Apache RocketMQ 4.9.1 高性能优化之路
经过社区的投票,Apache RocketMQ 秋天的第一个版本 4.9.1 如约而至,该版本中最值得关注的是高性能优化这块,针对 Broker 端的性能,特别是对小消息的生产性能进行了针对性优化,和 4.9.0 版本相比,小消息实时生产的 TPS 提升了约 28%。
这一批优化相关的 Pull Request(PR)都挂在 ISSUE2883 下,分为 7 个 PR(A-G),接下来我们来看一下这一批优化的细节,大家也可以到 github 查看代码明细。
![]()
A、针对事务消息的优化
![]()
在当前的版本中,事务消息已经较为成熟,但压测的时候就会发现,默认的配置下每条消息都会打出一条日志:
log.info("Half offset {} has been committed/rolled back", i);这肯定会影响性能,压测等大流量场景下甚至会导致灾难性影响。所以这个优化最简单,把这个日志改成 debug 就可以了。
![]()
B、消除不必要的锁
![]()
在 RocketMQ 内部,主从复制和同步刷盘都是多线程协作处理的。以主从复制为例(GroupTransferService),消息处理线程(多个)不断接收消息,产生待复制的消息,另外有一个 ServiceThread 单线程处理复制结果,可以把前者看做数据生产者,后者看做数据消费者,RocketMQ 使用了双 Buffer 来达到批量处理的目的。如下图,消费者正在处理数据的同时,生产者可以不受影响的继续添加数据,第一阶段生产者 Buffer 有 3 条数据,消费者 Buffer 有 2 条数据,由于消费者是单线程,没有别的线程跟它竞争,所以它可以批量处理这 2 条数据,完成后它会交换这两个 Buffer 的引用,于是接下来的第二阶段它又可以批量处理 3 条数据。

之前 RocketMQ 在生产者写入、交换 Buffer 引用、以及内部处理中都使用了多个重量级锁保证线程安全。但实际上只需要在生产线程写入以及交换 Buffer 引用的时候加轻量级自旋锁就可以,由于这两个操作都是非常快的,因此可以认为每次加解锁都只有 2 次 CAS 操作的开销。
除此之外,WaitNotifyObject 类也进行了优化,减少了需要进入同步代码块的次数。
![]()
C、消除主从复制中的数组拷贝
![]()
RocketMQ 使用 mmap 来方法 CommitLog 文件,其中有一个好处就是 io 操作的时候少了一个内存拷贝。但实际上由于工程的复杂性,代码中仍然会存在各种各样的内存拷贝,我们优化的目标就是消除那些本来可以避免的复制。
这一次我们就在主从复制这里找到了一个优化点,有一个 ByteBuffer,要把其中一部分写到 CommitLog 里面去,原来的代码会创建一个 byte [],然后复制一遍,其实只需要传入 ByteBuffer.array() 给后续方法,然后指明要复制的起止位置就可以了。这样优化后我们还节省了这个 byte[] 的创建,原先复制 1G 的 CommitLog 就会有至少 1G 的 byte[] 对象的分配和 gc 开销,这下也省了。这次修改的部分实际上运行在 Slave 中,但在同步复制的场景下,对消息发送的响应时间还是有影响的。
![]()
D、优化 Broker 的默认参数
![]()
从 RocketMQ4.X 开始引入了自旋锁并作为默认值,同时将参数 sendMessageThreadPoolNums(出现消息生产的线程数)改为了 1,这样处理每条消息写 CommitLog 的时候可以省下进出重量锁的开销。
不过这个地方单线程处理,任务有点重,处理消息的逻辑并不是往 CommitLog 里面一写(无法并行)就完事的,还有一些 CPU 开销比较大的工作,多线程处理比较好,经过一些实践测试,4 个线程是比较合理的数值,因此这个参数默认值改为 MIN(逻辑处理器数, 4)。
既然有 4 个线程,还用自旋锁可能就不合适了,因为拿不到锁的线程会让 CPU 白白空转。所以 useReentrantLockWhenPutMessage 参数还是改为 true 比较好。
还有个细节,endTransactionThreadPoolNums 这个参数默认设置成了 sendMessageThreadPoolNums 的至少 4 倍,以避免事务消息量特别大的场景下(比如事务消息压测),二阶段处理速度赶不上一阶段处理速度,进而导致严重的问题。
此外,对刷盘相关的参数也进行了调整。默认情况下,RocketMQ 是异步刷盘,但每次处理消息都会触发一个异步的刷盘请求。这次将 flushCommitLogTimed 这个参数改成 true,也就是定时刷盘(默认每 500ms),可以大幅降低对 IO 压力,在主从同步复制的场景下,可靠性也不会降低。
![]()
E、优化 put message 锁内操作
![]()
写 CommitLog 只能单线程操作,写之前要先获取一个锁,这个锁也就是影响 RocketMQ 性能最关键的一个锁。理论上这里只要往 MappedByteBuffer 写一下就好了,但实践往往要比理论复杂得多,因为各种原因,这个锁里面干的事情非常的多。
由于当前代码的复杂性,这个优化是本批次修改里面改动最大的,但它的逻辑其实很简单,就是把锁内干的事情,尽量的放到锁的外面去做,能先准备好的数据就先准备好。它包括了一下改动:
1、将 Buffer 的大部分准备工作(编码工作)放到了锁外,提前做好。
2、将 MessageId 的做成了懒初始化(放到锁外),这个消息 ID 的生成涉及很多编解码和数据复制工作,实际上性能开销相当大。
3、原来锁内用来查位点哈希表的 Key 是个拼接出来的字符串,这次也改到锁外先生成好。
4、顺便补上了之前遗漏的关于 IPv6 的处理。
5、删除了无用的代码。
![]()
F、优化消息属性编解码的性能
![]()
MessageDecoder 类中的下面这段代码:
public static String messageProperties2String(Map properties) {
StringBuilder sb = new StringBuilder();
if (properties != null) {
for (final Map.Entry entry : properties.entrySet()) {
final String name = entry.getKey();
final String value = entry.getValue();
if (value == null) {
continue;
}
sb.append(name);
sb.append(NAME_VALUE_SEPARATOR);
sb.append(value);
sb.append(PROPERTY_SEPARATOR);
}
}
return sb.toString();
} 如果是业务代码,这里看起来似乎没有什么问题。但在 TPS 很高的场景下, StringBuilder 默认长度是 16,处理一个正常的消息,至少会内部扩展 2 次,白白产生 2 个对象和 2 次数组复制。所以优化方案就是先算好需要的长度,创建 StringBuffer 的时候直接就指定好。
这个类中的 string2messageProperties 也进行了优化,用自己的解析代替了 split 调用。通过 jmh 进行一下测试,结果如下:

可以看出有了很大的提高。
关于消息属性,之前的程序还有一个问题是把一些不需要的属性也写到了 CommitLog 里面(或者也可以说是把不相关的东西放到了消息属性里面)。比如 wait=true 这个属性,实际上是在消息处理过程中才用的,不需要持久化,所以这次就想办法把它从 CommitLog 中删掉了。遗憾的是没有一个统一的地方可以一劳永逸的删掉这个属性,本次只针对普通消息进行了删除。删掉这个属性,每个消息的存储占用会减少 10 个字节,对于小消息来说,还是挺可观的。
![]()
G、优化消息 Header 解析的性能
![]()
RocketMQ 的通信协议定义了各种指令,它们的 Header 各不相同,共用了一个通用的解析方法,基于反射来解析和设置消息 Header。
这里简单的针对消息生产的指令,不再使用共同的这个解析器,而是简单粗暴的直接一个一个去 set 每一个属性,这样这个方法获得了大约 4 倍性能的提升。
![]()
性能测试
![]()
现在,我们针对本次优化的成果,进行一次分布式的性能测试。
我们使用 2 台物理机部署为 Master/Slaver 模式,同步复制,异步刷盘,其它参数均用默认,分区数设置为 18。然后用另外 6 台服务器作为 client 同时生产和消费,每个生产者启动 100 个线程同步发送,消息体约 300 字节。
服务器硬件配置为 2*Xeon(R) Gold 5218,一共 32 核心 64 线程,128G 内存,Nvme SSD,client 和 server 的 ping 延迟是 0.06ms。
我们还派出了一个神秘的参赛选手,最终待测试的版本包括以下 4 个:
A、4.9.0 版本,使用默认参数。
B、4.9.0 版本,按上面的修改 D 进行参数优化。
C、4.9.1 版本,默认参数。
D、快手内部某版本。
结果如下:
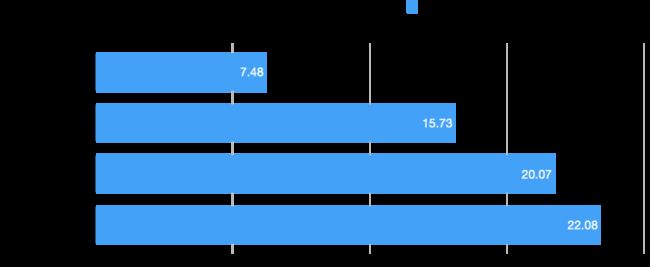
即使按进行过参数优化的 4.9.0 版本作为基线,4.9.1 版本也胜出了 28%,快手内部版本则胜出了 40%。
需要说明的是:
1、由于 OS 虚拟内存管理是个很复杂的机制,写 mmap 的 Byte Buffer 的速度也会存在抖动,所以测试的结果也存在波动。
2、内核参数会对OS的内存性能有很大影响,不同硬件、内核可能会有不同的表现,RocketMQ/bin 目录下的 os.sh 可以作为一个内核参数调整的参考。
3、Nvme SSD 不会是性能瓶颈所在,通过在一个物理机上安装多个 Broker(改一下端口号和文件存储路径),可以进一步提升 TPS,比如在本次测试的场景下,还是这两台物理机,4.9.1 版本每个物理机上 4 个 Broker 混布可以把总 TPS 提升到 60 多万。
4、压测的时候 RocketMQ 自身的 benchmark 程序自己也会存在瓶颈,需要多实例运行得出 Broker 的性能,本次测试没有使用使用这个程序。
![]()
总结
![]()
性能优化是个长期工作,本批次的优化主要集中在 Broker 的消息生产链路。其他地方也有很多可以优化的点,包括:
消费链路
Client 的对象创建、数据复制、线程切换等
网络通信和序列化
benchmark 程序
即便是生产链路也还有很多可以继续优化的地方,我们会继续推进这个工作,也欢迎大家一起来贡献。
作者介绍:
(1)黄理,当前就职于快手,架构师,Apache RocketMQ Commiter,多年 Java 架构和开发经验,个人技术爱好是性能优化方向。
(2)胡宗棠,当前就职于中国移动云能力中心,云原生领域技术专家,Apache RocketMQ Committer,SOFAJRaft Committer,Alibaba/Nacos Committer,熟悉分布式消息队列、API 网关和分布式事务等中间件设计原理、架构以及各种应用场景,具有丰富高性能、高可用和高并发经验;
往期推荐:
全链路压测体系建设方案的思考与实践
聊聊网商银行:小微企业1秒放贷背后的智能
软件架构等于和复杂性做斗争
万亿级别全链路数据治理最佳实践
大厂经验:通用规则平台的设计与应用
……
技术琐话
以分布式设计、架构、体系思想为基础,兼论研发相关的点点滴滴,不限于代码、质量体系和研发管理。
