创建流
创建流的方式很多,从jdk8起,很多类中添加了一些方法来创建相应的流,比如:BufferedReader类的lines()方法;Pattern类的splitAsStream方法。但是开发中使用到Stream基本上都是对集合的操作,了解如下几种创建方式即可:
// 集合与数组
List list = new ArrayList<>();
String[] arr = new String[]{};
Stream listStream = list.stream();
Stream arrayStream = Arrays.stream(arr);
// 静态方法创建指定元素的流
Stream programStream = Stream.of("java", "c++", "c");
// 将多个集合合并为一个流
List sub1 = new ArrayList<>();
List sub2 = new ArrayList<>();
Stream concatStream = Stream.concat(sub1.stream(), sub2.stream());
// 提供一个供给型函数式接口, 源源不断创造数据, 创建无限流
// 如下创建一个无限的整数流, 源源不断打印10以内的随机数
Stream generateStream = Stream.generate(() -> RandomUtil.randomInt(10));
generateStream.forEach(System.out::println);
// limit可控制返回流中的前n个元素, 此处仅取前2个随机数打印
Stream limitStream = generateStream.limit(2);
limitStream.forEach(System.out::println);
中间操作
筛选
filter:入参为断言型接口(Predicate),即用于筛选出断言函数返回true的元素
limit:截断流,获取前n个元素的流
skip:跳过n个元素
distinct:通过流中元素的equals方法比较,去除重复的元素
这四个筛选类方法较为简单,示例如下:
List> source = ImmutableList.of(
ImmutableMap.of("id", 1),
ImmutableMap.of("id", 2),
ImmutableMap.of("id", 2),
ImmutableMap.of("id", 3),
ImmutableMap.of("id", 4)
);
Stream> target = source.stream()
// 先筛选出id > 1的数据
.filter(item -> Convert.toInt(item.get("id")) > 1)
.distinct() // 去重
.skip(1) // 跳过一个元素
.limit(1); // 只返回第一个元素
target.forEach(System.out::println); // 输出: {id=3}
映射
map
map方法入参为函数式接口(Function),即将流中的每个元素映射为另一个元素;
如下,取出source中的每个map元素,取id和age属性拼成一句话当做新的元素
List> source = ImmutableList.of(
ImmutableMap.of("id", 1, "age", 10),
ImmutableMap.of("id", 2, "age", 12),
ImmutableMap.of("id", 3, "age", 16)
);
Stream target = source.stream()
.map(item -> item.get("id").toString() + "号嘉宾, 年龄: " + item.get("age"));
target.forEach(System.out::println);
输出:
1号嘉宾, 年龄: 10
2号嘉宾, 年龄: 12
3号嘉宾, 年龄: 16
flatMap
map操作是将单个对象转换为另外一个对象,而flatMap操作则是将单个对象转换为多个对象,这多个对象以流的形式返回,最后将所有流合并为一个流返回;
List> source = ImmutableList.of(
ImmutableList.of("A_B"),
ImmutableList.of("C_D")
);
Stream target = source.stream().flatMap(item -> {
String data = item.get(0);
// 将数据映射为一个数组, 即:一对多
String[] spilt = data.split("_");
// 由泛型可知, 需要返回流的形式
return Arrays.stream(spilt);
});
target.forEach(System.out::println); // 依次打印A、B、C、D
排序
sorted
对流中的元素进行排序,默认会根据元素的自然顺序排序,也可传入Comparator接口实现指定排序逻辑
List source = ImmutableList.of(
10, 1, 5, 3
);
source.stream()
.sorted()
.forEach(System.out::println); // 打印: 1、3、5、10
source.stream()
.sorted(((o1, o2) -> o2 - o1))
.forEach(System.out::println); // 打印: 10、5、3、1
消费
peek
该方法主要目的是用来调试,接收一个消费者函数,方法注释中用例如下:
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
实际使用很少,并不需要这么来调试问题
终结操作
查找与匹配
allMatch:检查是否匹配流中所有元素
anyMatch:检查是否至少匹配流中的一个元素
noneMatch:检查是否没有匹配的元素
findFirst:返回第一个元素
findAny:返回任意一个元素
max/min/count:返回流中最大/最小/总数
List source = ImmutableList.of(
10, 1, 5, 3
);
// 元素是否都大于0
System.out.println(source.stream().allMatch(s -> s > 0));
// 是否存在元素大于9
System.out.println(source.stream().anyMatch(s -> s > 9));
// 是否不存在元素大于10
System.out.println(source.stream().noneMatch(s -> s > 10));
// 返回第一个元素, 若不存在则返回0
System.out.println(source.stream().findFirst().orElse(0));
// 任意返回一个元素, 若不存在则返回0
System.out.println(source.stream().findAny().orElse(0));
reduce
该方法可用于聚合求值,有三个重载方法;
reduce(BinaryOperatoraccumulator) reduce(T identity, BinaryOperatoraccumulator) reduce(U identity, BiFunction
先看第一种重载形式:
当入参仅为函数式接口BinaryOperator时,定义了如何将流中的元素聚合在一起,即将流中所有元素组合成一个元素;注意到BinaryOperator接口继承自BiFunction,从泛型可知接口入参和出参都是同类型的
// 查询出在不同年龄拥有的财产
List> source = ImmutableList.of(
ImmutableMap.of("age", 10, "money", "21.2"),
ImmutableMap.of("age", 20, "money", "422.14"),
ImmutableMap.of("age", 30, "money", "3312.16")
);
// 计算年龄总和和财产总和
Map res = source.stream().reduce((firstMap, secondMap) -> {
Map tempRes = new HashMap<>();
tempRes.put("age", Integer.parseInt(firstMap.get("age").toString())
+ Integer.parseInt(secondMap.get("age").toString()));
tempRes.put("money", Double.parseDouble(firstMap.get("money").toString())
+ Double.parseDouble(secondMap.get("money").toString()));
// 流中的元素是map, 最终也只能聚合为一个map
return tempRes;
}).orElseGet(HashMap::new);
System.out.println(JSONUtil.toJsonPrettyStr(res));
// 输出
{
"money": 3755.5,
"age": 60
}
BinaryOperator函数的两个入参如何理解呢?如下:
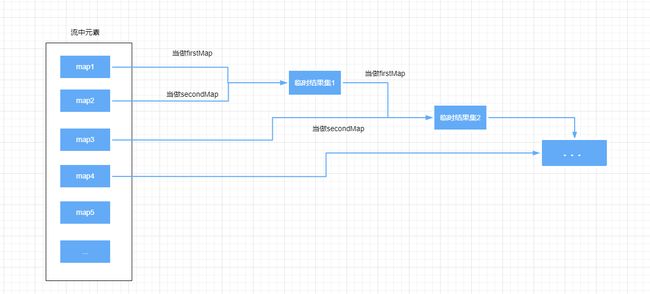
容易看出其含义就是将流中元素整合在一起,但是这种方法的初始值就是流中的第一个元素,能否自定义聚合的初始值呢?
这就是第二种重载形式了,显然,第一个参数就是指定聚合的初始值;
紧接着上个例子,假设人一出生就拥有100块钱(100块都不给我?),如下:
List> source = ImmutableList.of(
ImmutableMap.of("age", 10, "money", "21.2"),
ImmutableMap.of("age", 20, "money", "422.14"),
ImmutableMap.of("age", 30, "money", "3312.16")
);
// 计算年龄总和和财产总和
Map res = source.stream().reduce(ImmutableMap.of("age", 0, "money", "100"),
(firstMap, secondMap) -> {
Map tempRes = new HashMap<>();
tempRes.put("age", Integer.parseInt(firstMap.get("age").toString())
+ Integer.parseInt(secondMap.get("age").toString()));
tempRes.put("money", Double.parseDouble(firstMap.get("money").toString())
+ Double.parseDouble(secondMap.get("money").toString()));
// 流中的元素是map, 最终也只能聚合为一个map
return tempRes;
});
System.out.println(JSONUtil.toJsonPrettyStr(res));
// 输出
{
"money": 3855.5,
"age": 60
}
注意到第一种形式没有指定初始值,所以会返回一个Optional值,而第二种重载形式既定了初始值,也就是不会为空,所以返回值不需要Optional类包装了。
如上我们既可以定义初始值,又可以定义聚合的方式了,还缺什么呢?
有一点小缺就是上面两种返回的结果集的类型,跟原数据流中的类型是一样的,无法自定义返回的类型,这点从BinaryOperator参数的泛型可以看出。
所以第三种重载形式出场了,既可自定义返回的数据类型,又支持自定义并行流场景下的多个线程结果集的组合形式;
如下返回Pair类型:
List> source = ImmutableList.of(
ImmutableMap.of("age", 10, "money", "21.2"),
ImmutableMap.of("age", 20, "money", "422.14"),
ImmutableMap.of("age", 30, "money", "3312.16")
);
// 计算年龄总和和财产总和
Pair reduce = source.stream().reduce(Pair.of(0, 100d),
(firstPair, secondMap) -> {
int left = firstPair.getLeft()
+ Integer.parseInt(secondMap.get("age").toString());
double right = firstPair.getRight() +
+Double.parseDouble(secondMap.get("money").toString());
return Pair.of(left, right);
}, (o, n) -> o);
System.out.println(JSONUtil.toJsonPrettyStr(reduce));
其中(o, n) -> o是随便写的,因为在顺序流中这段函数不会执行,也就是无效的,只关注前两个参数:如何定义返回的数据和类型、如何定义聚合的逻辑。
坑点:
- 如果创建并行流,且使用前两种重载方法,最终得到的结果可能会和上面举例的有些差别,因为从上面的原理来看,reduce中的每一次运算,下一步的结果总是依赖于上一步的执行结果的,像这样肯定无法并行执行,所以并行流场景下,会有一些不同的细节问题
- 当创建并行流,且使用了第三种重载方法,得到的结果可能和预期的也不一样,这需要了解其内部到底是如何聚合多个线程的结果集的
目前开发中没有详细使用并行流的经验,有待研究
collect
collect是个非常有用的操作,可以将流中的元素收集成为另一种形式便于我们使用;该方法需要传入Collector类型,但是手动实现此类型还比较麻烦,通常用Collectors工具类来构建我们想要返回的形式:
| 构建方法 | 说明 |
|---|---|
| Collectors.toList() | 将流收集为List形式 |
| Collectors.toSet() | 将流收集为Set形式 |
| Collectors.toCollection() | 收集为指定的集合形式,如LinkedList...等 |
| Collectors.toMap() | 收集为Map |
| Collectors.collectingAndThen() | 允许对生成的集合再做一次操作 |
| Collectors.joining() | 用来连接流中的元素,比如用逗号分隔元素连接起来 |
| Collectors.counting() | 统计元素个数 |
| Collectors.summarizingDouble/Long/Int() | 为流中元素生成统计信息,返回的是一个统计类 |
| Collectors.averagingDouble/Long/Int() | 对流中元素做平均 |
| Collectors.maxBy()/minBy() | 根据指定的Comparator,返回流中最大/最小值 |
| Collectors.groupingBy() | 根据某些属性分组 |
| Collectors.partitioningBy() | 根据指定条件 |
如下举例一些使用:
toList/toSet/toCollection
将元素收集为集合形式
List> source = ImmutableList.of(
ImmutableMap.of("name", "小明", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小红", "grade", "a2", "sex", "2"),
ImmutableMap.of("name", "小白", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小黑", "grade", "a3", "sex", "1"),
ImmutableMap.of("name", "小黄", "grade", "a4", "sex", "2")
);
// toSet类似, toCollection指定要返回的集合即可
List toList = source.stream()
.map(map -> map.get("name").toString())
.collect(Collectors.toList());
System.out.println(toList); // [小明, 小红, 小白, 小黑, 小黄]
collectingAndThen
收集为集合之后再额外做一次操作
List andThen = source.stream()
.map(map -> map.get("name").toString())
.collect(Collectors.collectingAndThen(Collectors.toList(), x -> {
// 将集合翻转
Collections.reverse(x);
return x;
}));
// 由于上述方法在toList之后, 增加了一个函数操作使集合翻转, 所以结果跟上个示例是反的
System.out.println(andThen); // [小黄, 小黑, 小白, 小红, 小明]
toMap
收集为map,使用此方法务必要传入第三个参数,用于表明当key冲突时如何处理
Map toMap = source.stream()
.collect(Collectors.toMap(
// 取班级字段为key
item -> item.get("grade").toString(),
// 取名字为value
item -> item.get("name").toString(),
// 此函数用于决定当key重复时, 新value和旧value如何取舍
(oldV, newV) -> oldV + "_" + newV));
System.out.println(toMap); // {a1=小明_小白, a2=小红, a3=小黑, a4=小黄}
summarizingDouble/Long/Int
可用于对基本数据类型的数据作一些统计用,使用很少
// 对集合中sex字段统计一些信息
IntSummaryStatistics statistics = source.stream()
.collect(Collectors.summarizingInt(map -> Integer.parseInt(map.get("sex").toString())));
System.out.println("平均值:" + statistics.getAverage()); // 1.4
System.out.println("最大值:" + statistics.getMax()); // 2
System.out.println("最小值:" + statistics.getMin()); // 1
System.out.println("元素数量:" + statistics.getCount()); // 5
System.out.println("总和:" + statistics.getSum()); // 7
groupingBy
分组是用得比较多的一种方法,其有三种重载形式:
groupingBy(Function classifier)groupingBy(Function classifier, Collector downstream)groupingBy(Function classifier, SuppliermapFactory, Collector downstream)
点进源码中很容易发现,其实前两种都是第三种的特殊形式;
从第一种重载形式看起:
Function classifier:分类器,是个Function类型接口,此参数用于指定根据什么值来分组,Function接口返回的值就是最终返回的Map中的key
List> source = ImmutableList.of(
ImmutableMap.of("name", "小明", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小红", "grade", "a2", "sex", "2"),
ImmutableMap.of("name", "小白", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小黑", "grade", "a3", "sex", "1"),
ImmutableMap.of("name", "小黄", "grade", "a4", "sex", "2")
);
Map>> grade = source.stream()
.collect(Collectors.groupingBy(item -> item.get("grade") + "-" + item.get("sex")));
System.out.println(JSONUtil.toJsonPrettyStr(grade));
根据班级+性别组合成的字段分组,结果如下(省略了一部分):
{
"a4-2": [
{
"sex": "2",
"grade": "a4",
"name": "小黄"
}
],
"a1-1": [
{
"sex": "1",
"grade": "a1",
"name": "小明"
},
{
"sex": "1",
"grade": "a1",
"name": "小白"
}
],
...
}
可以看到key是Function接口中选择的grade+sex字段,value是原数据集中元素的集合;
既然key的形式可以控制,value的形式如何控制呢?这就需要第二种重载形式了
Collector downstream:该参数就是用于控制分组之后想返回什么形式的值,Collector类型,所以可以用Collectors工具类的方法来控制结果集形式;根据此特性,可以实现多级分组;
点进第一种重载方法源码中可以看到,不传第二个参数时,默认取的是Collectors.toList(),所以最后返回的Map中的value是集合形式,可以指定返回其他的形式。
比如上个例子,分组之后返回每组有多少个元素就行,不需要具体元素的集合
List> source = ImmutableList.of(
ImmutableMap.of("name", "小明", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小红", "grade", "a2", "sex", "2"),
ImmutableMap.of("name", "小白", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小黑", "grade", "a3", "sex", "1"),
ImmutableMap.of("name", "小黄", "grade", "a4", "sex", "2")
);
Map collect = source.stream()
.collect(Collectors.groupingBy(item -> item.get("grade") + "-" + item.get("sex"),
Collectors.counting()));
System.out.println(JSONUtil.toJsonPrettyStr(collect));
结果就是返回的Map中的value是元素个数了:
{
"a4-2": 1,
"a1-1": 2,
"a3-1": 1,
"a2-2": 1
}
再看最后返回的结果集Map,其中的key和value都可以自由控制形式了,那Map类型具体到底是哪个实现类呢?这就是第三种重载形式的作用了
Supplier mapFactory:从参数名显而易见就是制造map的工厂,Supplier供给型接口,即指定返回的Map类型就行
如果没有使用此参数指定Map类型,那么默认返回的就是HashMap实现,这点从方法源码中很容易看到
紧接着上个例子,返回LinkedHashMap实现
List> source = ImmutableList.of(
ImmutableMap.of("name", "小明", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小红", "grade", "a2", "sex", "2"),
ImmutableMap.of("name", "小白", "grade", "a1", "sex", "1"),
ImmutableMap.of("name", "小黑", "grade", "a3", "sex", "1"),
ImmutableMap.of("name", "小黄", "grade", "a4", "sex", "2")
);
Map collect = source.stream()
.collect(Collectors.groupingBy(item -> item.get("grade") + "-" + item.get("sex"),
LinkedHashMap::new,
Collectors.counting()));
System.out.println(JSONUtil.toJsonPrettyStr(collect));
System.out.println(collect instanceof LinkedHashMap);
输出:
{
"a4-2": 1,
"a1-1": 2,
"a2-2": 1,
"a3-1": 1
}
true
partitioningBy
分区也是分组的一种特殊表现形式,分区操作返回的结果集Map中的key固定为true/false两种,含义就是根据入参的预测型接口将数据分为两类,类比分组即可;