Python+selenium模块爬虫实战---拉勾网
Python+selenium模块爬虫实战---拉勾网
- 一. 项目需求
- 二. selenium概述
- 三. 爬虫思路
- 四. 代码实现
- 五. 完整代码
一. 项目需求
项目需求:实现一个可以自动获取拉钩网" 自定义搜索 "的岗位招聘信息的爬虫程序。
实现工具:Pycharm
运行环境:Python 3.9
二. selenium概述
Selenium是一个用于web应用程序自动化测试的工具,直接运行在浏览器当中,支持chrome、firefox等主流浏览器。可以通过代码控制与页面上元素进行交互(点击、输入等),也可以获取指定元素的内容。
作用:自动打开浏览器,模拟人一样的操作去操控浏览器,可以在selenium中直接提取网页上的各种信息。
关于selenium模块的使用和详解以下网址可供参考
http://www.selenium.org.cn/1598.html
三. 爬虫思路
1.导入selenium库及其他相关的库
2.创建一个浏览器对象
3.打开拉钩网址
4.实现点击所需地区的选择
5.打开检查,使用xpath定位到搜索框
6.使用input方法实现自定义搜索功能
7.查找所需招聘信息存放的位置,进行数据提取
四. 代码实现
1.导入selenium库及其他相关的库
#导入selenium库
from selenium.webdriver import Chrome
#导入键盘库
from selenium.webdriver.common.keys import Keys
#导入时间库
import time
导入的键盘库可以实现键盘输入功能,便于完成自定义搜索的需求。
2.创建一个浏览器对象并打开拉钩网址
#创建浏览器对象
web = Chrome()
#打开拉钩网址
web.get('https://www.lagou.com/')
3.实现点击所需地区的选择
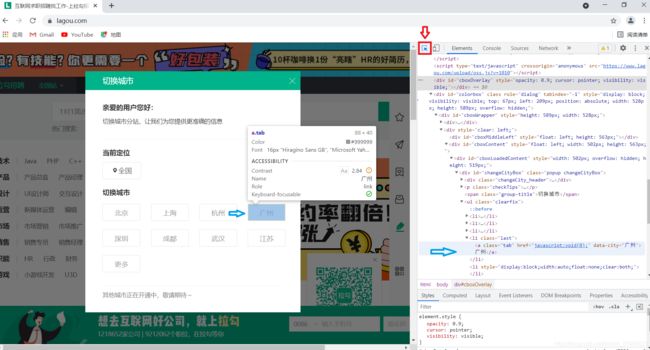
在页面任意空白区域点击右键,选择“ 检查 ”,点击如图红色方框内的小箭头,再回到页面进行所需城市的选取
如上图所示,在选取完城市广州后,在右边会有区域进行相互对应。
再在蓝色的区域进行鼠标右键点击,选择 Copy,再在其下选择 Copy XPath
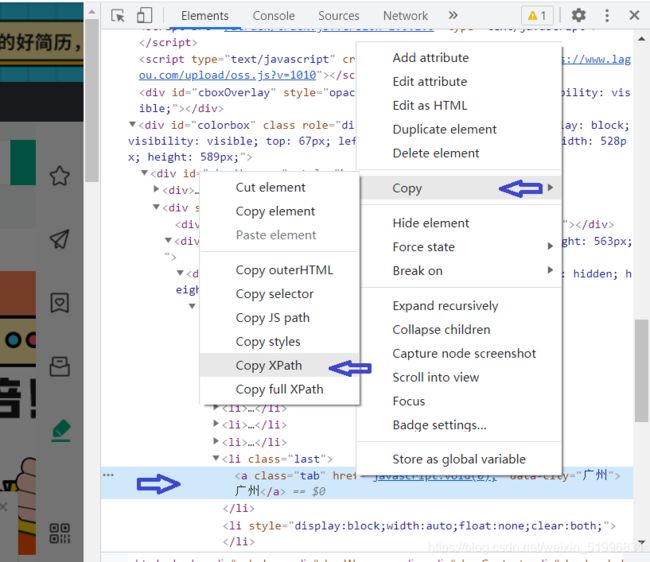
代码呈现
找到城市广州的元素,进行点击
el = web.find_element_by_xpath('//*[@id="changeCityBox"]/ul/li[4]/a')
el.click() #点击事件 click
4.打开检查,使用xpath定位到搜索框
实现步骤跟以上类似,使用检查里面的元素面板,获取到对应的XPath进行定位。
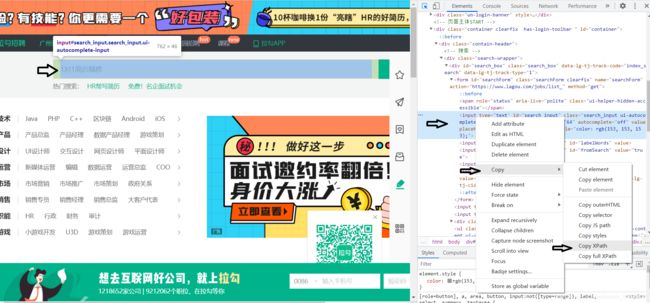
5.使用input方法实现自定义搜索功能
i = [input('输入搜索关键字:')]
web.find_element_by_xpath('//*[@id="search_input"]').send_keys(i,Keys.ENTER)
#key.ENTER:使用键盘库的enter键功能,效果同键盘的enter键一样。
time.sleep(1)
#加入休息时间,由于网页的运行没有程序快,如果跟不上那么则可能报错
7.查找所需招聘信息存放的位置,进行数据提取
由于搜索岗位后的岗位信息网页结构没有发生改变,故用搜索python岗位的信息为例,获取信息存放的位置,进行数据提取。
首先先定位获取到所有的招聘岗位的信息,如下图可以看到每个岗位的招聘信息(蓝色框)都是在大的红色框内的
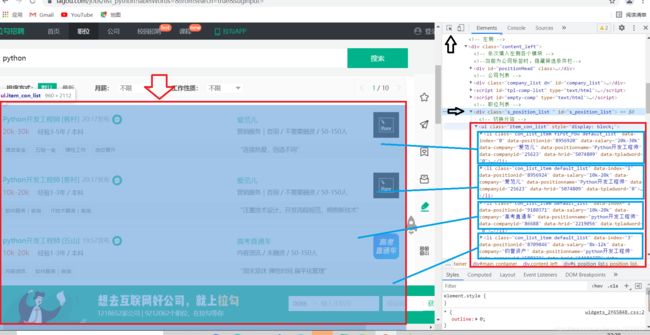
代码呈现
#查找存放数据的位置,进行数据提取
#找到页面中存放数据的所有list
li_list = web.find_elements_by_xpath('//*[@id="s_position_list"]/ul/li')
在以定位好的红色框内,再对蓝色框内的具体所需岗位信息进行细化提取,使用for循环将每一条招聘信息提取出来。方法同上,使用Copy XPath的值即可快速定位到所需的信息。
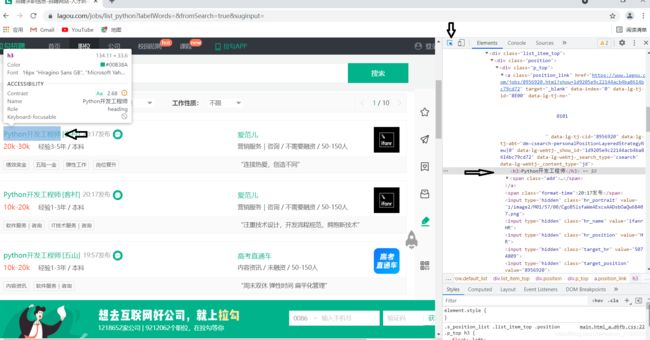
此处就只演示获取岗位的名称信息,小博主本着“ 授人以鱼不如授人以渔 ”的想法,其余的岗位信息都可以使用同样的操作步骤进行定位爬取
代码呈现
for li in li_list:
#注意结尾要加text保存成文本
job_name = li.find_element_by_tag_name('h3').text
company = li.find_element_by_xpath('./div/div[2]/div/a').text
job_price = li.find_element_by_xpath('./div[1]/div[1]/div[2]/div').text
#此处就只爬取3个信息示例
print('职位:',job_name,'公司:',company,'工资及相关要求:',job_price)
爬取效果呈现:
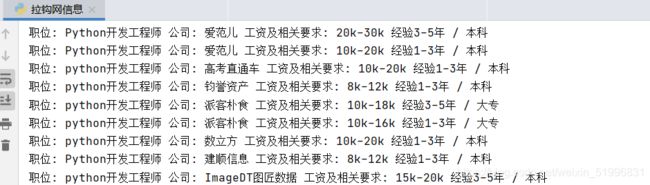
五. 完整代码
小博主第一次发博客,制作不易,看完的点个赞支持一下小博主叭,加油加油!
from selenium.webdriver import Chrome
#导入键盘库
from selenium.webdriver.common.keys import Keys
#导入时间库
import time
#创建浏览器对象
web = Chrome()
#打开拉钩网址
web.get('https://www.lagou.com/')
#找到元素,点击
el = web.find_element_by_xpath('//*[@id="changeCityBox"]/ul/li[4]/a')
el.click() #点击事件 click
i = [input('输入搜索关键字:')]
web.find_element_by_xpath('//*[@id="search_input"]').send_keys(i,Keys.ENTER)
#加入休息时间,由于网页的运行没有程序快,如果跟不上那么则可能报错
time.sleep(1)
#查找存放数据的位置,进行数据提取
#找到页面中存放数据的所有list
li_list = web.find_elements_by_xpath('//*[@id="s_position_list"]/ul/li')
for li in li_list:
#注意结尾要加text保存成文本
job_name = li.find_element_by_tag_name('h3').text
company = li.find_element_by_xpath('./div/div[2]/div/a').text
job_price = li.find_element_by_xpath('./div[1]/div[1]/div[2]/div').text
print('职位:',job_name,'公司:',company,'工资及相关要求:',job_price)
哈哈哈如果对你有帮助的话不妨点个赞吧,如对内容有任何调优意见欢迎指出!多多指教!!!