Deep Feedback Network for Recommendation用于推荐系统的深度反馈网络
整篇文章与传统的推荐算法模型做了相应的对比, 对传统算法而言, 这篇文章将所有的信息反馈做了细致的划分:
隐式积极反馈/隐式消极反馈 显示积极反馈/显示消极反馈, 隐式反馈与显示反馈的区别在于用户的行为模式。如下图所示:

在上图中,通过按钮的方式表示dislike action 就是显示反馈, 通过下滑item 条目表示隐式dislike action 反馈。文章当中也做了相应的说明:
1 显示反馈在实际的数据中占比是比较小的
2 隐式积极反馈与隐式消极反馈的占比相对而言较多。
3 隐式消极反馈中存在真隐式消极反馈与噪声(假阳性),这部分数据无法明显体现用户是真dislike action 还是假dislike action。 informative user behaviors 的类别区分。
针对以上的观点, 论文同时考虑了三个方面, 隐式积极反馈,隐式消极反馈,显示消极反馈以及噪声四个方面,噪声和隐式消极反馈之间天然存在稀缺斗争性, 也就是说人眼是无法分别出来的。论文在红色部分提出了该概念:

整个网络大致分为两个两个部分, 如下图所示:

图a 为论文提出算法整体结构, 图b 为不同种类的用户信息反馈的交互结构。该结构主要的目的是为了得到用户的行为偏好。
论文实验在实际的微信 wechat top stories 场景中做了真实的上线, 并且在abalation 数据集中做了对比实验,并做了算法的健壮性, 有效性以及数据分析。主要的贡献如下:
1 论文是第一个考虑结合隐私反馈,显示反馈两个方面(消极以及积极)的交互算法应用于深度神经推荐系统中。
2 论文提出了一个新的深度反馈网络(这里的反馈区别于神经网络系统系统),指的是用户反馈信息的深度交互。应用了内部以及外部交互学习用户偏好的无偏估计。同时考虑了多层次反馈损失的优化问题。
3 论文算法在离线以及在线两个方面的应用有着明显的改进,同时系统的健壮性以及有效性在真实的推荐应用场景中有明显效果。
首先提出几个问题:
作者是如何将反馈信息进行交互,图2 b中的结构如何通过数学模型去构建, 这是图2 a的输入。 同时, 图2a 中的三个组件的原理是什么, 输入是什么, 输出是什么, 如何将三个输出进行组合,并得到输出。 采用softmax 函数的到概率所表示的含义是什么。这几个问题是文章研究的重点。
在文章的介绍部分提出了一个重要的概念CTR(Click-Through Rate),原文是这样说的:

首先作者将隐式积极反馈点击行为序列考虑为一个集合![]() 。
。
将显示消极反馈序列考虑为![]() 集合。
集合。
将隐式消极反馈序列考虑为![]() 集合。
集合。

论文作者认为可以从高质量的隐式积极反馈 和 显示消极反馈作为指导, 从隐式消极反馈中提取出有用的信息。同时这样的信息在DFN 结构中很容易添加到 隐式积极反馈 和 显示消极反馈 中。 从这里可以看出, 作者给了我们重要的论文工作内容的方向和具体的内容。回到图2 的结构中:
 作者将三种反馈信息的序列的头部添加了一个目标item向量元素, 整个序列扩展到n+1 的维度。
作者将三种反馈信息的序列的头部添加了一个目标item向量元素, 整个序列扩展到n+1 的维度。
![]() t 表示target item。这里是无法知道该结构的数据具体的组织形式, 但是文章中给出了具体的提示:
t 表示target item。这里是无法知道该结构的数据具体的组织形式, 但是文章中给出了具体的提示:
因此可以得到,该结构所表示的所有数据将会呈现出一个矩阵。池化的操作针对的就是矩阵。有关池化的具体原理,可以参照图像处理的相关知识。
回到前面,作者通过在向量的头部添加一个target item 元素实现了self -attention, 同时将所有的用户行为映射到了一个联合的语义空间中:
在以上的文章句子中提到一个非常关键的点:position embeddings 。 这可能跟数据的组织形式有关,假设存在n 个target item, 以及n 个用户, 那么数据的维度为n*n。 数据矩阵类似传统的评分矩阵,是极度稀疏的。 三种类型的反馈信息都采用这样的模式去处理,得到了三个n*n矩阵。
为了进一步处理, 作者提出了三个参数概念:

查询,键,值。分别对应Q,K,V 。同时采用了插值加权处理。作为投影矩阵。
接下来计算self-attention:


蓝色线框中为池化,
公式(1)-(4)为transformer。 转化器。公式(5)的输出结果为隐含积极反馈信息,通过同样的方式可以得到显示的消极反馈以及隐含的消极反馈输出向量 ![]() 以及
以及![]() 。这样总共得到了fc,fd,fu 三种不同类型用户反馈信息。这种信息是target-item 和用户行为之间的反馈信息。这些信息可以刻画用户的积极与消极的偏好-针对某一个target- item。
。这样总共得到了fc,fd,fu 三种不同类型用户反馈信息。这种信息是target-item 和用户行为之间的反馈信息。这些信息可以刻画用户的积极与消极的偏好-针对某一个target- item。
以上是出于内部反馈, 同时论文考虑可外部反馈信息。因此定义了 external feedback interaction component 组件去对接这样的工作。从某种意义上说,隐含消极的反馈信息是属于外部反馈。而隐含的积极反馈以及显示的消极反馈属于内部反馈(个人理解哈)。外部反馈隐含着隐含消极信息,需要通过一些精细的策略去筛选出来。因此,论文定义这样一个external feedback interaction component 组件就是为了 区分用户是真的喜欢和不喜欢行为(针对items)。
首先反馈信息有着强弱之分,click 和dislike 属于高质量的强反馈。接下来作者分别将隐含的正反馈和显示的负反馈嵌入式向量fc以及fd 为基础 从fu向量中去获取积极的和消极的偏好,增强fc以及fd。

公式(6)、(7)实现了这样的工作。其中MLP是一个两层的感知器。多层感知器结构如下所示:
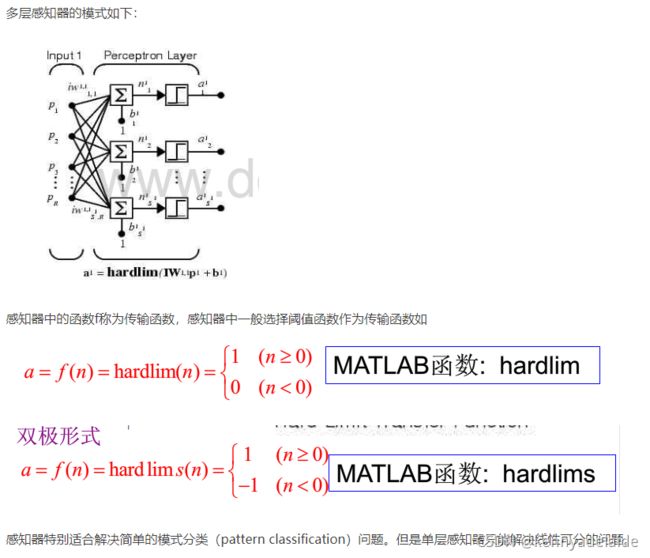
详细的资料可以参考https://blog.csdn.net/xufuyuan/article/details/77816698
fd 可以帮助从用户不喜欢的行为中提取到真正不喜欢的行为。 同时论文作者将不喜欢的行为中积极的信号进行放大处理,fc 就是放大信号的放大器。具体公式如(8)所示:
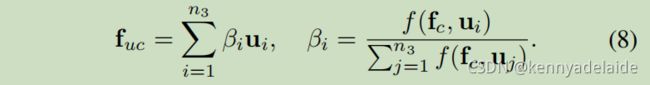
总结:fud是找到真正不喜欢的行为,而fuc 是找到真正喜欢的行为。最终得到了5个反馈特征。
除了隐式积极反馈与显示消极反馈被视为强信号,其余信号都视作弱信号。
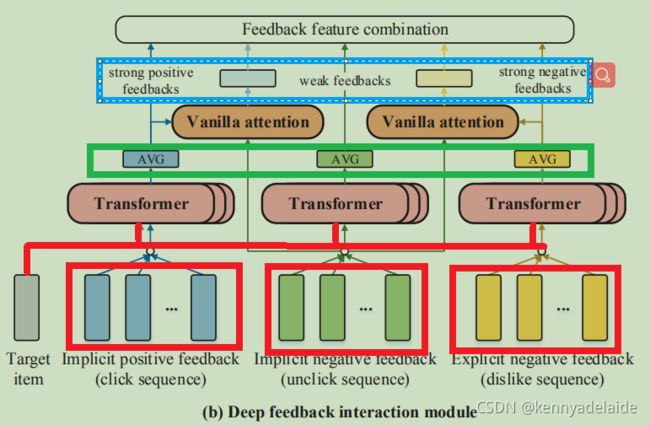
如图中蓝色部分所示。因此,deep feedback interaction module 的输出为5个特征。
回到图2 a的结构:首先要明确结构中的组成部分。在overall architecture 小节中明确的说到, the deep feedback interaction module takes multiple feedbacks as inputs to extract user unbiased positive and negative perferences.

从图2 a 中可以看出论文作者加入了other features and sparse features 两个数据特征。作者做了说明,可以是用户画像, 可以是items 画像,也可以是推荐文本信息特征。这个结构可以很好的将反馈与现实推荐系统的应用背景相结合。 跳过了评分矩阵计算的单一性,使得模型可伸缩。健壮性更好。数据特征来源也可以更丰富。要想使用这些特征信息,作者认为需要实现特征聚合。但是由于特征的表述方式的不一样,要想聚合特征在统一个标准下输出,需要对不同的特征数据进行不同的处理,之后再聚合。因此作者引入了, Wide,FM,Deep component 三个组件。 在论文的第3.3小节中,对该部分做了详细的说明。
Wide Component:
wide 采用了一个广泛应用于推荐系统的一个线性模型。在这篇文章中Wide & deep learning for recommender systems 对该线性问题做了详细的说明:论文提出了wide&deep 方法,包括wide以及deep两个部分。
使用wide 组件不得不提到的两个问题:
现在推荐系统的一个难点就是同时实现Memorization以及Generalization,这个难点与搜索排名问题相似。
1 Memorization:
之前大规模稀疏输入的处理是:通过线性模型 + 特征交叉。通过特征交叉能够带来很好的效果并且可解释性强。但是Generalization(泛化能力)需要更多的人工特征工程。
2 Generalization:
相比之下,DNN几乎不需要特征工程。通过对低纬度的dense embedding进行组合可以学习到更深层次的隐藏特征。但是,缺点是有点over-generalize(过度泛化)。推荐系统中表现为:会给用户推荐不是那么相关的物品,尤其是user-item矩阵比较稀疏并且是high-rank(高秩矩阵)
在wide 部分中使用了广义线性模型,可解释性强。而线性模型的输入是one-hot 编码后的稀疏特征。 因此通过在memorization 可以在特征上做特征交叉。特征交叉的原理是如果要做交叉特征的两个特征的取值相等,则对应的元素取值为1,否则为0, 从原理上来说, 仅仅是简单的交叉处理,对于高阶的特征组合是无法学习到内部隐含的特征。这种情况下需要引入人工特征。补充其特征的信息熵。但是隐藏的信息熵则被丢弃。
为了解决无法学习到高阶特征的隐藏信息熵,引入了deep 。主要的目的是发现高阶的特征组合。由于推荐算法的数据基本上是稀疏的,deep 引入了embedding-based 模型在稀疏的情况下学习到高维度特征组合。缺点是在high-rank 的时候,且数据稀疏的情况下很难学习到比较高质量的特征组合。但是dense embedding 会导致几乎所有的query-item的预测值都是非0,过度泛化。会推荐一些不想管的物品。
而wide&deep 结合了两者的有点,找到了memorization以及generalization 之间的平衡,效果有显著的提升。
wide&deep


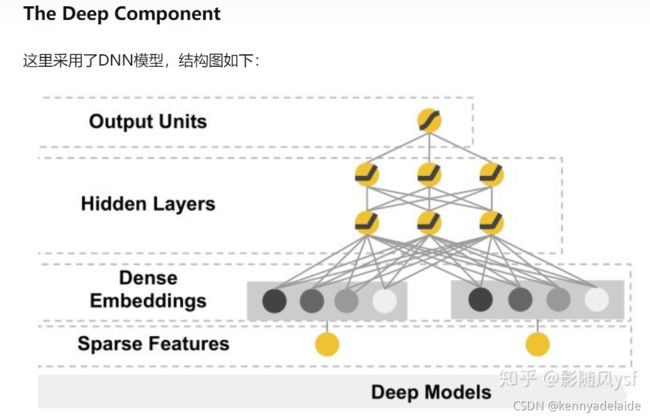
该模型使用了两层的感知器MLP。
推荐系统中Memorization和Generalization都十分重要,Wide&Deep模型实现了对Memorization和Generalization的统一建模
有关wide&deep参照了Wide & Deep Learning for Recommender Systems - 知乎

FM component:
FM 的目的是获取所有特征交互的二级特征, FM 的输入嵌入式向量由所有的dense features以及精炼过的反馈特征合并。表示如下:只是在其他特征的基础之上增加了一个特征向量维度。
![]()
将以上的向量作为一个输入,采用 策略得到一个FM 的输出:
公式(11) 所示 :

定义输出为:

最终三个component 的输出采用串联关系表示:

以上是整个算法结构的详细数学建模,最后论文提出了一个目标优化函数:该优化函数采用的是监督训练,其监督特征为click, unclick and dislike。 最总的输出结果是一个概率函数
 为聚合嵌入式特征。
为聚合嵌入式特征。
![]() 是sigmoid 函数。DFN 网络的loss 函数如下:
是sigmoid 函数。DFN 网络的loss 函数如下:

分为三个部分,对于三个监督特征向量。不同的损失权重衡量不同反馈的重要成程度。