基于RFM模型的Kmeans聚类算法实现
基于RFM模型的K均值聚类算法实现
- 模型介绍
-
- K 均值聚类原理
- 聚类步骤
- 导入库
- 读取数据
-
- 正确的代码
- 一个错误的示例
- 为什么会失败?
- 总结
点击跳转到总目录
本篇为Kmeans聚类算法实现,点击跳转数据分析
模型介绍
- 对于有监督的数据挖掘算法而言,数据集中需要包含标签变量(即因变量y的值)。但在有些场景下,并没有给定的y值,对于这类数据的建模,一般称为无监督的数据挖掘算法,最为典型的当属聚类算法
- Kmeans聚类算法利用距远近的思想将目标数据聚为指定的k个簇,进而使样本呈现簇内差异小,簇间差异大的特征。
K 均值聚类原理
- 随机选取 K 个样本作为初始聚类中心
- 计算样本与初始聚类中心的距离,按照距离最近的原则将
它们分配到对应的聚类中心 - 将每个类别中所有样本的均值作为该类别的聚类中心,重
复步骤 2,直到聚类中心收敛或不再发生变化
聚类步骤
- 从数据中随机挑选k个样本点作为原始的簇中心 计算剩余样本与簇中心的距离
- 把各样本标记为离k个簇中心最近的类别 重新计算各簇中样本点的均值
- 以均值作为新的k个簇中心
- 不断重复第二步和第三步,直到簇中心的变化趋于稳定,形成最终的k个簇
导入库
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import datetime
from sklearn.cluster import KMeans# 创建 Kmeans 模型并训练
from mpl_toolkits.mplot3d import Axes3D# 画3维图
from sklearn import preprocessing#标准化处理
import math#取对数log
读取数据
jiaoyu2 = pd.read_excel("22在线教育2.xlsx",sheet_name = "Sheet3",encoding="utf-8")
jiaoyu2.head(10)
data_edu = jiaoyu2.copy()

正确的代码
# 数据处理, 取 log
data_edu['R值_log'] = data_edu['最近一次消费时间间隔(R)'].map(lambda x: math.log(x + 0.001))#取对数log
data_edu['F值_log'] = data_edu['消费频率(F)'].map(lambda x: math.log(x + 0.001))#map函数
data_edu['M值_log'] = data_edu['消费金额(M)'].map(lambda x: math.log(x + 0.001))#lamda表达式
feature_columns = ['R值_log', 'F值_log','M值_log']
feature_data = data_edu[ feature_columns ].values
# 标准化处理
# 转化为均值为0,方差为1的数据
scaler = preprocessing.StandardScaler().fit(feature_data)
feature_data_scaled = scaler.transform(feature_data)
feature_data_scaled
# 创建 Kmeans 模型并训练
k_means_model = KMeans(n_clusters = 8, random_state = 0)
# k_means_model = KMeans(n_clusters = 3, random_state = 0)
# 3:分3类
# random_state:定初值,以防下次跑就不一样了
k_means_model.fit(feature_data_scaled)#训练模型参数
print(k_means_model)
labels = k_means_model.labels_# 拿到模型的,对应的每一个的样本的labels
print(pd.Series(labels).value_counts())# value_counts()统计
# 分成了3类,每一个样本一个标签
# 0,1,2
fig1 = plt.figure(1, figsize=(12, 8))
ax1 = Axes3D(fig1, rect = [0,0,.95, 1], elev = 45, azim = -45)# 使用axes3d 创建一个3维图
a = 0
c = []
d = []
e = ['r','g','b','c','m','y','k','w']# red,green,blue,cyan青色,magenta品红,yellow,black,white
for a in range(8):
b = ax1.scatter(data_edu['R值_log'][labels == a], data_edu['F值_log'][labels == a],
data_edu['M值_log'][labels == a], edgecolor = 'k', color = e[a])
c.append(b)
d.append('Cluster '+str(a))
# 每个标签都画到3维图上
ax1.legend(c, d)
ax1.invert_xaxis()
ax1.set_xlabel('Recency')
ax1.set_ylabel('Frequency')
ax1.set_zlabel('Monetary')
ax1.set_title('KMeans Clusters')
ax1.dist = 12
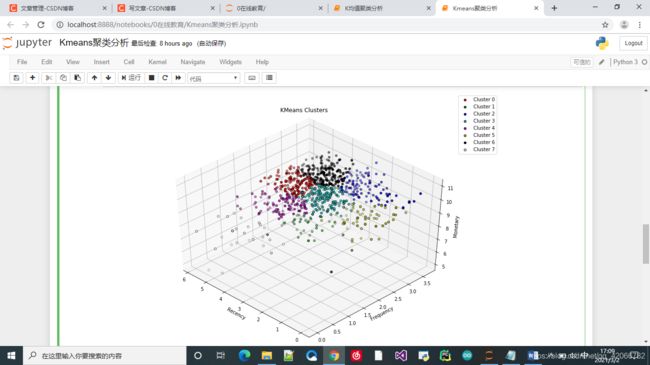
# 查看聚类的数据:
# 写一个for循环,计算每个labels,R值,M值,F值,均值
for i in range(len(set(labels))):
print(f'Data of Cluster {i + 1}:')
print(data_edu [labels == i][['最近一次消费时间间隔(R)', '消费频率(F)', '消费金额(M)']].mean())
一个错误的示例
# 数据处理, 取 log
data_edu['R值_log'] = data_edu['R值打分'].map(lambda x: math.log(x + 0.001))#取对数log
data_edu['F值_log'] = data_edu['F值打分'].map(lambda x: math.log(x + 0.001))#map函数
data_edu['M值_log'] = data_edu['M值打分'].map(lambda x: math.log(x + 0.001))#lamda表达式
feature_columns = ['R值_log', 'F值_log','M值_log']
feature_data = data_edu[ feature_columns ].values
# 标准化处理
# 转化为均值为0,方差为1的数据
scaler = preprocessing.StandardScaler().fit(feature_data)
feature_data_scaled = scaler.transform(feature_data)
feature_data_scaled
# 创建 Kmeans 模型并训练
k_means_model = KMeans(n_clusters = 8, random_state = 0)
# k_means_model = KMeans(n_clusters = 3, random_state = 0)
# 3:分3类
# random_state:定初值,以防下次跑就不一样了
k_means_model.fit(feature_data_scaled)#训练模型参数
print(k_means_model)
labels = k_means_model.labels_# 拿到模型的,对应的每一个的样本的labels
print(pd.Series(labels).value_counts())# value_counts()统计
# 分成了3类,每一个样本一个标签
# 0,1,2
fig1 = plt.figure(1, figsize=(12, 8))
ax1 = Axes3D(fig1, rect = [0,0,.95, 1], elev = 45, azim = -45)# 使用axes3d 创建一个3维图
a = 0
c = []
d = []
e = ['r','g','b','c','m','y','k','w']# red,green,blue,cyan青色,magenta品红,yellow,black,white
for a in range(8):
b = ax1.scatter(data_edu['R值_log'][labels == a], data_edu['F值_log'][labels == a],
data_edu['M值_log'][labels == a], edgecolor = 'k', color = e[a])
c.append(b)
d.append('Cluster '+str(a))
# 每个标签都画到3维图上
ax1.legend(c, d)
ax1.invert_xaxis()
ax1.set_xlabel('Recency')
ax1.set_ylabel('Frequency')
ax1.set_zlabel('Monetary')
ax1.set_title('KMeans Clusters')
ax1.dist = 12
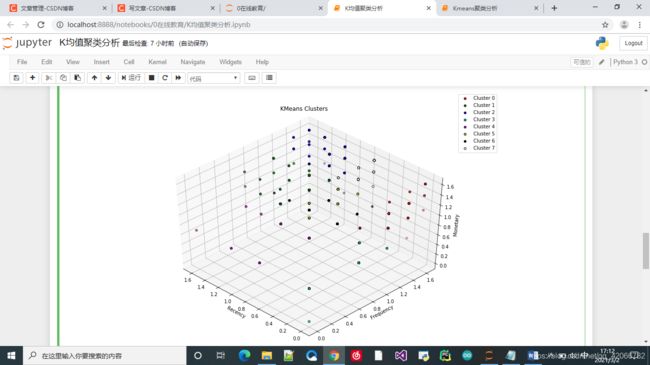
# 查看聚类的数据:
# 写一个for循环,计算每个labels,R值,M值,F值,均值
for i in range(len(set(labels))):
print(f'Data of Cluster {i + 1}:')
print(data_edu [labels == i][['R值打分', 'F值打分', 'M值打分']].mean())
为什么会失败?
- Kmeans聚类存在两个致命缺点:
- 一是聚类效果容易受到异常样本点的影响;
- 二是该 算法无法准确地将非球形样本进行合理的聚类。
- 基于密度的聚类则可以解决非球形簇的问题(DBSCAN聚类法),“密度”可以理解为样本点的紧密程度, 如果在指定的半径领域内,实际样本量超过给定的最小样本量阈值,则认为是密度高的对 象,就可以聚成一个簇
总结
1. 创建模型:KMeans(n_clusters = k)
2. 训练模型:fit