Hadoop压缩方式与存储格式
一、数据压缩方式
1.1 hadoop常用的压缩方式
| 压缩格式 | 扩展名 | 可分割性 | 工具 | 算法 | 编码/解码类 | hadoop自带 | native |
|---|---|---|---|---|---|---|---|
| default | .deflate | 不 | 无 | deflate | DefaultCodec | 是 | 是 |
| gzip | .gz | 是 | gzip | deflate | GzipCodec | 是 | 是 |
| bzip2 | .bz2 | 是 | bzip2 | bzip2 | Bzip2Codec | 是 | 否 |
| lzo | .lzo | 是 | lzop | lzo | LzopCodec | 否 | 是 |
| snappy | .snappy | 不 | 无 | snappy | SnappyCodec | 否 | 是 |
1.2 使用压缩的准则:
- 平衡压缩和解压缩数据所需的能力、读写数据所需的磁盘 IO,以及在网络中发送数据所需的网络带宽。
- 如果数据已压缩(例如 JPEG 格式的图像),则不建议进行压缩。事实上,结果文件实际上可能大于原文件。
- GZIP 压缩使用的 CPU 资源比 Snappy 或 LZO 更多,但可提供更高的压缩比。GZIP 通常是不常访问的冷数据的不错选择。而 Snappy 或 LZO 则更加适合经常访问的热数据。
- BZip2 还可以为某些文件类型生成比 GZip 更多的压缩,但是压缩和解压缩时会在一定程度上影响速度。HBase 不支持 BZip2 压缩。
- 对于 MapReduce,需要分为3个阶段来分析:
(1). Map Input:
从HDFS读取数据,如果是大文件,压缩可以节省读取过程的IO开销,此过程中使用压缩应需要支持split(如:Bzip2)
(2)Map Out
写入到磁盘(使用网络传输),此过程使用压缩可以减少写入过程的IO开销和网络传输
作为Reduce的输入,使用压缩时速度一定要快而且支持split(如:snappy, lzo),因为reduce阶段需要立即响应
(3). Reduce Out
写入磁盘, 此过程使用压缩可以减少写入过程的IO开销和网络传输(如:BZip2, LZO)
作为下一个job的输入,使用压缩时速度一定要快而且支持split
1.3 压缩的应用
1.3.1. 压缩使用性能参考
| 压缩算法 | 压缩比 | 压缩速度 | 解压速度 |
|---|---|---|---|
| gzip | 13.4% | 17.5 MB/s | 58 MB/s |
| bzip2 | 13.2% | 2.4 MB/s | 9.5 MB/s |
| lzo | 20.5% | 49.3 MB/s | 74.6 MB/s |
| snappy | 22.2% | 59.3 MB/s | 74.0 MB/s |
1.3.2. 常用算法的特点与使用场景:
(1). gzip算法
特点:
hadoop内置支持,支持native库,使用方便,压缩比高
不支持split。
在压缩后的文件大小与HDFS块大小差距不大时,可使用此算法
应用场景:
一天或者一个小时的日志压缩成一个gzip文件,运行mapreduce程序的时候通过多个gzip文件达到并发。
(2). bzip2算法
特点:
hadoop内置支持,支持split,压缩比很高,
不支持native库,压缩/解压速度慢
对于历史性很大的文件,想尽可能节省磁盘空间,还要支持split
应用场景:
mapreduce的输出,压缩存档,作为冷数据使用,通常是对大文件的压缩。
(3). lzo算法
特点:
支持native库,压缩/解压速度也比较快,合理的压缩率;支持split(需要建索引,文件修改后需要重新建索引),yum安装lzop命令后,使用方便
hadoop内置不支持,需要手动编译安装。
大文件的存储,作为热数据使用
应用场景:
一个大文件压缩后依然是两个或多个HDFS块的大小,还不希望作为冷数据使用
(4). snappy算法
特点:
高速压缩速度和合理的压缩率,支持native库
hadoop内置不支持,需要手动编译安装,不支持split,没有linux命令可使用
应用场景:
mapreduce过程中map的输出,reduce或另一个map的输入
1.3.3. Hadoop API应用实例
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils;
public class CodecTest {
public static void main(String[] args) throws Exception {
compress("org.apache.hadoop.io.compress.BZip2Codec");
// compress("org.apache.hadoop.io.compress.GzipCodec");
// compress("org.apache.hadoop.io.compress.Lz4Codec");
// compress("org.apache.hadoop.io.compress.SnappyCodec");
// uncompress("text");
// uncompress1("hdfs://master:9000/user/hadoop/text.gz");
}
// 压缩文件
public static void compress(String codecClassName) throws Exception {
Class<?> codecClass = Class.forName(codecClassName);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
//输入和输出均为hdfs路径
FSDataInputStream in = fs.open(new Path("/test.log"));
FSDataOutputStream outputStream = fs.create(new Path("/test1.bz2"));
System.out.println("compress start !");
// 创建压缩输出流
CompressionOutputStream out = codec.createOutputStream(outputStream);
IOUtils.copyBytes(in, out, conf);
IOUtils.closeStream(in);
IOUtils.closeStream(out);
System.out.println("compress ok !");
}
// 解压缩
public static void uncompress(String fileName) throws Exception {
Class<?> codecClass = Class
.forName("org.apache.hadoop.io.compress.GzipCodec");
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
CompressionCodec codec = (CompressionCodec) ReflectionUtils
.newInstance(codecClass, conf);
FSDataInputStream inputStream = fs
.open(new Path("/user/hadoop/text.gz"));
// 把text文件里到数据解压,然后输出到控制台
InputStream in = codec.createInputStream(inputStream);
IOUtils.copyBytes(in, System.out, conf);
IOUtils.closeStream(in);
}
// 使用文件扩展名来推断二来的codec来对文件进行解压缩
public static void uncompress1(String uri) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path inputPath = new Path(uri);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.out.println("no codec found for " + uri);
System.exit(1);
}
String outputUri = CompressionCodecFactory.removeSuffix(uri,
codec.getDefaultExtension());
InputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(inputPath));
out = fs.create(new Path(outputUri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(out);
IOUtils.closeStream(in);
}
}
}
1.3.4 在配置文件中设置压缩方式
(1). 在core-site.xml中配置所有的codec类
<property>
<name>io.compression.codecsname>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
value>
property>
<property>
<name>io.compression.codec.lzo.classname>
<value>com.hadoop.compression.lzo.LzoCodecvalue>
property>
(2). 在mapred-site.xml中配置map
注意: 此配置文件设置后:所有产生mapreduce过程的程序都会使用,而且是长期有效的。
例1:配置reduce out过程为snappy的压缩
<property>
<name>mapreduce.output.fileoutputformat.compressname>
<value>truevalue>
property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codecname>
<value>org.apache.hadoop.io.compress.SnappyCodecvalue>
property>
使用lzo压缩时应注意:lzopCodec和lzoCodec的配置
当配置
当配置
hadoop 自带的 wc 应用测试:
$hadoop_home/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /xxx/input/xxx.txt
/xxx/output
1.3.5 在hive中临时设置
(1). 指定map out
1.开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
2.开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
3.设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4.执行查询语句
select count(ename) name from emp;
(2). 指定reduce out
1.开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
2.开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
3.设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
4.设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5.测试一下输出结果是否是压缩文件
insert overwrite local directory
'/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc
二、数据存储格式
2.1 Hadoop中的文件格式大致上分为面向行和面向列两类:
(1). 行式存储:一条数据保存为一行,读取一行中的任何值都需要把整行数据都读取出来(如:SequenceFile, MapFile, Avro Datafile),这种方式在磁盘读取的开销比较大,这无法避免。
(2). 列式存储:整个文件被切割为若干列数据,每一列中数据保存在一起(如:arquet , RCFile, ORCFile, CarbonData , IndexR)。这种方式会占用更多的内存空间,需要将行数据缓存起来。
2.2 常用的存储格式:
- SequnceFile
- Avro
- RCFile
- ORCFile
- Parquet
- IndexR
- TextFile
- JSON
- CSV
- CarbonData
其中 IndexR, CarbonData 是当前比 Parquet 更优秀的存储方式。
2.3 常用到的存储格式的简单概论:
(1). SequenceFile 是Hadoop API 提供的一种二进制文件,其内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile(hive:key为空,使用value 存放实际的值)。
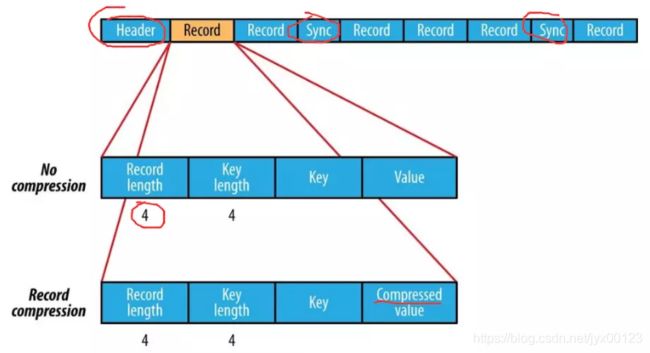
使用SqunceFile保存后文件都要比保存之前要大一些。由于SequnceFile文件头中定义了其元数据,元数据的内容根据压缩方式在决定;压缩都是选取block 级别进行的,每一个block都包含key的长度和value的长度,另外每4K字节会有一个sync-marker的标记。
SequenceFile的文件结构如下:
(2). Avro 是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件会在头部定义整个数据的模式(Schema)。这种方式存储后的文件要比RCFile存储占用更少的空间。
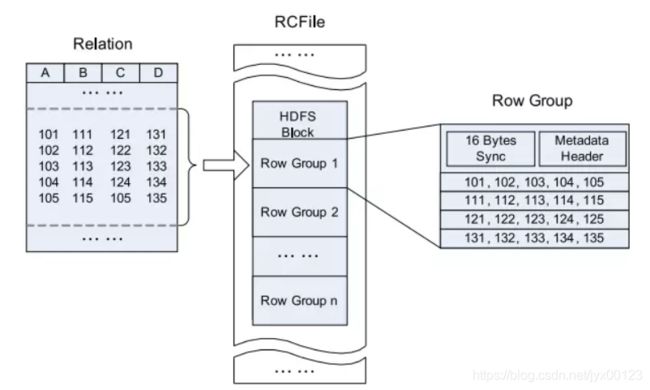
(3). RCFile 是Hive推出的一种专门面向列的数据格式。 它遵循“先按列划分,再垂直划分”的设计理念。这种存储方式会保存每个列的每个字段的长度,连续储存在头部元数据块中,而且每隔一定块大小重写一次头部的元数据块。
由于HDFS Block 的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高;而且头部对字段长度使用了Run Length Encoding进行压缩,所以RCFile 比SequenceFile又小一些。
Hive的Record Columnar File,这种类型的文件先将数据按行划分成Row Group,在Row Group内部,再将数据按列划分存储。其结构如下:
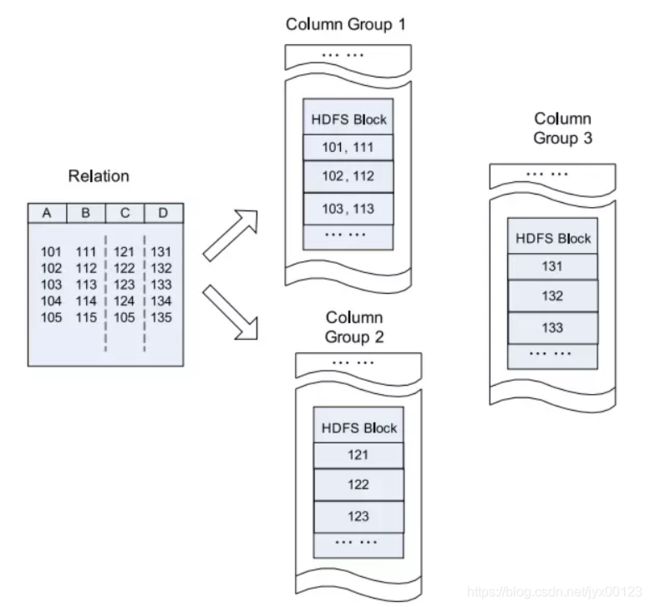
An Example of row_store in an HDFS block:
(4). ORCFile 提供了一种比RCFile更加高效的文件格式。其内部将数据划分为默认大小为250M的Stripe。每个Stripe包括索引、数据和Footer。索引存储每一列的最大最小值,以及列中每一行的位置。
在Hive中,如下命令用于使用ORCFile:
CREATE TABLE ... STORED AS ORC
ALTER TABLE ... SET FILEFORMAT ORC
SET hive.default.fileformat=ORC
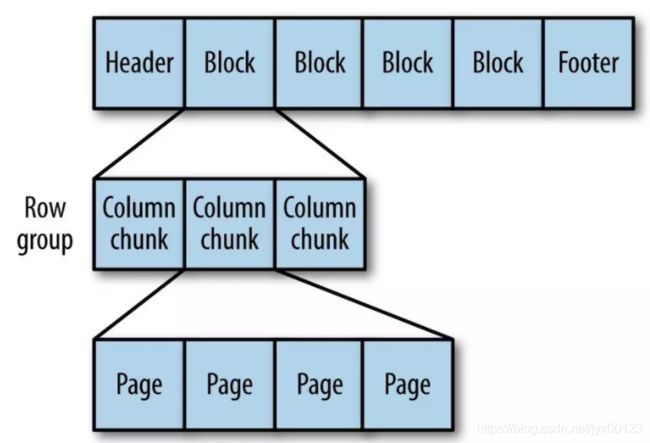
(5). Parquet 一种通用的面向列的存储格式,基于Google的Dremel。特别擅长处理深度嵌套的数据。
Parquet在2015年称为 Apache 顶级项目,后来被 Spark 项目吸收,作为 Spark 的默认数据源,在不指定读取和存储格式时,默认读写 Parquet 格式的文件。
列式存储的数据源一行一行来的,那Parquet是如何保存文件的呢?
首先在内存中缓存一些数据,等缓存到一定量后,将各个列的数据放在一起打包,这样各个包就可以按一定顺序写到一个文件中。这也就是列式存储的精髓:按列缓存打包。详细来讲,Parquet 在每一列内分成一个个的数据包,这个数据包就叫 Page,在Page 的开头存储元数据PageHeader,然后才是数据。 查询时,可通过PageHearder来进行过滤。更进一步来说,Parquet会先将多个 Page 放在一起存储,称为Column Chunk,作为每一列的组成单元,每个 Column Chunk都有其对应的ColumnChunk Metadata,在不同的Column Chunk内记录数据中不同的属性; 我们将多个Column Chunk称为Row Group,同样,不同的Row Group也有各自对应的Row Group Metadata,最终被放在File Metadata中。
Page 的分割标准可以按数据点数(如每1000行数据打成一个 Page),也可以按空间占用(如每列的数据攒到8KB合成一个 Page)。
(6). IndexR 适合于大数据的各种场景,包括离线和在线的各种统计分析,和快速过滤查询。是一个基于HDFS的分布式关系型列式数据库,擅长海量历史、实时数据的快速统计分析。
IndexR以列式存储数据,并分片存储,分片称为Segment,每一个Segment都是自解释的,包括Schema,数据以及索引。Segment通常是固定不变的,这极大简化了数据管理,便于分布式处理。
对于实时数据,IndexR可以多节点同时导入,导入效率高,而且以立刻被查询。实时导入的数据叫做Realtime Segment,在达到一定阀值后,IndexR会将它们合并成历史Segment,并上传到HDFS,之后数据就可以被离线分析工具所使用和管理。Realtime Segment会在磁盘上的commitlog文件保存所有更新操作,最新数据放在内存中以快速入库和索引,周期性将内存数据dump到磁盘。IndexR进程可以随时被重启,或者直接杀死,不用担心数据丢失。
高性能:
IndexR的扫描速度很快,约为Parquet的2.5倍。(冷数据 - 30M字段/秒/节点, 热数据 - 100M字段/秒/节点), OLAP查询约为Parquet格式的3~8倍,压缩后大小约为ORC格式的75%。
架构图:
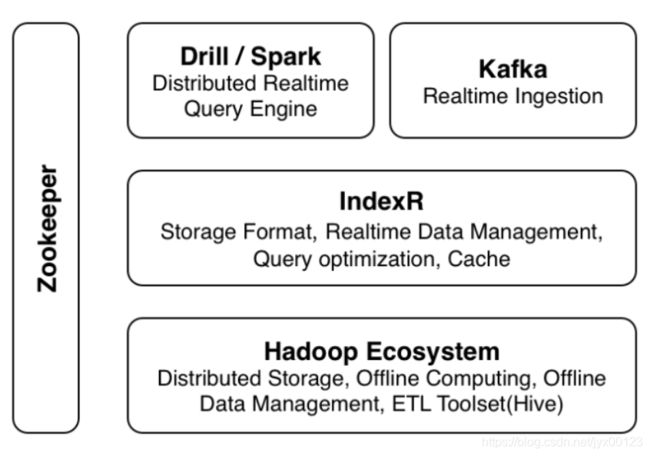
部署:
IndexR数据库系统部署非常简单,没有复杂依赖,只需要在所有Hadoop的DataNode(和NameNode)节点上部署一份带有IndexR插件的Drill节点,只有几项必须配置项,并且所有节点的配置都是一样的。在现有集群上部署IndexR通常可以在半小时之内完成,并且IndexR的服务逻辑嵌入了Drillbit进程,无需额外启动服务。
(7). CarbonData 的定位是作为一种通用的查询存储数据,通过Spark SQL来解决海量查询的问题,并且能够与Hadoop生态圈进行无缝对接。CarbonData最初的应用是与Spark SQL和Spark DataFrame深度结合,后续由携程团队将CarbonData引入了Presto,滴滴团队将CarbonData引入Hive。
文件存储格式:

File Header: 文件头的格式比较简单,保存了存储格式的版本和模式信息。
Blocklet: 单Blocklet最大的容量阀值为64M,也就是说单个HDFS的Block可以容纳多个Blocklet。这与ORCFile 和 Parquet都是一致的。
File Footer: 在文件尾部保存了存储数据的索引和摘要,索引是CarbonData最为核心的关键,它采用B+树的方式,允许支持二级索引,这样大大提高了CarbonData在不同查询场景之下的性能表现,但同时索引的使用压缩率缩减与数据导入时间的延长

实例1:
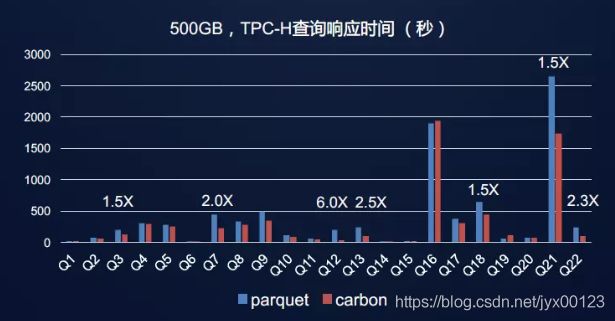
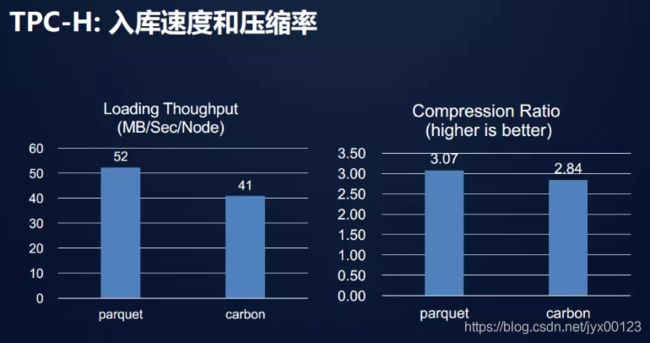
实例2:
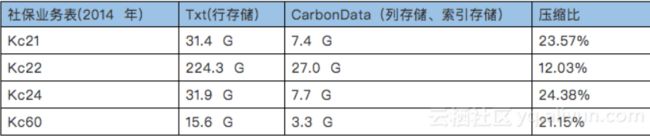
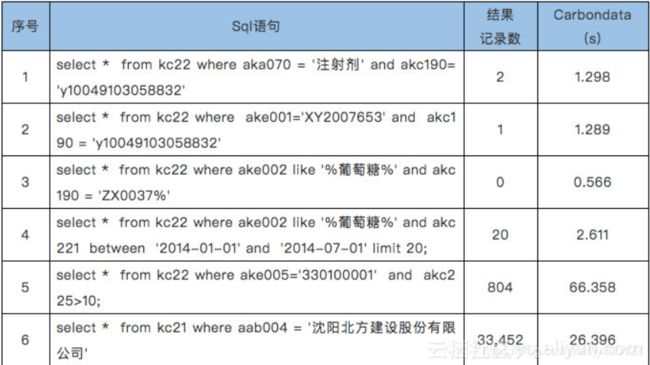
总结:
从上面的描述和实例中,可以看出CarbonData在数据查询的性能表现比Parquet好很多,在写一次读多次的场景下非常适合使用;社区比较活跃,响应也很及时。与最新的spark稳定版集成,增加了支持标准的Hive分区,支持流数据准实时入库等新特性。
