论文学习笔记-Gaussian YOLOv3
『写在前面』
高斯YOLOv3,在原版YOLOv3的基础上,针对边界框回归问题进行优化。在保证实时性的前提下,大幅提高了mAP和TP,降低了FP。同时,由于对边界框的置信度进行了建模,多了一个可以进行后处理的方式,以提高边界框回归的准确性。
作者机构:Jiwoong Choi等,Seoul National University.
论文出处:ICCV 2019.
文章标题:《Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving》
原文链接:https://arxiv.org/pdf/1904.04620
相关repo:https://github.com/jwchoi384/Gaussian_YOLOv3
目录
摘要
1 介绍
2 背景
3 Gaussian YOLOv3
3.1 高斯建模
3.2 损失函数重构
3.3 利用定位不确定性
4 试验结果
摘要
本文通过对YOLO V3中的bbox建模,引入高斯参数,改进LOSS函数中bbox回归分支,在支持实时的条件下提高检测精度。
旨在自动驾驶等任务中降低FP,提高TP.
1 介绍
原版YOLO的输出中包含各个bbox的置信度、类别得分、bbox参数(4个),可以看出,根据输出结果我们是无法得知回归出的包围框是否可靠。高斯YOLOv3首次尝试对YOLOv3中bbox定位的不确定性进行建模。
因为提出的方法只在检测层(YOLO Layer)中对bbox进行建模,所以额外的计算开销可以忽略不计,保证了算法的实时性。
2 背景
本文提出的高斯建模以及对原版YOLOv3中损失函数的重构,旨在减少训练过程中噪声数据产生的影响,并且在预测过程中,可以给出一个定位的准确性,从而进一步改善检测效果。
3 Gaussian YOLOv3
3.1 高斯建模
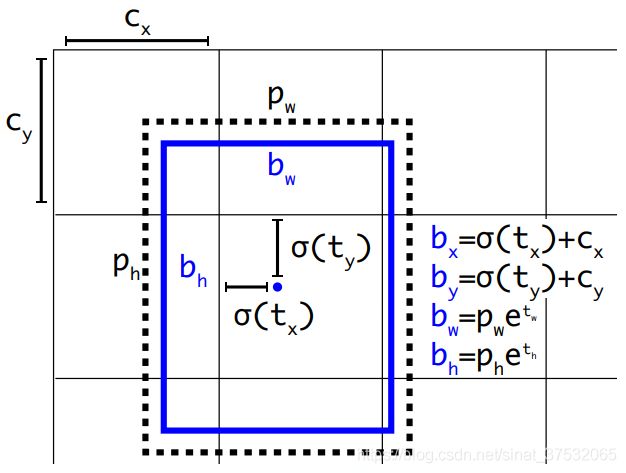
下图为原版YOLOv3中预测层输出结果示意图。YOLOv3中的预测层输出的feature map中,每个grid会产生3个预测框,每个预测框包含包围框坐标、目标得分和类别得分信息。最终一个目标的综合得分计算方式为目标得分(置信度)和最高类别得分的乘积。因为坐标的预测不像置信度那样是一个得分,而且目标得分大小并不能反映框定位的准确性,所以检测框定位的置信度是未知的。

从上图可以看到,YOLOv3中包围框的坐标通过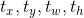 四个参数来编码。在本文中,为了对包围框的不确定性进行建模,作者为每个参数建立了一个单高斯模型,其均值对应框位置信息,方差表征框的不确定性。Gaussian YOLOv3的预测层输出如下图所示。
四个参数来编码。在本文中,为了对包围框的不确定性进行建模,作者为每个参数建立了一个单高斯模型,其均值对应框位置信息,方差表征框的不确定性。Gaussian YOLOv3的预测层输出如下图所示。

考虑YOLOv3中检测层的结构,在Gaussian YOLOv3中,对于参数,其对应的高斯参数计算如下:

回顾一下YOLOv3中,对框坐标信息的编解码方式:
其中,包围框的w和h需要通过
和先验框的w/h以及指数函数来计算得出。
基于上述讨论,可以解释一下Gaussian YOLOv3中各参数使用如此方法进行编码的原因:
1. 公式(2)中的![]() 和
和![]() 因为表示的是落在当前grid中的包围框的中心坐标,通过sigmoid函数将其标准化到0~1之间;
因为表示的是落在当前grid中的包围框的中心坐标,通过sigmoid函数将其标准化到0~1之间;
2. 公式(3)中的每一个方差都经过了sigmoid函数处理,表征对应的坐标信息的不确定性;
3. 因为原版YOLOv3中,![]() 和
和![]() 是有正有负的,所以在Gaussian YOLOv3中,没有对其加sigmoid处理,以保证它的正负性。
是有正有负的,所以在Gaussian YOLOv3中,没有对其加sigmoid处理,以保证它的正负性。
3.2 损失函数重构
在原版YOLOv3中,bbox的回归使用MSE loss,置信度和类别得分预测使用BCE loss。在Gaussian YOLOv3中,置信度和类别得分预测分支沿用原来的loss,而bbox的坐标因为被建模成高斯模型的参数,bbox回归的loss被重新设计为负对数似然函数(NLL loss):
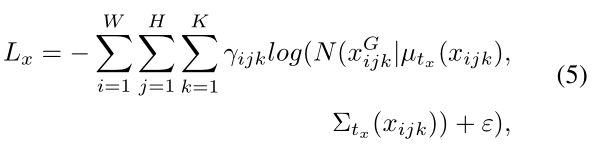
其中,![]() 表示
表示![]() 的NLL loss,
的NLL loss,![]() 的含义以此类推。
的含义以此类推。
W和H分别对应预测层中grids的数目, K对应anchor数。
K对应anchor数。
![]() 表示输出层第(i, j)个grid中第k个anchor的
表示输出层第(i, j)个grid中第k个anchor的![]() 的均值,
的均值,![]() 表示对应的
表示对应的![]() 的不确定性。
的不确定性。
![]() 表示
表示![]() 的Ground Truth,不同坐标信息的GT值编码方式不同,如下所示:
的Ground Truth,不同坐标信息的GT值编码方式不同,如下所示:
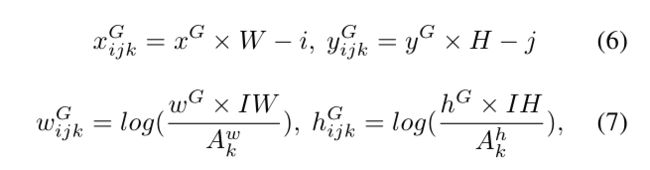
其中,![]() 分别表示GT框在原图中的比例,
分别表示GT框在原图中的比例,![]() 分别表示resize后的图像宽和高,
分别表示resize后的图像宽和高,![]() 分别表示第k个anchor的宽和高。
分别表示第k个anchor的宽和高。
此外,加权参数 的计算方式如下:
的计算方式如下:

简单解释一下,越小的GT框分配的权重越大,反之亦然。另外, 的含义同原版YOLO,是一个判别函数,只对当前最匹配的那个anchor进行训练。
的含义同原版YOLO,是一个判别函数,只对当前最匹配的那个anchor进行训练。
由于原版YOLO v3中使用MSE来回归bbox,它不能在训练过程中处理嘈杂数据。然而,Gaussian YOLOv3中重新设计的损失函数可以提供一个对不一致数据的惩罚,即可以通过一致性较强的数据来学习模型。也因此,重新设计的bbox loss使得模型对嘈杂数据更具有鲁棒性。
3.3 利用定位不确定性
在原版YOLOv3计算框综合得分的基础上,再乘上本文提出的(不)确定性,即得到最终的综合得分:
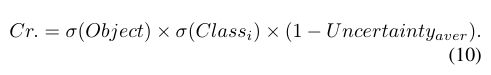
4 试验结果
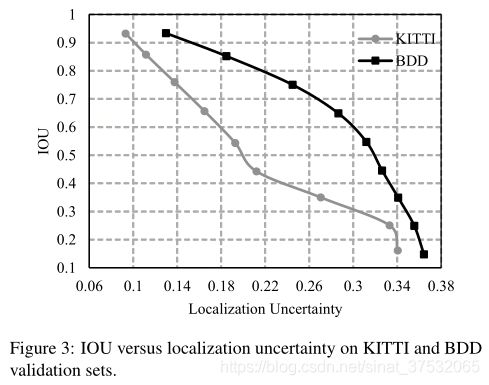
在KITTI/BDD数据集上测试,定位不确定性越大的框与GT的IoU越小,这符合直观认识,所以证明了本文所提方法的有效性。
mAP涨点:
- COCO +3.1%
- KITTI +3.09% (fps -0.44)
- BDD +3.5% (fps -0.4)