AI是游戏的灵魂,是人物的智商,是让玩家觉得游戏是否幼稚的重要判断功能,下面我将介绍国外流行,国内不行的,ai算法。
主要介绍 Flocking 和 Reciprocal Velocity Obstacles。
序言:历史
大家都知道 寻路算法,这些年,自从 XX大神 网上 发布了 A*算法 之后,国内 大白小白 ,只要是个人 都开始 使用他,
一时间,A* 寻路 是 做游戏 的 标准,也是面试 最常问的 话题。
A* 寻路 也是有发展历史的,最早是 Dijkstra算法,

后来 发明了启发式 搜索,BFS,他效率最快

但启发式搜索也有 智障的时候

然后 1968年,大神 把 常用算法和启发式算法 结合起来,发明 了A*算法。
好像是 时间的停止,又好像是 国人的 愚昧无知,A*算法被国人定义为 最终的 寻路方案,但历史的脚步不会停止。
之后的 几十年,国外对A*算法做了深入的加强
迭代深化、动态衡量、带宽搜索、动态A*与终身计划A*
今天我将推开历史的进程,寻找A*的未来
A* 算法之后,是动态A*寻路。大家都会对动态A*寻路提出各种想法,
有些人说,我可以让 运动物体 碰撞时候 再次 A*。但如果多个运动物体,碰撞太多,是否效率会影响
还有人说,遇到 动态 碰撞物体,我让A* 只做 一定 距离的 寻路,那我又问,如果短距离范围 会让运动物体不能合理指向 最终位置,那就是事与愿违。
所以此时 XX大神提出了 Flocking。
运动物体好比就是一辆辆 行驶在 马路上的汽车,他们都有GPS导航仪 进行路径设定。
但突然 有车辆 发生车祸,那么车祸会造成 汽车 失去控制,偏离轨道,这个时候,运动的指挥权 不再是 方向盘。
而是 其他车辆 碰撞后 产生的 轨迹。等碰撞结束后,汽车会继续 打开GPS 导航仪,开始寻路。
这个过程 我们发现,在多车 撞击的时候,汽车并没有在 这个时候 寻路,他会头昏,是的,他只做 物理运动,一阵晕眩后,他恢复神智,重新寻路。
这样的 过程,A*次数 开销会很小。
提出Flocking思想后,聪明可爱的 程序员(这里只单指 外国人),发现,他们可以用来做 群体寻路。
XX大神 提出Reciprocal Velocity Obstacles算法,有一个运动物体来进行A*寻路,其他物体跟着他,称为 领导者模式。
因为他们之间不会重叠,用来做即时战略游戏非常棒。(帝国时代,星际争霸 )等一系列的 策略类型游戏相继推出受到了广大玩家的青睐。
正文:开启
unity 的A*starPathfindingProject插件,就集成了Reciprocal Velocity Obstacles,我们简称RVO.
可能是版权问题,3.51后,作者自己重新编写了RVO的代码,大家不需要改动。
这是作者在文档上提出的
-
Note
- The local avoidance system was previously disabled because of licensing issues. This is no longer the case as the whole system has been rewritten in a new way. The exposed APIs for the previous system and the new one are almost identical.
- 国人有些人喜欢 以讹传讹搬弄是非,我就不想说他们了,永远是小白的命!
简单的使用下RVO的功能。
新建一个GameObject,选择菜单
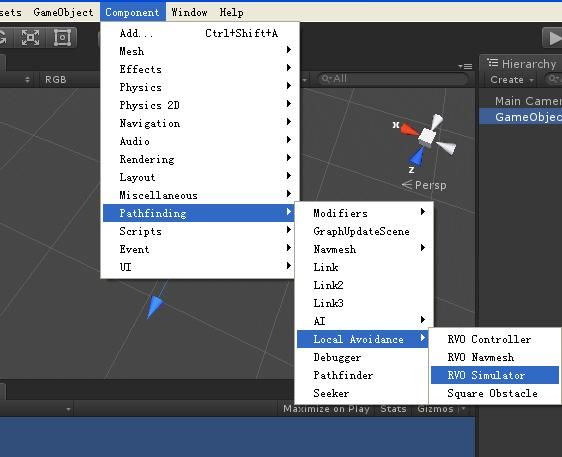
这个是说,我同意 使用 RVO这个功能了。。
按照上图 选择 RVONavmesh。说明,他可以 穿透 范围数据内的 物体,为啥要穿透物体。
因为有时候,在相互撞车的时候,会发生死路的可能,我们不能让他卡死在那吧,所以,有必要让他造假一下,当然这种情况很少,也是情非得已。
接下来,我们做一个运动物体,让他加载 插件 第一个RVOController。
这个意思是所,我可以 不要 碰撞盒子,我不需要重力影响,我也可以碰撞了。当然移动按照这个类的方法来执行。
RVOController的参数和使用方法,以及优化,我下一节来说。大家可以先看看我做的demo来感受下。
分享一个 国外 制作的 案例,我研究的方向 和他是 一样的,大家可以看这个demo 。
。
具体代码,我整合到 框架中。