Market Risk Modeling
Market Risk Modeling
Market Risk
- interest-rate risks
- equity risks
- exchange rate risks
- commodity risks
Traditional risk mesurement tools
-
Gap analysis
Ideas of interest-rate risk exposure
Δ N I I = ( G A P ) Δ r \Delta NII=(GAP) \Delta r ΔNII=(GAP)Δr
Δ N I I \Delta NII ΔNII 为净利率收入变化, Δ r \Delta r Δr 为利率变化
对时间线的选择比较敏感
-
Duration analysis
久期分析,测量利率风险
麦考利久期 D = ∑ i = 1 n [ i × P V C F i ] / ∑ i = 1 n P V C F i D=\sum_{i=1}^{n}[i\times PVCF_i]/\sum_{i=1}^{n}PVCF_i D=∑i=1n[i×PVCFi]/∑i=1nPVCFi , P V C F i PVCF_i PVCFi 是第 i i i 期的折现现金流。久期给出了债卷价格相对其收益变化的敏感度的近似指标:
%Change in bond price = − D × Δ y / ( 1 + y ) -D \times \Delta y/(1+y) −D×Δy/(1+y)
久期越大,收益变化对债卷价格影响越大。久期比较容易计算,相对于Gap Analysis,它审视了整个资产或负债的变化,而不是只关心净收入。但是久期也只针对于利率风险。
-
Scenario Approach
场景分析方法主要是构造不同的场景,并分析在这些场景下的所得和所失。场景的影响因素就包括诸如股票价格、利率和汇率等,同时研究资产和负债的现金流和折现值,从而得到风险敞口。
场景方法并不容易实施,构造一个正确的场景也非常困难,我们需要覆盖最可能的情况且考虑变量之间的相关性。
-
投资组合理论
投资组合理论认为投资者在配资投资组合时会基于资产的期望收益和收益标准差,组合收益的标准差就是风险的度量。显然,投资者会在同等风险上追求更高的收益,且权衡风险和收益。
在这种理论框架下,在投资组合中的某个资产的风险不仅仅和其本身有关,还和整个组合的相关性有关;或者说一个资产对整个组合的风险贡献度依赖于资产与组合协方差除以组合收益的方差(或称为贝塔)。
投资组合理论提供了一个可以处理多风险和风险之间的交互作用,它被基金经理,投资管理者广泛使用。但事实上,其参数诸如协方差,期望收益等并不容易估算,它需要大量数据。
-
衍生品风险度量(Derivatives Risk Measures)
我们可以通过以下参数来估算衍生品头寸风险:
-
Δ \Delta Δ :代表底层资产价格的小变化导致的衍生品价格变化
-
γ \gamma γ :底层资产价格的小变化导致的 Δ \Delta Δ 的变化 (二阶导数)
-
ρ \rho ρ :利率变化导致的衍生品价格变化
-
Vega : ∂ V / ∂ σ \partial V/\partial \sigma ∂V/∂σ , 波动率的变化导致的衍生品价格变化
-
θ \theta θ : 时间的推移导致衍生品价格的变化
使用这些度量指标,我们必须知道它们必须服从动态对冲策略,只针对于风险因子的小变化,需要经常检查。当市场有大的变化是,这些指标往往不能再说明问题。
-
VaR (Value at Risk)
-
在险价值(VaR)的出处
VaR来自于JP Morgan的RiskMetrics系统,设计为可以度量风险跨越不同的交易头寸,跨越整个机构,而且可把多个风险聚集为一个单一的风险度量。该系统采用了VaR,即在下一个交易日的最大可能损失。VaR是基于标准的投资组合理论的,会估算不同交易工具的标准差和相关系数,虽然看上去比较直接,但是实际上使其称为系统化方法还是有大量的工作要做的,例如测度惯例选择、构造数据集、统计假设、估算波动率和相关性的步骤等。
随后,很多机构都开始开发各自的VaR系统,有通过收益和损失直方图来估算的,也有采用蒙特卡洛模拟的;后来VaR被扩展到信用风险、流动性风险和现金流风险。
-
VaR的优点
- 提供通用的、跨越不同头寸和风险因子的风险度量工具
- 考虑了风险因子之间的相关性
-
关于VaR的指责
-
可验证性及其统计假设
对于社会体系中的智能体而言,他们会学习如何对所处的环境做出反应,致使市场中的很多过程是非平稳且具备动态依赖关系。这会使VaR在有些情况下呈现错误的结果。一个例子是长期资本管理公司(Long Term Capital Management)发现在1998年的秋季和夏季,损失是正常收益损失的14个标准差。
-
估算方法不明确
经验告诉我们多种多样的VaR的估算方法给出了不同的结果,这说明VaR带来了实现方法风险。
-
VaR会带来向下偏差
-
VaR会带来高度下行相关性
-
VaR并不是最佳的尾部风险度量
VaR不具备一致性属性,因此ETL(Expected Tail Loss)进入了这个舞台。
-
-
What is VaR

给定一个期间,在95%的置信水平下,亏损不会超过1.645.

给定一个期间,在99%的置信水平下,亏损不会超过2.326
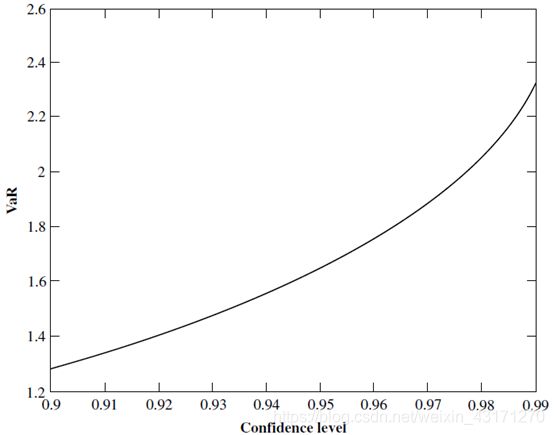
VaR与置信水平.

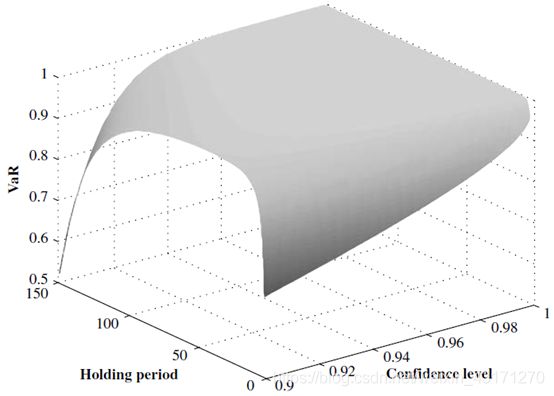
VaR与持有期间
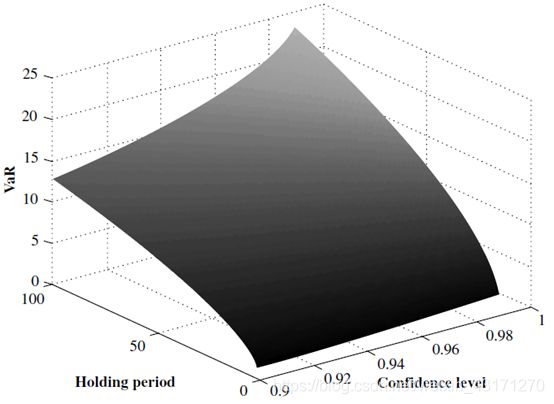
VaR平面
- VaR参数
- Holding Period
- Confidence Interval
Expected Tail Loss (ETL)
-
Coherent Risk Measures
如果 X X X , Y Y Y 是两个风险头寸的价值, ρ \rho ρ 代表风险度量,
ρ ( X ) + ρ ( Y ) ≤ ρ ( X + Y ) \rho(X)+\rho(Y) \le \rho(X+Y) ρ(X)+ρ(Y)≤ρ(X+Y) , sub-additivity
ρ ( t X ) = t ρ ( X ) \rho(tX)=t\rho(X) ρ(tX)=tρ(X) , homogeneity
ρ ( X ) ≥ ρ ( Y ) , i f X ≤ Y \rho(X) \ge \rho(Y), if \ X \le Y ρ(X)≥ρ(Y),if X≤Y , monotonicity
ρ ( X + n ) = ρ ( X ) − n \rho(X+n)=\rho(X)-n ρ(X+n)=ρ(X)−n , risk-free condition
满足这四个条件的风险度量称为连贯风险度量。前三个条件保证 ρ \rho ρ 为凸函数,最后一个条件说明当某头寸加上一个确定的无风险资产会减少其风险。
-
What is ETL
ETL还有其他名字,例如Expected Shortfall, Conditional VaR(CVaR)等。
E T L = E [ L ∣ L > V a R ] ETL=E[L|L>VaR] ETL=E[L∣L>VaR]
L 代表损失,ETL就是如果损失大于 VaR 的时候,损失的期望价值。


Basic Issues in Measureing Market Risk
-
数据问题
-
Profit/Loss Data
P / L t = P t + D t − P t − 1 P/L_t=P_t+D_t-P_{t-1} P/Lt=Pt+Dt−Pt−1, D t D_t Dt 为期间支付
Present Value ( P / L t ) = ( P t + D t ) / ( 1 + d ) − P t − 1 (P/L_t)=(P_t+D_t)/(1+d)-P_{t-1} (P/Lt)=(Pt+Dt)/(1+d)−Pt−1
Forward Value P / L t ) = P t + D t − ( 1 + d ) P t − 1 P/L_t)=P_t+D_t-(1+d)P_{t-1} P/Lt)=Pt+Dt−(1+d)Pt−1
其中, d d d 为折现率。
-
Loss/Profit Data
L / P t = − P / L t L/P_t=-P/L_t L/Pt=−P/Lt
-
Arithmetric Returns Data
r t = ( P t + D t − P t − 1 ) / P t − 1 r_t=(P_t+D_t-P_{t-1})/P_{t-1} rt=(Pt+Dt−Pt−1)/Pt−1
-
Geometric Returns Data
R t = l o g [ ( P t + D t ) / P t − 1 ] = l o g ( 1 + r t ) R_t=log[(P_t+D_t)/P_{t-1}]=log(1+r_t) Rt=log[(Pt+Dt)/Pt−1]=log(1+rt)
-
-
如何估算VaR
-
Historical Simulation
Ordered L/P observations

-
Parametric VaR
明确定义观测值的统计分布
- 正态分布:
V a R = − α c l σ P / L − μ P / L VaR=-\alpha_{cl}\sigma_{P/L}-\mu_{P/L} VaR=−αclσP/L−μP/L
- Normally Distributed Arithmetic Returns
V a R = − ( μ r + α c l σ r ) P t − 1 VaR=-(\mu_r+\alpha_{cl}\sigma_r)P_{t-1} VaR=−(μr+αclσr)Pt−1
- Lognormal VaR
V a R = P t − 1 − e x p [ μ R + α c l σ R + l o g P t − 1 ] VaR=P_{t-1}-exp[\mu_R+\alpha_{cl}\sigma_R+logP_{t-1}] VaR=Pt−1−exp[μR+αclσR+logPt−1]
log normal asset price
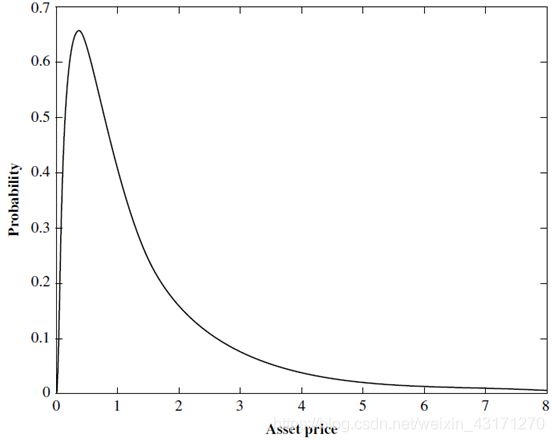
Lognormal VaR

-
-
如何估算ETL
ETL实际上是概率权重尾部损失的平均值,或者超过VaR的损失。
正常的VaR和ETL

非参数估算方法(VaR,ETL)
事实上,非参数法在估算VaR和ETL上更为普遍。这种方法并不对收益分布进行任何统计假设,它们主要依靠数据说话,但是它们共同依赖的假设是历史数据能近似表示未来。
-
历史模拟(Historical Simulation)
-
估算VaR/ETL曲线和曲面
-
估算置信区间
标准错误 s e ( x ) = p ( 1 − p ) / ( n f 2 ) se(x)=\sqrt {p(1-p)/(nf^2)} se(x)=p(1−p)/(nf2), f f f 为概率密度函数值; p p p 为累积密度函数值
1)Order Statistic Approach
2)Bootstrap Approach
-
加权历史模拟(Weighted Historical Simulation)
- Age-Weighted
- Volatility-Weighted
-
Filtered Historical Simulation (FHS)
传统的方法并不能适应条件变化波动率,而这些波动率比较自然的模型是GARCH,但是GARCH模型需要我们定义收益过程(return process),这一点并不适合于无参模型。FHS方法结合HS的优势和GARCH对条件波动率建模的灵活能力。
假如我们想用FHS来估算一个单资产的投资组合在一天的VaR:
1)第一步,用一个GARCH模型拟合观测数据,我们选择AGARCH(Asymmetric GARCH):
r t = μ + ϵ t r_t=\mu+\epsilon_t rt=μ+ϵt
σ t 2 = ω + α ( ϵ t − 1 + γ ) + β σ t − 1 2 \sigma_t^2=\omega+\alpha(\epsilon_{t-1+\gamma})+\beta\sigma_{t-1}^2 σt2=ω+α(ϵt−1+γ)+βσt−12
2)第二步,使用这个模型在采样期间中预测每一天的波动率,而这些波动率可以被分成实现的收益产生一个标准化的成iid(independent identically distribution)的收益集合.
3)第三步,对这个集合进行bootstrapping采样
4)最后,用这个新得到的收益集合来估算VaR。
这种方法通过采用多变量GARCH模型可以适用于多资产的组合,也可以用来估算ETL。
PCA to estimate VaR and ETL
主成分分析法提供了一种对数据中存在的风险因子的简单表示,PCA应用于VaR和ETL的典型应用是针对于固收类投资组合。固收类产品在跨越利率期限结构时会有波动,在这种情况下,会呈现许多高度相关的风险因子,高维和共线性会使协方差矩阵难以估算,经验表明前三个主成分一般会覆盖95%的波动性。
因子分析(Factor Analysis)着重于解释相关性,它在解释很多变量的相关性时非常有用。
这些方法配合顺序统计量(Order Statistics)和bootstrap方法可以帮助我们估算VaR和ETL的置信区间。
Parametric VaR and ETL
-
Normal
-
The Student t-distribution
V a R ( h p , c l ) = − α c l , v h p ( v − 2 ) / v σ P / L − h p μ P / L VaR(hp,cl)=-\alpha_{cl,v}\sqrt{hp}\sqrt{(v-2)/v}\sigma_{P/L}-hp\mu_{P/L} VaR(hp,cl)=−αcl,vhp(v−2)/vσP/L−hpμP/L , h p hp hp 为holding period, v v v 为自由度
-
Lognormal Distribution
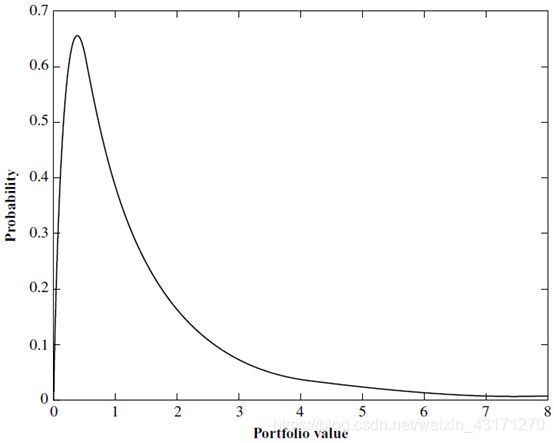
V a R = P t − 1 − e x p [ h p μ R + α c l h p σ R + l o g P t − 1 ] VaR=P_{t-1}-exp[hp\mu_R+\alpha_{cl}\sqrt{hp}\sigma_R+logP_{t-1}] VaR=Pt−1−exp[hpμR+αclhpσR+logPt−1]-
Extreme Value Distribution
Fisher–Tippett theorem 告诉我们如果 X X X 有合适的’well-behaved’的分布函数 F ( X ) F(X) F(X) ,那么 X X X 的极值的分布函数会渐渐收敛于广义极值分布函数(GEV, Generalized Extreme Value):
If ξ ≠ 0 \xi \neq 0 ξ=0, H ξ , a , b = e x p [ − ( 1 + ξ ( x − a ) / b ) − 1 / ξ ] H_{\xi,a,b}=exp[-(1+\xi(x-a)/b)^{-1/\xi}] Hξ,a,b=exp[−(1+ξ(x−a)/b)−1/ξ]
else, H ξ , a , b = e x p [ − e x p ( − ( x − a ) / b ) ] H_{\xi,a,b}=exp[-exp(-(x-a)/b)] Hξ,a,b=exp[−exp(−(x−a)/b)]
ξ > 0 \xi > 0 ξ>0 时,为Gumbel分布, V a R = a − ( b / ξ ) [ 1 − ( − l o g ( c l ) − ξ ] VaR=a-(b/\xi)[1-(-log (cl)^{-\xi}] VaR=a−(b/ξ)[1−(−log(cl)−ξ]
ξ = 0 \xi=0 ξ=0 时,为Frechet分布, V a R = a − b l o g ( l o g ( 1 / c l ) ) VaR=a-blog(log(1/cl)) VaR=a−blog(log(1/cl))

Grumbel VaR Surface
我们可以应用EVT到超过阈值的超额损失的分布,称为广义帕累托分布(Generalized Pareto Distribution):
如果 X X X 的分布函数为 F ( X ) F(X) F(X) , u u u 时 X X X 的阈值,定义 X X X 超过 u u u 的分布为
F u ( X ) = P r { X − u ≤ y ∣ X > u } F_u(X)=Pr\{X-u\le y|X>u\} Fu(X)=Pr{ X−u≤y∣X>u} ,
此分布函数收敛于广义帕累托分布:
If ξ ≠ 0 \xi \ne 0 ξ=0 , G ξ , β ( x ) = 1 − ( 1 + x ξ / β ) − 1 / ξ G_{\xi,\beta}(x)=1-(1+x\xi/\beta)^{-1/\xi} Gξ,β(x)=1−(1+xξ/β)−1/ξ
else , G ξ , β ( x ) = 1 − e x p ( − x / β ) G_{\xi,\beta}(x)=1-exp(-x/\beta) Gξ,β(x)=1−exp(−x/β)
这里, β > 0 \beta>0 β>0 为尺度参数, ξ \xi ξ 为形状参数,我们比较感兴趣的是 ξ > 0 \xi > 0 ξ>0 的情况,意味着收入分布具备厚尾,
V a R = u + ( β / ξ ) { [ ( n / N u ) ( 1 − c l ) ] − ξ − 1 } VaR=u+(\beta/\xi)\{[(n/N_u)(1-cl)]^{-\xi}-1\} VaR=u+(β/ξ){ [(n/Nu)(1−cl)]−ξ−1}
E T L = [ V a R + ( β − ξ u ) ] / ( 1 − ξ ) ETL=[VaR+(\beta-\xi u)]/(1-\xi) ETL=[VaR+(β−ξu)]/(1−ξ)
其中, ξ < 1 \xi <1 ξ<1, n n n 为样本数量, N u N_u Nu 为超额值的数量。
-
Multivariate Normal Variance-Covariance
前面所讨论的都是关于单一资产,多个资产的投资组合常用多元正态分布来建模,
V a R ( h p , c l ) = − [ α c l h p w Σ w T + h p w μ ] P VaR(hp,cl)=-[\alpha_{cl}\sqrt{hp}\sqrt{w\Sigma w^T}+hp w\mu]P VaR(hp,cl)=−[αclhpwΣwT+hpwμ]P
E T L ( h p , c l ) = [ h p w Σ w T ϕ ( − α c l ) / F ( α c l ) − h p w μ ] P ETL(hp,cl) =[\sqrt{hp}\sqrt{w\Sigma w^T}\phi(-\alpha_{cl})/F(\alpha_{cl})-hpw\mu ]P ETL(hp,cl)=[hpwΣwTϕ(−αcl)/F(αcl)−hpwμ]P
基于模拟技术的VaR/ETL估算
首先需要强调,一般只在直接的估算方法不可用的情况下,才会使用模拟技术来估算VaR/ETL,例如组合包含多种期权。最自然的模拟方法是模拟中的模拟,我们模拟期权的底层资产的各种情况,模拟所有这些情况下的离散点的期权价值,也可以模拟底层变量,但是计算复杂度非常高。因此,我们需要在精确率和速度上做权衡。
-
期权VaR和ETL
举例来说,假如我们想要估算一个美式put option的VaR和ETL,运用模拟技术需要嵌入一个期权定价模型伴随股票价格的模拟路径。最简单的模型是二叉树模型,采用的参数如下:
S ( 0 ) = X = 1 S(0)=X=1 S(0)=X=1 , r = μ = 0 r=\mu=0 r=μ=0 , σ = 0.25 \sigma=0.25 σ=0.25 ,maturity = 1 year , c l = 0.95 cl=0.95 cl=0.95 ,hp = 1 day
N = 20 N=20 N=20 步, M = 1000 M=1000 M=1000 trials
得到 V a R = 0.021 VaR=0.021 VaR=0.021 ,置信区间为 [ 0.019 , 0.022 ] [0.019,0.022] [0.019,0.022]
E T L = 0.026 ETL=0.026 ETL=0.026 ,置信区间为 [ 0.025 , 0.026 ] [0.025,0.026] [0.025,0.026]
我们可以通过优化来缩减计算时间:
- 控制变化
- 重要性采样
- 分层采样
- 动量匹配
-
模拟主成分
对一个固收类投资组合,我们首先选择一系列主要的零息利率 [ r 1 , r 2 , ⋯ , r n ] [r_1,r_2,\cdots,r_n] [r1,r2,⋯,rn] ,每一个都有不同的到期时间。对每一个利率用几何布朗运动建模, d r i / r i = μ i ( t ) d t + σ i d z i ( t ) dr_i/r_i=\mu_i(t)dt+\sigma_idz_i(t) dri/ri=μi(t)dt+σidzi(t) , z i ( t ) ∼ N ( 0 , t ) z_i(t)\sim N(0,\sqrt t) zi(t)∼N(0,t) , z i ( t ) z_i(t) zi(t) 会呈现非常高的相关性。我们通常会发现即期利率曲线的前三个主成分可以解释95%以上的波动。第一个主成分可以解释为平移因子(shift factor);第二个主成分可以解释为坡度因子(slope factor);第三个主成分为曲率因子。
我们让 C = [ ρ i . j ] C=[\rho_{i.j}] C=[ρi.j] 为其相关矩阵,第 j j j 个特征向量为 β j = [ β 1 , j , β 2 , j , ⋯ , β n , j ] \beta_j=[\beta_{1,j},\beta_{2,j},\cdots,\beta_{n,j}] βj=[β1,j,β2,j,⋯,βn,j] ,通过特征向量定义,我们有
C β j = λ j β j C\beta_j=\lambda_j\beta_j Cβj=λjβj , j = 1 , 2 , ⋯ , n j=1,2,\cdots,n j=1,2,⋯,n , λ j \lambda_j λj 为第 j j j 个特征值。
规范化 β \beta β 使得 ∣ β j ∣ 2 = ∑ i = 1 n β i , j 2 = λ j |\beta_j|^2=\sum_{i=1}^n\beta_{i,j}^2=\lambda_j ∣βj∣2=∑i=1nβi,j2=λj , 并且使得 λ j \lambda_j λj 从大到小排序,可以把 d z i dz_i dzi 写成
d z i = ∑ j = 1 n β i , j d w j ≈ β i , 1 d w 1 + β i , 2 d w 2 + β i , 3 d w 3 dz_i= \sum_{j=1}^n \beta_{i,j}dw_j \approx \beta_{i,1}dw_1+\beta_{i,2}dw_2+\beta_{i,3}dw_3 dzi=j=1∑nβi,jdwj≈βi,1dw1+βi,2dw2+βi,3dw3 , i = 1 , 2 , ⋯ , n i=1,2,\cdots,n i=1,2,⋯,n
对于 k ≠ j k \ne j k=j , E [ w k ⋅ w j ] = 0 E[w_k \cdot w_j]=0 E[wk⋅wj]=0 ; d w j = d t dw_j=\sqrt{dt} dwj=dt ,
可以得到 d r i / r ≈ μ i ( t ) d t + σ i β i , 1 d w 1 + σ i β i , 2 d w 2 + σ i β i , 3 d w 3 dr_i/r \approx \mu_i(t)dt+\sigma_i\beta_{i,1}dw_1+\sigma_i\beta_{i,2}dw_2+\sigma_i\beta_{i,3}dw_3 dri/r≈μi(t)dt+σiβi,1dw1+σiβi,2dw2+σiβi,3dw3
-
场景模拟
我们可以通过场景模拟方法在PCA的基础上进一步缩减计算量。三个主成分 d w 1 , d w 2 , d w 3 dw_1,dw_2,dw_3 dw1,dw2,dw3 中的每一个都可以允许有限状态中的一个状态,我们可以从多项式分布中抽取其状态。一个主成分如果可以取 m + 1 m+1 m+1 个状态,那么状态 i i i 的概率为:
P ( i ) = 2 − m m ! i ! ( m − i ) ! P(i)=2^{-m}\frac{m!}{i!(m-i)!} P(i)=2−mi!(m−i)!m! , i = 0 , 1 , ⋯ , m i=0,1,\cdots,m i=0,1,⋯,m
假如共有5个状态,概率分别为
1 16 , 1 4 , 3 8 , 1 4 , 1 16 \frac{1}{16},\ \frac{1}{4},\ \frac{3}{8}, \ \frac{1}{4},\ \frac{1}{16} 161, 41, 83, 41, 161 中间状态概率显然高于两边。
这样,在主成分的考虑中,中间状态可能是属于没有变化;其邻近状态时中度上升或下降;最边上的状态也许是极度上升和下降。鉴于第一主成分比第二主成分要重要很多,且第二主成分比第三主成分重要,第一主成分的状态需要比第二的多,而第二的比第三的多。一个常用的分配是7,5,3,概率为
P ( c o m p o n e n t 1 = i ) × P ( c o m p o n e n t 2 = j ) × P ( c o m p o n e n t 3 = k ) P(component 1=i)\times P(component2=j)\times P(component3=k) P(component1=i)×P(component2=j)×P(component3=k)
= [ 2 − m 1 m 1 ! i ! ( m 1 − i ) ! ] × [ 2 − m 2 m 2 ! j ! ( m 2 − j ) ! ] × [ 2 − m 3 m 3 ! k ! ( m 3 − k ) ! ] =[2^{-m_1}\frac{m_1!}{i!(m_1-i)!}] \times [2^{-m_2}\frac{m_2!}{j!(m_2-j)!}] \times [2^{-m_3}\frac{m_3!}{k!(m_3-k)!}] =[2−m1i!(m1−i)!m1!]×[2−m2j!(m2−j)!m2!]×[2−m3k!(m3−k)!m3!]
然后,我们可以从这个概率分布中随机抽取场景,每个场景将会给出一个即期利率曲线和投资组合的收益损失。
-
固收类VaR和ETL
固收类产品属于对利率比较敏感的投资工具,包括债券、浮动利率票据、结构性票据和利率置换等利率衍生品。好消息是模拟技术比较适合于固收产品,在采用模拟技术来估算固收产品的VaR和ETL时,需要考虑两个比较关键的因素:利率的随机过程和期限结构。
-
利率的随机过程
与股票价格的随机过程不同,利率通常呈现出均值反转,最流行的利率随机过程是Cox–Ingersoll–Ross (CIR) 过程:
d r = k ( μ − r ) d t + σ d t r d z dr=k(\mu-r)dt+\sigma \sqrt{dt}\sqrt rdz dr=k(μ−r)dt+σdtrdz , μ \mu μ 是长期利率均值, σ \sigma σ 是利率年化波动率, k k k 是利率反转到均值的速度, d z dz dz 是一个标准正态随机变量。这个模型捕捉了利率的三个经验特征:stochastic, positive, mean-reverting。
-
期限结构
利率的期限结构一般是比较棘手的,因为大多数固收头寸都包含多个远期会到期的支付,所以固收的估值需要我们考虑即期期限结构的多个不同时间点。
从估算VaR的角度上看,这意味着我们需要在持有到期时的预期期限结构的信息。VaR值依赖收益损失,而收益损失(P/L)依赖在持有期间的价格变化,价格依赖到期的即期期限结构,所以我们需要一个预期的未来期限结构。
-
-
动态投资组合策略下估算VaR和ETL
-
模拟方法估算信用相关风险
-
模拟方法估算保险风险
-
模拟方法估算养老金风险
Mapping positions to risk factor
很多情况下,我们需要从一个投资组合中区别各个头寸和风险因子,简单来说就是我们会经常把n个头寸映射到m个风险因子且通常是基准风险因子。主要过程分为三步:
-
构造一系列基准或核心投资工具或因子,收集其波动率和相关性数据。
-
为每一个所持有的投资工具产生合成替代品,组成在核心工具的头寸。
-
对合成替代品估算VaR和ETL.
-
选择核心工具
通常的做法是选择代表持有投资工具的宽泛类型,例如主要货币市场、权益类、现金类等。众所周知的RiskMetrics采用了以下核心工具:
- 权益类:对每一种核心货币使用等量的权益指数类
- 固收类:有限制的多个给定的到期时间的现金流的联合
- 外汇:外汇头寸以确定数目的核心货币的相近量来代表,外汇远期以相等的固收类头寸来表示。
- 大宗商品:以一定量的所选择的交易的标准远期合同来代表。
-
选择核心因子
另一种方法是选择核心因子而不是投资工具,因子的确定可以通过PCA量化方法。如前所言,通常PCA在降维方面非常有效,几个因子就可以解释大部分波动性。
-
头寸映射和VaR估算
我们现在考虑如何映射和估算VaR到特定类型的头寸。
1)基本构成要素
-
基本外汇头寸
V a R F X = − α c l σ E x E VaR^{FX}=-\alpha_{cl}\sigma_E xE VaRFX=−αclσExE
这里, x x x是头寸价值, E E E 为汇率, σ E \sigma_E σE 为汇率标准差(认为汇率成正态分布)
-
基本权益头寸
令市场收益为 R m R_m Rm ,公司股票收益为 R A R_A RA , β \beta β 收益为 β A \beta_A βA , α \alpha α 收益为 α A \alpha_A αA ,
有 R A = α A + β A R m + ϵ A R_A=\alpha_A+\beta_AR_m+\epsilon_A RA=αA+βARm+ϵA,
收益方差为 σ A 2 = β A 2 σ m 2 + σ ϵ 2 \sigma_A^2=\beta_A^2\sigma_m^2+\sigma_{\epsilon}^2 σA2=βA2σm2+σϵ2 ,
假设收益为正态分布, V a R A = − α c l σ A x A = − α c l x A β A 2 σ m 2 + σ E 2 VaR_A=-\alpha_{cl}\sigma_Ax_A=-\alpha_{cl}x_A\sqrt{\beta_A^2\sigma_m^2+\sigma_E^2} VaRA=−αclσAxA=−αclxAβA2σm2+σE2
-
零息债卷
我们的任务是把无违约风险的零息债卷映射到参考投资工具上,例如月零息债券、3月零息债券等。我们会有这些特定到期时间债卷的波动率和相关性,但不包含其他到期时间的,所以我们没有我们所持有的特定到期时间零息债券的波动率和相关性数据。例如参考零息债券为30天和90天,我们所持有的债券是80天,我们该如何估算其VaR值呢?事实上,只能通过30天和90天的某种组合来估算。
从RiskMetrics的建议上来看,映射后的头寸应该与原头寸有相同的价值和波动性,现金流应具备相同的符号。
假设我们有一个6年的流入现金流,最近的参考到期时间工具为5年和7年,那么
I 6 m a p p e d = ω I 5 + ( 1 − ω ) I 7 I_6^{mapped}=\omega I_5+(1-\omega)I_7 I6mapped=ωI5+(1−ω)I7
σ 6 2 = ω 2 σ 5 2 + ( 1 − ω ) 2 σ 7 2 + 2 ω ( 1 − ω ) ρ 5 , 7 σ 5 σ 7 \sigma_6^2=\omega^2\sigma_5^2+(1-\omega)^2\sigma_7^2+2\omega(1-\omega)\rho_{5,7}\sigma_5 \sigma_7 σ62=ω2σ52+(1−ω)2σ72+2ω(1−ω)ρ5,7σ5σ7
问题就转化为如何选择 ω \omega ω , 其他项可知的情况下,我们可以解出
ω = [ − b ± b 2 − 4 a c ] / 2 a \omega=[-b\pm\sqrt{b^2-4ac}]/2a ω=[−b±b2−4ac]/2a
a = σ 5 2 + σ 7 2 − 2 ρ 5 , 7 σ 5 σ 7 a=\sigma_5^2+\sigma_7^2-2\rho_{5,7}\sigma_5\sigma_7 a=σ52+σ72−2ρ5,7σ5σ7
b = 2 ρ 5 , 7 σ 5 σ 7 − 2 σ 7 2 b=2\rho_{5,7}\sigma_5\sigma_7-2\sigma_7^2 b=2ρ5,7σ5σ7−2σ72
c = σ 7 2 − σ 6 2 c=\sigma_7^2-\sigma_6^2 c=σ72−σ62
-
基本远期/期货
假如我们有 x x x 个价值为 F F F 的远期或期货合同,
V a R ≈ − α c l σ F x F VaR\approx -\alpha_{cl}\sigma_FxF VaR≈−αclσFxF
如上面方法类似,四个月合同可以映射为不同参考到期时间的组合,
I 4 m a p p e d = ω I 3 + ( 1 − ω ) I 6 I_4^{mapped}=\omega I_3+(1-\omega)I_6 I4mapped=ωI3+(1−ω)I6
-
-
其他复杂的头寸
- 带息债券
- Forward Rate Agreements
- Floating-rate instruments
- Vanilla interest-rate swaps
- Structural notes
- FX forwords
- Commodity, equity and FX swaps
-
Delta-Gamma and Related Approximations
我们已经看到了采用线性方法把头寸映射到风险因子上,本小结讨论非线性方法。
在处理期权和固收类时,这种非线性关系非常普遍。
-
Delta-Normal 方法
想象我们有股票看涨期权价值为 c c c, 价值依赖于很多底层因子,例如底层股票的价格、行权价格、价格波动率等。在Delta-Normal模型中,我们忽略除底层股票价格之外的其他因子,对期权价格变化采用一阶泰勒近似,
Δ c ≈ δ Δ S \Delta c\approx \delta \Delta S Δc≈δΔS, Δ c = c − c ˉ \Delta c=c-\bar{c} Δc=c−cˉ , Δ S = S − S ˉ \Delta S=S-\bar{S} ΔS=S−Sˉ
其中, δ \delta δ 是期权的delta,带上划线的是该变量的当前值。
当处理非常短的Holding Period时,
V a R o p t i o n ≈ δ V a R S ≈ − δ α x l σ S VaR^{option}\approx\delta VaR^S \approx -\delta \alpha_{xl}\sigma S VaRoption≈δVaRS≈−δαxlσS , σ \sigma σ 是 S S S 的波动率
-
Delta-Gamma方法
Delta-Gamma方法采用的是二阶泰勒近似,
Δ c ≈ δ Δ S + ( γ / 2 ) ( Δ S ) 2 \Delta c \approx \delta \Delta S+(\gamma/2)(\Delta S)^2 Δc≈δΔS+(γ/2)(ΔS)2
-
Delta-Gamma normal approach
这种方法是把额外的风险项 ( Δ S ) 2 (\Delta S)^2 (ΔS)2 看成是一个独立的正态分布变量,
Δ c ≈ δ Δ S + ( γ / 2 ) Δ U \Delta c \approx \delta \Delta S+(\gamma/2)\Delta U Δc≈δΔS+(γ/2)ΔU
把期权看成为两个正态风险因子的线性组合,其波动率为
σ p = δ 2 σ 2 + ( γ / 2 ) 2 σ U 2 = δ 2 σ 2 + ( 1 / 4 ) γ 2 σ 4 \sigma_p=\sqrt{\delta^2\sigma^2+(\gamma/2)^2\sigma_U^2}=\sqrt{\delta^2\sigma^2+(1/4)\gamma^2\sigma^4} σp=δ2σ2+(γ/2)2σU2=δ2σ2+(1/4)γ2σ4
V a R o p t i o n = − α c l σ p S = − α c l σ S δ 2 + ( 1 / 4 ) γ 2 σ 2 VaR^{option}=-\alpha_{cl}\sigma_pS=-\alpha_{cl}\sigma S\sqrt{\delta^2+(1/4)\gamma^2\sigma^2} VaRoption=−αclσpS=−αclσSδ2+(1/4)γ2σ2
Delta-Gamma正态性方法通过把问题引回到线性正态领域而实现了可追溯性。但是这种方法存在一个逻辑问题,就是 Δ S \Delta S ΔS 和 ( Δ S ) 2 (\Delta S)^2 (ΔS)2 不可能都是正态分布,如果 Δ S \Delta S ΔS 是正态的, ( Δ S ) 2 (\Delta S)^2 (ΔS)2 应该是卡方分布。
-
Wilson’s Delta-Gamma approach
Incremental and Component Risks
这一节主要讨论加性风险和风险分解。当改变投资组合时,风险如何变化;如何分解组合风险?
-
增量风险(Incremental risks)
当一些因子变化的时候,风险也会随之改变。例如说,我们想要知道但在组合中增加一个头寸时,VaR如何变化,这称为IVaR.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3GDbraB7-1573309733306)(C:\Users\Martin\Documents\IVaR.PNG)]
- The Before and After Approach
I V a R = V a R ( p + a ) − V a R ( p ) IVaR=VaR(p+a)-VaR(p) IVaR=VaR(p+a)−VaR(p)
- Garman’s ‘delVaR’ approach (Marginal VaRs)
设投资组合 p p p 有 n n n 个映射头寸 [ w 1 , w 2 , ⋯ , w 3 ] [w_1,w_2,\cdots,w_3] [w1,w2,⋯,w3] ,改变后的头寸大小为 [ w 1 + Δ w 1 , ⋯ , w n + Δ w n ] [w_1+\Delta w_1,\cdots,w_n+\Delta w_n] [w1+Δw1,⋯,wn+Δwn] ,采用一阶泰勒展开,
V a R ( p + a ) ≈ V a r ( p ) + ∑ i = 1 n ∂ V a R ∂ w i d w i VaR(p+a) \approx Var(p)+\sum_{i=1}^n\frac{\partial VaR}{\partial w_i}dw_i VaR(p+a)≈Var(p)+i=1∑n∂wi∂VaRdwi
最后一项即为 I V a R IVaR IVaR , d w i ≈ Δ w i dw_i \approx \Delta w_i dwi≈Δwi
I V a R ( a ) ≈ ▽ V a R ( p ) d w IVaR(a) \approx \bigtriangledown VaR(p)dw IVaR(a)≈▽VaR(p)dw
当P/L为正态分布,且均值向量为 μ \mu μ , 协方差矩阵为 Σ \Sigma Σ 时,
▽ V a R ( p ) = − μ + Σ w α c l [ w T Σ w ] 1 / 2 \bigtriangledown VaR(p)=-\mu + \frac{\Sigma w\alpha_{cl}}{[w^T\Sigma w]^{1/2}} ▽VaR(p)=−μ+[wTΣw]1/2Σwαcl
-
成分风险(component risks)
对一定的整体风险而言,我们希望对风险进行分解,从而知道其风险成分都有什么。风险成分需要满足两个主要特性:Incrementality 和 Additivity。做风险分解时,首先我们需要选择分解的维度,例如投资工具、资产类别等。投资组合的VaR是一个线性齐次函数:$VaR=\sum_{i=1}^nw_i\frac{\partial VaR}{\partial w_i}=\bigtriangledown VaR§w $ ,我们定义工具 i i i 的成分VaR, C V a R i = w i ∂ V a R ∂ w i CVaR_i=w_i \frac{\partial VaR}{\partial w_i} CVaRi=wi∂wi∂VaR , V a R = ∑ i = 1 n C V a R i VaR=\sum_{i=1}^n CVaR_i VaR=∑i=1nCVaRi .
如果P/L为正态, C V a R i ≈ ω i β i V a R ( p ) CVaR_i \approx \omega_i \beta_i VaR(p) CVaRi≈ωiβiVaR(p) ,这里 ω i \omega_i ωi 为工具 i i i 在整个组合中的比重,认为非常小; β i \beta_i βi 是工具 i i i 在组合中的贝塔系数 σ i , p / σ p 2 \sigma_{i,p}/\sigma_p^2 σi,p/σp2 , σ i , p \sigma_{i,p} σi,p 是工具 i i i 与组合 p p p 的收益协方差。
估算流动性风险
本节讨论流动性问题和它是如何影响风险度量的,主要包含以下内容:
- 市场流动性和不流动性,以及其关联成本和风险。
- 在流动性和不流动性下估算VaR(LVaR, liquidity-adjust VaR)和ETL(LETL, liquidity-adjust ETL)。
- 度量在险流动性(LaR, Liquidity at Risk)
- 度量危机相关流动性风险(crisis-related liquidity risk)
1)流动性和流动性风险
流动性是市场的功能,是执行交易或改变头寸,同时保持无成本,无风险,且具备便利性的能力。流动性依赖于市场中交易者的数量、交易频率、交易大小;交易时间和交易成本等多种因素。不同的交易工具具有不同的流动性成本和风险。
第一个关心的问题使流动性问题如何影响VaR和ETL的估算,首先需要集中在流动性成本和流动性风险,因为它们与度量市场风险非常相关。流动性成本的主因是买卖价差(bid-ask spread)
2)交易成本估算法
T C = [ 1 + P S / M S ] λ 1 ( A L × s p r e a d / 2 ) e x p ( − λ 2 h p ) TC=[1+PS/MS]^{\lambda_1}(AL\times spread/2)exp(-\lambda_2 hp) TC=[1+PS/MS]λ1(AL×spread/2)exp(−λ2hp)
T C TC TC 是交易成本, P S PS PS 是头寸大小, M S MS MS 是市场大小, A L AL AL 是在持有期 h p hp hp 结束时流动量, s p r e a d spread spread 是买卖价差, λ 1 \lambda_1 λ1 近似于交易成本的弹性, λ 2 \lambda_2 λ2 近似于延迟率。
L V a R = V a R + T C LVaR=VaR+TC LVaR=VaR+TC ,
可得 L V a R = V a R + k P S 1 + k LVaR=\frac{VaR+kPS}{1+k} LVaR=1+kVaR+kPS , k = [ 1 + P S / M S ] λ 1 ( s p r e a d / 2 ) e x p ( − λ 2 h p ) k=[1+PS/MS]^{\lambda_1}(spread/2)exp(-\lambda_2 hp) k=[1+PS/MS]λ1(spread/2)exp(−λ2hp)
L V a R V a R = 1 + k P S / V a R 1 + k \frac{LVaR}{VaR}=\frac{1+kPS/VaR}{1+k} VaRLVaR=1+k1+kPS/VaR

3)The Exogenous Spread Approach
如果我们的头寸相对于市场非常小,我们可以认为流动性风险和我们的交易是无关的。假设价差具备均值 μ s p r e a d \mu_{spread} μspread ,标准差为 σ s p r e a d \sigma_{spread} σspread ,那么在 95% 的置信水平下,有
L V a R = [ 1 + ( μ s p r e a d + 1.645 σ s p r e a d ) / 2 ] V a R LVaR=[1+(\mu_{spread}+1.645\sigma_{spread})/2]VaR LVaR=[1+(μspread+1.645σspread)/2]VaR
4)The Market Price Response Approach
集中考虑交易对市场价格的影响。
5)Derivatives Pricing Approaches
这种方法比较适合于流动性调整下的衍生品定价。
我们定义流动性变量 L L L 为底层资产价格 S S S 对交易量 N N N 的偏导的倒数, L = 1 / ( ∂ S / ∂ N ) L=1/(\partial S/\partial N) L=1/(∂S/∂N) ,认为 S S S 遵循以下过程: d S = μ d t + σ d x t + 1 L d N dS=\mu dt+\sigma dx_t+\frac{1}{L}dN dS=μdt+σdxt+L1dN ,最后一项反映了顶层资产交易的影响。
如果我们用Black-Shore等式建模,我们可以导出流动性调整后的等式,然后采用蒙特卡洛模拟来估算VaR和ETL.
6)The Liquidity Discount Approach
流动性折损法有更为宽泛的应用且更为灵活,但它的要求也更多。考虑一个交易者,当他面临流动性优化问题时,他需要在一定的期间内流动其头寸,且最大化功效和寻找最好的方法。从三个方面来调整VaR:优化持有期、增加平均流动折损、增加流动时间波动和折损因子波动。
流动性折损被表示称为一个比例因子 c ( s ) c(s) c(s) , s s s 为交易量,
L V a R = − μ h p − μ l o g c ( s ) − α c l σ h p + 2 σ l o g c ( s ) LVaR=-\mu hp-\mu_{logc(s)}-\alpha_{cl}\sigma\sqrt{hp}+2\sigma_{logc(s)} LVaR=−μhp−μlogc(s)−αclσhp+2σlogc(s)
7)Summary and Comparison
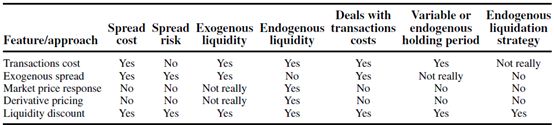
估算在险流动性(LaR)
LaR有时也称为在险现金流(cash flow at risk),为在一定期间内和在给定的置信区间最可能的流出现金流,它与流动性相关损失所带来的风险不同。LaR对很多因子都很敏感,包括:
- 借贷
- 保证金
- 附带义务
- 期权执行时触发的非预期现金流
- 风险管理策略变化
估算危机中的流动性
我们现在考虑在危机情况下的流动性。在危机发生的时候,很多金融资产都会迅速贬值,出现重大损失和高买卖价差。
假如我们持有一个单一的衍生品工具头寸,其P/L是一个delta-gamma近似,
Π = δ d S + 0.5 γ ( d S ) 2 \Pi=\delta dS+0.5\gamma (dS)^2 Π=δdS+0.5γ(dS)2 , d S dS dS 是股票价格的变化,最大损失出现的条件是 d S = − γ / δ dS=-\gamma/\delta dS=−γ/δ
得到 L m a x = − Π m i n = δ 2 / ( 2 γ ) L^{max}=-\Pi^{min}=\delta^2/(2\gamma) Lmax=−Πmin=δ2/(2γ) ,最坏情况下的现金流出为 m δ 2 / ( 2 γ ) m\delta^2/(2\gamma) mδ2/(2γ) , m m m 是保证金和附带责任。
实际上,上述方法还是过于简单了,还应该考虑信用事件与市场风险因子的交互影响。
回测市场风险
在我们确信我们的模型之前,我们需要验证其准确性;模型验证的关键问题是回测,回测是一种量化应用,通常采用统计方法来检验模型的风险估算是否与模型的假设是一致的。回测是风险度量过程的关键步骤,我们依赖其给出模型存在问题的指示。
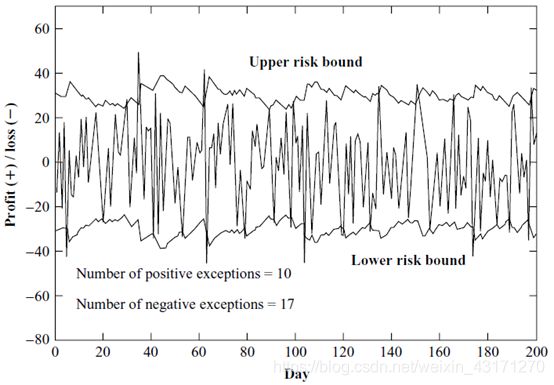
A backtesting chart
上图是一个假设组合的日P/L序列,在5%到95%的置信水平下,预期有10个正向意外点和10个负向意外点,我们实际观察到了10个正向意外点和17个负向意外点。
-
STATISTICAL BACKTESTS BASED ON THE FREQUENCY OF TAIL LOSSES
所有统计检验的基本思想都是先选择显著性水平,然后假设原假设为真的情况下估算概率。
1)The Basic Frequency-of-tail-losses (or Kupiec) Test
这大概是最为广泛使用的尾部损失频率检验法,其主要思想是检验观察到的尾部损失频率(超过VaR的损失频率)与模型预测的频率是否一致。原假设为"The model is good",尾部损失的数量 x x x 服从二项式分布,
P r o b ( x ∣ n . p ) = ( n i ) p i ( 1 − p ) n − i Prob(x|n.p) = {n \choose i}p^i(1-p)^{n-i} Prob(x∣n.p)=(in)pi(1−p)n−i , n n n 为P/L的观测值的数量, p p p 为尾部损失的预测频率,等于1-VaR的置信水平。
2)The Time-to-first-tail-loss Test
如果尾部损失的概率为 p p p ,在期间 T T T 内观测到第一次尾部损失的概率为 p ( 1 − p ) T − 1 p(1-p)^{T-1} p(1−p)T−1 ,截至到期间 T T T 观测到第一次尾部损失的概率为 1 − ( 1 − p ) T 1-(1-p)^T 1−(1−p)T ,服从几何分布

3)A Tail-Loss Confidence-interval Test这种方法是用来估算尾部损失的次数的置信区间,基于可用样本,它检查尾部损失的次数的期望值是否在样本中。
4)The Conditional Backtesting (Christoffersen) Approach
这种方法的主要思想是分离特别的假设,对分离后的假设分别做检验。
-
STATISTICAL BACKTESTS BASED ON THE SIZES OF TAIL LOSSES
前面的统计检验法主要考虑尾部风险发生的次数,但实际上损失的多少也是非常有用的信息。这一点对模型的完备性非常重要。
1)The Basic Sizes-of-tail-losses Test
首先估算VaR,然后对P/L数据值取负数从而使损失为正,只保留损失高于VaR的数据;这样得到了尾部损失观测值的经验分布。接下来我们用模型来预测此分布,然后比较两个分布的差,通常采用K-S检验。
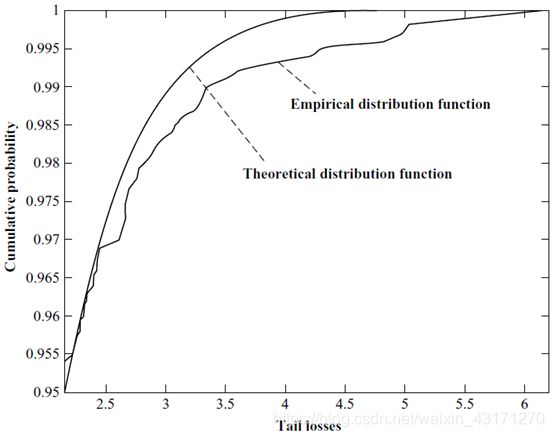
2)The Crnkovic–Drachman Backtest Procedure
这种方法的关键是通过比较P/L的经验分布和预测分布的差异来评价模型,跨越其整个值域。每一个P/L观测值可以被分类成预测分布的分位数,如果模型是良好的,所分类的P/L观测值应该呈现均匀分布且是独立的。这种推理导出了两种检验:
- 均匀分布检验
- 标准独立检验(BDS test)
3)The Berkowitz Approach
CD方法告诉我们分类的P/L观测值应该服从 i i d U ( 0 , 1 ) iid \ U(0,1) iid U(0,1) ,我们可以在原假设下将其转化为正态分布:
如果 x t ∼ i i d U ( 0 , 1 ) x_t \sim iid \ U(0,1) xt∼iid U(0,1) , 那么 z t = Φ − 1 ( x ) z_t=\Phi^{-1}(x) zt=Φ−1(x) 为 i i d N ( 0 , 1 ) iid \ N(0,1) iid N(0,1)
在正态分布下,我们可以使用更多的统计方法来进行检验。
-
FORECAST EVALUATION APPROACHES TO BACKTESTING
这一类方法允许我们对模型进行分级,但是并不提供任何关于模型完备性的统计指示。在分级中,它也允许我们考虑任何其他的特殊因素,例如我们会更加关心高额损失,因此希望给高额损失更大的权重。
预测评估过程有四个要素、一个输出和对每一个模型的最终评分。
四个要素为:
-
n n n 个成对观测值的集合(每一段期间的P/L和其关联的预测VaR)
-
损失函数:给每一个观测一个分数用来衡量其对比于VaR预测的观测损失。
如果 L t L_t Lt 为在期间 t t t 的损失或者盈利,损失函数为
if L t > V a R t L_t \gt VaR_t Lt>VaRt , C t = f ( L t , V a R t ) C_t=f(L_t,VaR_t) Ct=f(Lt,VaRt)
else, C t = g ( L t , V a R t ) C_t=g(L_t,VaR_t) Ct=g(Lt,VaRt)
-
基准:一个良好模型的期望分数
-
评分函数: Q P S = ( 2 / n ) ∑ t = 1 n ( C t − p ) 2 QPS=(2/n)\sum_{t=1}^n(C_t-p)^2 QPS=(2/n)∑t=1n(Ct−p)2, Q P S i n [ 0 , 2 ] QPS\ in \ [0,2] QPS in [0,2]
1)The Frequency-of-tail-losses (Lopez I) Approach
Binominal Loss Function
if L t > V a R t L_t \gt VaR_t Lt>VaRt , C t = 1 C_t=1 Ct=1
else, C t = 0 C_t=0 Ct=0
基准 p = E ( C t ) p=E(C_t) p=E(Ct)
2)The Size-adjusted Frequency (Lopez II) Approach
if L t > V a R t L_t \gt VaR_t Lt>VaRt , C t = 1 + ( L t − V a R t ) 2 C_t=1+(L_t-VaR_t)^2 Ct=1+(Lt−VaRt)2
else, C t = 0 C_t=0 Ct=0
基准估算通过蒙特卡洛模拟
3)The Blanco-Ihle Approach
基于前面方法中金额的平方项并没有很好的解释,
if L t > V a R t L_t \gt VaR_t Lt>VaRt , C t = ( L t − V a R t ) / V a R t C_t=(L_t-VaR_t)/VaR_t Ct=(Lt−VaRt)/VaRt
else, C t = 0 C_t=0 Ct=0
基准为 E T L − V a R V a R \frac{ETL-VaR}{VaR} VaRETL−VaR
4)An Alternative Sizes-of-tail-losses Approach
if L t > V a R t L_t \gt VaR_t Lt>VaRt , C t = L t C_t=L_t Ct=Lt
else, C t = 0 C_t=0 Ct=0
二次评分函数: Q S = ( 2 / n ) ∑ t = 1 n ( C t − E T L t ) 2 QS=(2/n)\sum_{t=1}^n(C_t-ETL_t)^2 QS=(2/n)∑t=1n(Ct−ETLt)2
基准为ETL
-
-
ASSESSING THE ACCURACY OF BACKTEST RESULTS
标准的统计回测方法非常依赖于一个估算的概率值,毕竟其真实概率无从得知。所以,我们需要知道所估算概率值的精确度。
-
BACKTESTING WITH ALTERNATIVE CONFIDENCE LEVELS, POSITIONS AND DATA

压力测试
压力测试是用来判定投资组合对于假设事件的脆弱程度的标准步骤。长久以来,金融机构一直在使用压力测试,特别是在判定其利率风险敞口。压力测试比较适合于在危机情况下量化我们可能的损失,当危机出现时,正常的市场关系被打破,而VaR和ETL都带有误导性。
压力测试可以确定我们的脆弱程度在不同的危机场景下,
-
正常相关关系被打破
-
突然的流动性下降
-
集中风险
-
宏观经济风险
压力测试主要有两类方式,
- 场景分析
模拟场景来评价模型。
- 机械化压力测试
评价一系列统计可能性下的模型表现
模型风险
金融模型是规范框架,可以使我们确定输出的价值,例如资产价格、对冲比率、VaR等。模型主要有三类:基础的、描述性的、和统计模型。
模型是对真实世界高度简化抽象的结构,我们不应该期望模型可以给出完美的结果。模型必定会存在一定程度的错误,我们可以把这种错误的风险称为模型风险。需要注意的是并不是所有模型的输出错误都是模型风险。
金融模型的最主要的输出就是价格,例如期权定价模型中的期权价格,Greek hedge ratio, options delta/gamma,或者风险度量中的VaR和ETL。无论任何模型都会有价格上的某种错误,事实上模型风险总会归于价格风险。
-
SOURCES OF MODEL RISK
1)Incorrect Model Specification
Stochastic processes might be misspecified
Missing risk factors
Misspecified relationships
Transactions costs and liquidity factors
2)Incorrect Model Application
当一个良好的模型被错误应用时也会产生模型风险。
3)Implementation Risk
模型的实现方式也会产生模型风险
4)Other Sources of Model Risk
Incorrect Calibration
Programming Problems
Data Problems
-
COMBATING MODEL RISK
模型风险并不能被完全消除,但是可以在一定程度上缩减。
1)Some Guidelines for Risk Practitioners
Be aware of model risk
Identify, evaluate and check key assumptions
Test models against known problems
Choose the simplest reasonable model
Backtest and stress test the model
Estimate model risk quantitatively
Don’t ignore small problems
Plot results and use non-parametric statistics
Re-evaluate models periodically
2)Some Guidelines for Managers
Pay attention to warning signals
Ensure that their risk control systems are working3)Institutional Methods to Combat Model Risk
Procedures to Vet, Check and Review Models
Independent Risk Oversight