编者荐语:
文章作者为中国移动云能力中心,文章转载已授权。本文将详细解析基于 Apache Pulsar 的云原生消息队列 AMQP 背景与整体设计等深度内容。
以下文章来源于苏研大云人,作者云原生中间件团队

友情提示:全文5000多文字,预计阅读时间3分钟
一、自研消息队列中间件AMQP的背景
随着公司公有云业务持续发展和用户数量的不断增长,数据量和请求量也在急剧增长,消息队列作为必不可少的通信组件,面临的压力也在日益增长。在对消息队列的组件维护中我们发现:OpenStack使用的消息队列RabbitMQ存在一些问题,比如消息易丢失,集群稳定性差,问题排查困难等。诸多难以解决的问题使我们萌生了寻求替代开源RabbitMQ消息队列的想法;另一方面,主流云服务厂商,如阿里云、华为云、天翼云等均已提供AMQP协议支持的消息队列产品,而我们缺少自研对标产品。基于以上两点,团队开始自研一款高性能、高可靠、高稳定,支持AMQP协议的消息队列产品。
我们的需求
综合云上产品和移动云组件的需求,整理了消息队列AMQP的几大核心需求如下:
- 具备高吞吐量,低延迟,高可靠的能力;
- 能根据需求进行无限制的扩容,缩容;
- 对于上云产品来说,需要具备多租户隔离的能力;
- 具备海量消息堆积能力,并且消息的堆积不会影响性能和稳定性;
- 支持AMQP协议,兼容AMQP协议的客户端(比如,开源RabbitMQ SDK);
- 具备运维部署能力,数据迁移的便利性,具备高效的集群部署、迁移效率。
开源产品调研
在产品设计之初,研发团队主要调研了两款实现了AMQP协议的开源产品:RabbitMQ和Qpid。由于Qpid在性能方面表现不佳被排除在外,RabbitMQ性能高、使用范围广,但是不符合我们的需求使用场景,有如下几个原因:
- 持久化消息性能较差。为了保证消息不丢失且消息可回溯,需要将消息持久化存储,经过测试RabbitMQ的持久化消息性能较差,不满足我们的需求,详见第四章节的性能测试对比。
- 为了保证消息不丢失,可以使用RabbitMQ的镜像队列,镜像队列的机制就是消息多副本保存在多节点的内存中,经过测试发现,在开启镜像队列的场景下,会出现两方面的问题:首先是集群稳定性较差,其次是消息堆积会导致内存溢出。
- 问题排查的困难性,RabbitMQ的编程语言是Erlang,这种编程语言较为小众。RabbitMQ的源码晦涩难懂,导致出现问题时,排查困难,且RabbitMQ没有实时消息追踪的能力,需要开启消息追踪的插件,无法及时回溯出现问题的消息。
基于以上原因,我们开始消息队列AMQP的自研。
二、消息队列AMQP整体设计
计算存储分离的架构
考虑到高稳定性、高可靠性和高吞吐量等诸多设计目标,研发团队最终决定采用符合云原生设计理念的计算存储分离架构。
计算存储耦合和计算存储分离有如下几个方面的对比:
当存储和计算耦合在一个集群中时,存在如下的一些问题:
- 在不同的应用或者发展时期,需要不同的存储空间和计算能力配比,使得机器的选型会比较复杂;
- 当存储空间或计算资源不足时,只能同时对两者进行扩容,导致扩容的经济效率比较低(另一种扩容的资源被浪费了);
- 在云计算场景下,不能实现真正的弹性计算,因为计算集群中也有数据,关闭闲置的计算集群会丢失数据。
针对计算存储耦合带来的一些问题,研发团队也调研了具有计算存储分离能力的开源消息队列Apache Pulsar。

在Pulsar的架构中,计算和数据存储是单独的两个组件:
计算层也就是Broker,Pulsar的Broker不直接存储消息实体数据,主要负责处理Consumer和Producer相关的连接请求处理等,如果业务上Consumer和Producer特别的多,可以单独扩展这一层。
数据存储也就是Bookie,Pulsar使用了Apache BookKeeper作为存储支持,BookKeeper是一个提供日志条目流存储持久化的服务框架,计算层使用时不必过多的关心存储细节。
结合消息队列AMQP的应用场景以及分析面向的客户群体,我们选择Pulsar这种计算存储分离的消息队列作为原型进行消息队列AMQP的定制化开发。在调研Pulsar以及与Puslar社区深入沟通之后发现Pulsar现有的Protocol Handler机制非常符合我们这种定制化开发的需求,Protocol Handler协议处理插件可以利用Pulsar 现有的一些组件(例如 服务发现组件-Topic LookUp、分布式日志库-ManagedLedger、消费进度管理组件-Cursor 等)来帮助我们实现一些逻辑处理。
因此Pulsar的Protocol Handler就成为了我们消息队列AMQP定制化开发的基础。更多Protocol Handler的介绍可参考Pulsar PIP-41。
(https://github.com/apache/pul...)
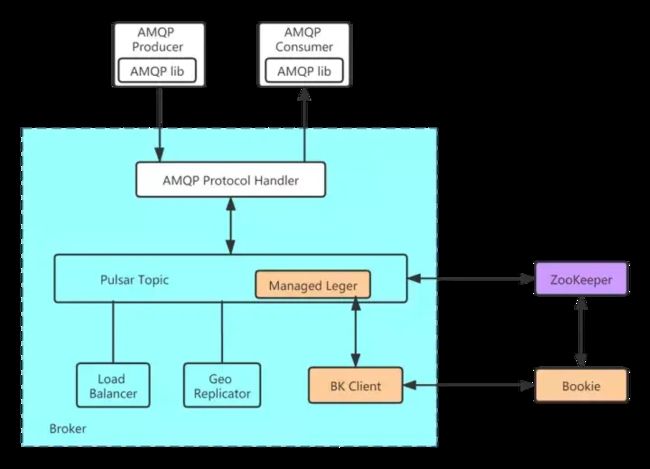
消息队列AMQP整体架构如上图所示,开发的重点就在于AMQP Protocol Handler的通信层协议的解析处理、AMQP 0-9-1协议模型与Pulsar模型之间的映射、多租户的支持以及最核心的发送消费流程的处理。
核心功能点设计
- 消息的存储
消息队列AMQP的存储设计借鉴了RabbitMQ,最终实现利用Pulsar的PersistentTopic来实现具体的实体数据以及索引数据的存储。
1、RabbitMQ的消息存储模型
RabbitMQ的消息持久化实际包括两部分:队列索引(rabbit_queue_index)和消息存储(rabbit_msg_store)。
rabbit_queue_index负责维护队列中落盘消息的信息,包括消息的存储位点、是否已经提交给消费者、是否已被消费者ACK等,每个队列都有一个与之对应的rabbit_queue_index。
rabbit_msg_store以键值对的形式存储消息,每个节点有且只有一个,该节点上的所有队列共享该文件。从技术层面讲rabbit_msg_store又可以分为msg_store_persistent和msg_store_transient,其中msg_store_persistent负责持久化消息的存储,不会丢失;而msg_store_transient负责非持久化消息的存储,重启后消息会丢失。
2、BookKeeper提供存储支持
Pulsar broker中的ManagedLedger实现了对BookKeeper存储层的封装,利用ManagedLedger可以实现消息的持久化、读取以及消费进度管理。
3、如何利用Pulsar现有的模型实现exchange以及queue的对应
AMQP 0-9-1引入了一些基础概念,例如 Exchagne, Queue 和 Router。这些与 Pulsar 的模型有着较大的区别。因此,我们需要采用一种建模映射方式,将现有Pulsar中对于Topic的发布/订阅模型与AMQP通信协议中的业务模型映射到一起。
AmqpExchange
AmqpExchange 包含一个原始消息 Topic,用来保存 AMQP Producer 发送的消息。AmqpExchange 的 Replicator 会将消息处理到 AMQP 队列中。Replicator 是基于 Pulsar 的持久化游标,可以确保成功将消息发送到队列,而不会丢失消息。
AmqpMessageRouter
AmqpMessageRouter 用于维护消息路由类型以及将消息从 AmqpExchange 路由到 AmqpQueue 的路由规则。路由类型和路由规则这些元数据都持久化在 Pulsar 的ManagedLedger 中。所以就算 Broker 重启,我们也可以恢复 AmqpMessageRouter。
AmqpQueue
AmqpQueue 提供一个索引消息 Topic,用来存储路由到这个队列的 IndexMessage。IndexMessage 由原始消息的 ID 和存储消息的 Exchange 的名称组成。当 AmqpQueue 向 Consumer 发送消息时,AmqpQueue 会根据 IndexMessage 读取原始消息数据,然后将其发送给 Consumer。
- 多租户的支持
作为一种企业级的消息系统,Pulsar 的多租户能力可满足下列需求:
- 保证不同租户之间的隔离
- 针对资源利用率强制实施配额
- 提供每租户和系统级的安全性
- 确保低成本运维以及尽可能简单的管理

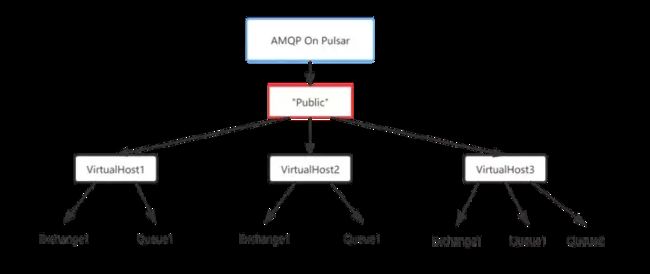
Pulsar多租户的特性,在topic的URL映射上充分显现,结构如下:

AMQP 0-9-1的协议定义中,VirtualHost是资源隔离的基本单位,和Pulsar的这种多层级的模型不能有完全一致的对应关系,在我们的实现中,移动云AMQP消息队列引入了Instance的概念,对应到Pulsar中的Tenant,组件版本使用固定的Tenant,Pulsar中的Namespace则对应到AMQP中的VirtualHost。其中组件版本的对应图如下所示:
- 消息流转过程

- 当 Producer 发送消息到 AmqpExchange,AmqpExchange 将消息持久化到 Pulsar Topic (我们称之为存储原始消息的 Topic)。
- AmqpExchange 的 Replicator 会将消息传递给 Router。
- Router 判断是否需要将消息路由给 AmqpQueue。如果是,会将原始消息的 ID 存入AmqpQueue 的 Topic 中 (我们称之为存储索引消息的 Topic)。
- AmqpQueue 将消息传递给 Consumer。
三、消息队列AMQP和RabbitMQ比较
云原生
云原生的"原生"即软件设计之初就考虑到了在云端部署的可能,消息队列AMQP采用计算存储分离的核心架构,能够充分利用分布式、弹性伸缩的云端资源。

传统架构下的消息队列如RabbitMQ,将消息存储在本地,Broker组件需承担消息分发和存储的双重功能;这使得Broker并非无状态服务,不具备弹性伸缩的能力。
而自研消息队列AMQP通过计算存储分离的架构,将Broker的角色进一步拆分为用于消息分发的Broker和用于消息存储的Bookie,从而将Broker打造成无状态服务,以实现Broker的弹性伸缩。
消息可靠性
消息的不丢失通常由两个方面保障:首先消息需要持久化到磁盘中,其次持久化消息需要保存多副本以提升消息队列的容错能力。相较于消息队列RabbitMQ,自研AMQP在消息可靠性的保障方面具有以下优势:
RabbitMQ持久化消息采用异步刷盘机制,无法保障断电、硬件故障等极端情况下数据的不丢失;消息队列AMQP原生支持消息同步刷盘,可以保障除磁盘损坏的任何极端故障场景下,消息的不丢失。
RabbitMQ仅在开启镜像队列时才能够进行消息的多副本同步;而消息队列AMQP原生支持消息的多副本保存,部分节点磁盘损坏情况下,数据也能够从副本中恢复出来。
RabbitMQ在开启消息持久化和镜像队列时,性能很差,无法满足高性能的需求;而消息队列AMQP通过文件的顺序读取和消息的缓存机制,仍能保证极高的性能。
容错
容错指集群中部分节点发生故障的时候,集群的可用性。
RabbitMQ的容错性不高,在发生网络分区的情况下,会导致数据丢失和集群的不可用,尤其是在配置镜像队列的情况下。
而消息队列AMQP各个组件都可以独立的容错。Broker是无状态服务,当发生错误的时候,Queue就会转移到其他Broker,不会影响消息收发。Bookie虽然有状态,但是并无主从之分,只要消息的副本足够多,即使部分Bookie宕机或者不可用的情况下,服务依然可以正常运行。
可维护性
相较于RabbitMQ,自研AMQP提供更加完善的运维监控系统,对于系统的各项指标,比如TPS、容量、连接状态、消费者状态等各项指标均有详细的监控,同时提供完善的说明文档以应对可能出现的各类问题,便于故障排查。
RabbitMQ不具备实时消息追踪能力,无法及时回溯出现问题的消息;而AMQP具备消息追踪的功能,保障所有消息可追溯,为问题的排查提供了便利。
RabbitMQ采用Erlang语言,较为小众且晦涩难懂,很难进行源码级别的问题排查;而AMQP为自研中间件,所有问题都可以通过代码分析排查解决。
四、性能
在同样的环境下,对消息队列AMQP和RabbitMQ的单机性能进行测试:
消息体大小:1KB
exchange数量:1个
queue数量:1个
消息是否持久化:是

通过创建1个Queue,1个Exchange,发送1KB的消息,对比消息队列AMQP和RabbitMQ的性能,得到上述的折线图,从上图可以看出,在同等测试条件下,消息队列AMQP的性能表现远高于RabbitMQ。
五、总结
目前消息队列AMQP已经正式上线移动云,欢迎大家订购使用。
(https://ecloud.10086.cn/home/...)
另外消息队列AMQP组件版本替换OpenStack中RabbitMQ也已经完成测试环境的验证工作,后续会在移动云生产环境中作为OpenStack组件的通信组件使用。
参考资料
1、Apache Pulsar 官网:https://pulsar.apache.org/doc...
2、《RabbitMQ 实战指南》
END
作者简介

张浩
中国移动云能力中心中间件开发工程师,消息队列AMQP研发负责人,在消息中间件以及分布式缓存领域有丰富的经验。

王少杰
中国移动云能力中心软件开发工程师,主要负责移动云消息队列产品研发、性能调优和维护工作,在RocketMQ,Pulsar,RabbitMQ等方面有丰富的实践和优化经验。
欢迎投稿
Apache Pulsar 社区欢迎大家踊跃投稿,希望这里成为大家获取 Pulsar 经验与知识分享的平台,并帮助更多的社区小伙伴深入了解 Pulsar。扫码添加 Bot 好友即可联络投稿


点击链接访问原文。