Federated Meta-Learning with Fast Convergence and Efficient Communication 论文阅读笔记+关键代码解读
论文地址点这里
一. 介绍
联邦学习中数据是非独立同分布的,基于FedAvg算法成功后,作者发现元学习算法MAML应对客户端上数据量较少,数据分布不均的场景提出了FedMeta框架,作为连接元学习方法和联邦学习的桥梁。在元学习中,参数化算法通过元训练过程从大量任务中慢慢学习,在元训练过程中,算法在每个任务中快速训练特定的模型。任务由互不关联的支持集和查询集组成。在支持集上训练特定的模型,然后在查询集上进行测试,测试结果用于更新算法。对于FedMeta来说,算法在服务器上维护并分发给客户端进行训练。训练之后,查询集上的测试结果被上传到服务器进行算法更新。
二. 算法介绍
首先我们定义一下
D S T : s u p p o r t s e t D_S^T:support\ set DST:support set
D Q T : q u e r y s e t D_Q^T:query\ set DQT:query set
A : 元 学 习 算 法 A:元学习算法 A:元学习算法
ϕ : 元 学 习 参 数 \phi:元学习参数 ϕ:元学习参数
θ T : 模 型 参 数 \theta_T:模型参数 θT:模型参数
根据元学习思想,我们首先通过 D S T D_S^T DST训练A上的模型f,经过更新输出模型参数 θ T \theta_T θT,这一步叫做inner update(内部更新)。之后训练出来的 θ T \theta_T θT通过我们的query set D Q T D_Q^T DQT进行评估,计算出测试的损失 L D Q T ( θ T ) L_{D_Q^T}(\theta_T) LDQT(θT),通过损失我们可以反映出我们的算法 A ϕ A_\phi Aϕ上的训练能力,最后我们根据这个测试损失去最小化更新我们的参数 ϕ \phi ϕ,这一步叫outer update(外部更新)。这些过程用数据表达就是:我们的算法 A ϕ A_\phi Aϕ通过优化下面目标:
min ϕ E T [ L D Q T ( θ T ) ] = min ϕ E T [ L D Q T ( A ϕ ( D S T ) ) ] \min_\phi E_{T}[L_{D_Q^T}(\theta_T)]=\min_\phi E_{T}[L_{D_Q^T}(A_\phi (D_S^T))] ϕminET[LDQT(θT)]=ϕminET[LDQT(Aϕ(DST))]
如果以maml来看的话,在一开始我们出事参数 ϕ = θ \phi=\theta ϕ=θ,然后通过 D S T D_S^T DST训练更新(几步梯度下降) L D S T ( θ ) = 1 ∣ D S T ∣ ∑ ( x , y ) l ( f θ ( x ) , y ) L_{D_S^T}(\theta)=\frac{1}{|D_S^T|}\sum_{(x,y)}l(f_\theta(x),y) LDST(θ)=∣DST∣1∑(x,y)l(fθ(x),y)使得 θ = θ T \theta = \theta_T θ=θT,之后,将 f θ T f_{\theta_T} fθT在 D Q T D_Q^T DQT进行测试,获得测试损失函数 L D S T ( θ ) = 1 ∣ D Q T ∣ ∑ ( x ′ , y ′ ) l ( f θ T ( x ′ ) , y ′ ) L_{D_S^T}(\theta)=\frac{1}{|D_Q^T|}\sum_{(x',y')}l(f_{\theta_T}(x'),y') LDST(θ)=∣DQT∣1∑(x′,y′)l(fθT(x′),y′)。定义好值周上面的最小化目标就可以改变为:
min ϕ E T [ L D Q T ( θ − α ∇ L D S T ( θ ) ) ] \min_\phi E_{T}[L_{D_Q^T}(\theta\ -\ \alpha\nabla L_{D_S^T}(\theta))] ϕminET[LDQT(θ − α∇LDST(θ))]。
到这里,meta的部分结束,之后就是联邦学习部分。怎么结合起来呢?作者想到每一个客户端在query set测试完之后,获取到测试的损失,同时根据这个损失计算出对应的梯度,将这个梯度传到服务端,服务端平均梯度后,根据这个梯度更新服务端的参数,最后再把参数传回到客户端,也就是客户端进行inner update和outer update(只进行梯度计算),服务端进行outer update(合并梯度更新)。
算法过程如图所示
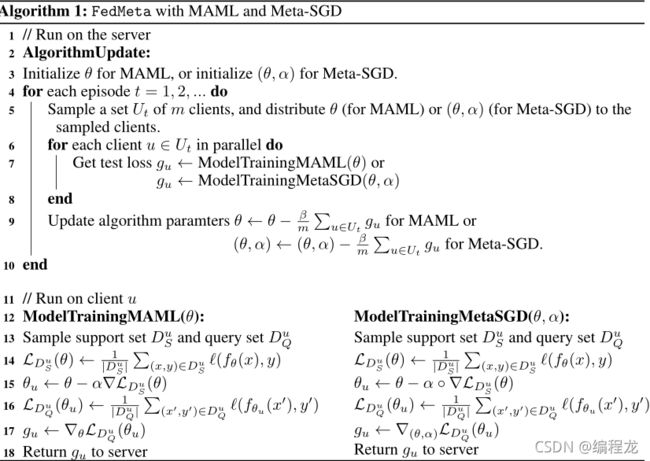
这里对maml以及meta learning还有不太清楚,以及query set和support set有疑问的可以看我之前的博客点这里。
四. 代码讲解
本次算法的github地址点这里,代码中很大一部分是实现客户端服务端的交互,这里就不详细说,重点讲解客户端训练过程和服务端的更新过程。
首先我们来看客户端的训练(对应inner update)
for batch_idx, (x, y) in enumerate(support_data_loader):
x, y = x.to(self.device), y.to(self.device)
num_sample = y.size(0)
pred = self.model(x)
loss = self.criterion(pred, y)
# 评估
correct = self.count_correct(pred, y)
# 写入相关的记录, 这份 loss 是平均的
support_loss.append(loss.item())
support_correct.append(correct)
support_num_sample.append(num_sample)
# 计算 loss 关于当前参数的导数, 并更新目前网络的参数(回传到 model)
loss_sum += loss * num_sample
grads = torch.autograd.grad(loss_sum / sum(support_num_sample), list(self.model.parameters()), create_graph=True, retain_graph=True)
for p, g in zip(self.model.parameters(), grads):
p.data.add_(g.data, alpha=-self.inner_lr)
这里是根据support set进行更新,第一个for循环是计算梯度,第二个for循环则是更新参数
更新的参数将用于query set上进行损失计算(outer update的梯度计算部分)
query_loss, query_correct, query_num_sample = [], [], []
loss_sum = 0.0
for batch_idx, (x, y) in enumerate(query_data_loader):
x, y = x.to(self.device), y.to(self.device)
num_sample = y.size(0)
pred = self.model(x)
loss = self.criterion(pred, y)
# batch_sum_loss
# 评估
correct = self.count_correct(pred, y)
# 写入相关的记录, 这份 loss 是平均的
query_loss.append(loss.item())
query_correct.append(correct)
query_num_sample.append(num_sample)
#
loss_sum += loss * num_sample
spt_sz = np.sum(support_num_sample)
qry_sz = np.sum(query_num_sample)
# 这个优化器的唯一作用是清除网络多余的梯度信息
# self.optimizer.zero_grad()
# 获取此使的梯度, 这个梯度为一个 tensor
grads = torch.autograd.grad(loss_sum / qry_sz, list(self.model.parameters()))
之后就是服务端进行合并和更新,合并梯度和更新
def aggregate_grads_weighted(self, solns, num_samples, weights_before):
# 使用 adam
m = len(solns)
g = []
for i in range(len(solns[0])):
# i 表示的当前的梯度的 index
# 总是 client 1 的梯度的形状
grad_sum = torch.zeros_like(solns[0][i])
total_sz = 0
for ic, sz in enumerate(num_samples):
grad_sum += solns[ic][i] * sz
total_sz += sz
# 累加之后, 进行梯度下降
g.append(grad_sum / total_sz)
# 普通的梯度下降 [u - (v * self.outer_lr / m) for u, v in zip(weights_before, g)]
self.outer_opt.increase_n()
for i in range(len(weights_before)):
# 这是一个 in-place 的函数
self.outer_opt(weights_before[i], g[i], i=i)
其实就是根据客户端的梯度和训练量加权平均计算得来,outer_opt则是进行参数更新,这里的更新用的是Adam