Day49_深入HBase(一)
(一)重要工作机制
1、读数据流程
- 从zookeeper找到meta表所在的region的位置,然后读取meta表中的数据。而meta中又存储了用户表的region信息
ZK:/hbase/meta-region-server,该节点保存了meta表的region server数据

- 根据namespace、表名和rowkey根据meta表中的数据找到对应的region信息
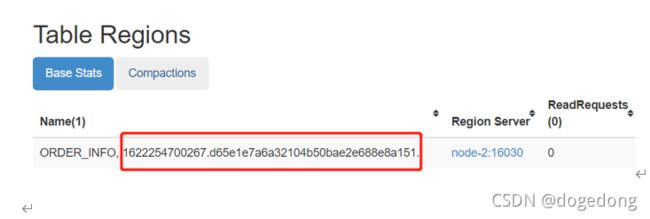
scan "hbase:meta", { FILTER => "PrefixFilter('ORDER_INFO')"}
ROW COLUMN+CELL
ORDER_INFO column=table:state, timestamp=1622254701537, value=\x08\x00
ORDER_INFO,,1622254700267.d65e1e7a6a321 column=info:regioninfo, timestamp=1622373881754, value={ENCODED => d65e1e7a6a32104b50bae2e688e8a151, NAME => 'ORDER_IN
04b50bae2e688e8a151. FO,,1622254700267.d65e1e7a6a32104b50bae2e688e8a151.', STARTKEY => '', ENDKEY => ''}
ORDER_INFO,,1622254700267.d65e1e7a6a321 column=info:seqnumDuringOpen, timestamp=1622373881754, value=\x00\x00\x00\x00\x00\x00\x02_
04b50bae2e688e8a151.
ORDER_INFO,,1622254700267.d65e1e7a6a321 column=info:server, timestamp=1622373881754, value=bd-offcn-02:16020
04b50bae2e688e8a151.
ORDER_INFO,,1622254700267.d65e1e7a6a321 column=info:serverstartcode, timestamp=1622373881754, value=1622373861799
04b50bae2e688e8a151.
ORDER_INFO,,1622254700267.d65e1e7a6a321 column=info:sn, timestamp=1622373880034, value=bd-offcn-02,16020,1622373861799
04b50bae2e688e8a151.
ORDER_INFO,,1622254700267.d65e1e7a6a321 column=info:state, timestamp=1622373881754, value=OPEN
04b50bae2e688e8a151.
- 找到对应的regionserver,查找对应的region
- 从MemStore找数据,再去BlockCache中找,如果没有,再到StoreFile上读
- 可以把MemStore理解为一级缓存,BlockCache为二级缓存,但注意scan的时候BlockCache意义不大,因为scan是顺序扫描

2、数据存储流程
- HBase V2.x以前版本
- 写内存(MemStore)
- 二阶段StoreFiles合并
2、Vx
- In-memory compaction(带合并的写内存)
- 二阶段StoreFiles合并
HBase的数据存储过程是分为几个阶段的。写入的过程与HBase的LSM结构对应。
- 为了提高HBase的写入速度,数据都是先写入到MemStore(内存)结构中,V2.0 MemStore也会进行Compaction
- MemStore写到一定程度(默认128M),由后台程序将MemStore的内容flush刷写到HDFS中的StoreFile
- 数据量较大时,会产生很多的StoreFile。这样对高效读取不利,HBase会将这些小的StoreFile合并,一般3-10个文件合并成一个更大的StoreFile
(1)写入MemStore
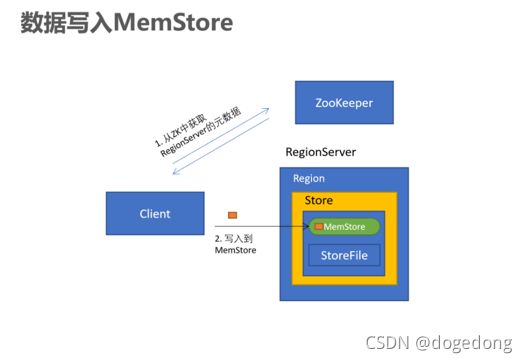
- Client访问zookeeper,从ZK中找到meta表的region位置
- 读取meta表中的数据,根据namespace、表名、rowkey获取对应的Region信息
- 通过刚刚获取的地址访问对应的RegionServer,拿到对应的表存储的RegionServer
- 去表所在的RegionServer进行数据的添加
- 查找对应的region,在region中寻找列族,先向MemStore中写入数据
(2)MemStore溢写合并
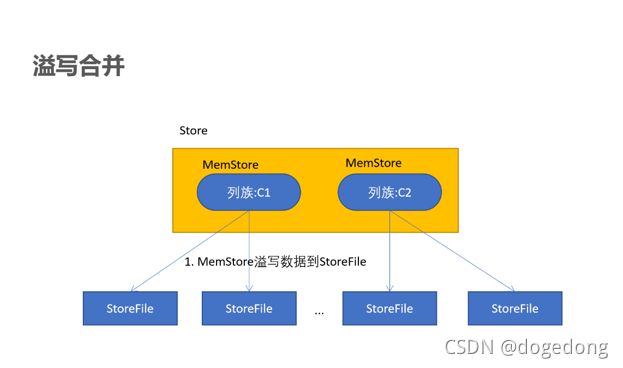
a、说明
- 当MemStore写入的值变多,触发溢写操作(flush),进行文件的溢写,成为一个StoreFile
- 当溢写的文件过多时,会触发文件的合并(Compact)操作,合并有两种方式(major,minor)
b、触发条件
Region级别
hbase.hregion.memstore.flush.size
134217728
hbase-default.xml
当一个 Region 中所有 MemStore 占用的内存达到了上限hbase.hregion.memstore.flush.size,默认128MB,会触发Memstore刷新。
但是如果数据增加得很快,达到了hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier的大小,
hbase.hregion.memstore.block.multiplier 默认值为4,也就是128*4=512MB的时候,那么除了触发 MemStore 刷写之外,HBase 还会在刷写的时候同时阻塞所有写入该 Store 的写请求!这时候如果你往对应的 Store 写数据,会出现RegionTooBusyException 异常
- RegionServer级别
HBase 为 RegionServer 的整体的 MemStore 分配了一定的写缓存,大概占用 RegionServer 整个 JVM 内存使用量的 40%:
hbase.regionserver.global.memstore.size=0.4,如果整个 RegionServer 的所有 MemStore 占用内存总和大于写缓存的0.95。将会触发 MemStore 的刷写。
hbase.regionserver.global.memstore.size.lower.limit=0.95
举个例子,如果我们 HBase 堆内存总共是 32G,按照默认的比例,那么触发 RegionServer 级别的 Flush 是 RS 中所有的 MemStore 占用内存为:32 * 0.4 * 0.95 = 12.16G。
RegionServer 级别的Flush策略是按照Memstore由大到小执行,先Flush Memstore最大的Region,再执行次大的,直至总体Memstore内存使用量低于阈值。需要注意的是,如果达到了RegionServer 级别的 Flush,那么当前 RegionServer 的所有写操作将会被阻塞,而且这个阻塞可能会持续到分钟级别。
- 自动刷写
hbase.regionserver.optionalcacheflushinterval
3600000
hbase-default.xml
- 手动刷写
用户可以通过shell命令 flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
disable 'user'
drop 'user'
create 'user', 'info', 'data'
put 'user','001','info:name','zhangsan'
flush 'user'
put 'user','002','info:name','lisi'
flush 'user'
(3)模拟数据查看MemStore使用情况

注意:此处小数是无法显示的,只显示整数位的MB。
- 将之前的水费账单数据再次导入一遍,查看效果。
hbase org.apache.hadoop.hbase.mapreduce.Import WATER_BILL /water_bill/output_ept_10W
- 打开Region所在的Region Server
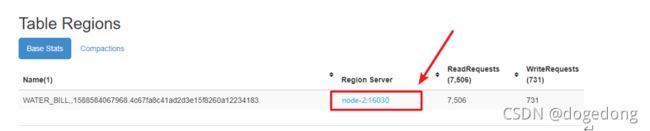
点击Memory查看内存占用情况

将数据可以手动刷新到到磁盘
hbase(main):004:0> flush 'WATER_BILL'
(4) In-memory合并(了解)
a、In-memory compaction介绍
In-memory合并是HBase 2.0之后添加的。它与默认的MemStore的区别:实现了在内存中进行compaction(合并)。
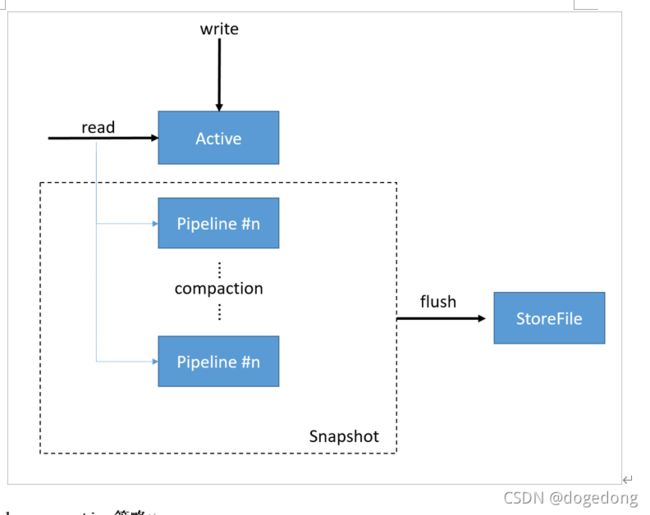
在CompactingMemStore中,数据是以段(Segment)为单位存储数据的。MemStore包含了多个segment。
- 当数据写入时,首先写入到的是Active segment中(也就是当前可以写入的segment段)
- 在2.0之前,如果MemStore中的数据量达到指定的阈值时,就会将数据flush到磁盘中的一个StoreFile
- 2.0的In-memory compaction,active segment满了后,将数据移动到pipeline中。这个过程跟以前不一样,以前是flush到磁盘,而这次是将Active segment的数据,移到称为pipeline的内存当中。一个pipeline中可以有多个segment。而In-memory compaction会将pipeline的多个segment合并为更大的、更紧凑的segment,这就是compaction
- HBase会尽量延长CompactingMemStore的生命周期,以达到减少总的IO开销。当需要把CompactingMemStore flush到磁盘时,pipeline中所有的segment会被移动到一个snapshot中,然后进行合并后写入到HFile
b、compaction策略
但Active segment flush到pipeline中后,后台会触发一个任务来合并pipeline中的数据。合并任务会扫描pipeline中所有的segment,将segment的索引合并为一个索引。有三种合并策略:
- basic(基础型)
- Basic compaction策略不清理多余的数据版本,无需对cell的内存进行考核(检查是否版本多余)
- basic适用于大量写模式
- eager(饥渴型)
- eager compaction会过滤重复的数据,清理多余的版本,这会带来额外的开销
- eager模式主要针对数据大量过期淘汰的场景,例如:购物车、消息队列等
- adaptive(适应型)
- adaptive compaction根据数据的重复情况来决定是否使用eager策略
- 该策略会找出cell个数最多的一个,然后计算一个比例,如果比例超出阈值,则使用eager策略,否则使用basic策略
c、配置
- 可以通过hbase-site.xml来配置默认In Memory Compaction方式
hbase.hregion.compacting.memstore.type
hbase-2.2.4版本
hbase.systemtables.compacting.memstore.type
NONE | BASIC | EAGER >
- 在创建表的时候指定
create "test_memory_compaction", {NAME => 'C1', IN_MEMORY_COMPACTION => "BASIC"}(5)StoreFile合并
- 当MemStore超过阀值的时候,就要flush到HDFS上生成一个StoreFile。因此随着不断写入,HFile的数量将会越来越多,根据前面所述,StoreFile数量过多会降低读性能
- 为了避免对读性能的影响,需要对这些StoreFile进行compact操作,把多个HFile合并成一个HFile
compact操作需要对HBase的数据进行多次的重新读写,因此这个过程会产生大量的IO。可以看到compact操作的本质就是以IO操作换取后续的读性能的提高
a、minor compaction
(1)说明
- Minor Compaction操作只用来做部分文件的合并操作,不做任何删除过期数据、多版本数据的清理工作
- 小范围合并,默认是3-10个文件进行合并,不会删除其他版本的数据
- Minor Compaction则只会选择数个StoreFile文件compact为一个StoreFile
- Minor Compaction的过程一般较快,而且IO相对较低
(2)触发条件
- 在打开Region或者MemStore时会自动检测是否需要进行Compact(包括Minor、Major)
- minFilesToCompact由hbase.hstore.compaction.min控制,默认值为3
- 即Store下面的StoreFile数量减去正在compaction的数量 >=3时,需要做compaction
可以查看具体配置:
http://bd-offcn-01:16010/conf
hbase.hstore.compaction.min
3
false
hbase-default.xml
b、major compaction
(1)说明
- Major Compaction操作是对Region下的Store下的所有StoreFile执行合并操作,会物理上清理掉过期数据、被用户删除的数据,多余版本数据,最终的结果是整理合并出一个文件
- 一般手动触发(自动触发每隔7天),会删除其他版本的数据(不同时间戳的)
(2)触发条件
- 如果无需进行Minor compaction,HBase会继续判断是否需要执行Major Compaction
将Store下面所有StoreFile合并为一个StoreFile,此操作会删除其他版本的数据(不同时间戳的),忽略标记为delete的KeyValue(被删除的KeyValue只有在compact过程中才真正被"删除"),可以想象major会产生大量的IO操作,对HBase的读写性能产生影响。
major 大合并 默认7天进行一次 生成环境中建议将其关闭 由自己在业务空闲的时候手动触发,因为大合并的时候会非常消耗IO资源。
hbase.hregion.majorcompaction = 建议设置为0,还可以设置抖动比例(hbase.hregion.majorcompaction.jitter),默认是0.5,最终的周一起为3.5-10.5天
hbase.hregion.majorcompaction
604800000
hbase-default.xml
604800000毫秒 = 604800秒 = 168小时 = 7天
手动触发方式:触发完成之后,可以查看hdfs的数据,原本多个storefile文件会变成一个。
手动触发方式:触发完成之后,可以查看hdfs的数据,原本多个storefile文件会变成一个。
hbase(main):009:0> major_compact 'WATER_BILL'
3、Region管理
(1)region分配
- 任何时刻,一个region只能分配给一个region server
- Master记录了当前有哪些可用的region server,以及当前哪些region分配给了哪些region server,哪些region还没有分配。当需要分配的新的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
(2)region server上线
- Master使用ZooKeeper来跟踪region server状态
- 当某个region server启动时
- 首先在zookeeper上的/hbase/rs目录下建立代表自己的znode
- 由于Master订阅了/hbase/rs目录上的变更消息,当/hbase/rs目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知
- 一旦region server上线,master能马上得到消息。
(3)region server下线
- 当region server下线时,它和zookeeper的会话断开,ZooKeeper而自动释放代表这台server的文件上的独占锁
- Master就可以确定
- region server和zookeeper之间的网络断开了
- region server挂了
- 无论哪种情况,region server都无法继续为它的region提供服务了,此时master会删除server目录下代表这台region server的znode数据,并将这台region server的region分配给其它还活着的节点
(4)Region分裂
当region中的数据逐渐变大之后,达到某一个阈值,会进行裂变
- 一个region等分为两个region,并分配到不同的RegionServer
- 原本的Region会下线,新Split出来的两个Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
<-- Region最大文件大小为10G -->
hbase.hregion.max.filesize
10737418240
false
hbase-default.xml
- HBase只是增加数据,所有的更新和删除操作,都是在Compact阶段做的
- 用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能读写
a、自动分区
自动分区的算法 根据hbase版本的不同而不同,可以引入hbase-server包查看源码
hbase0.94版本以前是:ConstantSizeRegionSplitPolicy
0.94-2.0.0是:IncreasingToUpperBoundRegionSplitPolicy
2.0.0及以后是:SteppingSplitPolicy
org.apache.hbase
hbase-server
2.2.4
0.94以前如果一个region大小超过10G才会进行切片
0.94-2.0.0之间,如果一个表中region的数量等于0或者大于100,则按照10G切片
否则,每次计算一个表中region的数量,然后通过region数*region数*region数*2*flushsize(即128M)得出一个值,将该值与10G比较,取最小值,
某个region的大小超过该最小值才切片,
例如,
此时region数量为2,则2*2*2*256=2048M,该值小于10G,则这两个region中的一个超过2048M,则可切片。
此时region数量为3,则3*3*3*256=6912M,该值小于10G,则这3个region中的一个超过6912M,则可切片。
此时region数量为4,则4*4*4*256=16384M,该值大于10G,则这4个region中的一个超过10G,则可切片。
即可总结,若一个表的region数量大于等于4的话,是按照10G切片
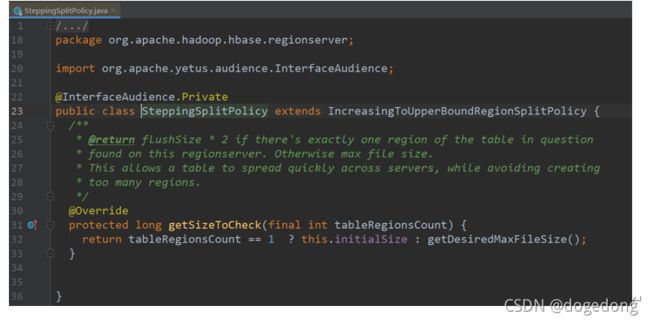
b、手动分区
在创建表的时候,就可以指定表分为多少个Region。默认一开始的时候系统会只向一个RegionServer写数据,系统不指定startRow和endRow,可以在运行的时候提前Split,提高并发写入。
hbase(main):012:0> create 'staff1','info',SPLITS => ['1000','2000','3000','4000']
4、Master工作机制
(1)Master上线
Master启动进行以下步骤:
- 从zookeeper上获取唯一一个代表active master的锁,用来阻止其它master成为master
- 一般hbase集群中总是有一个master在提供服务,还有一个以上的‘master’在等待时机抢占它的位置。
- 扫描zookeeper上的/hbase/rs父节点,获得当前可用的region server列表
- 和每个region server通信,获得当前已分配的region和region server的对应关系
- 扫描meta表,计算得到当前还未分配的region,将他们放入待分配region列表
(2)Master下线
- 由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结
- 无法创建删除表
- 无法修改表的schema
- 无法进行region的负载均衡
- 无法处理region 上下线
- 唯一例外的是region的split可以正常进行,因为只有region server参与,但是新分裂出的region没法交给master进行分配给其它regionserver维护
- 表的数据读写还可以正常进行
- 因此master下线短时间内对整个hbase集群没有影响。
- 从上线过程可以看到,master保存的信息全是可以冗余信息(都可以从系统其它地方收集到或者计算出来)
(二) HBase批量装载(Bulk load)
1、简介
很多时候,我们需要将外部的数据导入到HBase集群中,例如:将一些历史的数据导入到HBase做备份。我们之前已经学习了HBase的Java API,通过put方式可以将数据写入到HBase中,我们也学习过通过MapReduce编写代码将HDFS中的数据导入到HBase。但这些方式都是基于HBase的原生API方式进行操作的。这些方式有一个共同点,就是需要与HBase连接,然后进行操作。HBase服务器要维护、管理这些连接,以及接受来自客户端的操作,会给HBase的存储、计算、网络资源造成较大消耗。此时,在需要将海量数据写入到HBase时,通过Bulk load(大容量加载)的方式,会变得更高效。可以这么说,进行大量数据操作,Bulk load是必不可少的。
我们知道,HBase的数据最终是需要持久化到HDFS。HDFS是一个文件系统,那么数据可定是以一定的格式存储到里面的。例如:Hive我们可以以ORC、Parquet等方式存储。而HBase也有自己的数据格式,那就是HFile。Bulk Load就是直接将数据写入到StoreFile(HFile)中,从而绕开与HBase的交互,HFile生成后,直接一次性建立与HBase的关联即可。使用BulkLoad,绕过了Write to WAL,Write to MemStore及Flush to disk的过程
更多可以参考官方对Bulk load的描述:
Apache HBase ™ Reference Guide
2、Bulk load MapReduce程序开发
Bulk load的流程主要分为两步:
- 通过MapReduce准备好数据文件(Store Files)
- 加载数据文件到HBase
3、银行转账记录海量冷数据存储案例
银行每天都产生大量的转账记录,超过一定时期的数据,需要定期进行备份存储。本案例,在MySQL中有大量转账记录数据,需要将这些数据保存到HBase中。因为数据量非常庞大,所以采用的是Bulk Load方式来加载数据。
- 项目组为了方便数据备份,每天都会将对应的转账记录导出为CSV文本文件,并上传到HDFS。我们需要做的就将HDFS上的文件导入到HBase中。
- 因为我们只需要将数据读取出来,然后生成对应的Store File文件。所以,我们编写的MapReduce程序,只有Mapper,而没有Reducer。
(1)数据集
| id |
ID |
| code |
流水单号 |
| rec_account |
收款账户 |
| rec_bank_name |
收款银行 |
| rec_name |
收款人姓名 |
| pay_account |
付款账户 |
| pay_name |
付款人姓名 |
| pay_comments |
转账附言 |
| pay_channel |
转账渠道 |
| pay_way |
转账方式 |
| status |
转账状态 |
| timestamp |
转账时间 |
| money |
转账金额 |
(2)项目准备工作
a、HBase中创建银行转账记录表
create_namespace "OFFCN_BANK"
# disable "TRANSFER_RECORD"
# drop "TRANSFER_RECORD"
create "OFFCN_BANK:TRANSFER_RECORD", { NAME => "C1", COMPRESSION => "GZ"}, { NUMREGIONS => 6, SPLITALGO => "HexStringSplit"}
b、创建项目
| groupid |
com.offcn |
| artifactid |
bankrecord_bulkload |
c、导入POM依赖
org.apache.hbase
hbase-client
2.2.4
org.apache.hbase
hbase-mapreduce
2.2.4
org.apache.hadoop
hadoop-mapreduce-client-jobclient
3.2.1
org.apache.hadoop
hadoop-common
3.2.1
org.apache.hadoop
hadoop-mapreduce-client-core
3.2.1
org.apache.hadoop
hadoop-auth
3.2.1
org.apache.hadoop
hadoop-hdfs
3.2.1
commons-io
commons-io
2.6
junit
junit
4.12
compile
d、创建包结构
| 包 |
说明 |
| com.offcn.bank_record.bulkload.mr |
MapReduce相关代码 |
| com.offcn.bank_record.entity |
实体类 |
e、导入配置文件
将 core-site.xml、hbase-site.xml、log4j.properties三个配置文件拷贝到resources目录中。
(3)编写实体类
实现步骤:
- 创建实体类TransferRecord
- 添加一个parse静态方法,用来将逗号分隔的字段,解析为实体类
- 使用以下数据测试解析是否成功
7e59c946-b1c6-4b04-a60a-f69c7a9ef0d6,SU8sXYiQgJi8,6225681772493291,杭州银行,丁杰,4896117668090896,卑文彬,老婆,节日快乐,电脑客户端,电子银行转账,转账完成,2020-5-13 21:06:92,11659.0
参考代码: