golang-程序实体
golang的程序实体
可能要了解下go编程的一些语言特性和一些编程方法和思想
Go 语言中的程序实体包括变量、常量、函数、结构体和接口
Go 语言是静态类型的编程语言,所以我们在声明变量或常量的时候,都需要指定它们的类型,或者给予足够的信息,这样才可以让 Go 语言能够推导出它们的类型。
在 Go 语言中,变量的类型可以是其预定义的那些类型,也可以是程序自定义的函数、结构体或接口。常量的合法类型不多,只能是那些 Go 语言预定义的基本类型。它的声明方式也更简单一些。
声明变量
声明一个name
var name string
还是上代码:
package main
import (
"flag"
"fmt"
)
func main() {
var name string // [1]
flag.StringVar(&name, "name", "everyone", "The greeting object.") // [2]
flag.Parse()
fmt.Printf("Hello, %v!\n", name)
}
除了var的声明方式,还可以有其他的声明方式吗?
第一种方式需要先对注释[2]处的代码稍作改动,把被调用的函数由flag.StringVar改为flag.String,传参的列表也需要随之修改,这是为了[1]和[2]处代码合并的准备工作。
var name = flag.String("name", "everyone", "The greeting object.")
注意,flag.String函数返回的结果值的类型是*string而不是string。类型*string代表的是字符串的指针类型,而不是字符串类型。因此,这里的变量name代表的是一个指向字符串值的指针。
在这种情况下,那个被用来打印内容的函数调用就需要微调一下,把其中的参数name改为*name,即:fmt.Printf("Hello, %v!\n", *name)。
第二种方式与第一种方式非常类似,它基于第一种方式的代码,赋值符号=右边的代码不动,左边只留下name,再把=变成:=——海象符号? 其实这个极其常见了吧
name := flag.String("name", "everyone", "The greeting object.")
解析
- 一个是你要知道
Go语言中的类型推断,以及它在代码中的基本体现 - 另一个是短变量声明的用法。
第一种方式中的代码在声明变量name的同时,还为它赋了值,而这时声明中并没有显式指定name的类型
之前的变量声明语句是var name string。这里利用了 Go 语言自身的类型推断,而省去了对该变量的类型的声明。
你可以认为,表达式类型就是对表达式进行求值后得到结果的类型。Go 语言中的类型推断是很简约的,这也是 Go 语言整体的风格。
至于第二种方式所用的短变量声明,实际上就是 Go 语言的类型推断再加上一点点语法糖。
我们只能在函数体内部使用短变量声明。在编写if、for或switch语句的时候,我们经常把它安插在初始化子句中,并用来声明一些临时的变量。而相比之下,第一种方式更加通用,它可以被用在任何地方。
短变量声明还有其他的玩法
Go 语言的类型推断可以带来哪些好处?
当然,在写代码时,我们通过使用 Go 语言的类型推断,而节省下来的键盘敲击次数几乎可以忽略不计。但它真正的好处,往往会体现在我们写代码之后的那些事情上,比如代码重构。
我们依然通过调用一个函数在声明name变量的同时为它赋值,但是这个函数不是flag.String,而是由我们自己定义的某个函数,比如叫getTheFlag。
package main
import (
"flag"
"fmt"
)
func main() {
var name = getTheFlag()
flag.Parse()
fmt.Printf("Hello, %v!\n", *name)
}
func getTheFlag() *string {
return flag.String("name", "everyone", "The greeting object.")
}
我们可以用getTheFlag函数包裹(或者说包装)那个对flag.String函数的调用,并把其结果直接作为getTheFlag函数的结果,结果的类型是*string。
这样一来,var name =右边的表达式,可以变为针对getTheFlag函数的调用表达式了。这实际上是对“声明并赋值name变量的那行代码”的重构。
我们通常把不改变某个程序与外界的任何交互方式和规则,而只改变其内部实现”的代码修改方式,叫做对该程序的重构。重构的对象可以是一行代码、一个函数、一个功能模块,甚至一个软件系统
可以随意改变getTheFlag函数的内部实现,及其返回结果的类型,而不用修改main函数中的任何代码
我们不显式地指定变量name的类型,使得它可以被赋予任何类型的值。也就是说,变量name的类型可以在其初始化时,由其他程序动态地确定。
在你改变getTheFlag函数的结果类型之后,Go 语言的编译器会在你再次构建该程序的时候,自动地更新变量name的类型。如果使用过Python或Ruby这种动态类型的编程语言的话,一定会觉得这情景似曾相识。
没错,通过这种类型推断,你可以体验到动态类型编程语言所带来的一部分优势,即程序灵活性的明显提升。但在那些编程语言中,这种提升可以说是用程序的可维护性和运行效率换来的。
Go 语言是静态类型的,所以一旦在初始化变量时确定了它的类型,之后就不可能再改变。这就避免了在后面维护程序时的一些问题。另外,请记住,这种类型的确定是在编译期完成的,因此不会对程序的运行效率产生任何影响。
只用一两句话回答这个问题的话,我想可以是这样的:Go 语言的类型推断可以明显提升程序的灵活性,使得代码重构变得更加容易,同时又不会给代码的维护带来额外负担(实际上,它恰恰可以避免散弹式的代码修改),更不会损失程序的运行效率。
变量的重声明是什么意思?
这涉及了短变量声明。通过使用它,我们可以对同一个代码块中的变量进行重声明。
既然说到了代码块,我先来解释一下它。在 Go 语言中,代码块一般就是一个由花括号括起来的区域,里面可以包含表达式和语句。Go 语言本身以及我们编写的代码共同形成了一个非常大的代码块,也叫全域代码块。这主要体现在,只要是公开的全局变量,都可以被任何代码所使用。相对小一些的代码块是代码包,一个代码包可以包含许多子代码包,所以这样的代码块也可以很大。接下来,每个源码文件也都是一个代码块,每个函数也是一个代码块,每个if语句、for语句、switch语句和select语句都是一个代码块。甚至,switch或select语句中的case子句也都是独立的代码块。走个极端,我就在main函数中写一对紧挨着的花括号算不算一个代码块?当然也算,这甚至还有个名词,叫“空代码块”。
回到变量重声明的问题上。其含义是对已经声明过的变量再次声明。变量重声明的前提条件如下。
- 由于变量的类型在其初始化时就已经确定了,所以对它再次声明时赋予的类型必须与其原本的类型相同,否则会产生编译错误。
- 变量的重声明只可能发生在某一个代码块中。如果与当前的变量重名的是外层代码块中的变量,那么就是另外一种含义了
- 变量的重声明只有在使用短变量声明时才会发生,否则也无法通过编译。如果要在此处声明全新的变量,那么就应该使用包含关键字var的声明语句,但是这时就不能与同一个代码块中的任何变量有重名了。
- 被“声明并赋值”的变量必须是多个,并且其中至少有一个是新的变量。这时我们才可以说对其中的旧变量进行了重声明。
这样来看,变量重声明其实算是一个语法糖(或者叫便利措施)。它允许我们在使用短变量声明时不用理会被赋值的多个变量中是否包含旧变量。可以想象,如果不这样会多写不少代码。
看下代码片段:
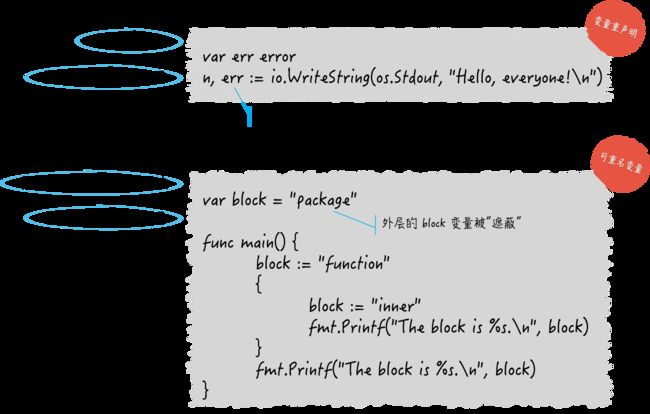
var err error
n, err := io.WriteString(os.Stdout, "Hello, everyone!\n")
我使用短变量声明对新变量n和旧变量err进行了“声明并赋值”,这时也是对后者的重声明。
结论
基于类型推断,Go 语言的类型推断只应用在了对变量或常量的初始化方面。
所谓“变量的重声明”容易引发歧义,而且也不容易理解。如果没有为变量分配一块新的内存区域,那么用声明是不恰当的。在《Go 语言圣经》一书中将短声明的这种特性称为赋值。总结如下:
在使用短变量声明的时候,你可能想要同时对一个已有的变量赋值,类似使用 = 进行多重赋值那样(如 i, j = 2, 3)。所以,Go 为短声明语法提供了一个语法糖(或者叫便利措施):短变量声明不需要声明所有在左边的变量。如果多个变量在同一个词法块中声明,那么对于这些变量,短声明的行为等同于赋值。
比如,在下面的代码中,第一条语句声明了 in 和 err。第二条语句仅声明了 out,但向已有的 err 变量进行赋值。
in, err := os.Open(infile)
// ...
out, err := os.Create(outfile)
但是这种行为需要一些前提条件:
- 要赋值的变量必须声明在同一个词法块中。
如果两个变量位于不同的词法块中,短声明语法表示的仍然是“声明”而非“赋值”。此时它们就是重名的变量了,而且内层变量会“覆盖”外部变量。
- 必须至少声明一个新变量,否则代码将不能编译通过。
原因很简单,如果不用声明新变量而仅仅是为了赋值,那么直接使用赋值符 = 即可:
f, err := os.Open(infile)
// ...
// f, err := os.Create(outfile) // 编译错误:没有新变量
f, err = os.Create(outfile) // 使用普通的赋值语句即可
到这里是不是想说;不就是一个声明和赋值吗?搞这么复杂???
是
变量作用域
这个很简单,应该说不复杂
之前说过了,重新给一个变量进行声明——你也可以理解为赋值,由于是强类型语言,后续的赋值一定要是相同的或者说可兼容的类型,否则会出现编译错误~
请记住,一个程序实体的作用域总是会被限制在某个代码块中,而这个作用域最大的用处,就是对程序实体的访问权限的控制。对“高内聚,低耦合”这种程序设计思想的实践,恰恰可以从这里开始。
简单看下go的变量作用域:
package main
import "fmt"
var block = "package"
func main() {
block := "function"
{
block := "inner"
fmt.Printf("The block is %s.\n", block)
}
fmt.Printf("The block is %s.\n", block)
}
直接看下输出:
The block is inner.
The block is function.
那不用多说:block的作用域,只自本地的代码块优先起作用!~
- 首先,代码引用变量的时候总会最优先查找当前代码块中的那个变量。注意,这里的“当前代码块”仅仅是引用变量的代码所在的那个代码块,并不包含任何子代码块。
- 其次,如果当前代码块中没有声明以此为名的变量,那么程序会沿着代码块的嵌套关系,从直接包含当前代码块的那个代码块开始,一层一层地查找。
- 一般情况下,程序会一直查到当前代码包代表的代码块。如果仍然找不到,那么 Go 语言的编译器就会报错了。
但有个特殊情况,如果我们把代码包导入语句写成import . "XXX"的形式(注意中间的那个“.”),那么就会让这个“XXX”包中公开的程序实体,被当前源码文件中的代码,视为当前代码包中的程序实体。 比如,如果有代码包导入语句import . fmt,那么我们在当前源码文件中引用fmt.Printf函数的时候直接用Printf就可以了。在这个特殊情况下,程序在查找当前源码文件后会先去查用这种方式导入的那些代码包。
既然可重名变量的类型可以是任意的,那么当它们之间存在“屏蔽”时你就更需要注意了。不同类型的值大都有着不同的特性和用法。当你在某一种类型的值上施加只有在其他类型值上才能做的操作时,Go 语言编译器一定会告诉你:“这不可以”。
怎样判断一个变量的类型?
package main
import "fmt"
var container = []string{"zero", "one", "two"}
func main() {
container := map[int]string{0: "zero", 1: "one", 2: "two"}
fmt.Printf("The element is %q.\n", container[1])
}
怎样在打印其中元素之前,正确判断变量container的类型?
断言表达式:
value, ok := interface{}(container).([]string)
interface{}表示空接口:
它包括了用来把container变量的值转换为空接口值的interface{}(container)``。 以及一个用于判断前者的类型是否为切片类型 ``[]string 的 .([]string)
这个表达式的结果可以被赋给两个变量,在这里由value和ok代表。变量ok是布尔(bool)类型的,它将代表类型判断的结果,true或false。
如果是true,那么被判断的值将会被自动转换为[]string类型的值,并赋给变量value,否则value将被赋予nil(即“空”)。
顺便提一下,这里的ok也可以没有。也就是说,类型断言表达式的结果,可以只被赋给一个变量,在这里是value。
但是这样的话,当判断为否时就会引发异常。
断言
类型断言表达式的语法形式是x.(T)
当这里的container变量类型不是任何的接口类型时,我们就需要先把它转成某个接口类型的值。
如果container是某个接口类型的,那么这个类型断言表达式就可以是container.([]string)。这样看是不是清晰一些了?
在 Go 语言中,interface{}代表空接口,任何类型都是它的实现类型。我在下个模块,会再讲接口及其实现类型的问题。现在你只要知道,任何类型的值都可以很方便地被转换成空接口的值就行了。
这里的具体语法是interface{}(x),例如前面展示的interface{}(container)。你可能会对这里的{}产生疑惑,为什么在关键字interface的右边还要加上这个东西?请记住,一对不包裹任何东西的花括号,除了可以代表空的代码块之外,还可以用于表示不包含任何内容的数据结构(或者说数据类型)。
比如struct{},它就代表了不包含任何字段和方法的、空的结构体类型。而空接口interface{}则代表了不包含任何方法定义的、空的接口类型。当然了,对于一些集合类的数据类型来说,{}还可以用来表示其值不包含任何元素,比如空的切片值[]string{},以及空的字典值map[int]string{}。

我们再向答案的最右边看。圆括号中[]string是一个类型字面量。所谓类型字面量,就是用来表示数据类型本身的若干个字符。
比如,string是表示字符串类型的字面量,uint8是表示 8 位无符号整数类型的字面量。
还有更复杂的结构体类型字面量、接口类型字面量
类型转换规则中有哪些值得注意的地方
- 语法形式是T(x)–
其中的x可以是一个变量,也可以是一个代表值的字面量(比如1.23和struct{}{}),还可以是一个表达式。注意,如果是表达式,那么该表达式的结果只能是一个值,而不能是多个值。在这个上下文中,x可以被叫做源值,它的类型就是源类型,而那个T代表的类型就是目标类型——GO类型转换
一些常见的“陷阱”
- 首先,对于整数类型值、整数常量之间的类型转换,原则上只要源值在目标类型的可表示范围内就是合法的。比如,之所以uint8(255)可以把无类型的常量255转换为uint8类型的值,是因为255在[0, 255]的范围内。
但需要特别注意的是,源整数类型的可表示范围较大,而目标类型的可表示范围较小的情况,比如把值的类型从int16转换为int8。请看下面这段代码:
var srcInt = int16(-255)
dstInt := int8(srcInt)
变量srcInt的值是int16类型的-255,而变量dstInt的值是由前者转换而来的,类型是int8。int16类型的可表示范围可比int8类型大了不少。问题是,dstInt的值是多少?
整数在 Go 语言以及计算机中都是以补码的形式存储的。这主要是为了简化计算机对整数的运算过程。(负数的)补码其实就是原码各位求反再加 1。
比如,int16类型的值-255的补码是1111111100000001。如果我们把该值转换为int8类型的值,那么 Go 语言会把在较高位置(或者说最左边位置)上的 8 位二进制数直接截掉,从而得到00000001。
又由于其最左边一位是0,表示它是个正整数,以及正整数的补码就等于其原码,所以dstInt的值就是1。
类似的快刀斩乱麻规则还有:当把一个浮点数类型的值转换为整数类型值时,前者的小数部分会被全部截掉。
- 第二,虽然直接把一个整数值转换为一个string类型的值是可行的,但值得关注的是,被转换的整数值应该可以代表一个有效的 Unicode 代码点,否则转换的结果将会是"�"(仅由高亮的问号组成的字符串值)。
字符’�’的 Unicode 代码点是U+FFFD。它是 Unicode 标准中定义的 Replacement Character,专用于替换那些未知的、不被认可的以及无法展示的字符。
哪个整数值转换后会得到哪个字符串?
看代码:
string(-1)
由于-1肯定无法代表一个有效的 Unicode 代码点,所以得到的总会是"�"。在实际工作中,我们在排查问题时可能会遇到�,你需要知道这可能是由于什么引起的。
- 第三个知识点是关于string类型与各种切片类型之间的互转的
先要理解的是,一个值在从string类型向[]byte类型转换时代表着以 UTF-8 编码的字符串会被拆分成零散、独立的字节。
除了与 ASCII 编码兼容的那部分字符集,以 UTF-8 编码的某个单一字节是无法代表一个字符的
string([]byte{'\xe4', '\xbd', '\xa0', '\xe5', '\xa5', '\xbd'}) // 你好
比如,UTF-8 编码的三个字节\xe4、\xbd和\xa0合在一起才能代表字符’你’,而\xe5、\xa5和\xbd合在一起才能代表字符’好’。
其次,一个值在从string类型向[]rune类型转换时代表着字符串会被拆分成一个个 Unicode 字符。
string([]rune{'\u4F60', '\u597D'}) // 你好
真正理解了 Unicode 标准及其字符集和编码方案之后,上面这些内容就会显得很容易了。什么是 Unicode 标准?我会首先推荐你去它的官方网站一探究竟。
还有一个就是别名类型了
他只是为了重构而生的我觉得
type MyString = string // 注意这里有等号
别名类型与其源类型的区别恐怕只是在名称上,它们是完全相同的。
Go 语言内建的基本类型中就存在两个别名类型。byte是uint8的别名类型,而rune是int32的别名类型。
如果我这样声明:
type MyString2 string // 注意,这里没有等号。
MyString2和string就是两个不同的类型了。这里的MyString2是一个新的类型,不同于其他任何类型。
这种方式也可以被叫做对类型的再定义。我们刚刚把string类型再定义成了另外一个类型MyString2

对于这里的类型再定义来说,string可以被称为MyString2的潜在类型。潜在类型的含义是,某个类型在本质上是哪个类型。
潜在类型相同的不同类型的值之间是可以进行类型转换的。因此,MyString2类型的值与string类型的值可以使用类型转换表达式进行互转。
但对于集合类的类型[]MyString2与[]string来说这样做却是不合法的,因为[]MyString2与[]string的潜在类型不同,分别是[]MyString2和[]string。另外,即使两个不同类型的潜在类型相同,它们的值之间也不能进行判等或比较,它们的变量之间也不能赋值。
总结
类似这种可以用来搭建基础设施的代码golang,总的来说越精通越好,细节决定成败,会与不会的差距真的就太大了,出问题反察的时候,及其考验基本功~