个操作数指定的寄存器或内存位置存储的数据加1或减1。
2.6 negl指令
指令的格式如下:
neg R/M
neg指令将第1个操作数的符号进行反转。
3、位运算指令
3.1 andl、orl与xorl指令
指令的格式如下:
and I/R/M,R/M
or I/R/M,R/M
xor I/R/M,R/M
and指令将第2个操作数与第1个操作数进行按位与运算,并将结果写入第2个操作数;
or指令将第2个操作数与第1个操作数进行按位或运算,并将结果写入第2个操作数;
xor指令将第2个操作数与第1个操作数进行按位异或运算,并将结果写入第2个操作数;
3.2 not指令
指令的格式如下:
not R/M
将操作数按位取反,并将结果写入操作数中。
3.3 sal、sar、shr指令
指令的格式如下:
sal I/%cl,R/M #算术左移
sar I/%cl,R/M #算术右移
shl I/%cl,R/M #逻辑左移
shr I/%cl,R/M #逻辑右移
sal指令将第2个操作数按照第1个操作数指定的位数进行左移操作,并将结果写入第2个操作数中。移位之后空出的低位补0。指令的第1个操作数只能是8位的立即数或cl寄存器,并且都是只有低5位的数据才有意义,高于或等于6位数将导致寄存器中的所有数据被移走而变得没有意义。
sar指令将第2个操作数按照第1个操作数指定的位数进行右移操作,并将结果写入第2个操作数中。移位之后的空出进行符号扩展。和sal指令一样,sar指令的第1个操作数也必须为8位的立即数或cl寄存器,并且都是只有低5位的数据才有意义。
shl指令和sall指令的动作完全相同,没有必要区分。
shr令将第2个操作数按照第1个操作数指定的位数进行右移操作,并将结果写入第2个操作数中。移位之后的空出进行零扩展。和sal指令一样,shr指令的第1个操作数也必须为8位的立即数或cl寄存器,并且都是只有低5位的数据才有意义。
4、流程控制指令
4.1 jmp指令
指令的格式如下:
jmp I/R
jmp指令将程序无条件跳转到操作数指定的目的地址。jmp指令可以视作设置指令指针(eip寄存器)的指令。目的地址也可以是星号后跟寄存器的栈,这种方式为间接函数调用。例如:
jmp *%eax
将程序跳转至eax所含地址。
4.2 条件跳转指令
条件跳转指令的格式如下:
Jcc 目的地址
其中cc指跳转条件,如果为真,则程序跳转到目的地址;否则执行下一条指令。相关的条件跳转指令如下表所示。
| 指令 | 跳转条件 | 描述 | 指令 | 跳转条件 | 描述 |
| jz | ZF=1 | 为0时跳转 | jbe | CF=1或ZF=1 | 大于或等于时跳转 |
| jnz | ZF=0 | 不为0时跳转 | jnbe | CF=0且ZF=0 | 小于或等于时跳转 |
| je | ZF=1 | 相等时跳转 | jg | ZF=0且SF=OF | 大于时跳转 |
| jne | ZF=0 | 不相等时跳转 | jng | ZF=1或SF!=OF | 不大于时跳转 |
| ja | CF=0且ZF=0 | 大于时跳转 | jge | SF=OF | 大于或等于时跳转 |
| jna | CF=1或ZF=1 | 不大于时跳转 | jnge | SF!=OF | 小于或等于时跳转 |
| jae | CF=0 | 大于或等于时跳转 | jl | SF!=OF | 小于时跳转 |
| jnae | CF=1 | 小于或等于时跳转 | jnl | SF=OF | 不小于时跳转 |
| jb | CF=1 | 大于时跳转 | jle | ZF=1或SF!=OF | 小于或等于时跳转 |
| jnb | CF=0 | 不大于时跳转 | jnle | ZF=0且SF=OF | 大于或等于时跳转 |
4.3 cmp指令
cmp指令的格式如下:
cmp I/R/M,R/M
cmp指令通过比较第2个操作数减去第1个操作数的差,根据结果设置标志寄存器eflags中的标志位。cmp指令和sub指令类似,不过cmp指令不会改变操作数的值。
操作数和所设置的标志位之间的关系如表所示。
| 操作数的关系 | CF | ZF | OF |
| 第1个操作数小于第2个操作数 | 0 | 0 | SF |
| 第1个操作数等于第2个操作数 | 0 | 1 | 0 |
| 第1个操作数大于第2个操作数 | 1 | 0 | not SF |
4.4 test指令
指令的格式如下:
test I/R/M,R/M
指令通过比较第1个操作数与第2个操作数的逻辑与,根据结果设置标志寄存器eflags中的标志位。test指令本质上和and指令相同,只是test指令不会改变操作数的值。
test指令执行后CF与OF通常会被清零,并根据运算结果设置ZF和SF。运算结果为零时ZF被置为1,SF和最高位的值相同。
举个例子如下:
test指令同时能够检查几个位。假设想要知道 AL 寄存器的位 0 和位 3 是否置 1,可以使用如下指令:
test al,00001001b #掩码为0000 1001,测试第0和位3位是否为1
从下面的数据集例子中,可以推断只有当所有测试位都清 0 时,零标志位才置 1:
0 0 1 0 0 1 0 1 <- 输入值
0 0 0 0 1 0 0 1 <- 测试值
0 0 0 0 0 0 0 1 <- 结果:ZF=0
0 0 1 0 0 1 0 0 <- 输入值
0 0 0 0 1 0 0 1 <- 测试值
0 0 0 0 0 0 0 0 <- 结果:ZF=1
test指令总是清除溢出和进位标志位,其修改符号标志位、零标志位和奇偶标志位的方法与 AND 指令相同。
4.5 sete指令
根据eflags中的状态标志(CF,SF,OF,ZF和PF)将目标操作数设置为0或1。这里的目标操作数指向一个字节寄存器(也就是8位寄存器,如AL,BL,CL)或内存中的一个字节。状态码后缀(cc)指明了将要测试的条件。
获取标志位的指令的格式如下:
setcc R/M
指令根据标志寄存器eflags的值,将操作数设置为0或1。
setcc中的cc和Jcc中的cc类似,可参考表。
4.6 call指令
指令的格式如下:
call I/R/M
call指令会调用由操作数指定的函数。call指令会将指令的下一条指令的地址压栈,再跳转到操作数指定的地址,这样函数就能通过跳转到栈上的地址从子函数返回了。相当于
push %eip
jmp addr
先压入指令的下一个地址,然后跳转到目标地址addr。
4.7 ret指令
指令的格式如下:
ret
ret指令用于从子函数中返回。X86架构的Linux中是将函数的返回值设置到eax寄存器并返回的。相当于如下指令:
popl %eip
将call指令压栈的“call指令下一条指令的地址”弹出栈,并设置到指令指针中。这样程序就能正确地返回子函数的地方。
从物理上来说,CALL 指令将其返回地址压入堆栈,再把被调用过程的地址复制到指令指针寄存器。当过程准备返回时,它的 RET 指令从堆栈把返回地址弹回到指令指针寄存器。
4.8 enter指令
enter指令通过初始化ebp和esp寄存器来为函数建立函数参数和局部变量所需要的栈帧。相当于
push %rbp
mov %rsp,%rbp
4.9 leave指令
leave通过恢复ebp与esp寄存器来移除使用enter指令建立的栈帧。相当于
mov %rbp, %rsp
pop %rbp
将栈指针指向帧指针,然后pop备份的原帧指针到%ebp
5.0 int指令
指令的格式如下:
int I
引起给定数字的中断。这通常用于系统调用以及其他内核界面。
5、标志操作
eflags寄存器的各个标志位如下图所示。
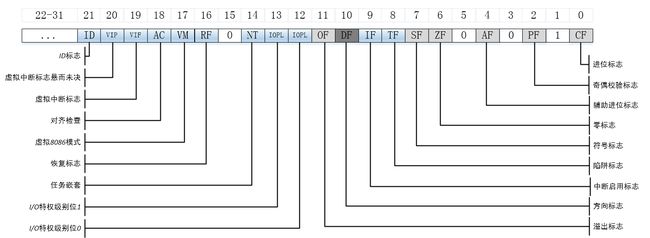
操作eflags寄存器标志的一些指令如下表所示。
| 指令 | 操作数 | 描述 |
| pushfd | R | PUSHFD 指令把 32 位 EFLAGS 寄存器内容压入堆栈 |
| popfd | R | POPFD 指令则把栈顶单元内容弹出到 EFLAGS 寄存器 |
| cld | 将eflags.df设置为0 |
第19篇-加载与存储指令(1)
TemplateInterpreterGenerator::generate_all()函数会生成许多例程(也就是机器指令片段,英文叫Stub),包括调用set_entry_points_for_all_bytes()函数生成各个字节码对应的例程。
最终会调用到TemplateInterpreterGenerator::generate_and_dispatch()函数,调用堆栈如下:
TemplateTable::geneate() templateTable_x86_64.cpp
TemplateInterpreterGenerator::generate_and_dispatch() templateInterpreter.cpp
TemplateInterpreterGenerator::set_vtos_entry_points() templateInterpreter_x86_64.cpp
TemplateInterpreterGenerator::set_short_entry_points() templateInterpreter.cpp
TemplateInterpreterGenerator::set_entry_points() templateInterpreter.cpp
TemplateInterpreterGenerator::set_entry_points_for_all_bytes() templateInterpreter.cpp
TemplateInterpreterGenerator::generate_all() templateInterpreter.cpp
InterpreterGenerator::InterpreterGenerator() templateInterpreter_x86_64.cpp
TemplateInterpreter::initialize() templateInterpreter.cpp
interpreter_init() interpreter.cpp
init_globals() init.cpp
调用堆栈上的许多函数在之前介绍过,每个字节码都会指定一个generator函数,通过Template的_gen属性保存。在TemplateTable::generate()函数中调用。_gen会生成每个字节码对应的机器指令片段,所以非常重要。
首先看一个非常简单的nop字节码指令。这个指令的模板属性如下:
// Java spec bytecodes ubcp|disp|clvm|iswd in out generator argument
def(Bytecodes::_nop , ____|____|____|____, vtos, vtos, nop , _ );
nop字节码指令的生成函数generator不会生成任何机器指令,所以nop字节码指令对应的汇编代码中只有栈顶缓存的逻辑。调用set_vtos_entry_points()函数生成的汇编代码如下:
// aep
0x00007fffe1027c00: push %rax
0x00007fffe1027c01: jmpq 0x00007fffe1027c30
// fep
0x00007fffe1027c06: sub $0x8,%rsp
0x00007fffe1027c0a: vmovss %xmm0,(%rsp)
0x00007fffe1027c0f: jmpq 0x00007fffe1027c30
// dep
0x00007fffe1027c14: sub $0x10,%rsp
0x00007fffe1027c18: vmovsd %xmm0,(%rsp)
0x00007fffe1027c1d: jmpq 0x00007fffe1027c30
// lep
0x00007fffe1027c22: sub $0x10,%rsp
0x00007fffe1027c26: mov %rax,(%rsp)
0x00007fffe1027c2a: jmpq 0x00007fffe1027c30
// bep cep sep iep
0x00007fffe1027c2f: push %rax
// vep
// 接下来为取指逻辑,开始的地址为0x00007fffe1027c30
可以看到,由于tos_in为vtos,所以如果是aep、bep、cep、sep与iep时,直接使用push指令将%rax中存储的栈顶缓存值压入表达式栈中。对于fep、dep与lep来说,在栈上开辟对应内存的大小,然后将寄存器中的值存储到表达式的栈顶上,与push指令的效果相同。
在set_vtos_entry_points()函数中会调用generate_and_dispatch()函数生成nop指令的机器指令片段及取下一条字节码指令的机器指令片段。nop不会生成任何机器指令,而取指的片段如下:
// movzbl 将做了零扩展的字节传送到双字,地址为0x00007fffe1027c30
0x00007fffe1027c30: movzbl 0x1(%r13),%ebx
0x00007fffe1027c35: inc %r13
0x00007fffe1027c38: movabs $0x7ffff73ba4a0,%r10
// movabs的源操作数只能是立即数或标号(本质还是立即数),目的操作数是寄存器
0x00007fffe1027c42: jmpq *(%r10,%rbx,8)
r13指向当前要取的字节码指令的地址。那么%r13+1就是跳过了当前的nop指令而指向了下一个字节码指令的地址,然后执行movzbl指令将所指向的Opcode加载到%ebx中。
通过jmpq的跳转地址为%r10+%rbx*8,关于这个跳转地址在前面详细介绍过,这里不再介绍。
我们讲解了nop指令,把栈顶缓存的逻辑和取指逻辑又回顾了一遍,对于每个字节码指令来说都会有有栈顶缓存和取指逻辑,后面在介绍字节码指令时就不会再介绍这2个逻辑。
加载与存储相关操作的字节码指令如下表所示。
| 字节码 | 助词符 | 指令含义 |
| 0x00 | nop | 什么都不做 |
| 0x01 | aconst_null | 将null推送至栈顶 |
| 0x02 | iconst_m1 | 将int型-1推送至栈顶 |
| 0x03 | iconst_0 | 将int型0推送至栈顶 |
| 0x04 | iconst_1 | 将int型1推送至栈顶 |
| 0x05 | iconst_2 | 将int型2推送至栈顶 |
| 0x06 | iconst_3 | 将int型3推送至栈顶 |
| 0x07 | iconst_4 | 将int型4推送至栈顶 |
| 0x08 | iconst_5 | 将int型5推送至栈顶 |
| 0x09 | lconst_0 | 将long型0推送至栈顶 |
| 0x0a | lconst_1 | 将long型1推送至栈顶 |
| 0x0b | fconst_0 | 将float型0推送至栈顶 |
| 0x0c | fconst_1 | 将float型1推送至栈顶 |
| 0x0d | fconst_2 | 将float型2推送至栈顶 |
| 0x0e | dconst_0 | 将double型0推送至栈顶 |
| 0x0f | dconst_1 | 将double型1推送至栈顶 |
| 0x10 | bipush | 将单字节的常量值(-128~127)推送至栈顶 |
| 0x11 | sipush | 将一个短整型常量值(-32768~32767)推送至栈顶 |
| 0x12 | ldc | 将int、float或String型常量值从常量池中推送至栈顶 |
| 0x13 | ldc_w | 将int,、float或String型常量值从常量池中推送至栈顶(宽索引) |
| 0x14 | ldc2_w | 将long或double型常量值从常量池中推送至栈顶(宽索引) |
| 0x15 | iload | 将指定的int型本地变量推送至栈顶 |
| 0x16 | lload | 将指定的long型本地变量推送至栈顶 |
| 0x17 | fload | 将指定的float型本地变量推送至栈顶 |
| 0x18 | dload | 将指定的double型本地变量推送至栈顶 |
| 0x19 | aload | 将指定的引用类型本地变量推送至栈顶 |
| 0x1a | iload_0 | 将第一个int型本地变量推送至栈顶 |
| 0x1b | iload_1 | 将第二个int型本地变量推送至栈顶 |
| 0x1c | iload_2 | 将第三个int型本地变量推送至栈顶 |
| 0x1d | iload_3 | 将第四个int型本地变量推送至栈顶 |
| 0x1e | lload_0 | 将第一个long型本地变量推送至栈顶 |
| 0x1f | lload_1 | 将第二个long型本地变量推送至栈顶 |
| 0x20 | lload_2 | 将第三个long型本地变量推送至栈顶 |
| 0x21 | lload_3 | 将第四个long型本地变量推送至栈顶 |
| 0x22 | fload_0 | 将第一个float型本地变量推送至栈顶 |
| 0x23 | fload_1 | 将第二个float型本地变量推送至栈顶 |
| 0x24 | fload_2 | 将第三个float型本地变量推送至栈顶 |
| 0x25 | fload_3 | 将第四个float型本地变量推送至栈顶 |
| 0x26 | dload_0 | 将第一个double型本地变量推送至栈顶 |
| 0x27 | dload_1 | 将第二个double型本地变量推送至栈顶 |
| 0x28 | dload_2 | 将第三个double型本地变量推送至栈顶 |
| 0x29 | dload_3 | 将第四个double型本地变量推送至栈顶 |
| 0x2a | aload_0 | 将第一个引用类型本地变量推送至栈顶 |
| 0x2b | aload_1 | 将第二个引用类型本地变量推送至栈顶 |
| 0x2c | aload_2 | 将第三个引用类型本地变量推送至栈顶 |
| 0x2d | aload_3 | 将第四个引用类型本地变量推送至栈顶 |
| 0x2e | iaload | 将int型数组指定索引的值推送至栈顶 |
| 0x2f | laload | 将long型数组指定索引的值推送至栈顶 |
| 0x30 | faload | 将float型数组指定索引的值推送至栈顶 |
| 0x31 | daload | 将double型数组指定索引的值推送至栈顶 |
| 0x32 | aaload | 将引用型数组指定索引的值推送至栈顶 |
| 0x33 | baload | 将boolean或byte型数组指定索引的值推送至栈顶 |
| 0x34 | caload | 将char型数组指定索引的值推送至栈顶 |
| 0x35 | saload | 将short型数组指定索引的值推送至栈顶 |
| 0x36 | istore | 将栈顶int型数值存入指定本地变量 |
| 0x37 | lstore | 将栈顶long型数值存入指定本地变量 |
| 0x38 | fstore | 将栈顶float型数值存入指定本地变量 |
| 0x39 | dstore | 将栈顶double型数值存入指定本地变量 |
| 0x3a | astore | 将栈顶引用型数值存入指定本地变量 |
| 0x3b | istore_0 | 将栈顶int型数值存入第一个本地变量 |
| 0x3c | istore_1 | 将栈顶int型数值存入第二个本地变量 |
| 0x3d | istore_2 | 将栈顶int型数值存入第三个本地变量 |
| 0x3e | istore_3 | 将栈顶int型数值存入第四个本地变量 |
| 0x3f | lstore_0 | 将栈顶long型数值存入第一个本地变量 |
| 0x40 | lstore_1 | 将栈顶long型数值存入第二个本地变量 |
| 0x41 | lstore_2 | 将栈顶long型数值存入第三个本地变量 |
| 0x42 | lstore_3 | 将栈顶long型数值存入第四个本地变量 |
| 0x43 | fstore_0 | 将栈顶float型数值存入第一个本地变量 |
| 0x44 | fstore_1 | 将栈顶float型数值存入第二个本地变量 |
| 0x45 | fstore_2 | 将栈顶float型数值存入第三个本地变量 |
| 0x46 | fstore_3 | 将栈顶float型数值存入第四个本地变量 |
| 0x47 | dstore_0 | 将栈顶double型数值存入第一个本地变量 |
| 0x48 | dstore_1 | 将栈顶double型数值存入第二个本地变量 |
| 0x49 | dstore_2 | 将栈顶double型数值存入第三个本地变量 |
| 0x4a | dstore_3 | 将栈顶double型数值存入第四个本地变量 |
| 0x4b | astore_0 | 将栈顶引用型数值存入第一个本地变量 |
| 0x4c | astore_1 | 将栈顶引用型数值存入第二个本地变量 |
| 0x4d | astore_2 | 将栈顶引用型数值存入第三个本地变量 |
| 0x4e | astore_3 | 将栈顶引用型数值存入第四个本地变量 |
| 0x4f | iastore | 将栈顶int型数值存入指定数组的指定索引位置 |
| 0x50 | lastore | 将栈顶long型数值存入指定数组的指定索引位置 |
| 0x51 | fastore | 将栈顶float型数值存入指定数组的指定索引位置 |
| 0x52 | dastore | 将栈顶double型数值存入指定数组的指定索引位置 |
| 0x53 | aastore | 将栈顶引用型数值存入指定数组的指定索引位置 |
| 0x54 | bastore | 将栈顶boolean或byte型数值存入指定数组的指定索引位置 |
| 0x55 | castore | 将栈顶char型数值存入指定数组的指定索引位置 |
| 0x56 | sastore | 将栈顶short型数值存入指定数组的指定索引位置 |
| 0xc4 | wide | 扩充局部变量表的访问索引的指令 |
我们不会对每个字节码指令都查看对应的机器指令片段的逻辑(其实是反编译机器指令片段为汇编后,通过查看汇编理解执行逻辑),有些指令的逻辑是类似的,这里只选择几个典型的介绍。
1、压栈类型的指令
(1)aconst_null指令
aconst_null表示将null送到栈顶,模板定义如下:
def(Bytecodes::_aconst_null , ____|____|____|____, vtos, atos, aconst_null , _ );
指令的汇编代码如下:
// xor 指令在两个操作数的对应位之间进行逻辑异或操作,并将结果存放在目标操作数中
// 第1个操作数和第2个操作数相同时,执行异或操作就相当于执行清零操作
xor %eax,%eax
由于tos_out为atos,所以栈顶的结果是缓存在%eax寄存器中的,只对%eax寄存器执行xor操作即可。
(2)iconst_m1指令
iconst_m1表示将-1压入栈内,模板定义如下:
def(Bytecodes::_iconst_m1 , ____|____|____|____, vtos, itos, iconst , -1 );
生成的机器指令经过反汇编后,得到的汇编代码如下:
mov $0xffffffff,%eax
其它的与iconst_m1字节码指令类似的字节码指令,如iconst_0、iconst_1等,模板定义如下:
def(Bytecodes::_iconst_m1 , ____|____|____|____, vtos, itos, iconst , -1 );
def(Bytecodes::_iconst_0 , ____|____|____|____, vtos, itos, iconst , 0 );
def(Bytecodes::_iconst_1 , ____|____|____|____, vtos, itos, iconst , 1 );
def(Bytecodes::_iconst_2 , ____|____|____|____, vtos, itos, iconst , 2 );
def(Bytecodes::_iconst_3 , ____|____|____|____, vtos, itos, iconst , 3 );
def(Bytecodes::_iconst_4 , ____|____|____|____, vtos, itos, iconst , 4 );
def(Bytecodes::_iconst_5 , ____|____|____|____, vtos, itos, iconst , 5 );
可以看到,生成函数都是同一个TemplateTable::iconst()函数。
iconst_0的汇编代码如下:
xor %eax,%eax
iconst_@(@为1、2、3、4、5)的字节码指令对应的汇编代码如下:
// aep
0x00007fffe10150a0: push %rax
0x00007fffe10150a1: jmpq 0x00007fffe10150d0
// fep
0x00007fffe10150a6: sub $0x8,%rsp
0x00007fffe10150aa: vmovss %xmm0,(%rsp)
0x00007fffe10150af: jmpq 0x00007fffe10150d0
// dep
0x00007fffe10150b4: sub $0x10,%rsp
0x00007fffe10150b8: vmovsd %xmm0,(%rsp)
0x00007fffe10150bd: jmpq 0x00007fffe10150d0
// lep
0x00007fffe10150c2: sub $0x10,%rsp
0x00007fffe10150c6: mov %rax,(%rsp)
0x00007fffe10150ca: jmpq 0x00007fffe10150d0
// bep/cep/sep/iep
0x00007fffe10150cf: push %rax
// vep
0x00007fffe10150d0 mov $0x@,%eax // @代表1、2、3、4、5
如果看过我之前写的文章,那么如上的汇编代码应该能看懂,我在这里就不再做过多介绍了。
(3)bipush
bipush 将单字节的常量值推送至栈顶。模板定义如下:
def(Bytecodes::_bipush , ubcp|____|____|____, vtos, itos, bipush , _ );
指令的汇编代码如下:
// %r13指向字节码指令的地址,偏移1位
// 后取出1个字节的内容存储到%eax中
movsbl 0x1(%r13),%eax
由于tos_out为itos,所以将单字节的常量值存储到%eax中,这个寄存器是专门用来进行栈顶缓存的。
(4)sipush
sipush将一个短整型常量值推送到栈顶,模板定义如下:
def(Bytecodes::_bipush , ubcp|____|____|____, vtos, itos, bipush , _ );
生成的汇编代码如下:
// movzwl传送做了符号扩展字到双字
movzwl 0x1(%r13),%eax
// bswap 以字节为单位,把32/64位寄存器的值按照低和高的字节交换
bswap %eax
// (算术右移)指令将目的操作数进行算术右移
sar $0x10,%eax
Java中的短整型占用2个字节,所以需要对32位寄存器%eax进行一些操作。由于字节码采用大端存储,所以在处理时统一变换为小端存储。
2、存储类型指令
istore指令会将int类型数值存入指定索引的本地变量表,模板定义如下:
def(Bytecodes::_istore , ubcp|____|clvm|____, itos, vtos, istore , _ );
生成函数为TemplateTable::istore(),生成的汇编代码如下:
movzbl 0x1(%r13),%ebx
neg %rbx
mov %eax,(%r14,%rbx,8)
由于栈顶缓存tos_in为itos,所以直接将%eax中的值存储到指定索引的本地变量表中。
模板中指定ubcp,因为生成的汇编代码中会使用%r13,也就是字节码指令指针。
其它的istore、dstore等字节码指令的汇编代码逻辑也类似,这里不过多介绍。
第20篇-加载与存储指令之ldc与_fast_aldc指令(2)
ldc指令将int、float、或者一个类、方法类型或方法句柄的符号引用、还可能是String型常量值从常量池中推送至栈顶。
这一篇介绍一个虚拟机规范中定义的一个字节码指令ldc,另外还有一个虚拟机内部使用的字节码指令_fast_aldc。ldc指令可以加载String、方法类型或方法句柄的符号引用,但是如果要加载String、方法类型或方法句柄的符号引用,则会在类连接过程中重写ldc字节码指令为虚拟机内部使用的字节码指令_fast_aldc。下面我们详细介绍ldc指令如何加载int、float类型和类类型的数据,以及_fast_aldc加载String、方法类型或方法句柄,还有为什么要进行字节码重写等问题。
1、ldc字节码指令
ldc指令将int、float或String型常量值从常量池中推送至栈顶。模板的定义如下:
def(Bytecodes::_ldc , ubcp|____|clvm|____, vtos, vtos, ldc , false );
ldc字节码指令的格式如下:
// index是一个无符号的byte类型数据,指明当前类的运行时常量池的索引
ldc index
调用生成函数TemplateTable::ldc(bool wide)。函数生成的汇编代码如下:
第1部分代码:
// movzbl指令负责拷贝一个字节,并用0填充其目
// 的操作数中的其余各位,这种扩展方式叫"零扩展"
// ldc指定的格式为ldc index,index为一个字节
0x00007fffe1028530: movzbl 0x1(%r13),%ebx // 加载index到%ebx
// %rcx指向缓存池首地址、%rax指向类型数组_tags首地址
0x00007fffe1028535: mov -0x18(%rbp),%rcx
0x00007fffe1028539: mov 0x10(%rcx),%rcx
0x00007fffe102853d: mov 0x8(%rcx),%rcx
0x00007fffe1028541: mov 0x10(%rcx),%rax
// 从_tags数组获取操作数类型并存储到%edx中
0x00007fffe1028545: movzbl 0x4(%rax,%rbx,1),%edx
// $0x64代表JVM_CONSTANT_UnresolvedClass,比较,如果类还没有链接,
// 则直接跳转到call_ldc
0x00007fffe102854a: cmp $0x64,%edx
0x00007fffe102854d: je 0x00007fffe102855d // call_ldc
// $0x67代表JVM_CONSTANT_UnresolvedClassInError,也就是如果类在
// 链接过程中出现错误,则跳转到call_ldc
0x00007fffe102854f: cmp $0x67,%edx
0x00007fffe1028552: je 0x00007fffe102855d // call_ldc
// $0x7代表JVM_CONSTANT_Class,表示如果类已经进行了连接,则
// 跳转到notClass
0x00007fffe1028554: cmp $0x7,%edx
0x00007fffe1028557: jne 0x00007fffe10287c0 // notClass
// 类在没有连接或连接过程中出错,则执行如下的汇编代码
// -- call_ldc --
下面看一下调用call_VM(rax, CAST_FROM_FN_PTR(address, InterpreterRuntime::ldc), c_rarg1)函数生成的汇编代码,CAST_FROM_FN_PTR是宏,宏扩展后为( (address)((address_word)(InterpreterRuntime::ldc)) )。
在调用call_VM()函数时,传递的参数如下:
- %rax现在存储类型数组首地址,不过传入是为了接收调用函数的结果值
- adr是InterpreterRuntime::ldc()函数首地址
- c_rarg1用rdi寄存器存储wide值,这里为0,表示为没有加wide前缀的ldc指令生成汇编代码
生成的汇编代码如下:
第2部分:
// 将wide的值移到%esi寄存器,为后续
// 调用InterpreterRuntime::ldc()函数准备第2个参数
0x00007fffe102855d: mov $0x0,%esi
// 调用MacroAssembler::call_VM()函数,通过此函数来调用HotSpot VM中用
// C++编写的函数,通过这个C++编写的函数来调用InterpreterRuntime::ldc()函数
0x00007fffe1017542: callq 0x00007fffe101754c
0x00007fffe1017547: jmpq 0x00007fffe10175df // 跳转到E1
// 调用MacroAssembler::call_VM_helper()函数
// 将栈顶存储的返回地址设置到%rax中,也就是将存储地址0x00007fffe1017547
// 的栈的slot地址设置到%rax中
0x00007fffe101754c: lea 0x8(%rsp),%rax
// 调用InterpreterMacroAssembler::call_VM_base()函数
// 存储bcp到栈中特定位置
0x00007fffe1017551: mov %r13,-0x38(%rbp)
// 调用MacroAssembler::call_VM_base()函数
// 将r15中的值移动到rdi寄存器中,也就是为函数调用准备第一个参数
0x00007fffe1017555: mov %r15,%rdi
// 只有解释器才必须要设置fp
// 将last_java_fp保存到JavaThread类的last_java_fp属性中
0x00007fffe1017558: mov %rbp,0x200(%r15)
// 将last_java_sp保存到JavaThread类的last_java_sp属性中
0x00007fffe101755f: mov %rax,0x1f0(%r15)
// ... 省略调用MacroAssembler::call_VM_leaf_base()函数
// 重置JavaThread::last_java_sp与JavaThread::last_java_fp属性的值
0x00007fffe1017589: movabs $0x0,%r10
0x00007fffe1017593: mov %r10,0x1f0(%r15)
0x00007fffe101759a: movabs $0x0,%r10
0x00007fffe10175a4: mov %r10,0x200(%r15)
// check for pending exceptions (java_thread is set upon return)
0x00007fffe10175ab: cmpq $0x0,0x8(%r15)
// 如果没有异常则直接跳转到ok
0x00007fffe10175b3: je 0x00007fffe10175be
// 如果有异常则跳转到StubRoutines::forward_exception_entry()获取的例程入口
0x00007fffe10175b9: jmpq 0x00007fffe1000420
// -- ok --
// 将JavaThread::vm_result属性中的值存储到%rax寄存器中并清空vm_result属性的值
0x00007fffe10175be: mov 0x250(%r15),%rax
0x00007fffe10175c5: movabs $0x0,%r10
0x00007fffe10175cf: mov %r10,0x250(%r15)
// 结束调用MacroAssembler::call_VM_base()函数
// 恢复bcp与locals
0x00007fffe10175d6: mov -0x38(%rbp),%r13
0x00007fffe10175da: mov -0x30(%rbp),%r14
// 结束调用MacroAssembler::call_VM_helper()函数
0x00007fffe10175de: retq
// 结束调用MacroAssembler::call_VM()函数
下面详细解释如下汇编的意思。
call指令相当于如下两条指令:
push %eip
jmp addr
而ret指令相当于:
pop %eip
所以如上汇编代码:
0x00007fffe1017542: callq 0x00007fffe101754c
0x00007fffe1017547: jmpq 0x00007fffe10175df // 跳转
...
0x00007fffe10175de: retq
调用callq指令将jmpq的地址压入了表达式栈,也就是压入了返回地址x00007fffe1017547,这样当后续调用retq时,会跳转到jmpq指令执行,而jmpq又跳转到了0x00007fffe10175df地址处的指令执行。
通过调用MacroAssembler::call_VM()函数来调用HotSpot VM中用的C++编写的函数,call_VM()函数还会调用如下函数:
MacroAssembler::call_VM_helper
InterpreterMacroAssembler::call_VM_base()
MacroAssembler::call_VM_base()
MacroAssembler::call_VM_leaf_base()
在如上几个函数中,最重要的就是在MacroAssembler::call_VM_base()函数中保存rsp、rbp的值到JavaThread::last_java_sp与JavaThread::last_java_fp属性中,然后通过MacroAssembler::call_VM_leaf_base()函数生成的汇编代码来调用C++编写的InterpreterRuntime::ldc()函数,如果调用InterpreterRuntime::ldc()函数有可能破坏rsp和rbp的值(其它的%r13、%r14等的寄存器中的值也有可能破坏,所以在必要时保存到栈中,在调用完成后再恢复,这样这些寄存器其实就算的上是调用者保存的寄存器了),所以为了保证rsp、rbp,将这两个值存储到线程中,在线程中保存的这2个值对于栈展开非常非常重要,后面我们会详细介绍。
由于如上汇编代码会解释执行,在解释执行过程中会调用C++函数,所以C/C++栈和Java栈都混在一起,这为我们查找带来了一定的复杂度。
调用的MacroAssembler::call_VM_leaf_base()函数生成的汇编代码如下:
第3部分汇编代码:
// 调用MacroAssembler::call_VM_leaf_base()函数
0x00007fffe1017566: test $0xf,%esp // 检查对齐
// %esp对齐的操作,跳转到 L
0x00007fffe101756c: je 0x00007fffe1017584
// %esp没有对齐时的操作
0x00007fffe1017572: sub $0x8,%rsp
0x00007fffe1017576: callq 0x00007ffff66a22a2 // 调用函数,也就是调用InterpreterRuntime::ldc()函数
0x00007fffe101757b: add $0x8,%rsp
0x00007fffe101757f: jmpq 0x00007fffe1017589 // 跳转到E2
// -- L --
// %esp对齐的操作
0x00007fffe1017584: callq 0x00007ffff66a22a2 // 调用函数,也就是调用InterpreterRuntime::ldc()函数
// -- E2 --
// 结束调用
MacroAssembler::call_VM_leaf_base()函数
在如上这段汇编中会真正调用C++函数InterpreterRuntime::ldc(),由于这是一个C++函数,所以在调用时,如果要传递参数,则要遵守C++调用约定,也就是前6个参数都放到固定的寄存器中。这个函数需要2个参数,分别为thread和wide,已经分别放到了%rdi和%rax寄存器中了。InterpreterRuntime::ldc()函数的实现如下:
// ldc负责将数值常量或String常量值从常量池中推送到栈顶
IRT_ENTRY(void, InterpreterRuntime::ldc(JavaThread* thread, bool wide))
ConstantPool* pool = method(thread)->constants();
int index = wide ? get_index_u2(thread, Bytecodes::_ldc_w) : get_index_u1(thread, Bytecodes::_ldc);
constantTag tag = pool->tag_at(index);
Klass* klass = pool->klass_at(index, CHECK);
oop java_class = klass->java_mirror(); // java.lang.Class通过oop来表示
thread->set_vm_result(java_class);
IRT_END
函数将查找到的、当前正在解释执行的方法所属的类存储到JavaThread类的vm_result属性中。我们可以回看第2部分汇编代码,会将vm_result属性的值设置到%rax中。
接下来继续看TemplateTable::ldc(bool wide)函数生成的汇编代码,此时已经通过调用call_VM()函数生成了调用InterpreterRuntime::ldc()这个C++的汇编,调用完成后值已经放到了%rax中。
// -- E1 --
0x00007fffe10287ba: push %rax // 将调用的结果存储到表达式中
0x00007fffe10287bb: jmpq 0x00007fffe102885e // 跳转到Done
// -- notClass --
// $0x4表示JVM_CONSTANT_Float
0x00007fffe10287c0: cmp $0x4,%edx
0x00007fffe10287c3: jne 0x00007fffe10287d9 // 跳到notFloat
// 当ldc字节码指令加载的数为float时执行如下汇编代码
0x00007fffe10287c5: vmovss 0x58(%rcx,%rbx,8),%xmm0
0x00007fffe10287cb: sub $0x8,%rsp
0x00007fffe10287cf: vmovss %xmm0,(%rsp)
0x00007fffe10287d4: jmpq 0x00007fffe102885e // 跳转到Done
// -- notFloat --
// 当ldc字节码指令加载的为非float,也就是int类型数据时通过push加入表达式栈
0x00007fffe1028859: mov 0x58(%rcx,%rbx,8),%eax
0x00007fffe102885d: push %rax
// -- Done --
由于ldc指令除了加载String外,还可能加载int和float,如果是int,直接调用push压入表达式栈中,如果是float,则在表达式栈上开辟空间,然后移到到这个开辟的slot中存储。注意,float会使用%xmm0寄存器。
2、fast_aldc虚拟机内部字节码指令
下面介绍_fast_aldc指令,这个指令是虚拟机内部使用的指令而非虚拟机规范定义的指令。_fast_aldc指令的模板定义如下:
def(Bytecodes::_fast_aldc , ubcp|____|clvm|____, vtos, atos, fast_aldc , false );
生成函数为TemplateTable::fast_aldc(bool wide),这个函数生成的汇编代码如下:
// 调用InterpreterMacroAssembler::get_cache_index_at_bcp()函数生成
// 获取字节码指令的操作数,这个操作数已经指向了常量池缓存项的索引,在字节码重写
// 阶段已经进行了字节码重写
0x00007fffe10243d0: movzbl 0x1(%r13),%edx
// 调用InterpreterMacroAssembler::load_resolved_reference_at_index()函数生成
// shl表示逻辑左移,相当于乘4,因为ConstantPoolCacheEntry的大小为4个字
0x00007fffe10243d5: shl $0x2,%edx
// 获取Method*
0x00007fffe10243d8: mov -0x18(%rbp),%rax
// 获取ConstMethod*
0x00007fffe10243dc: mov 0x10(%rax),%rax
// 获取ConstantPool*
0x00007fffe10243e0: mov 0x8(%rax),%rax
// 获取ConstantPool::_resolved_references属性的值,这个值
// 是一个指向对象数组的指针
0x00007fffe10243e4: mov 0x30(%rax),%rax
// JNIHandles::resolve(obj)
0x00007fffe10243e8: mov (%rax),%rax
// 从_resolved_references数组指定的下标索引处获取oop,先进行索引偏移
0x00007fffe10243eb: add %rdx,%rax
// 要在%rax上加0x10,是因为数组对象的头大小为2个字,加上后
// %rax就指向了oop
0x00007fffe10243ee: mov 0x10(%rax),%eax
获取_resolved_references属性的值,涉及到的2个属性在ConstantPool类中的定义如下:
// Array of resolved objects from the constant pool and map from resolved
// object index to original constant pool index
jobject _resolved_references; // jobject是指针类型
Array* _reference_map;
关于_resolved_references指向的其实是Object数组。在ConstantPool::initialize_resolved_references()函数中初始化这个属性。调用链如下:
ConstantPool::initialize_resolved_references() constantPool.cpp
Rewriter::make_constant_pool_cache() rewriter.cpp
Rewriter::Rewriter() rewriter.cpp
Rewriter::rewrite() rewriter.cpp
InstanceKlass::rewrite_class() instanceKlass.cpp
InstanceKlass::link_class_impl() instanceKlass.cpp
后续如果需要连接ldc等指令时,可能会调用如下函数:(我们只讨论ldc加载String类型数据的问题,所以我们只看往_resolved_references属性中放入表示String的oop的逻辑,MethodType与MethodHandle将不再介绍,有兴趣的可自行研究)
oop ConstantPool::string_at_impl(
constantPoolHandle this_oop,
int which,
int obj_index,
TRAPS
) {
oop str = this_oop->resolved_references()->obj_at(obj_index);
if (str != NULL)
return str;
Symbol* sym = this_oop->unresolved_string_at(which);
str = StringTable::intern(sym, CHECK_(NULL));
this_oop->string_at_put(which, obj_index, str);
return str;
}
void string_at_put(int which, int obj_index, oop str) {
// 获取类型为jobject的_resolved_references属性的值
objArrayOop tmp = resolved_references();
tmp->obj_at_put(obj_index, str);
}
在如上函数中向_resolved_references数组中设置缓存的值。
大概的思路就是:如果ldc加载的是字符串,那么尽量通过_resolved_references数组中一次性找到表示字符串的oop,否则要通过原常量池下标索引找到Symbol实例(Symbol实例是HotSpot VM内部使用的、用来表示字符串),根据Symbol实例生成对应的oop,然后通过常量池缓存下标索引设置到_resolved_references中。当下次查找时,通过这个常量池缓存下标缓存找到表示字符串的oop。
获取到_resolved_references属性的值后接着看生成的汇编代码,如下:
// ...
// %eax中存储着表示字符串的oop
0x00007fffe1024479: test %eax,%eax
// 如果已经获取到了oop,则跳转到resolved
0x00007fffe102447b: jne 0x00007fffe1024481
// 没有获取到oop,需要进行连接操作,0xe5是_fast_aldc的Opcode
0x00007fffe1024481: mov $0xe5,%edx
调用call_VM()函数生成的汇编代码如下:
// 调用InterpreterRuntime::resolve_ldc()函数
0x00007fffe1024486: callq 0x00007fffe1024490
0x00007fffe102448b: jmpq 0x00007fffe1024526
// 将%rdx中的ConstantPoolCacheEntry项存储到第1个参数中
// 调用MacroAssembler::call_VM_helper()函数生成
0x00007fffe1024490: mov %rdx,%rsi
// 将返回地址加载到%rax中
0x00007fffe1024493: lea 0x8(%rsp),%rax
// 调用call_VM_base()函数生成
// 保存bcp
0x00007fffe1024498: mov %r13,-0x38(%rbp)
// 调用MacroAssembler::call_VM_base()函数生成
// 将r15中的值移动到c_rarg0(rdi)寄存器中,也就是为函数调用准备第一个参数
0x00007fffe102449c: mov %r15,%rdi
// Only interpreter should have to set fp 只有解释器才必须要设置fp
0x00007fffe102449f: mov %rbp,0x200(%r15)
0x00007fffe10244a6: mov %rax,0x1f0(%r15)
// 调用MacroAssembler::call_VM_leaf_base()生成
0x00007fffe10244ad: test $0xf,%esp
0x00007fffe10244b3: je 0x00007fffe10244cb
0x00007fffe10244b9: sub $0x8,%rsp
0x00007fffe10244bd: callq 0x00007ffff66b27ac
0x00007fffe10244c2: add $0x8,%rsp
0x00007fffe10244c6: jmpq 0x00007fffe10244d0
0x00007fffe10244cb: callq 0x00007ffff66b27ac
0x00007fffe10244d0: movabs $0x0,%r10
// 结束调用MacroAssembler::call_VM_leaf_base()
0x00007fffe10244da: mov %r10,0x1f0(%r15)
0x00007fffe10244e1: movabs $0x0,%r10
// 检查是否有异常发生
0x00007fffe10244eb: mov %r10,0x200(%r15)
0x00007fffe10244f2: cmpq $0x0,0x8(%r15)
// 如果没有异常发生,则跳转到ok
0x00007fffe10244fa: je 0x00007fffe1024505
// 有异常发生,则跳转到StubRoutines::forward_exception_entry()
0x00007fffe1024500: jmpq 0x00007fffe1000420
// ---- ok ----
// 将JavaThread::vm_result属性中的值存储到oop_result寄存器中并清空vm_result属性的值
0x00007fffe1024505: mov 0x250(%r15),%rax
0x00007fffe102450c: movabs $0x0,%r10
0x00007fffe1024516: mov %r10,0x250(%r15)
// 结果调用MacroAssembler::call_VM_base()函数
// 恢复bcp和locals
0x00007fffe102451d: mov -0x38(%rbp),%r13
0x00007fffe1024521: mov -0x30(%rbp),%r14
// 结束调用InterpreterMacroAssembler::call_VM_base()函数
// 结束调用MacroAssembler::call_VM_helper()函数
0x00007fffe1024525: retq
// 结束调用MacroAssembler::call_VM()函数,回到
// TemplateTable::fast_aldc()函数继续看生成的代码,只
// 定义了resolved点
// ---- resolved ----
调用的InterpreterRuntime::resolve_ldc()函数的实现如下:
IRT_ENTRY(void, InterpreterRuntime::resolve_ldc(
JavaThread* thread,
Bytecodes::Code bytecode)
) {
ResourceMark rm(thread);
methodHandle m (thread, method(thread));
Bytecode_loadconstant ldc(m, bci(thread));
oop result = ldc.resolve_constant(CHECK);
thread->set_vm_result(result);
}
IRT_END
这个函数会调用一系列的函数,相关调用链如下:
ConstantPool::string_at_put() constantPool.hpp
ConstantPool::string_at_impl() constantPool.cpp
ConstantPool::resolve_constant_at_impl() constantPool.cpp
ConstantPool::resolve_cached_constant_at() constantPool.hpp
Bytecode_loadconstant::resolve_constant() bytecode.cpp
InterpreterRuntime::resolve_ldc() interpreterRuntime.cpp
其中ConstantPool::string_at_impl()函数在前面已经详细介绍过。
调用的resolve_constant()函数的实现如下:
oop Bytecode_loadconstant::resolve_constant(TRAPS) const {
int index = raw_index();
ConstantPool* constants = _method->constants();
if (has_cache_index()) {
return constants->resolve_cached_constant_at(index, THREAD);
} else {
return constants->resolve_constant_at(index, THREAD);
}
}
调用的resolve_cached_constant_at()或resolve_constant_at()函数的实现如下:
oop resolve_cached_constant_at(int cache_index, TRAPS) {
constantPoolHandle h_this(THREAD, this);
return resolve_constant_at_impl(h_this, _no_index_sentinel, cache_index, THREAD);
}
oop resolve_possibly_cached_constant_at(int pool_index, TRAPS) {
constantPoolHandle h_this(THREAD, this);
return resolve_constant_at_impl(h_this, pool_index, _possible_index_sentinel, THREAD);
}
调用的resolve_constant_at_impl()函数的实现如下:
oop ConstantPool::resolve_constant_at_impl(
constantPoolHandle this_oop,
int index,
int cache_index,
TRAPS
) {
oop result_oop = NULL;
Handle throw_exception;
if (cache_index == _possible_index_sentinel) {
cache_index = this_oop->cp_to_object_index(index);
}
if (cache_index >= 0) {
result_oop = this_oop->resolved_references()->obj_at(cache_index);
if (result_oop != NULL) {
return result_oop;
}
index = this_oop->object_to_cp_index(cache_index);
}
jvalue prim_value; // temp used only in a few cases below
int tag_value = this_oop->tag_at(index).value();
switch (tag_value) {
// ...
case JVM_CONSTANT_String:
assert(cache_index != _no_index_sentinel, "should have been set");
if (this_oop->is_pseudo_string_at(index)) {
result_oop = this_oop->pseudo_string_at(index, cache_index);
break;
}
result_oop = string_at_impl(this_oop, index, cache_index, CHECK_NULL);
break;
// ...
}
if (cache_index >= 0) {
Handle result_handle(THREAD, result_oop);
MonitorLockerEx ml(this_oop->lock());
oop result = this_oop->resolved_references()->obj_at(cache_index);
if (result == NULL) {
this_oop->resolved_references()->obj_at_put(cache_index, result_handle());
return result_handle();
} else {
return result;
}
} else {
return result_oop;
}
}
通过常量池的tags数组判断,如果常量池下标index处存储的是JVM_CONSTANT_String常量池项,则调用string_at_impl()函数,这个函数在之前已经介绍过,会根据表示字符串的Symbol实例创建出表示字符串的oop。在ConstantPool::resolve_constant_at_impl()函数中得到oop后就存储到ConstantPool::_resolved_references属性中,最后返回这个oop,这正是ldc需要的oop。
通过重写fast_aldc字节码指令,达到了通过少量指令就直接获取到oop的目的,而且oop是缓存的,所以字符串常量在HotSpot VM中的表示唯一,也就是只有一个oop表示。
C++函数约定返回的值会存储到%rax中,根据_fast_aldc字节码指令的模板定义可知,tos_out为atos,所以后续并不需要进一步操作。
HotSpot VM会在类的连接过程中重写某些字节码,如ldc字节码重写为fast_aldc,还有常量池的tags类型数组、常量池缓存等内容在《深入剖析Java虚拟机:源码剖析与实例详解》中详细介绍过,这里不再介绍。
第21篇-加载与存储指令之ldc与_fast_aldc指令(3)
iload会将int类型的本地变量推送至栈顶。模板定义如下:
def(Bytecodes::_iload , ubcp|____|clvm|____, vtos, itos, iload , _ );
iload指令的格式如下:
iload index
index是一个无符号byte类型整数,指向局部变量表的索引值。
生成函数为TemplateTable::iload(),反编译后的汇编代码如下:
// 将%ebx指向下一条字节码指令的首地址
0x00007fffe1028d30: movzbl 0x2(%r13),%ebx
// $0x15为_iload指令的操作码值
0x00007fffe1028d35: cmp $0x15,%ebx
// 当下一条指令为iload时,直接跳转到done
0x00007fffe1028d38: je 0x00007fffe1028deb // done
// 0xdf为_fast_iload指令的操作码值
0x00007fffe1028d3e: cmp $0xdf,%ebx
// 将_fast_iload2指令移动到%ecx
0x00007fffe1028d44: mov $0xe0,%ecx
0x00007fffe1028d49: je 0x00007fffe1028d5a // rewrite
// 0x34为_caload指令的操作码
// _caload指令表示从数组中加载一个char类型数据到操作数栈
0x00007fffe1028d4b: cmp $0x34,%ebx
// 将_fast_icaload移动到%ecx中
0x00007fffe1028d4e: mov $0xe1,%ecx
0x00007fffe1028d53: je 0x00007fffe1028d5a // rewrite
// 将_fast_iload移动到%ecx中
0x00007fffe1028d55: mov $0xdf,%ecx
// -- rewrite --
// 调用patch_bytecode()函数
// 重写为fast版本,因为%cl中存储的是字节码的fast版本,%ecx的8位叫%cl
0x00007fffe1028de7: mov %cl,0x0(%r13)
// -- done --
// 获取字节码指令的操作数,这个操作数为本地变量表的索引
0x00007fffe1028deb: movzbl 0x1(%r13),%ebx
0x00007fffe1028df0: neg %rbx
// 通过本地变量表索引从本地变量表中加载值到%eax中,
// %eax中存储的就是栈顶缓存值,所以不需要压入栈内
0x00007fffe1028df3: mov (%r14,%rbx,8),%eax
执行的逻辑如下:

假设现在有个方法的字节码指令流为连接3个iload指令,这3个iload指令前后都为非iload指令。那么重写的过程如下:

汇编代码在第一次执行时,如果判断最后一个_iload之后是非_iload指令,则会重写最后一个_iload指令为_fast_iload;第二次执行时,当第2个字节码指令为_iload,而之后接着判断为_fast_iload时,会更新第2个_iload为_fast_iload2。
执行_fast_iload和执行_fast_iload2都可以提高程序执行的效率,_fast_icaload指令也一样,下面详细介绍一下这几个指令。
1、_fast_iload指令
_fast_iload会将int类型的本地变量推送至栈顶。模板定义如下:
def(Bytecodes::_fast_iload , ubcp|____|____|____, vtos, itos, fast_iload , _ );
生成函数为TemplateTable::fast_iload() ,汇编代码如下:
0x00007fffe1023f90: movzbl 0x1(%r13),%ebx
0x00007fffe1023f95: neg %rbx
0x00007fffe1023f98: mov (%r14,%rbx,8),%eax
汇编代码很简单,这里不再过多说。
执行_fast_iload指令与执行_iload指令相比,不用再进行之前汇编介绍的那么多判断,也没有重写的逻辑,所以会提高执行效率。
2、_fast_iload2指令
_fast_iload2会将int类型的本地变量推送至栈顶。模板定义如下:
def(Bytecodes::_fast_iload2 , ubcp|____|____|____, vtos, itos, fast_iload2 , _ );
生成函数为TemplateTable::fast_iload2() ,汇编代码如下:
0x00007fffe1024010: movzbl 0x1(%r13),%ebx
0x00007fffe1024015: neg %rbx
0x00007fffe1024018: mov (%r14,%rbx,8),%eax
0x00007fffe102401c: push %rax
0x00007fffe102401d: movzbl 0x3(%r13),%ebx
0x00007fffe1024022: neg %rbx
0x00007fffe1024025: mov (%r14,%rbx,8),%eax
可以看到,此指令就相当于连续执行了2次iload指令,省去了指令跳转,所以效率要高一些。
3、_fast_icaload指令
caload指令表示从数组中加载一个char类型数据到操作数栈。
_fast_icaload会将char类型数组指定索引的值推送至栈顶。模板定义如下:
def(Bytecodes::_fast_icaload , ubcp|____|____|____, vtos, itos, fast_icaload , _ );
生成函数为TemplateTable::fast_icaload(),生成的汇编代码如下:
0x00007fffe1024090: movzbl 0x1(%r13),%ebx
0x00007fffe1024095: neg %rbx
// %eax中存储着index
0x00007fffe1024098: mov (%r14,%rbx,8),%eax
// %rdx中存储着arrayref
0x00007fffe102409c: pop %rdx
// 将一个双字扩展后送到一个四字中,%rax中存储着index
0x00007fffe102409d: movslq %eax,%rax
// %rdx指向数组对象的首地址,偏移0xc后获取length属性的值
0x00007fffe10240a0: cmp 0xc(%rdx),%eax
0x00007fffe10240a3: mov %eax,%ebx
// 如果数组索引index等于数组的长度或大于数组长度时,那么跳转
// 到_throw_ArrayIndexOutOfBoundsException_entry抛出异常
0x00007fffe10240a5: jae 0x00007fffe100ff20
// 在指定数组arrayref中加载指定索引处index的值
0x00007fffe10240ab: movzwl 0x10(%rdx,%rax,2),%eax
可以看到,此指令省去了指令跳转,所以效率要高一些。
由于字数限制,《模板解释器解释执行Java字节码指令(下)》将在下篇中释出