【动态规划】LeetCode - 139. 单词拆分——DFS、BFS、DP
139. 单词拆分
题目描述
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
示例 1:
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以被拆分成 “leet code”。
示例 2:
输入: s = “applepenapple”, wordDict = [“apple”, “pen”]
输出: true
解释: 返回 true 因为 “applepenapple” 可以被拆分成 “apple pen apple”。
注意你可以重复使用字典中的单词。
示例 3:
输入: s = “catsandog”, wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出: false
解题思路
(1)DFS思路
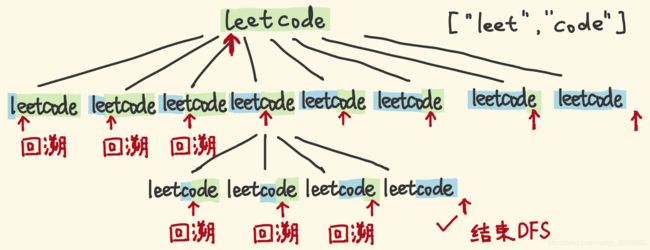
- 不带记忆化搜索的DFS方法
"leetcode"能否 break,可以拆分为:
- "l"是否是单词表的单词、剩余子串能否 break。
- "le"是否是单词表的单词、剩余子串能否 break。
- “lee”…以此类推…
用 DFS 回溯,考察所有的拆分可能,指针从左往右扫描:
- 如果指针的左侧部分是单词,则对剩余子串递归考察。
- 如果指针的左侧部分不是单词,不用看了,回溯,考察别的分支。
递归树,问题的解的空间树
-
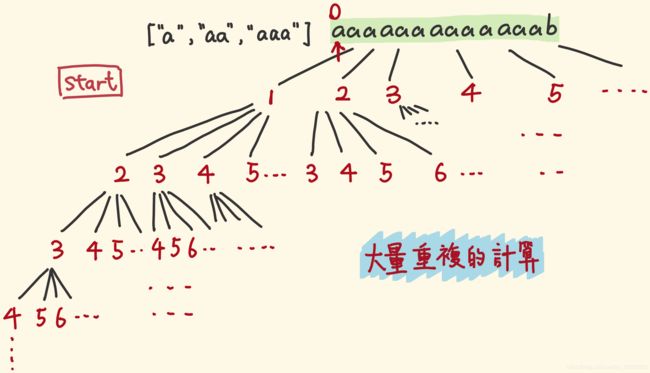
带记忆化搜索的DFS方法
start 指针代表了节点的状态,可以看到,做了大量重复计算:
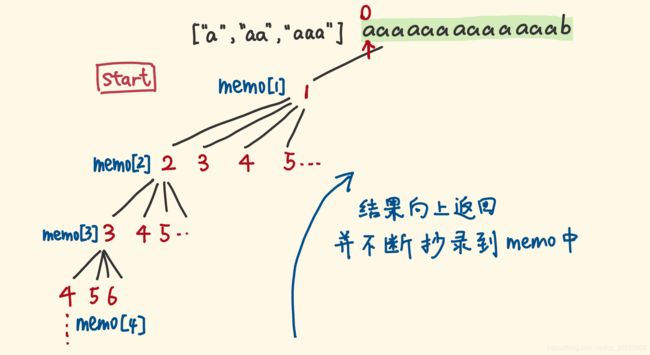
用一个数组,存储计算的结果,数组索引为指针位置,值为计算的结果。下次遇到相同的子问题,直接返回数组中的缓存值,就不用进入重复的递归。
代码:
// BFS
public boolean wordBreak(String s, List<String> wordDict) {
Queue<Integer> queue = new LinkedList<>();
queue.add(0);
int slength = s.length();
boolean[] visited = new boolean[slength + 1];
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
int start = queue.poll().intValue();
for (String word : wordDict) {
int nextStart = start + word.length();
if (nextStart > slength || visited[nextStart]) {
continue;
}
if (s.indexOf(word, start) == start) {
if (nextStart == slength) {
return true;
}
queue.add(nextStart);
visited[nextStart] = true;
}
}
}
}
return false;
}
(2)BFS
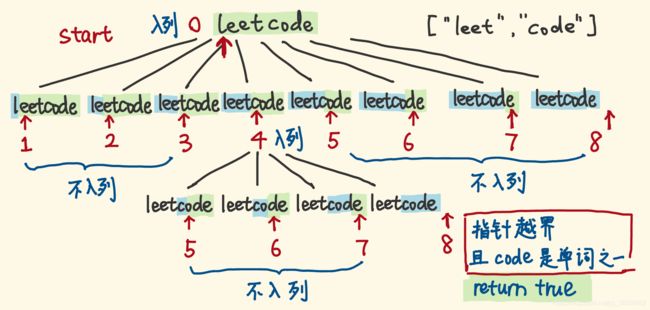
1. BFS 带有访问重复的节点
- 刚才我们用DFS遍历空间树,当然也能用BFS。
- 维护一个队列,依然用指针描述一个节点,依旧考察指针。
- 起初,指针 0 入列,然后它出列,指针 1,2,3,4,5,6,7,8 就是它的子节点,分别与 0 围出前缀子串,如果不是单词,对应的指针就不入列,否则入列,继续考察以它为起点的剩余子串。
- 然后重复:节点(指针)出列,考察它的子节点,能入列的就入列、再出列……
- 直到指针越界,没有剩余子串了,没有指针可入列,如果前缀子串是单词,说明之前一直在切出单词,返回 true。
- 如果整个BFS过程,始终没有返回true,则返回 false。
2. BFS 避免访问重复的节点
未剪枝的DFS会重复遍历节点,BFS也一样。思考一下超时的case,BFS是如何重复访问节点。
解决:用一个 visited 数组记录访问过的节点,出列考察一个指针时,存在于 visited 就跳过,否则将它存入 visited。
代码:
// BFS
public boolean wordBreak(String s, List<String> wordDict) {
Queue<Integer> queue = new LinkedList<>();
queue.add(0);
int slength = s.length();
boolean[] visited = new boolean[slength + 1];
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
int start = queue.poll().intValue();
for (String word : wordDict) {
int nextStart = start + word.length();
if (nextStart > slength || visited[nextStart]) {
continue;
}
if (s.indexOf(word, start) == start) {
if (nextStart == slength) {
return true;
}
queue.add(nextStart);
visited[nextStart] = true;
}
}
}
}
return false;
}
(3)动态规划
- s 串能否分解为单词表的单词,即:前 s.length 个字符的 s 串能否分解为单词表单词。
- 将大问题分解为规模小一点的子问题,规模不同就是长度,问题分解成:
- 前 i个字符的子串,能否分解成单词
- 剩余子串,是否为单个单词。
- dp[i]:长度为i的s[0:i-1]子串是否能拆分成单词。题目要我们求:dp[s.length]

状态转移方程
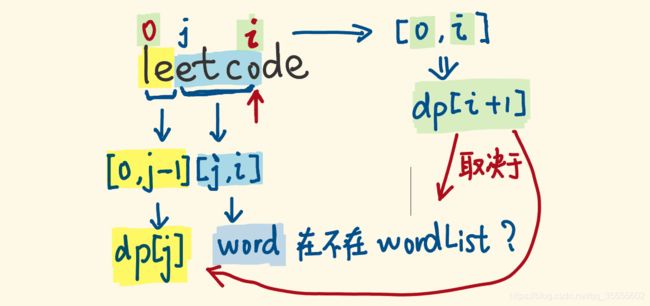
- 我们用指针 j 去划分s[0:i] 子串,如下图:
- s[0:i] 子串的 dp[i+1] ,是否为真(是否可拆分成单词),取决于两点:
- 它的前缀子串 s[0:j-1] 的 dp[j] ,是否为真。
- 剩余子串 s[j:i],是否是单个单词。
base case
- dp[0] = true。长度为 0 的s[0:-1]能拆分成单词表单词。
- 看似荒谬,但这只是为了让边界情况也能满足状态转移方程。
- 当 j = 0 时(上图黄色部分为空串,j 划分的前缀串为空串),s[0:i]子串的dp[i+1],取决于s[0:-1]的dp[0],和,剩余子串s[0:i]是否是单个单词。
- 只有让dp[0]为真,dp[i+1]才会只取决于s[0:i]是否为单个单词,满足了状态转移方程。
优化后的动态规划
- 迭代过程中,如果发现dp[i] == true ,直接break
- 如果dp[j] == false,dp[i]没有为 true 的可能,continue,考察下一个 j
代码:
// DP
public boolean wordBreak(String s, List<String> wordDict) {
int maxWordLength = 0;
Set<String> wordSet = new HashSet<>(wordDict.size());
for (String word : wordDict) {
wordSet.add(word);
if (word.length() > maxWordLength) {
maxWordLength = word.length();
}
}
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;
for (int i = 1; i < dp.length; i++) {
for (int j = (i - maxWordLength < 0 ? 0 : i - maxWordLength); j < i; j++) {
if (dp[j] && wordSet.contains(s.substring(j, i))) {
dp[i] = true;
break;
}
}
}
return dp[dp.length - 1];
}
图片参考:文中图片来源