【论文分享】Identifying Encrypted Malware Traffic with Contextual Flow Data
在某一节研讨课上对这篇文章进行了pre,是一篇非常经典的文章,本篇博客争取除了讲清楚文章之外,还能对文章中提到的一些陌生的概念做一个补充学习。有的地方都会在文章末尾补充概念学习哦,那我们现在开始吧~

目录
介绍
TLS流
DNS流
HTTP流
数据
数据来源
数据特征
分类
分类结果:
模型解释性:
真实数据分类
结论
补充知识
TLS
SAN
DMZ
马尔科夫链
正则项L1 L2
稀疏模型
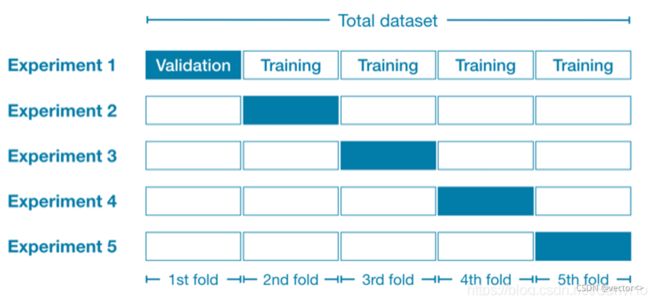
交叉验证
介绍
研究问题:在不损害加密完整性的情况下,识别加密网络中的恶意流量
❓为什么不解密后再识别:数据完整性+用户隐私+复杂度
研究对象:TLS数据流(在不破坏TLS协议的情况下,区分出恶意的TLS数据流)
研究方法:data omnia 数据全方位方法
收集与TLS流相关联的DNS和HTTP上下文数据,以及TLS本身的元数据共同进行判断。
❓DNS流,HTTP流与需要检测的TLS流有什么关系?
TLS流量不可能在网络中单独出现,在它出现之前或者之后总是会伴随着其他网络流量,这些在它前后出现的流量就是所谓的上下文。恶意的TLS除了本身有一些区别于正常流量的特点之外,与之相关联的上下文DNS流量和HTTP流量也会呈现出一些特征。
在做了简要介绍之后,作者需要阐述为什么DNS,HTTP上下文有利于分类,所以接下来的三个部分,作者统计正常TLS流量以及恶意TLS流量,分析他们的差异,主要是从三个角度分析差异:TLS本身,DNS以及HTTP。
TLS流

每一个部分作者都根据统计结果提出了非常多的差异,在这里只做简单的列举。
数据来源:
- 2016年1月至4月期间在ThreatGRID收集了21,417个具有完整TLS握手功能的恶意TLS流
- 2016年4月的5天期间收集1,130,386个良性TLS流。
1. 加密套件(client hello):
- 恶意流量通常在clientHello消息中提供一组三种过时的加密套件
- 0x002f 是良性流量中提供最多的加密套件
2. TLS扩展(client hello):
- 相较于良性流量,恶意数据中TLS扩展不够多样
- 恶意数据集中很少看到0x0005,0x3374,0xff01
3. SAN(certificate)
4. 有效期(certificate)
DNS流
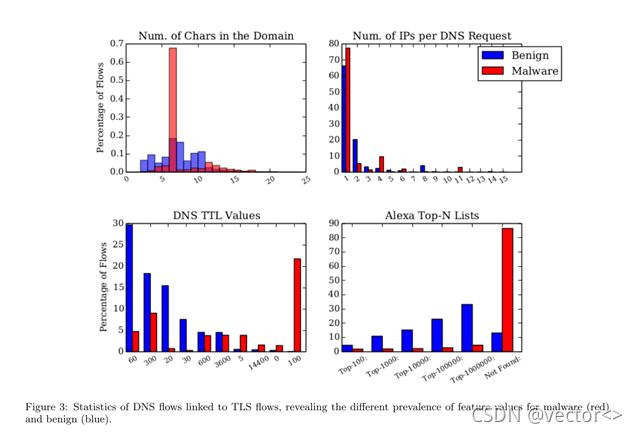
数据来源:
与TLS流的数据来源相同6,906,627个恶意DNS和8,060064个良性DNS响应
1.每个DNS请求返回的IP数目:
- 更多良性响应返回2和8个IP地址
- 更多恶意响应返回4和11个IP地址
2.TTL值:
- 正常DNS响应最常见的4个TTL值依次是60、300、20和30
- 恶意流量中TLL值20和30很少被观察到, TTL值300是恶意流量的第二常见值
HTTP流

数据来源: ThreatGRID
1.HTTP server 字段:
- 恶意流量最常说的是它使用的是一个无版本的nginx服务器
- 良性流量最常说的是它使用的是无版本的Apache
2 .HTTP return codes:
- 恶意流量最常见的返回码是200 302 301 404
- 402 503 303 400 几乎只在恶意流量中被返回
基于统计结果,得出来上述这么多差异之后,在下面这一小节,作者将要介绍数据,主要包括用于训练分类器的数据来源,这么多差异应该挑选哪些作为分类特征,这些数据特征又应该用什么表示。
数据
数据来源

上图是对所有数据的统计,实际可用的只有交集部分,这是以为其他部分的TLS流量缺少相关联的DNS或者HTTP
恶意数据
数据来源:2016年1月到4月从商用沙盒环境ThreatGRID中收集
良性数据:
数据来源:大型企业网络的DMZ收集,为期5天
实际上DMZ区中的流量也存在一些恶意流量,但是作者有强调在本篇文章的研究范畴内,认为DMZ流量就为良性流量
数据特征
1.Observable Metadata
经常会在论文中看到“元数据”,可以直接理解为数据本身
特征选取:
特征描述:
2.TLS Data
特征选取
3.DNS Data
- 域名长度
- 40个最常见的后缀+“other”
- 32个最常见的TTL值+“other”
- 数字字符数量
- 非字母数字字符数量
- DNS响应返回的IP地址数量
- 域名是否在Alexa列表中的前100名、前1000名、前10000名、前10万名、前100万名或未被找到
4.HTTP Data
1个二进制变量:在所有的数据流中,只要任何一个数据流具有http的头信息,就将这个变量标记为1
7个具体的特征值:HTTP outbound和inbound字段、Content-Type、User-Agent、AcceptLanguage、Server和code。
网上关于outbound和inbound字段的讯息很少,根据作者的描述,我认为可以理解为请求和响应字段
数据工具:
1.基于libpcap的自定义工具:用于解析TLS流,并捕获数据特性
2.Joy:将数据包捕获文件或实时收集的所有数据转换为方便的JSON格式
分类
模型:L1正则化的逻辑回归模型+10折交叉验证
逻辑回归模型可以理解为一个线性分类器+sigmoid
分类结果:

SPLT:数据包长度、到达时间序列
BD:字节分布
准确率描述:0.00% FDR
下面仅列举几个重要的分类结果
1.SPLT+BD+ TLS分类器在准确率为77.881%, 但是,一旦我们利用了额外的HTTP和DNS上下文,0.00%的FDR就变成了99.978%,一个显著的改进
2.SPLT+BD+ TLS的模型参数为250.7个,但是在加入了HTTP和DNS之后模型参数反而降到了189.7。
模型解释性:
按照影响权重对有利于给恶意流量进行分类的特征进行了排名,可以看到与DNS以及HTTP相关的特征都排在前列。

真实数据分类

数据来源:
在采集了初始数据集4周后从同一企业DMZ中收集的,为期4天
分类结果:
All:+HTTP+DNS
All Available:+任何可用的上下文流信息
使用DNS和HTTP上下文信息的分类器在验证数据集上的性能最好
结论
研究问题:在不损害加密完整性的情况下,识别加密网络中的恶意流量
data omnia 数据全方位方法
收集与TLS流相关联的DNS和HTTP上下文数据,以及TLS本身的元数据作为特征,能够将加密后恶意TLS流很好的识别出来,并且保护了数据完整性,以及用户隐私。
补充知识
TLS

SAN
DMZ
马尔科夫链
https://blog.csdn.net/qq_34037046/article/details/88969990
为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:
正则项L1 L2
机器学习中正则化项L1和L2的直观理解_小平子的专栏-CSDN博客_l2正则
稀疏模型
机器学习中正则化项L1和L2的直观理解_小平子的专栏-CSDN博客_l2正则
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。
在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。
这就是稀疏模型与特征选择的关系。
交叉验证
https://blog.csdn.net/SanyHo/article/details/105236945