数据分析之pandas_20题_16-20
数据分析之pandas_20题
-
- 系列文章
- 写在前面的话
- pandas是什么?
- 引入库
- 16.画图
- 17. 对Series对象再加工
- 18. 写入文件和读取文件
- 19. 时间序列索引操作
- 5. 可用在jupyter notebook中的透视表工具
系列文章
数据分析之pandas_20题_1-5
数据分析之pandas_20题_6-10
数据分析之pandas_20题_11-15
写在前面的话
这边笔记主要记录一些在数据分析过程中使用到的pandas模块的方法,希望可以帮到需要的人。
pandas 20题并不是简单的20个题目哟,是20中不同的需求。
pandas是什么?
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。常用语数据分析处理
引入库
代码如下(示例):
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
16.画图
pandas可以直接进行画图,实际是调用了matplotlib库的画图方法
准备数据
df = pd.DataFrame(
np.random.randint(10,100,(100,5)),
columns=[i for i in 'abcde']
)
df['label'] = [random.sample(['A','B','C'],1)[0] for i in range(100)]
结果

画图
df.plot(figsize=(16,10),y='a',kind='bar')
结果
df.plot()的参数很多,均是关键字参数,一般常用的有 x : 横坐标 默认是索引 y : 纵坐标 默认全部数值型类型列 kind : 图类型
- ‘line’ : line plot (default) 折线图,默认是折线图
- ‘bar’ : vertical bar plot 柱状图
- ‘barh’ : horizontal bar plot 水平柱状图
- ‘hist’ : histogram 直方图
- ‘box’ : boxplot 箱型图
- ‘kde’ : Kernel Density Estimation plot
- ‘density’ : same as ‘kde’
- ‘area’ : area plot 面积图
- ‘pie’ : pie plot 饼图
- ‘scatter’ : scatter plot 散点图
- ‘hexbin’ : hexbin plot.
figsize: 图大小 (宽,高) 元组类型 title :图的标题 grid :网格
df.plot.bar(y=‘a’,figsize=(16,10)) 与 df.plot(figsize=(16,10),y=‘a’,kind=‘bar’) 的结果完全一致
df.plot(kind='kde',title='kde 图',grid='--')
# kde图是将数据做了标准化处理,消除了各个维度间的量纲
结果
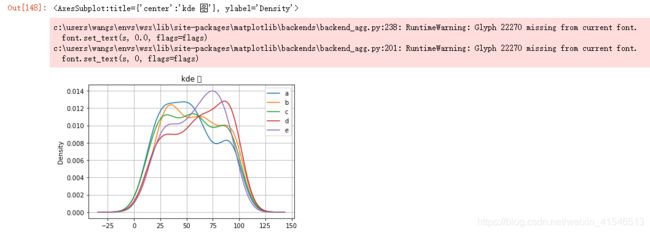
DataFrame绘图一般会出现这样的警告
当不想看到警告时,可以设置(此处是以jupyter notebook运行代码时的设置)
import warnings
warnings.filterwarnings('ignore')
当我们的图标中有中文字体时,可能不显示或者乱码,我们需要设置字体
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei','SimSun'] # 设置中文字体
plt.rcParams['axes.unicode_minus']=False
df.plot(kind='box',grid='-.',title='箱型图')
plt.show() # 直接显示图形,不再显示图标对象的存储信息
结果

17. 对Series对象再加工
有时,我们拿到的数据并不能直接进行分析,需要进一步处理,或者进行其他属性的加工
如下面的这种数据:
# 次数在造数,无需关注
i = 0
data = {
'工作':[],'薪资':[]}
while i < 100:
a,b = random.sample(range(7,15),k=2)
if a > b:
continue
i += 1
data['薪资'].append('%sk-%sk'%(a,b))
data['工作'].append(f.job())
df11 = pd.DataFrame(data)
结果

当我们要分析薪资情况时发现,薪资是字符串类型的,如果我们想要对薪资进行描述性分析时,需要转换成数值型
df11['薪资'].apply(lambda x:(int(x.split('-')[0][:-1]) + int(x.split('-')[-1][:-1]))/2)
# 对 薪资 列进行apply操作,传入的参数是函数,这个函数会作用于Series中的每一个元素
结果
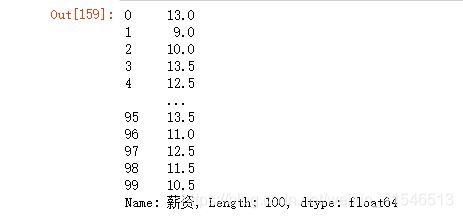
pandas还提供了针对字符串类型处理的api
Series.str.字符串方法
可以使用所有字符串的方法
# split 方法
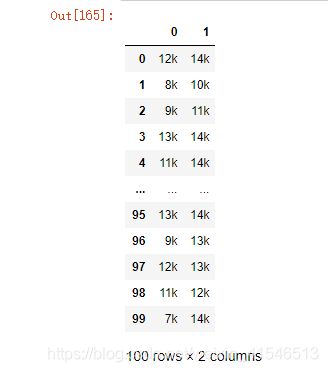
df11['薪资'].str.split('-',expand=True)
# expand 是设置是否分列显示
结果
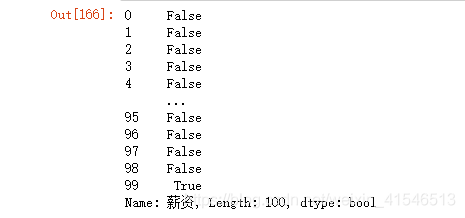
startwith方法
df11['薪资'].str.startswith('7')
结果
当类型是时间的,可以使用Series.dt.时间相关方法进行处理
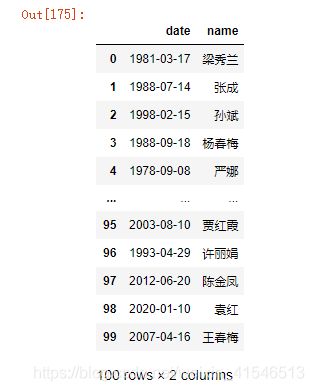
df4 = pd.DataFrame({
'date':[f.date() for i in range(100)],
'name':[f.name() for i in range(100)]
})
结果

此时的date列是object类型
df4.info()
结果

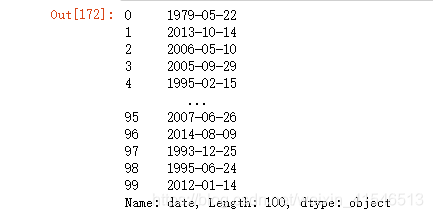
将字符串格式的日期时间转成pandas的时间类型
df4['date'] = pd.to_datetime(df4['date'])
结果
此时date列已经是时间类型了
df4.info()
结果

日期
df4['date'].dt.date
一周中的第几天
在这里插入代码片
结果
一周中的第几天
df4['date'].dt.weekday
结果
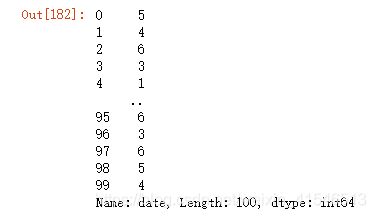
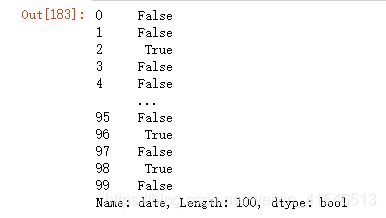
是不是闰年
df4['date'].dt.is_leap_year
结果
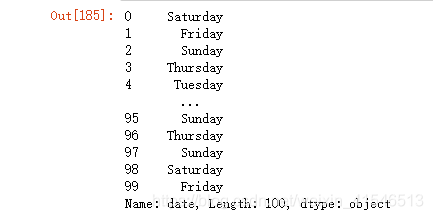
星期几
df4['date'].dt.day_name()
结果
其他方法不再介绍,有需要可以查看pandas文档
18. 写入文件和读取文件
pandas支持多种文件格式的写入写出,此处只介绍excel和SQL,其他文件的写入写出基本类似
Excel
df11.to_excel('./工作.xlsx') # 写入文件
df = pd.read_excel('./工作.xlsx',usecols=['工作','薪资']) # 读取文件
df结果

SQL
此处以写入写出sqlite为例
# 导入sqlalchemy模块的创建引擎连接的方法
from sqlalchemy import create_engine
engine = create_engine('sqlite://',echo=False)
df5.to_sql(name='job',con=engine,if_exists='replace',index=False)
# 注意,索引转成默认数值型才可以
读取sql
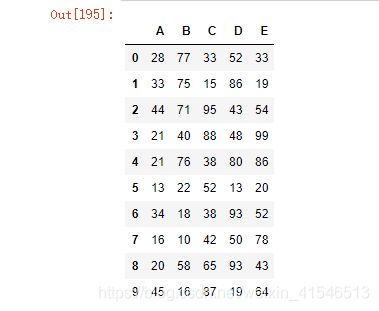
sql = 'select * from job where A < 50 limit 10'
pd.read_sql(sql=sql,con=engine)
此时可以根据SQL语句进行数据读取,并返回DataFrame对象
结果
19. 时间序列索引操作
我们经常遇到的数据是以时间为索引的,当需要数据与时间关系时,要对时间进行转换,例如 日转月 月转季,我们可以使用apply等api操作,同时pandas也提供了很多时间序列索引的方法,可以更快的处理时间序列
注意,这里说的是时间序列索引,PeriodIndex
df5 = pd.DataFrame(
data = np.random.randint(10,100,(100,5)),
index=pd.PeriodIndex(pd.date_range(start='2020-01-01',freq='D',periods=100)),
columns=list('ABCDE')
)
结果
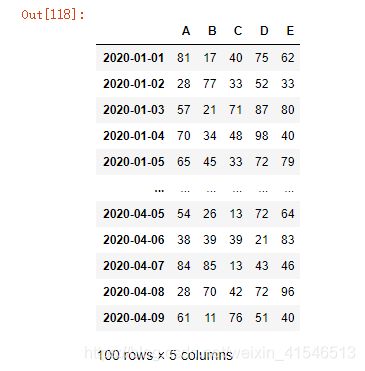
df5.index.asfreq(freq='M',how='e') # 日转月
结果

asfreq函数的参数
freq:按什么方式 可选的有 S 秒,H 时, D 天,M 月 ,Q 季,A 年
how: 开始还是结束 可选 E 结束, S 开始 只有在高转低的情况下有用,例如 年转月,日转时
以PeriodIndex为索引的DataFrame,可以直接使用asfreq方法,他会直接作用到index上
df5.asfreq('M',how='e')
结果
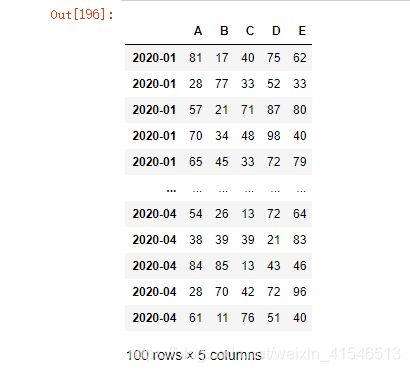
除了asfreq方法,还可以对索引以strftime方法转成字符串类型的索引,方法类似于datetime模块格式化输出时间字符串的方法
df5.index.strftime('%m-%d')
结果

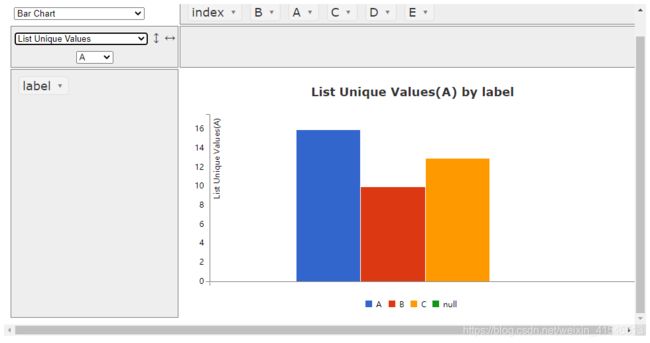
5. 可用在jupyter notebook中的透视表工具
当我们想在jupyter中使用想Excel那样的数据透视表时该怎么办呢
我们可以使用这款插件,可以帮助我们在jupyter 中轻松生成透视表甚至是画图
from pivottablejs import pivot_ui
pivot_ui(df5.reset_index()) # 在联网情况下使用,需要下载内容
结果
我们可以直接拖动标签,就可以快速生成数据透视表或图
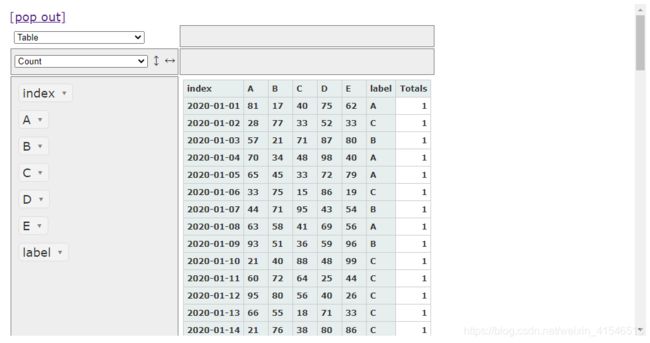
生成图
写在后面的话:
如果你看到了这篇文章,还请给予小小的支持,灰常感谢!!!
如果需要jupyter文件的可以私聊我哟!