【大连理工大学】计算机专业选修:深度学习2020期末复习
考完试了,老师考试范围就是他的PPT(虽然我比较菜看不懂其中公式),造福学弟学妹攒人品,大家取需~
题型:单选20‘多选15’判断10‘论述30’
必考:
计算题:
卷积网络计算(考了)
pooling计算
论述题:
过拟合解决方法(重点,一道多选一道简答)
- dropout
- 降低维度,减小宽度,降低模型复杂度
- 参数正则化
- data augmentation
- early stopping
数据预处理一般方法:中心化、归一化、白化、维数约简
目标检测RPN网络定义,在faster-RCNN中的作用(PPT上写的我没看懂,网上搜搜看吧)
pooling定义和作用: - 降维
- 实现非线性
- 扩大感受野
- 实现不变性
常用的CNN模型,简述特点 - LeNet
- AlexNet
- VGG-16
- GoogleNet
- ResNet
- DenseNet
深度学习训练一般步骤
没考:
KNN,SVM原理
聚类学习Kmeans
梯度下降
目标检测
LSTM:遗忘门,输入门,输出门
GRU有一个重置门和一个更新门(电梯门),重置门决定了如何把新的输入与之前的记忆相结合,更新门决定多少先前的记忆起作用。GRU将LSTM里面的遗忘门和输入门合并为更新门
课后习题:
- 假设有1000张5种不同动物的照片,分别简述在监督学
习和无监督学习的条件下完成此项任务
监督学习:SVM,KNN,神经网络,决策树
无监督学习:Kmeans进行聚类切割,k=5
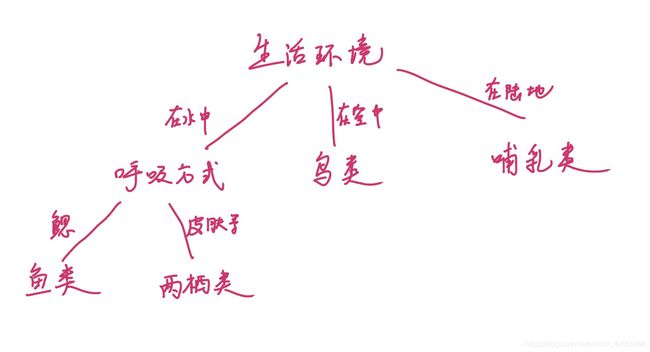
- 已知数据集中样本为{猫,狗,虎,鲤鱼,鲨鱼,麻雀,
鹰,青蛙},请从生活环境、呼吸器官等角度构建决策树,
将样本分为哺乳类、鸟类、两栖类、鱼类等不同类型
选择题
考试题
CNN中1x1 kernel 作用
聚合学习中单个模型直接相关度高还是低
SPPNet性能(多选)
监督学习CNN最后一层神经元和分类数相同,对吗
如果把imagenet上训练好的模型拿出,输入一张白色图片,那么它在所有分类上概率相等?
如果随机初始化权重全部设为0,会出现什么结果?
解析:我们在线性回归,logistics回归的时候,基本上都是把参数初始化为0,我们的模型也能够很好的工作。然后在神经网络中,把w初始化为0是不可以的。这是因为如果把w初始化0,那么每一层的神经元学到的东西都是一样的(输出是一样的),而且在bp的时候,每一层内的神经元也是相同的,因为他们的gradient相同。
1、在实现前向传播和反向传播中使用的“cache”是什么?(D)
A.它用于跟踪我们正在搜索的超参数,以加速计算。
B.用于在训练期间缓存代价函数的中间值。
C.我们使用它传递反向传播中计算的变量到相应的前向传播步骤,它包含对于前向传播计算导数有用的变量。
D.我们使用它传递前向传播中计算的变量到相应的反向传播步骤,它包含对于反向传播计算导数有用的变量。
解析:“缓存”记录来自正向传播单元的值,并将其发送到反向传播单元,这是链式求导的需要。
2、以下哪些是“超参数”?(ABEF)
A.隐藏层的大小
B.神经网络的层数
C.激活值
D.权重
E.学习率
F.迭代次数
G.偏置
3、下列哪个说法是正确的?(A)
A.神经网络的更深层通常比前面层计算更复杂的输入特征。
B.神经网络的前面层通常比更深层计算更复杂的输入特性。
4、下面关于神经网络的说法正确的是:A
A.总层数L为5,隐藏层层数为3。
B.总层数L为3,隐藏层层数为3。
C.总层数L为4,隐藏层层数为4。
D.总层数L为5,隐藏层层数为4。
解析: 网络层数按隐藏层数+2计算。输入和输出层不算作隐藏层。
5、在前向传播期间,在层l的前向传播函数中,您需要知道层l中的激活函数(Sigmoid,tanh,ReLU等)是什么, 在反向传播期间,相应的反向传播函数也需要知道第l层的激活函数是什么,因为梯度是根据它来计算的。这样描述正确吗?(A)
A.正确
B.错误
解析: 不同激活函数有不同的导数。在反向传播期间,需要知道正向传播中使用哪种激活函数才能计算正确的导数。
6、有一些功能具有以下属性:
利用浅网络电路计算一个函数时,需要一个大网络(我们通过网络中的逻辑门数量来度量大小),但是(ii)使用深网络电路来计算它,只需要一个指数较小的网络。真/假?(A)
A.正确
B.错误
解析: 深层的网络隐藏单元数量相对较少,隐藏层数目较多,如果浅层的网络想要达到同样的计算结果则需要指数级增长的单元数量才能达到。
7、前面的问题使用了一个特定的网络,一般情况下, 与层l有关的权重矩阵W[l]的维数是多少?(A)
A.W[l]的维度是 (n[l], n[l−1])
B.W[l]的维度是 (n[l-1], n[l])
C.W[l]的维度是 (n[l+1], n[l])
D.W[l]的维度是 (n[l], n[l+1])
解析: 一般来说W[l]的形状是(n[l],n[l-1]),b[l]的形状是(n[l],1)
北航2019机器学习考试题(部分)
-
贝叶斯决策,基于最小风险和最小方差的决策
-
svm的基本思想,模型表达式,软间隔和硬间隔的物理含义,如何用来解决非线性问题
-
什么是过拟合,解决方法有哪一些
过拟合指模型过于复杂,在训练集上表现好而在测试集上表现不好。
解决方法:
简化模型结构(减小深度/降低宽度);
dropout(深度学习常用)
参数正则化:降低复杂度,提升稳定度
data augmentation:以CV为例,在训练集中裁剪旋转、添加噪点。
early stopping:在每个epoch中,当accuracy不变时停止训练。 -
pca算法基于最小均方误差的思想。
-
给出一个4X4X4X3的全连接神经网络,推导反向传播算法,以第二层的第三个节点为例
-
给出机器学习和深度学习的联系,各有什么优缺点,你认为未来深度学习会如何发展。
北航2019机器学习考试题https://www.csdn.net/gather_2d/MtjaYg5sMDcyODMtYmxvZwO0O0OO0O0O.html
深度学习测试题
详细解析
一、单选题
- 神经网络的“损失函数”(Loss fuction)衡量的是(A)
A.预测值与真实值之间的差距
B.训练集与测试集之间的差距
C.dropout损失的信息量
D.pooling损失的信息量
- 函数f(x)=1/(1+e^(-x))的导数在x>∞的极限是(B)
A.1 B.0 C.0.5 D.∞
解析 :sigmoid函数极限的是在(0,1),这里问的是它的导数S’(x)=S(x)(1-S(x)),所以应该是0。
- 在反向传播的过程中,首先被计算的变量(C)的梯度,之后将其反向传播。
A.连接权重 B.损失函数 C.激活函数 D.特征映射
-
卷积神经网络VGG16名称中16指的是(C)
A.论文发表于2016年
B.网络总共有16层
C.网络有16层的参数需要训练
D.VGG发表的第16代网络
解析 :VGG16共包含:
13个卷积层(Convolutional Layer),分别用conv3-XXX表示
3个全连接层(Fully connected Layer),分别用FC-XXXX表示
5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是
VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
所以这里的16层指的是需要参与训练的层数。
- 在神经网络中,“梯度消失”问题的主要来源是(D)
A.被Dropout丢弃
B.被Pooling丢弃
C.梯度为负数
D.梯度趋近于零
-
下列哪一项在神经网络中引入了非线性 B
A. 随机梯度下降
B. 修正线性单元(ReLU)
C. 卷积函数
D. 以上都不对 -
以下哪种不是自适应学习率方法 A
A. Mini-batch SGD
B. Adagrad
C. RMSprop -
如果使用的学习率太大,会导致 C
A. 网络收敛的快
B. 网络收敛的快
C. 网络无法收敛
D. 不确定 -
下列目标检测网络中,哪个是一阶段的网络 C
A. Faster-rcnn
B. RFCN
C. YOLOV3
D. SPP-net -
假定在神经网络中的隐藏层中使用激活函数X。在特定神经元给定任意输入,会得到输出[-0.0001]。X可能是以下哪一个激活函数 B
A. ReLU
B. tanh
C. Sigmoid
D. 以上都不是
解析:该激活函数可能是 tanh,因为该函数的取值范围是 (-1,1)。
- 如果增加神经网络的宽度,精确度会增加到一个阈值,然后开始降低。造成这一现象的原因可能是 C
A. 只有一部分核被用于预测
B. 当核数量增加,神经网络的预测能力降低
C. 当核数量增加,其相关性增加,导致过拟合
D. 以上都不对
二、多选题
- 神经网络中参数极多,常用的初始化方法有哪些?(ABD)
A.全零初始化 B.随机初始化 C.加载预训练模型 D.使用深度信念网络
解析 :深度信念网络(DBN)通过采用逐层训练的方式,解决了深层次神经网络的优化问题,通过逐层训练为整个网络赋予了较好的初始权值,使得网络只要经过微调就可以达到最优解。
- 人工智能网络的常用激活函数有(ABD)
A.sigmond B.tanh C.sinh D.relu E.cos
-
以关于梯度下降法叙述正确的有?(BD)
A. 精度下降方法迭代时将沿着梯度方向进行更新
B.梯度下降方法迭代时将沿着负梯度方向进行更新
C.梯度方向是使得函数值下降最快的方向
D.梯度方向是使得函数值上升降最快的方向
解析 :梯度是一个向量,目标函数在具体某点沿着梯度的相反方向下降最快,一个形象的比喻是想象你下山的时候,只能走一步下山最快的方向即是梯度的相反方向,每走一步就相当于梯度下降法的一次迭代更新。
- 常用的池化层有哪些?(AB)
A.MaxPooling B.AveragePooling C.MinPooling D.MedianPooling
- 相对于普通的神经网络,循环神经网络(RNN)的“循环”主要体现在(ABC)
A.训练过程中的反向传播次数更多
B.训练经过一定轮次之后将参数归零
C.深层节点的输出会反过来影响浅层节点
D.每个节点自循环
-
当图像分类的准确率不高时,可以考虑以下哪种方法提高准确率 (ABC)
A. 数据增强
B. 调整超参数
C. 使用预训练网络参数
D. 减少数据集 -
下列哪个神经网络结构会发生权重共享 AB
A. 卷积神经网络
B. 循环神经网络
C. 全连接神经网络 -
关于梯度下降算法,以下说法正确的是 ABC
A. 随机梯度下降算法是每次考虑单个样本进行权重更新
B. Mini-Batch梯度下降算法是批量梯度下降和随机梯度下降的折中
C. 批量梯度下降算法是每次考虑整个训练集进行权重更新 -
当图像分类的准确率不高时,可以考虑以下哪种方法提高准确率
A. 数据增强
B. 调整超参数
C. 使用预训练网络参数
D. 减少数据集