爬虫进阶 -- 爬虫相关定义、反爬机制及其破解
经历了好几个小爬虫项目的“摧残”后,我想着不能白做,于是四处搜集和学习,便有了这篇笔记文章。
目录
一、定义
什么是爬虫和反爬虫
Headers相关概念
一种好用的爬虫
二、加解密网页源码
反爬机制
破解手段
三、实行访问IP限制
反爬机制
破解手段
四、监测用户行为
反爬机制
破解手段
五、Headers内容检测
UA限制
反爬机制
破解手段
反爬机制
破解手段
六、登陆验证码
反爬机制
破解手段
七、Ajax动态加载
反爬机制
破解手段
一、定义
什么是爬虫和反爬虫
- 爬虫:使用任何技术手段,批量获取网站信息的一种方式。
- 反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。
Headers相关概念
- host:提供了主机名及端口号
- Referer 提供给服务器客户端从那个页面链接过来的信息(有些网站会据此来反爬)
- Origin:Origin字段里只包含是谁发起的请求,并没有其他信息.(仅存于post请求)
- User agent: 发送请求的应用程序名(一些网站会根据UA访问的频率间隔时间进行反爬)
- proxies: 代理,一些网站会根据ip访问的频率次数等选择封ip.
- cookie: 特定的标记信息,一般可以直接复制,对于一些变化的可以选择构造.(session=requests.session()自动把cookie信息存入response对象中)
一种好用的爬虫
- 大型爬虫都用Scrapy框架,这个框架我没学过,但是很难。
- 还有一个简单好用的,那就是Python的Selenium包,这是一个模拟浏览器的程序,可以在其中编辑形成爬取程序,由于模拟浏览器,有效的避过了UA检查,也可以读取cookies,还由于加载了页面,不用考虑Ajax动态网页的问题。
二、加解密网页源码
反爬机制
加密网页源码,也就是把网页上显示的文本内容不直接写到网页的源码里,而是用CSS读取的字体文件来做密文(加密后的文本表示形式)到明文(网页上显示的文字)映射,当然,这个字体文件是自定义的,根据自己的加密规则。
通过修改字体文件,对文件内字体的unicode码进行加密,然后将该字体作为自定义字体进行加载到网页。也就是修改Unicode码到汉字的映射,以此加密网站内容,并没有禁止 “爬取” 这一行为,只是保证了爬虫或者爬虫操作者无法轻易地转码识别抓取到的内容。
另外这种方式还可以升级,准备多个字体库(不同的加密方式),每次刷新页面都会使用不同的字体库,这种方式相对于使用单独字体库来说难度又提升了一步。
通过自定义字体font-face来渲染页面内容,相对于其他方案更有效,但并不彻底,最终也只能提高抓取内容的难度,但能做到这一步已经能阻止大部分爬虫,因为加密之后,破解的难度和代价较高。比如大众点评网站和猫眼网站,对详情页面的敏感的数字和评论内容做了这种加密反爬。
具体的实现方法和理论参考 https://blog.csdn.net/zz_jesse/article/details/104191349以及https://zhuanlan.zhihu.com/p/37838586
破解手段
字体加密映射的解密方法:人工收集网站的特殊编码和对应的汉字的关系,有了这个映射表,就可以机器匹配出最终的内容。(难度不大,人工很费事)
三、实行访问IP限制
反爬机制
在不用登录的网站(比如一些新闻网站或京东购物网站),直接限制某个IP地址的访问频率(限制某一时间访问次数),即监测同一IP地址短时间内请求一定的次数即视为机器人,可以要求登录、要求人工验证身份或者直接拉黑IP处理。
通过并发识别爬虫:有些爬虫的并发是很高的,统计并发最高的IP,加入黑名单(或者直接封掉爬虫IP所在C段)
破解手段
1、开一个pool线程池,开50个,开多线程访问同一网页,让服务器反应不过来,这个时候想要的数据就已经全部提取出来了。
2、构造自己的 IP 代理池(就是费钱),然后每次访问时随机选择代理(但一些 IP 地址不是非常稳定,需要经常检查更新)。
3、分布式爬取,这个是针对大型爬虫系统的,实现一个分布式的爬虫,主要为以下几个步骤:1、基本的http抓取工具,如scrapy; 2、避免重复抓取网页,如Bloom Filter; 3、维护一个所有集群机器能够有效分享的分布式队列; 4、将分布式队列和Scrapy的结合; 5、后续处理,网页析取(如python-goose),存储(如Mongodb)。
四、监测用户行为
反爬机制
在需要登录才能看信息的网站(比如社交网站),可以长期监测,一旦有异常的用户行为,比如:
- 短时间内多次访问他人用户主页和动态资料
- 短时间多次登出登入
- 短时间多次换IP登陆
- 本身不发表正常动态和完善资料
- 本身是新注册不久的号
有这种情况,即要求人工验证身份或者直接封号处理,封号的同时,可以同时拉黑IP地址和MAC地址(更狠更彻底,比如FaceBook就是这样处理)。
破解手段
1、随机时间等待操作,在点击和点击或者滑动条操作之间,加上随机时间等待,时间长度视情况定,可以较短也可以很长。设置判断语句,在进行几个循环后额外等待一段时间。
2、隔几天停止程序,不持续操作。
3、写脚本,让账户自己发帖、转帖、点赞、评论甚至加好友。
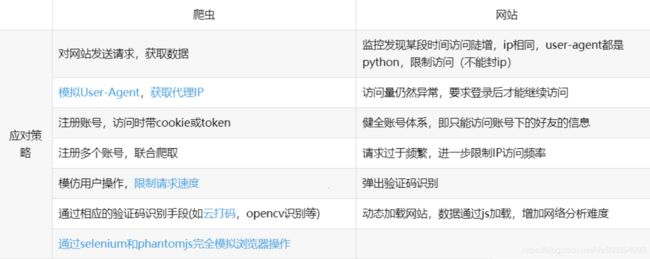
这里有一张他人的总结图片,我粘贴一下,参考文章在文末。
五、Headers内容检测
Headers进行反爬是最常见的反爬虫策略,还有一些网站会对 Referer (上级链接)进行检测(机器行为不太可能通过链接跳转实现)。
Headers,即HTTP请求的头部数据,服务器检测使用者发送的HTTP请求的此部分内容,达到排除恶意机器人的目的。
很多网站在用python的request包的方法申请访问的时候没有请求头访问会不成功,或者返回乱码,最简单的解决方式就是伪装成浏览器进行访问,这就需要添加一个请求头来伪装浏览器行为。
或者可以使用headless browser无头浏览器,没有前端界面(比如Selenium的chrome headless),直接绕过header检查,而且Selenium包的方法是模拟浏览器,直接省略伪装部分。
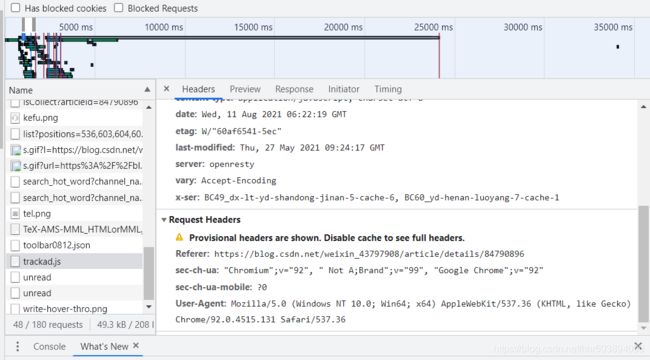
打开任意浏览器某一页面(要联网),按f12,然后点network,之后再按f5刷新网页,然后点击name里面的任意文件,之后右边有一个headers,点击headers找到request headers,这个就是浏览器的请求报头,复制里面的信息,编写自己的headers。
UA限制
反爬机制
UA即user-angent。
破解手段
构建自己的UA池,每次python做requests访问时随机挂上UA标识,更好的模拟浏览器行为,或者复制网站headers的默认信息。
cookie限制
反爬机制
浏览器端第一次打开网页,服务器会生成一个随机cookie并返回给浏览器,如果再次打开网页时这个cookie不存在,那么服务器会再次设置,第三次打开仍然不存在,这就非常有可能是机器人操作,也就是爬虫。
破解手段
在headers挂上相应的cookie或者根据其方法进行构造。先在模拟登陆时获取cookies,然后以后的登陆就可以读取cookies然后直接刷新网页完成登陆,就好像从来没下线过。
六、登陆验证码
反爬机制
超频的访问可以弹出动态生成的验证码输入,要求输入内容。
破解手段
图片验证码通过简单的图像识别即可以完成,比如截图,二值化、中值滤波去噪、分割、紧缩重排(让高矮统一)、字库特征匹配识别等。
通常验证码是一张图片,文本自然抓不出是什么,这一度难倒了大多数的攻击方,直到 OCR 的出现,JS 已经有许多开源的库了,就如 tesseract,只要调用一次 API,就能破解简单的验证码。
围绕验证码的攻防也是一个巨大的话题。防御方发觉验证码轻松被破,那么就要上难度更高的验证码,可以是更扭曲变形的文字,加入干扰线,混淆背景和文字的图片。越来越难的验证码,机器人自然很难识别,攻击方发觉单单的 OCR 已经无法拿取到图片内容了,新的玩法就产生了,上机器学习+OCR的模式了。
七、Ajax动态加载
反爬机制
Ajax动态加载的工作原理是:从网页的url加载网页的源代码之后,会在浏览器里执行JavaScript程序。这些程序会加载出更多的内容,并把这些内容传输到网页中。这就是为什么有些网页直接爬它的URL得不到数据。
破解手段
过去一直用抓包分析json数据来破解Ajax动态加载的网页,现在可以直接用模拟浏览器(Selenium)来进行爬虫,快速便捷,而且不怕动态加载。
参考文章:
https://www.nowcoder.com/questionTerminal/ff855339df524980b7fdd2ac4c7006a0
https://www.cnblogs.com/angle6-liu/p/10451047.html
https://blog.csdn.net/zz_jesse/article/details/104191349
https://blog.csdn.net/qq_36869808/article/details/87715293
https://zhuanlan.zhihu.com/p/37838586
https://blog.csdn.net/weixin_30774813/article/details/113641105