深度学习:基于python:第三章
文章目录
- 第三章 神经网络
-
- 3.1 从感知机到神经网络
-
- 3.1.1 神经网络的例子
- 3.1.2 复习感知机
- 3.1.3 激活函数登场
- 3.2 激活函数
-
- 3.2.1 sigmoid函数
- 3.2.2 阶跃函数的实现
- 3.2.3 阶跃函数的图形
- 3.2.4 sigmoid函数的实现
- 3.2.5 sigmoid函数和阶跃函数的比较
- 3.2.6 非线性函数
- 3.2.7 ReLU函数
- 3.3 多维数组的运算
-
- 3.3.1 多维数组
- 3.3.2 矩阵乘法
- 3.3.3 神经网络的内积
- 3.4 3层神经网络的实现
-
- 3.4.1 符号确认
- 3.4.2 各层间信号传递的实现
-
- **现第1层到第2层的信号传递**
- 第2层到输出层的信号传递
- 3.4.3 代码实现小结
- 3.5 输出层的设计
-
- 3.5.1 恒等函数和 softmax函数
-
- 恒等函数:
- softmax函数
- 3.5.2 实现 softmax函数时的注意事项
- 3.5.3 softmax函数的特征
- 3.5.4 输出层的神经元数量
- 3.6 手写数字识别
-
- 3.6.1 MNIST数据集
- 3.6.2 神经网络的推理处理
- 3.6.3 批处理
- 3.7 小结
- 3.8 总结(函数)
-
- 1.激活函数
-
- sigmoid函数 (处理h() )
- ReLU函数(处理h() )
- 2.输出层
-
- softmax函数
- 恒等函数
- 3.总函数:例子
第三章 神经网络
3.1 从感知机到神经网络
3.1.1 神经网络的例子
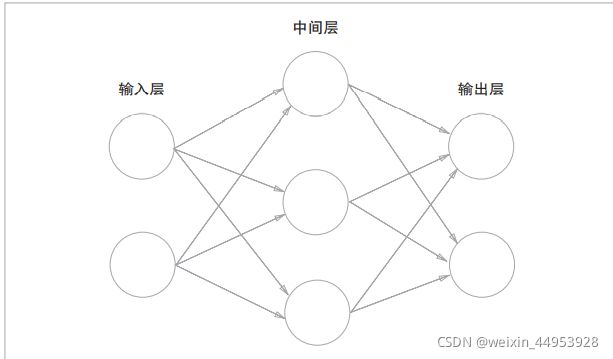
网络一共由 3层神经元构成,但实质上只有 2层神经 元有权重,因此将其称为“2层网络”。请注意,有的书也会根据 构成网络的层数,把图 3-1的网络称为“3层网络”。本书将根据 实质上拥有权重的层数(输入层、隐藏层、输出层的总数减去 1 后的数量)来表示网络的名称
3.1.2 复习感知机
y = h(b + w1x1 + w2x2)

3.1.3 激活函数登场
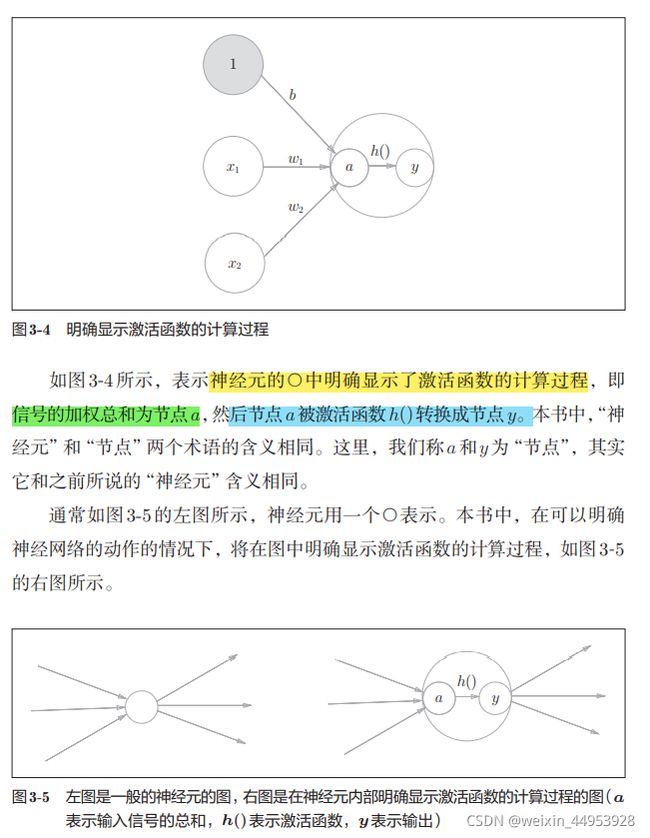
刚才登场的h(x)函数会将输入信号的总和转换为输出信号,这种函数 一般称为激活函数
a = b + w1x1 + w2x2
y = h(a)
3.2 激活函数
3.2.1 sigmoid函数

神经网络中用sigmoid函数作为激活函数,进行信号的转换,信号被传送给下一个神经元。
3.2.2 阶跃函数的实现
支持NumPy数组的实现的函数
def step_function(x):
y = x > 0
return y.astype(np.int)
这个这个函数的运算过程

astype()方法转换NumPy数组的类型。astype()方法通过参数指定期望的类型,
这个例子中是np.int型。Python中将布尔型 转换为int型后,True会转换为1,False会转换为0。
3.2.3 阶跃函数的图形
函数
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()
np.arange(-5.0, 5.0, 0.1)在−5.0到5.0的范围内,以0.1为单位,生成 NumPy数组([-5.0, -4.9, …, 4.9])。
step_function()以该NumPy数组为 参数,对数组的各个元素执行阶跃函数运算,并以数组形式返回运算结果。
3.2.4 sigmoid函数的实现
def sigmoid(x):
return 1 / (1 + np.exp(-x))
>>> x = np.array([-1.0, 1.0, 2.0])
>>> sigmoid(x)
array([ 0.26894142, 0.73105858, 0.88079708])
以sigmoid函数的实现能支持NumPy数组,秘密就在于NumPy的 广播功能。根据NumPy 的广播功能,
如果在标量和NumPy数组 之间进行运算,则标量会和NumPy数组的各个元素进行运算。
3.2.5 sigmoid函数和阶跃函数的比较
sigmoid函数是一条平 滑的曲线,输出随着输入发生连续性的变化。
而阶跃函数以0为界,输出发 生急剧性的变化
相对于阶跃函数只能返回0或1,
sigmoid函数可以返 回0.731 …、0.880 …等实数
3.2.6 非线性函数
神经网络的激活函数必须使用非线性函数。
3.2.7 ReLU函数
def relu(x):
return np.maximum(0, x)

3.3 多维数组的运算
3.3.1 多维数组
>>> import numpy as np
>>> A = np.array([1, 2, 3, 4])
>>> print(A)
[1 2 3 4]
>>> np.ndim(A)
1
>>> A.shape
(4,)
>>> A.shape[0]
4
>>> B = np.array([[1,2], [3,4], [5,6]])
>>> print(B)
[[1 2]
[3 4]
[5 6]]
>>> np.ndim(B)
2
>>> B.shape
(3, 2)
数组的维数可以通过np.dim()函数获得,A是一维数组,由4个元素 构成
注意,这里的A.shape的结果是个元组(tuple)。
3.3.2 矩阵乘法
>>> A = np.array([[1,2], [3,4]])
>>> A.shape
(2, 2)
>>> B = np.array([[5,6], [7,8]])
>>> B.shape
(2, 2)
>>> np.dot(A, B)
array([[19, 22],
[43, 50]])
A 和 B 都 是 2 × 2 的 矩 阵,它 们 的 乘 积 可 以 通 过 NumPy 的 np.dot()函数计算(乘积也称为点积)。np.dot()接收两个NumPy数组作为参 数,并返回数组的乘积。
>>> A = np.array([[1,2,3], [4,5,6]])
>>> A.shape
(2, 3)
>>> B = np.array([[1,2], [3,4], [5,6]])
>>> B.shape
(3, 2)
>>> np.dot(A, B)
array([[22, 28],
[49, 64]])
3.3.3 神经网络的内积
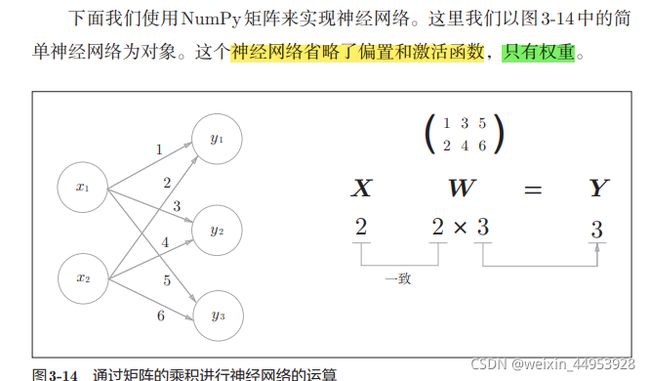
>>> X = np.array([1, 2])
>>> X.shape
(2,)
>>> W = np.array([[1, 3, 5], [2, 4, 6]])
>>> print(W)
[[1 3 5]
[2 4 6]]
>>> W.shape
(2, 3)
>>> Y = np.dot(X, W)
>>> print(Y)
[ 5 11 17]
3.4 3层神经网络的实现

3.4.1 符号确认

3.4.2 各层间信号传递的实现
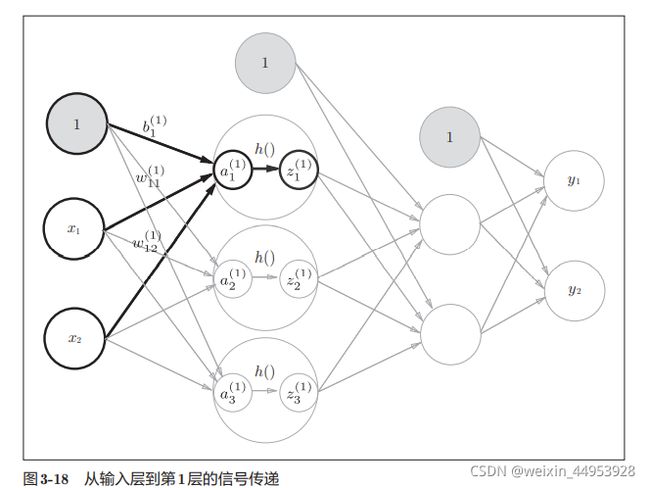
#### **现输入层到第1层的信号传递**


X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1
Z1 = sigmoid(A1)
print(A1) # [0.3, 0.7, 1.1]
print(Z1) # [0.57444252, 0.66818777, 0.75026011
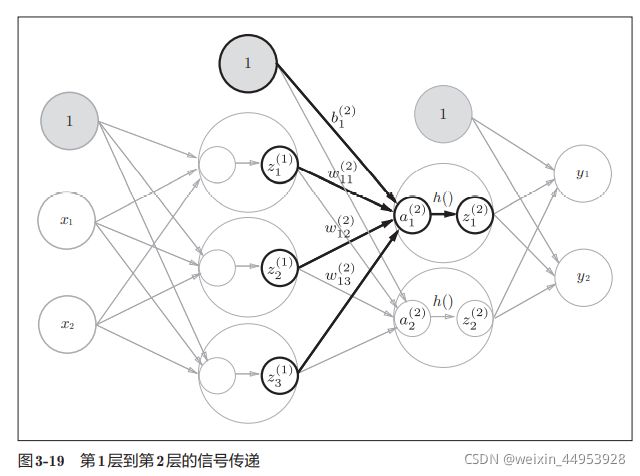
如图3-18所示,隐藏层的加权和(加权信号和偏置的总和)用a表示,被 激活函数转换后的信号用z表示。此外,图中h()表示激活函数,

现第1层到第2层的信号传递
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape) # (3,)
print(W2.shape) # (3, 2)
print(B2.shape) # (2,)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
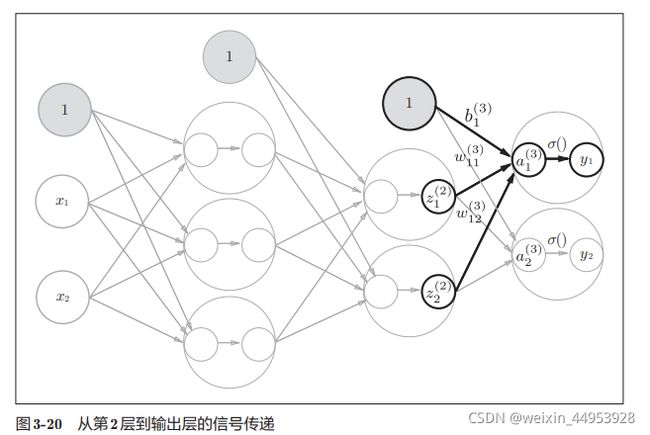
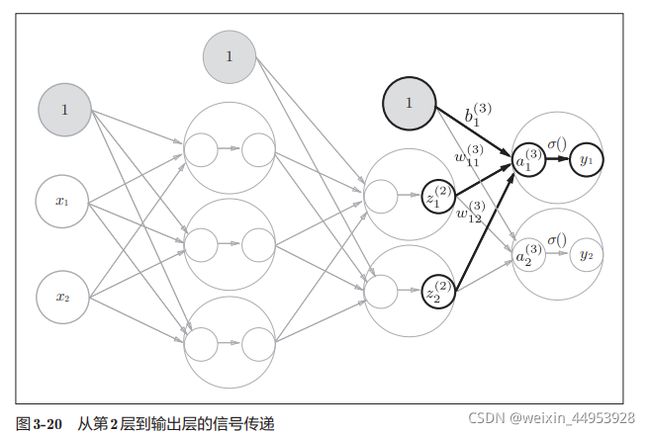
第2层到输出层的信号传递
输出层的实现也和之前的 实现基本相同。不过,最后的激活函数和之前的隐藏层有所不同
输出层的激活函数用σ()表示,不同于隐 藏层的激活函数h()(σ读作sigma)。
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3) # 或者Y = A3
3.4.3 代码实现小结
def init_network():
network = {
}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [ 0.31682708 0.69627909]
定义了init_network()和forward()函数。
init_network()函数会进 行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变 量network中保存了每一层所需的参数(权重和偏置)。
forward()函数中则封装了将输入信号转换为输出信号的处理过程。
3.5 输出层的设计
神经网络可以用在分类问题和回归问题上
回归问题用恒等函数,分类问题用softmax函数。
3.5.1 恒等函数和 softmax函数
恒等函数:
会将输入按原样输出,对于输入的信息,不加以任何改动地直 接输出。

softmax函数


函数:
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
解释:
>>> a = np.array([0.3, 2.9, 4.0])
>>>
>>> exp_a = np.exp(a) # 指数函数
>>> print(exp_a)
[ 1.34985881 18.17414537 54.59815003]
>>>
>>> sum_exp_a = np.sum(exp_a) # 指数函数的和
>>> print(sum_exp_a)
74.1221542102
>>>
>>> y = exp_a / sum_exp_a
>>> print(y)
[ 0.01821127 0.24519181 0.73659691]
3.5.2 实现 softmax函数时的注意事项

函数:
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
>>> a = np.array([1010, 1000, 990])
>>> np.exp(a) / np.sum(np.exp(a)) # softmax函数的运算
array([ nan, nan, nan]) # 没有被正确计算
>>>
>>> c = np.max(a) # 1010
>>> a - c
array([ 0, -10, -20])
>>>
>>> np.exp(a - c) / np.sum(np.exp(a - c))
array([ 9.99954600e-01, 4.53978686e-05, 2.06106005e-09])
3.5.3 softmax函数的特征
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
>>> a = np.array([0.3, 2.9, 4.0])
>>> y = softmax(a)
>>> print(y)
[ 0.01821127 0.24519181 0.73659691]
>>> np.sum(y)
1.0
3.5.4 输出层的神经元数量
3.6 手写数字识别
3.6.1 MNIST数据集
训练图像有6万张, 测试图像有1万张
MNIST数据集是由0到9的数字图像构成的(图3-24)。训练图像有6万张, 测试图像有1万张,这些图像可以用于学习和推理。MNIST数据集的一般 使用方法是,先用训练图像进行学习,再用学习到的模型度量能在多大程度 上对测试图像进行正确的分类。
MNIST的图像数据是28像素 × 28像素的灰度图像(1通道),各个像素 的取值在0到255之间。每个图像数据都相应地标有“7”“2”“1”等标签。
load_mnist函数以“(训练图像 ,训练标签 ),(测试图像,测试标签 )”的形式返回读入的MNIST数据。
还可以像load_mnist(normalize=True, flatten=True, one_hot_label=False) 这 样,设 置 3 个 参 数。第 1 个参数 normalize设置是否将输入图像正规化为0.0~1.0的值。如果将该参数设置 为False,则输入图像的像素会保持原来的0~255。第2个参数flatten设置 是否展开输入图像(变成一维数组)。如果将该参数设置为False,则输入图 像为1 × 28 × 28的三维数组;若设置为True,则输入图像会保存为由784个 元素构成的一维数组。第3个参数one_hot_label设置是否将标签保存为onehot表示(one-hot representation)。one-hot表示是仅正确解标签为1,其余 皆为0的数组,就像[0,0,1,0,0,0,0,0,0,0]这样。当one_hot_label为False时, 只是像7、2这样简单保存正确解标签;当one_hot_label为True时,标签则 保存为one-hot表示
训练图像
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0] #表示取出一个照片
label = t_train[0] #给记号就是几,比如标记为5,label=5
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸
print(img.shape) # (28, 28)
img_show(img)

3.6.2 神经网络的推理处理
下面,我们对这个MNIST数据集实现神经网络的推理处理。神经网络 的输入层有784个神经元,输出层有10个神经元。输入层的784这个数字来 源于图像大小的28 × 28 = 784,输出层的10这个数字来源于10类别分类(数 字0到9,共10类别)。此外,这个神经网络有2个隐藏层,第1个隐藏层有 50个神经元,第2个隐藏层有100个神经元。这个50和100可以设置为任何值。 下面我们先定义get_data()、init_network()、predict()这3个函数(代码在 ch03/neuralnet_mnist.py中)。
#会读入保存在pickle文件sample_weight.pkl中的学习到的权重参数
#这个文件中以字典变量的形式保存了权重和偏置参数。
#因为之前我们假设学习已经完成,所以学习到的参数被保存下来。假设保存在sample_weight.pkl文件中,
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
#用predict()函数进行分类
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
accuracy_cnt = 0
#用for语句逐一取出保存在x中的图像数据
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
执行上面的代码后,会显示“Accuracy:0.9352”。这表示有93.52 %的数 据被正确分类了。
3.6.3 批处理
>>> x, _ = get_data()
>>> network = init_network()
>>> W1, W2, W3 = network['W1'], network['W2'], network['W3']
>>>
>>> x.shape
(10000, 784)
>>> x[0].shape
(784,)
>>> W1.shape
(784, 50)
>>> W2.shape
(50, 100)
>>> W3.shape
(100, 10)


这种打包式的输入数据称为批(batch)
函数:
#会读入保存在pickle文件sample_weight.pkl中的学习到的权重参数
#这个文件中以字典变量的形式保存了权重和偏置参数。
#因为之前我们假设学习已经完成,所以学习到的参数被保存下来。假设保存在sample_weight.pkl文件中,
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
#用predict()函数进行分类
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
解释
>>> list( range(0, 10) )
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list( range(0, 10, 3) )
[0, 3, 6, 9]
>>> x = np.array([[0.1, 0.8, 0.1], [0.3, 0.1, 0.6],[0.2, 0.5, 0.3], [0.8, 0.1, 0.1]])
>>> y = np.argmax(x, axis=1) # argmax()获取值最大的元素的索引
#这指定了在100 × 10的数组中,沿着第1维方向(以第1维为轴)找到值最大的元素的索引(第0维对应第1个维度)
>>> print(y)
[1 2 1 0]
>>> y = np.array([1, 2, 1, 0])
>>> t = np.array([1, 2, 0, 0])
>>> print(y==t)
[True True False True]
>>> np.sum(y==t)
3
3.7 小结
- 神经网络中的激活函数使用平滑变化的sigmoid函数或ReLU函数。 •
- 通过巧妙地使用NumPy多维数组,可以高效地实现神经网络。 •
- 机器学习的问题大体上可以分为回归问题和分类问题。
- 关于输出层的激活函数,回归问题中一般用恒等函数,分类问题中 一般用softmax函数。 •
- 分类问题中,输出层的神经元的数量设置为要分类的类别数。 •
- 输入数据的集合称为批。通过以批为单位进行推理处理,能够实现 高速的运算。
3.8 总结(函数)
1.激活函数
sigmoid函数 (处理h() )
def sigmoid(x):
return 1 / (1 + np.exp(-x))
ReLU函数(处理h() )
def relu(x):
return np.maximum(0, x)
2.输出层
softmax函数
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
恒等函数
3.总函数:例子
#会读入保存在pickle文件sample_weight.pkl中的学习到的权重参数
#这个文件中以字典变量的形式保存了权重和偏置参数。
#因为之前我们假设学习已经完成,所以学习到的参数被保存下来。假设保存在sample_weight.pkl文件中,
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def sigmoid(x):
return 1 / (1 + np.exp(-x))
#用predict()函数进行分类
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))