web安全:口令构成分析(python实现)【代码+报告】
国科大web安全技术大作业,分析国内某网站以及yahoo泄露的600万口令,分析其特点并生成一个字典,由于是团队作业,这里只放上我的部分:分析口令长度以及口令结构特点。

目录
0. 程序结构:
1. 数据预处理
2.口令长度分析
基本思路
结果存储:
分析结果
3.口令构成分析
第一步:逐位判断口令组成
第二步:统计每种结构的数量
第三步:输出处理
分析结果
4.常见口令分析
基本思路
分析结果
代码:web安全:口令构成分析(python实现)【代码】-网络攻防文档类资源-CSDN下载
0. 程序结构:
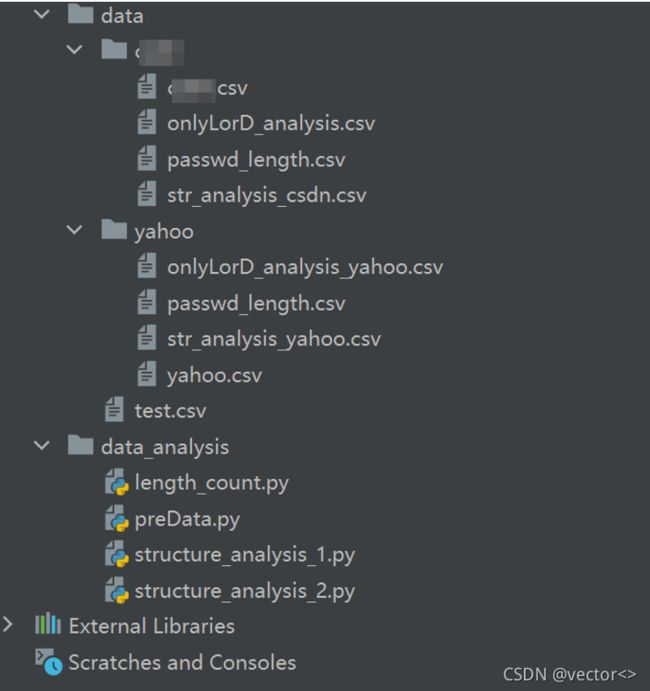
程序结构如上图所示,data文件夹中存储的.csv文件为原始数据集以及数据处理结果。data_analysis文件夹中存储的脚本用于数据预处理以及口令分析,具体结构如下表所示:
| 输入 |
脚本 |
输出 |
| bsdn.csv |
preData.py |
bsdn.csv |
| bsdn.csv |
length_count.py |
passwd_length.csv |
| bsdn.csv |
structure_analysis_1.py |
str_analysis_bsdn.csv |
| bsdn.csv |
structure_analysis_2.py |
onlyLorD_analysis.csv |
1. 数据预处理
preData.py->bsdn.csv
提供的数据集用sql格式存储,为了方便统计,本实验选取.csv格式的文件进行处理。相比较于.sql格式和.txt格式,csv格式有以下优点:
- 存储容量较小,对于600w数据,txt存储需要28wKB,而.csv存储只需要7wKB,更小的容量意味着更快的处理速度,对大数据集而言更加友好。
- .csv的数据可以直接用excel打开并编辑,因此可以直接在excel中绘图统计
观察所给数据可以发现,第一列为用户名,第二列为口令,第三列为邮箱,本次实验只需要用到第二列,为了进一步加快处理速度,因此有必要对原始数据集进行删减。
基本思路是将数据读入后,逐行遍历,并将每行数据用空格分割,只保留分割后的第三列数据,存入一个.csv文件中,并且为该文件添加一个表头passwd
| while line: count=count+1 # count用来观察数据处理进度 a = line.split() b = a[2] # 这是选取需要读取的位数 list1.append(b) # 将其添加在列表之中 line = f.readline() print(count) f.close() |
处理后的数据如下所示:
2.口令长度分析
length_count.py-> passwd_length.csv
基本思路
分析口令:
建立一个存储口令数量的标记数组,数组大小暂定为100。逐行遍历口令,读取口令长度,并在长度所在的数组位置上+1。
| Python def countLength(self): count = 0 list = [0] * 100 for passwd in self.passwdList: count += 1 list[len(str(passwd)) - 1] += 1 print(count) # 仅记录文件处理进度 return list |
结果存储:
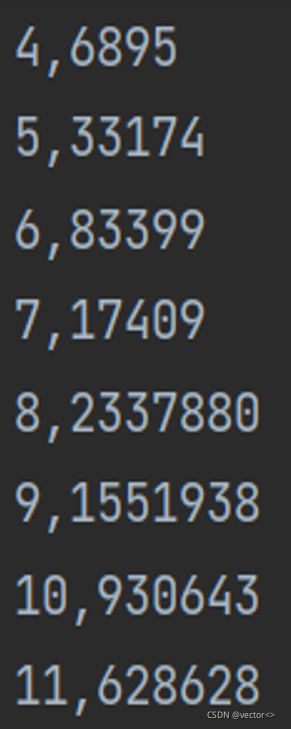
第一列表示口令长度,第二列表示口令数量。(4,6895)表示口令长度为4的口令共有6895个。
分析结果
下图为口令长度分析结果,可以看到排名最高的口令长度为8位,其次为9位和10位。

3.口令构成分析
structure_analysis_1.py-> str_analysis_bsdn.csv
基本思路
为了分析常见的口令结构,用‘L’表示字母,‘S’表示特殊字符,‘D’表示数字,口令‘abc#123’的结构表示为‘L3S1D3’,注意即使数字对应相同,字母、字符以及数字的顺序不同表示的也是不同的表结构,即‘L3S1D3’与‘S1D3L3’表示的是两种不同的结构。
本节口令结构分析主要分为三个步骤,第一步判断口令上的每一位的成分,第二步统计具有相同结构的口令数量,最后一步整理为‘LxSyDz’的形式并存储在.csv文件中,其中xyz分别表示字母、特殊字符以及数字的数量。接下来对每一个步骤进行简要的叙述,以如下三个口令组成的口令集作为例子。
| passwd abc?123 abc\123 avvvv?\22 第一个口令与第二个口令有相同的结构L3S1D3 第三个口令的结构为L5S2D2 |
第一步:逐位判断口令组成
| strucList = [] for passwd in self.passwdList: # 遍历每一行口令 struc = '' passwd = str(passwd) # 将passwd对象转为字符串 for ch in passwd: # 遍历每口令中的每一个字符 if ch.isdigit(): struc += 'D' elif ch.isalpha(): struc += 'L' else: struc += 'S' strucList.append(struc) |
遍历每一行口令的每个字符,如果是数字,在struc字符串中添加一个D,其他情况同理,最后将每行处理得到的struc存储在数组strucList中。在上文所举的例子,经过这一步后strucList将如下所示:
| strucList:['LLLSDDD', 'LLLSDDD', 'LLLLLSSDD'] |
可以看到第一个元素和第二个元素相同,这是因为前两个口令具有相同有的结构。
第二步:统计每种结构的数量
定义一个字典dic,存储键值对,键为口令结构,值为结构数量。逐个遍历第一步得到的strucList数组,统计出现的结构数量。
| nums = {} # 定义一个dic,键为口令结构,值为结构数量 for stru in strucList: # 在结构数组中遍历每一种结构 if stru in nums.keys(): # 如果该结构已经被统计(即在字典nums的键中能找),则结构出现次数+1 nums[stru] += 1 else: # 如果该结构没有被统计过,则更新字典,并将出现次数设定为1 nums[stru] = 1 |
经过第二步之后得到字典nums{}如下所述:
| dic: {'LLLSDDD': 2, 'LLLLLSSDD': 1} |
第三步:输出处理
这一步的主要工作是将分析得到的数据进行输出处理,这一步需要完成以下工作:
1、将’ LLLSDDD‘整理为’L3S1D3‘的形式
遍历第二步得到的nums{}字典的键,记录字符串中连续L、D、S的个数并记录在其后。遍历过程需要设定一个计数器,并在合适的位置进行更新。
2、计算每种结构出现的频率
在统计了数量之后,这一步只需要将数量除以总口令数即可
3、调整输出格式
DataFrame存储三列(第一列为口令结构,第二列为口令总数,第三列为频率)并最终输出到.csv文件中
| for x in nums.keys(): # 遍历字典的每一个键,即遍历每一种结构 char = x[0] # 将第一个字母定为标志字符 stru = x[1:] # stru为结构的第二个字符往后的字符串 c = 1 # 计数器置为1 res = '' for i in stru: # 遍历第二个字符往后的每一个字符 if i == char: # 如果某一个字符与第一个字符相同 c += 1 # 计数器加一 else: # 如果该字符与第一个字符不想图 res += char # 则将该字符存入结果字符串中 res += str(c) # 并且记录该字符的个数 char = i # 更新当前字符为标志字符 c = 1 # 重置计数器 res += char res += str(c)
df = DataFrame(columns=('structure', 'nums', 'freq')) # 输出csv文件的列名,共存储三列,分别存储口令结构,口令数量以及该结构口令出现的频率 df.loc[x]['structure'] = res ge = '{:.18f}'.format(int(nums[x]) * 1.0 / len(strucList)) # 计算频率 df.loc[x] = [x, nums[x], ge] |
经过处理后,上述例子的输出结果应为:
| structure,nums,freq L3S1D3 2 0.666 L5S2D2 1 0.333 |
分析结果
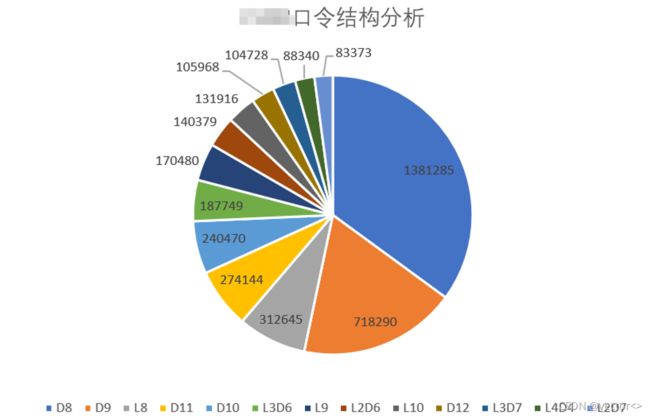
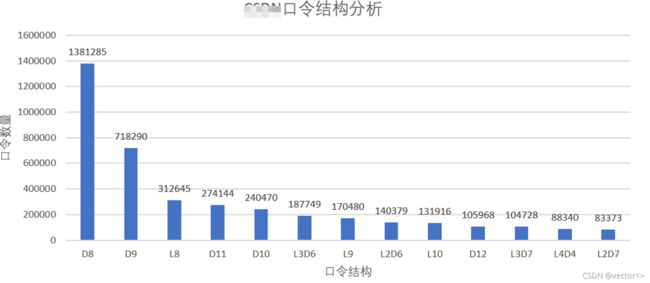
由下图的统计结果可知,最多的一种口令结果为’D8‘,即连续8个数字组合,后续分别为D9,L8等。
4.常见口令分析
structure_analysis_2.py-> onlyLorD_analysis.csv
基本思路
为了方便描述,本节将只含有数字,只含有字母,或只含特殊字符的口令称为纯口令。根据口令结构的分析结果,可以挑选出最常见的纯口令结构,本节将分析每一种纯口令结构最常用的十个口令以及他们的数量。
第一步:将最常见的口令结构设置为如下所示的字典。
| dic = {'L4': {}, 'L7': {}, 'L6': {}, 'L8': {}, 'L5': {}, 'L10': {}, 'L9': {}, 'L3': {}, 'L11': {}, 'L12': {}, 'D14': {}, 'D8': {}, 'D6': {}, 'D5': {}, 'D7': {}, 'D9': {}, 'D4': {}, 'D12': {}, 'L13': {}, 'L15': {}, 'L19': {}, 'L14': {}, 'L16': {}, 'D10': {}, 'L17': {}, 'D3': {}, 'L18': {}, 'D1': {}, 'D20': {},'L20': {}, 'D11': {}, 'L1': {}, 'L2': {}, 'D18': {}, 'D15': {}, 'D13': {}, 'D16': {}, 'S5': {}, 'S6': {}, 'D2': {}, 'S7': {}, 'S4': {}, 'S20': {}, 'S1': {}, 'S10': {}, 'S9': {}, 'D21': {}, 'D19': {}} |
第二步:逐行遍历原始口令数据集中的每一个口令,首先判断是否是纯口令,如果是纯口令则将其补充或更新到字典中。例如原始口令为‘abc’,经过该步骤处理后字典中对应的‘D3’行将更新为如下所示
| ‘D3’:{‘abc’,2} # 假设更新之前为‘D3’:{‘abc’,1} |
| Python for line in self.passwdList: # 遍历每一条口令 line = str(line) l = '' if patternLetter.match(line): # 如果是纯字母 l = 'L' + str(len(line)) elif patternDigit.match(line): # 如果是纯数字 l = 'D' + str(len(line)) elif patternSig.match(line): # 如果是纯特殊字符 l = 'S' + str(len(line)) if l in dic: # 去字典中查询该纯口令 if line in dic[l]: dic[l][line] += 1 # 记录该纯口令出现的次数 else: dic[l][line] = 1 |
第三步:逐行遍历第二步得到的字典,统计每一种纯口令结构的总数,并将每一种纯口令结构最常见的十种口令以及他们的总数存储在.csv文件中
| Python for tp in dic: # 逐行遍历字典 every_dic = dic[tp] # tp为字典中的逐个纯字符串,every_dic为每行的所有键值对 tp=S1 sums = sum(every_dic.get(x) for x in every_dic) # 记录纯字符串总数 every_dic={'*': 1, '%': 1} sums=2 rows = [tp, sums] # 键值对 every_dic = sorted(every_dic.items(), key=lambda x: x[1], reverse=True) # 给所有的字典值排序(按照数量,降序) for r in range(10): # 统计最常见的十种口令,不足十个的用0补齐 if r < len(every_dic): rows.append(str(every_dic[r])) else: rows.append(0) |
输出结果解释:经过处理后会得到如下结构的.csv文件:第一列存储纯口令结构,第二列表示该结构的口令总数,后十列分别存储该结构排名前十的口令以及数量。例如下图只能的第二行提供了一下信息:‘D8’是使用最多的口令结构,口令集合中一共有1381285个口令都是这一种结构,这些口令中最常使用的是‘12345678’这个口令(共212751个),其次为‘11111111’。
分析结果