拓端tecdat|R语言有状态依赖强度的非线性、多变量跳跃扩散过程模型似然推断分析股票价格波动
原文链接:http://tecdat.cn/?p=23010
原文出处:拓端数据部落公众号
跳跃扩散过程为连续演化过程中的偏差提供了一种建模手段。但是,跳跃扩散过程的微积分使其难以分析非线性模型。本文开发了一种方法,用于逼近具有依赖性或随机强度的多变量跳跃扩散的转移密度。通过推导支配过程时变的方程组,我们能够通过密度因子化来近似转移密度,将跳跃扩散的动态与无跳跃扩散的动态进行对比。在这个框架内,我们开发了一类二次跳跃扩散,我们可以计算出对似然函数的精确近似。随后,我们分析了谷歌股票波动率的一些非线性跳跃扩散模型,在各种漂移、扩散和跳跃机制之间进行。在此过程中,我们发现了周期性漂移和依赖状态的跳跃机制的依据。
简介
现实世界的过程经常受到许多随机输入源的影响,导致各种随机行为,形成过程轨迹的一个组成部分。因此,在对这种现象进行建模时,模型方程必须考虑到过程动态的各种随机性来源。
尽管扩散过程在连续过程的建模中被广泛使用,但通常假设布朗运动作为过程随机演化的驱动机制。如果布朗运动不够,可以对模型过程进行概括,使其应用更加实际。
一个这样的概括是在模型过程的轨迹中包括随机发生的 "跳跃"。这种修改主要是在金融背景下进行的,其中扩散模型被用来描述价格/资产过程的动态,这些价格/资产过程在观察到的时间序列中会出现看似自发的频繁跳动。例如,人们通常假设一个给定的股票价格过程的对数收益为正态分布。通过假设股票价格过程的动态变化遵循几何布朗运动,这一假设可以很容易地被纳入随机微分方程中。
![]()
其中Xt表示时间t的股票价格,由此可见,对数(Xt)-对数(Xs)∼N((μ-σ2/2)(t-s), σ2(t-s)),对于t>s。然而,股票价格收益率的正态性长期以来一直受到争议,经验证据表明,收益率往往表现出正态分布不能很好复制的特征。其中最广为人知的是模型过程中明显缺乏重尾的现象。这一点可以通过计算描述性的统计数据来证明,比如观察到的收益率序列的偏度和峰度,随后可以与正态分布下的相应统计数据进行对比。在扩散过程的背景下,这种差异通常是通过建立随机波动率模型来弥补的,其中收益过程的扩散系数本身被视为一个随机过程。也就是说,修改后的过程可以采取以下形式:

![]()
其中a(σ 2 t , t)和b(σ 2 t , t)分别表示方差过程的漂移和扩散,B (1) t和B (2) t是相关的布朗运动。随机波动率模型通过允许对数收益的方差随时间变化,更准确地捕捉股票价格收益的尾部行为。
然而,在解释随机波动率机制时需要注意。事实上,当 B (1) t 和 B (2) t 不相关时,对数收益过程的边际分布是以方差过程的已知初始值为条件的(即Xt|Xs, σ2 s for t > s),仍然是正态分布,即存在强相关,在这种情况下,对数收益的边际分布可能是偏斜的,尾部比正态分布下预测的略厚,由此产生的转移密度可能没有足够的leptokurtic来解释短转移期内的极端收益事件。
为了说明这一点,考虑对标准普尔500指数(S&P 500)的每日对数收益的滚动估计。让Xti表示标准普尔500指数在时间ti的值,然后用带宽h定义一个峰度滚动估计值。
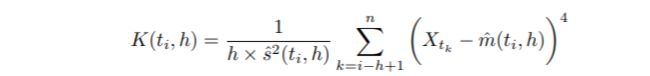
图描述了峰度的滚动估计和时间差估计,计算为{K(ti, h) - K(ti-1, h) : i = h, h + 1, . . N},在1990-01-01至2015-12-31的时间段内使用h=250天的带宽。在这个带宽下,差分序列代表了将滚动估计值向前移动一天所引起的估计峰度的变化,即(大约)过去一年的数据。此外,我们还将峰度的总体估计值(在整个时间段内计算)与正态分布的估计值叠加在一起。
根据总体估计,样本的峰度明显超过了正态分布的估计。然而,一年的滚动估计显示,尽管对数收益系列的峰度通常高于正态分布的峰度,但总体估计的规模可归因于一些极端收益事件的发生。这些事件表现为峰度的滚动估计值中突然出现的尖峰,在时间差的估计值中可以清楚地看到。
为了解释这种极端事件,Merton(1976)提出在扩散轨迹中加入跳跃,以便建立一个比几何布朗运动的连续路径所预测的更精确的资产价格回报模型,在这种情况下,修改后的随机微分方程(SDE)的形式为
![]()
其中z˙t表示正态分布的跳跃随机变量,Nt是强度恒定的泊松过程,即Nt-Ns∼Poi(λ(t - s))。在这种表述下,极端事件被明确地包含在随机微分方程中,作为扩散轨迹中随机发生的不连续跳跃。因此,观察到的对数收益的尾部行为和布朗运动的尾部行为之间的差异,通过加入跳跃机制得到了缓解。在此基础上,我们可以扩展该模型,以建立一个带有跳跃的随机波动率模型,例如:

其中跳跃同时影响着收益率和波动率。利用这一点,可以保留随机波动率的有用特性,同时直接说明极端收益事件和波动率的跳跃。
标量的例子
为了证明矩量方程在分析跳跃扩散模型中的应用,我们考虑一个具有随机强度的非线性、时间不均一的跳跃扩散。设
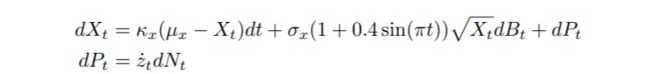
λ(Xt, r˙t, t) = r˙t,其中强度参数r˙t的动态变化由连续时间马尔科夫链(CTMC)给出。

转移率矩阵
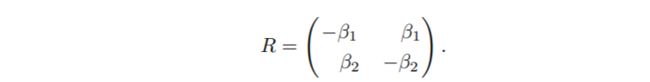
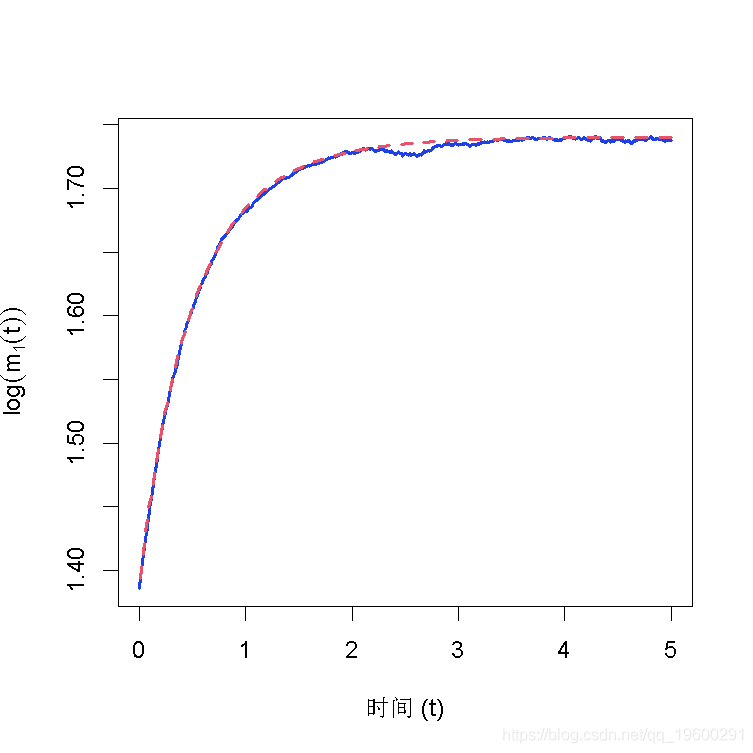
在方程的动态作用下,该过程表现出线性漂移和波动,随时间周期性变化。此外,该过程还受到随机发生的跳跃事件的影响,跳跃强度随时间在λ1和λ2之间随机转换。我们需要评估强度过程随时间变化的期望值。从˙rt的转移概率矩阵中,可以得到

图将得到的近似值与不同时间点的模拟轨迹计算的频率分布进行了比较。与矩方程一样,转移密度近似值似乎准确地复制了指定时间段内的转移密度。周期性波动的影响可以从转移密度曲面的振荡形状中看出。
for(i in 1:4)plot(log(moments[i,])~time,type='l')
lines(log(moments[i,])~time)


legend('bottomright',bty='n')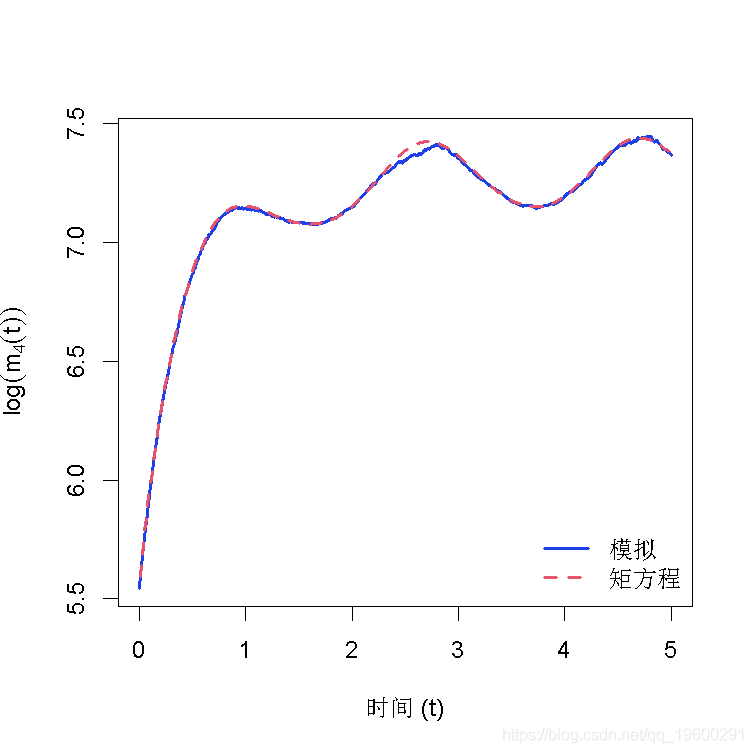
for(i in 2:5) h1 =simhists[[i]]
surface3d(x,ch)
plot(1:2, type='n', main="", xlab="", ylab="",axes=FALSE)
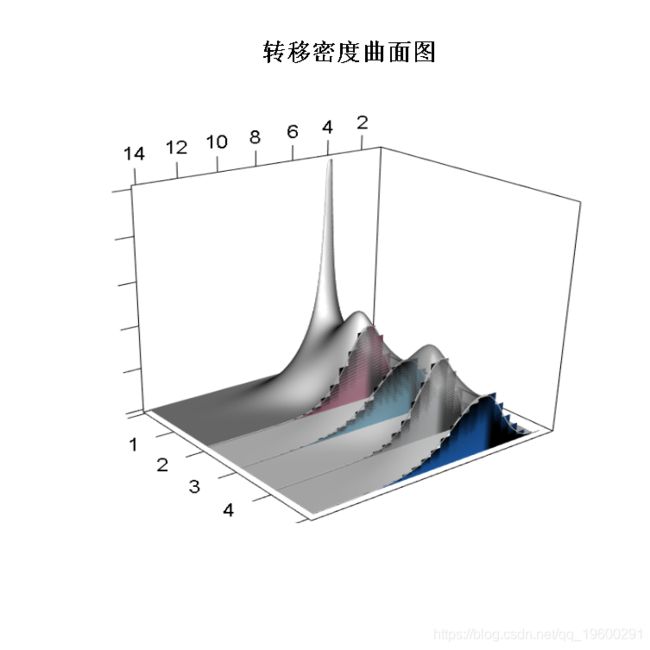

通过重复计算不同初始条件下的转移密度近似值--我们不是从低跳频状态开始,而是让过程从高跳频状态开始--我们可以直观地看到随机强度的影响。图比较了强度过程的两个初始状态的近似过渡密度。在高强度制度下,过渡密度明显比低强度制度下更偏斜。这是很直观的,因为尽管无论强度过程的状态如何,跳跃分布都是固定的,但在假定的参数集下,跳跃通常会假设正值。
因此,如果跳跃发生得更频繁,那么与低强度区制下相比,该过程很可能在某一特定时间内从其初始状态进一步传播。注意到,尽管强度过程转换回低强度状态的概率不为零,但与从低强度状态开始相比,平均而言,在转移期的持续时间内,强度预计会更高。这可以通过比较假设参数下强度过程的两个初始状态的h(t, λ, β)来验证。
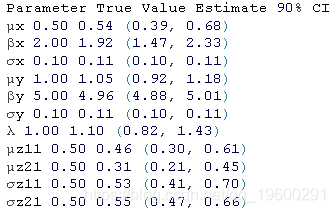
得到的参数估计值与真实的参数集相当吻合,但μz21是个明显的例外。然而,仔细检查发现,在跳跃扩散模型下计算出的估计值确实是一个有效的估计值,因为直接从跳跃实现中计算出的值是相当相似的。事实上,在这个实验中,跳跃信号是相当强的,因为跳跃分布的分散性相对于扩散参数来说是很大的。因此,跳跃和扩散动态之间的对比度很高,足以对跳跃区制的动态做出相当准确的推断。
尽管估计的参数接近真实的参数集,但在模拟中产生的特定的跳跃实现序列包含在真实参数集下相对不可能的值。尽管这样,跳跃区制的参数仍然可以被准确地提取出来,尽管保留了不可能的跳跃序列的属性。
对谷歌股票价格波动的应用
在次贷危机后的世界里,投资者已经越来越意识到了解股票价值的大幅波动对投资组合和金融产品的影响的重要性。因此,分析金融数据的技术已经变得越来越复杂,而且往往侧重于更好地管理与极端事件相关的风险和机会,包括在高频和低频交易范围内。
与此同时,数据市场也有了类似的发展,成千上万的经济变量和股票的高度详细数据几乎可以免费获得。期权交易所(CBOE)发布了在主要证券交易所上市的一些大盘股的波动率指数。通过使用诸如S & P 500波动率指数,这些股票波动率指数可以量化单个股票价格过程的波动性,而不是股票指数的波动。
事实上,单个股票过程的动态可能与一组股票的总体动态有很大的不同。因此,股票波动率指数在量化投资组合中的风险敞口方面非常有用,这些投资组合对此类股票和相关过程有大量投资。通过使用各种跳跃扩散模型,我们试图对互联网搜索巨头谷歌的股票波动率进行建模。
图显示了谷歌股票波动率(VXGOG)从2010年开始到2015年底的轨迹,以每日为单位进行采样。在接下来的分析中,我们以年为单位来衡量时间,并使用准确的日期来观察,以构建连续观察的转移期限。
# 谷歌股票波动率
#做一个数据的图表
plot(Vt~time1,type='l',lwd=1)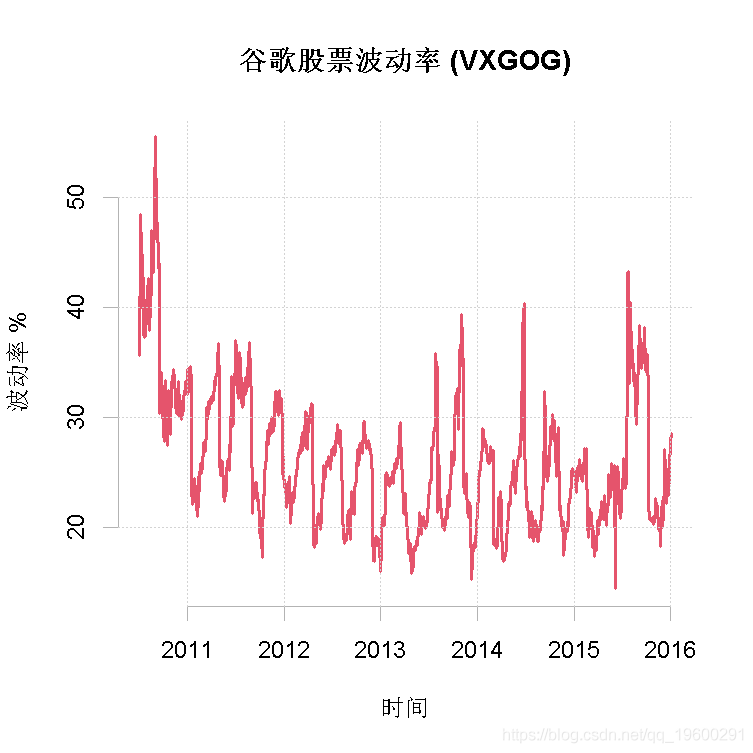
为了对波动率时间序列进行建模,我们定义了一些嵌套在SDE中的跳跃扩散模型。

跳跃强度为λθ(Xt, t),旨在复制波动率序列的突出特征和动态变化。利用广义二次方程框架,我们可以为方程建立一个模板,可以用来拟合各种形式的漂移、扩散和跳跃。为了对波动率序列的漂移进行建模,我们使用了线性均值回归的漂移结构。
![]()
请注意,先验参数大多是无信息的,然而,它们确实有助于将相关参数限制在适当的领域内。例如,θ8被限制在[0,1]区间内,否则似然会包含多个相同的模型。我们可以将跳跃扩散过程拟合到观察到的序列中,并计算出参数估计值。
# 计算参数估计值
estimates(model_1)

从建模的角度来看,通过比较模型与传统扩散模型的拟合,可以清楚地看到跳跃式扩散的使用。例如,与它的无跳跃对应模型--股票波动率的时间同质性CIR模型相比。
与DIC的比较显示了拟合度的大幅提高。
# 比较DIC值
dic(model_1, model_2)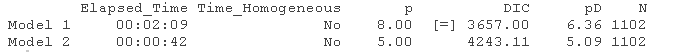
尽管参数估计值可以说明过程的跳跃区制的动态,但JGQD.mcmc()函数为评估跳跃事件的概率提供了一个有用的统计数字。从模型输出中,我们可以访问列表变量,它给出了在MCMC运行的每个迭代中观察到至少一次跳跃的估计平均概率。因此,我们可以画出上述概率的频率直方图,以便深入了解一个典型转移跳跃到来的拟合概率。
# 做一个每个转移期的平均跳跃概率的柱状图。
hist(zero.jump[seq(burns,updates,1)]

根据直方图,我们可以预期在任何一个交易日看到至少一次波动率的跳跃,概率约为6.5%。
作为参考,我们还叠加了每个转移区间的跳跃概率的解码序列。也就是说,我们估计了每个观察到的转移期包含跳跃的概率(基于基础模型),并人为地选择了预(后)测的跳跃到达的时间序列。这是通过强加一个启发式规则来实现的,即90%或更高的包含跳跃的估计概率(包含在模型输出列表变量中)被认为是检测跳跃事件的决定性因素。尽管不严格,但对探索性分析很有用。
从图上看,估计的到达时间似乎与波动率序列中的大幅波动相吻合。具体来说,一些解码的到达似乎是结构性的,在波动率周期性上升之后观察到波动率的下降......更深入的分析将在接下来的研究中进行,但要考虑以下几点。
plot(deprob~time)
abline(h=0.8) 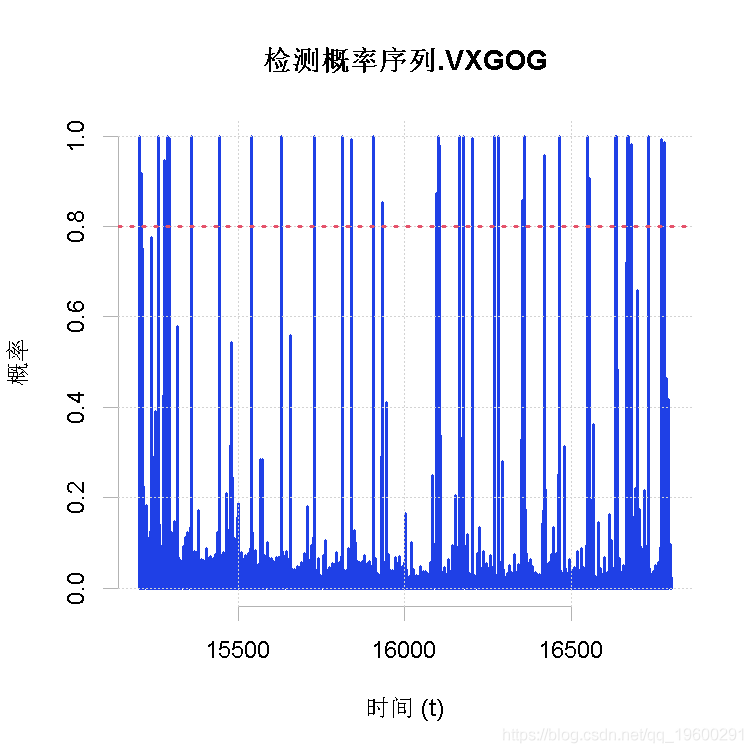
plot(Vt~time1)
for(i in 1:length(at.dates)segments(dates, 10, dates[i])


最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析
3.使用r语言进行时间序列(arima,指数平滑)分析
4.r语言多元copula-garch-模型时间序列预测
5.r语言copulas和金融时间序列案例
6.使用r语言随机波动模型sv处理时间序列中的随机波动
7.r语言时间序列tar阈值自回归模型
8.r语言k-shape时间序列聚类方法对股票价格时间序列聚类
9.python3用arima模型进行时间序列预测