手把手教你使用ggplot2绘制散点图
散点图可以用来描述两个连续变量之间的关系,一般在做数据探索分析时会使用到,通过散点图发现变量之间的相关性强度、是否线性关系等。
绘制简单的散点图
ggplot包中的geom_point()函数可以非常方便绘制出所需的散点图。
library(ggplot2)
set.seed(1234)
x <- rnorm(100,mean = 2, sd = 3)
y <- -1.5 + 2*x + rnorm(100)
df <- data.frame(x = x, y = y)
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_point()
绘制分组的散点图
可将分组变量(因子或字符变量)赋值给颜色或形状属性,实现分组散点图的绘制
set.seed(1234)
x <- rnorm(100,mean = 2, sd = 3)
y <- -1.5 + 2*x + rnorm(100)
z <- sample(c(0,1), size = 100, replace = TRUE)
df <- data.frame(x = x, y = y, z = z)
#将数值型变量转换为因子型变量
df$z <- factor(df$z)
#分组变量赋值给颜色属性
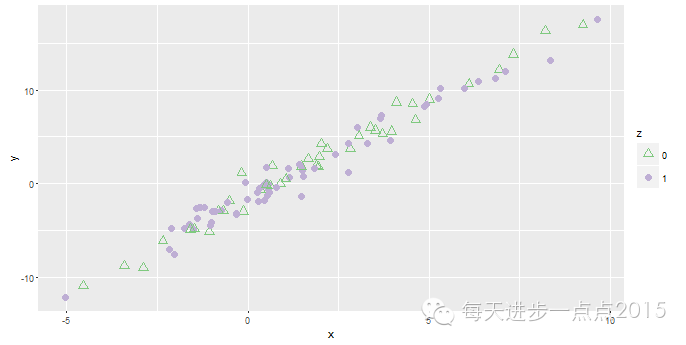
ggplot(data = df, mapping = aes(x = x, y = y, colour = z)) + geom_point(size = 3)

#分组变量赋值给形状属性
ggplot(data = df, mapping = aes(x = x, y = y, shape = z)) + geom_point(size = 3)

用户可能对默认的颜色或形状不满意,可以通过scale_colour_brewer()或scale_colour_manual()函数自定义点的颜色;通过scale_shape_manual()函数实现自定义点的形状。为了说明问题,这里将分组变量同时赋值给颜色属性和形状属性。
ggplot(data = df, mapping = aes(x = x, y = y, colour = z, shape = z)) + geom_point(size = 3) + scale_color_brewer(palette = 'Accent') + scale_shape_manual(values = c(2,16))
有关可选的点的形状可参考下图:

这里需要提醒的是,21-25之间的点形状,既可以赋值边框颜色,又可以赋值填充色,当数据点颜色较浅时,带边框线的点就显得尤为重要,这样可以将数据点与背景色区分开来,而0-20之间的点形状,只能赋值边框颜色。
以上几种图形是将离散变量或因子映射给颜色属性或形状属性,下面介绍如何将连续变量映射给颜色属性或大小属性。
x <- c(10,13,11,15,18,20,21,22,24,26)
y <- c(76,60,70,58,55,48,44,40,26,18)
z <- c(100,120,300,180,80,210,30,95,145,420)
df <- data.frame(x = x, y = y, z = z)
#将连续变量映射给颜色属性
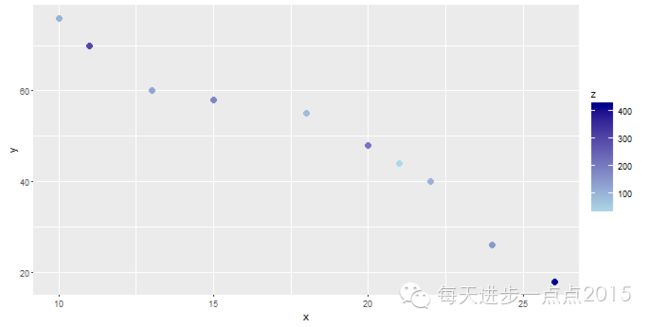
ggplot(data = df, mapping = aes(x = x, y = y, colour = z)) + geom_point(size = 3)

但这里发现一个问题,颜色越深而对应的值越小,如何将值的大小与颜色的深浅保持一致呢?很简单,只需人为的设置色阶,从低到高设置不同的颜色即可。
ggplot(data = df, mapping = aes(x = x, y = y, colour = z)) + geom_point(size = 3) + scale_colour_gradient(low = 'lightblue', high = 'darkblue')
#将连续变量映射给大小属性
ggplot(data = df, mapping = aes(x = x, y = y, size = z)) + geom_point()

上面将连续变量赋值给颜色属性或大小属性,我们还可以人为的设置色阶间隔或大小间隔。
#自定义色阶间隔
ggplot(data = df, mapping = aes(x = x, y = y, fill = z)) + geom_point(shape = 21, size = 3) + scale_fill_continuous(low = 'lightblue', high = 'darkblue', breaks = c(100,150,200,300,350,400))

#自定义球大小的间隔
ggplot(data = df, mapping = aes(x = x, y = y, size = z)) + geom_point() + scale_size_continuous(breaks = c(100,150,200,300,350,400), guide = guide_legend())

#将连续变量值的大小与球的大小成比例
ggplot(data = df, mapping = aes(x = x, y = y, size = z)) + geom_point() + scale_size_area(max_size = 10)

很明显,使用第二种球大小的图看起来更舒服,也更明显。
重叠点的处理
当数据点非常多时,可能会导致数据点重叠非常严重,该如何处理这样的问题呢?一般有以下几种方法:
1)使用半透明的点
2)数据分箱,并用矩形表示
3)数据分箱,并用六边形表示
4)使用二维密度估计,并将等高线添加到散点图中
5)向散点图中添加边际地毯
set.seed(1234)
x <- rnorm(10000)
y <- rnorm(10000,0,2)
df <- data.frame(x = x, y = y)
#不作任何处理
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_point()

#使用透明度处理点的重叠问题
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_point(alpha = 0.1)

#分箱,并用矩阵表示
ggplot(data = df, mapping = aes(x = x, y = y)) + stat_bin2d()

默认情况下,stat_bin_2d()函数将x轴和y轴的数据点各分为30个段,即参数900个箱子,用户还可以自定义分段个数,以及箱子在垂直和水平方向上的宽度。
#设置bins为50
ggplot(data = df, mapping = aes(x = x, y = y)) + stat_bin2d(bins = 50) + scale_fill_gradient(low = 'steelblue', high = 'darkred', limits = c(0,100), breaks = c(0,25,50,100))

将图形划分为小的正方形箱可能会产生分散注意力的视觉假象,一般建议使用六边形代之。
#分箱,并用六边形表示
ggplot(data = df, mapping = aes(x = x, y = y)) + stat_binhex(binwidth = c(0.2,0.3)) + scale_fill_gradient(low = 'lightgreen', high = 'darkred', limits = c(0,100), breaks = c(0,25,50,100))

#使用stat_density2d作二维密度估计,并将等高线添加到散点图中
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_point() + stat_density2d()

#使用大小与分布密度成正比例的点
ggplot(data = df, mapping = aes(x = x, y = y)) + stat_density2d(geom = 'point', aes(size = ..density..), contour = FALSE) + scale_size_area()

#使用热图展示数据分布密度情况
ggplot(data = df, mapping = aes(x = x, y = y)) + stat_density2d(geom = 'tile', aes(fill = ..density..), contour = FALSE)

#向散点图中添加边际地毯
ggplot(data = faithful, mapping = aes(x = eruptions, y = waiting)) + geom_point() + geom_rug()

通过边际地毯,可以快速查看每个坐标轴上数据的分布密疏情况。还可以通过向边际地毯线的位置坐标添加扰动并设定size减少线宽,从而减轻边际地毯线的重叠程度。
ggplot(data = faithful, mapping = aes(x = eruptions, y = waiting)) + geom_point() + geom_rug(position = 'jitter', size = 0.1)

如果一个变量为离散变量,另一个变量为连续变量时,如何绘制散点图?
set.seed(1234)
x <- rep(1:5, each = 1000)
y <- c(rnorm(1000),rnorm(1000,1,2),rnorm(1000,3,4),rt(1000,2),rt(1000,4))
df <- data.frame(x = x, y = y)
df$x <- factor(df$x)
#不作任何处理的散点图
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_point()

对于这样的图,似乎没有什么意义,为了避免过度重叠,有以下两种处理方法:
1)使用扰动图
2)使用箱线图(适用于一个或两个变量为离散变量)
#给数据点添加随机扰动
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_point(position = 'jitter')
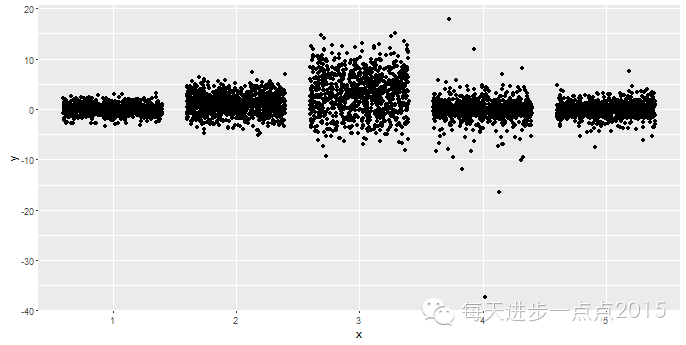
默认情况下,扰动函数在每个方向(水平和垂直)上添加的扰动值为数据点最小精度的40%,当然也可以通过width和height参数自定义扰动量。
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_point(position = position_jitter(width = 0.5, height = 0))
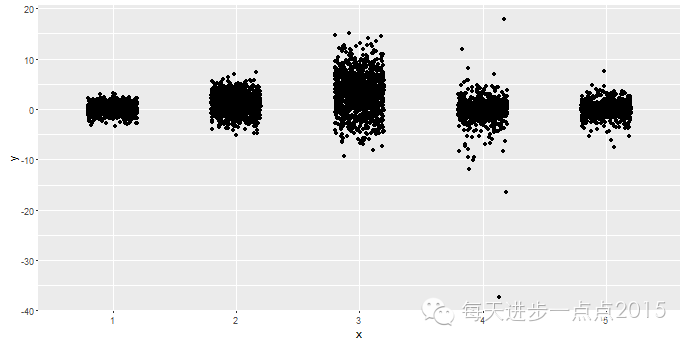
上图只在水平方向上添加50%的扰动量。
#绘制箱线图
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_boxplot(mapping = aes(group = x), fill = 'steelblue')

这里需要提醒的是,横坐标为数值型变量时,必须要将其转换为因子,并在geom_boxplot()函数的属性中将因子映射给group,否则产生的效果图将是错误的。
上文中提到,通过绘制两个变量的散点图可以查看变量将的关系,可以是线性的也可以是非线性的,如何在散点图的基础上再添加拟合曲线呢?下文将逐一介绍几种拟合线。
#不添加任何拟合线
ggplot(data = iris, mapping = aes(x = Petal.Length, y = Petal.Width, colour = Species)) + geom_point()

#添加线性拟合线
ggplot(data = iris, mapping = aes(x = Petal.Length, y = Petal.Width, colour = Species)) + geom_point() + stat_smooth(method = 'lm')

#添加局部加权多项式曲线
ggplot(data = iris, mapping = aes(x = Petal.Length, y = Petal.Width, colour = Species)) + geom_point() + stat_smooth(method = 'loess')
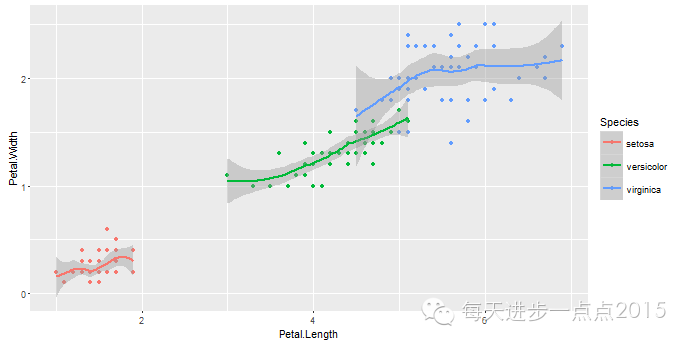
#添加Logistic曲线
library(MASS)
b <- biopsy
#绘制Logistic曲线必须将因变量强制转换为0-1
b <- transform(b, class_trans = ifelse(class == 'benign', 0, 1))
ggplot(data = b, mapping = aes(x = V1, y = class_trans)) + geom_point(position = position_jitter(width = 0.3, height = 0.06), alpha = 0.4, shape = 21, size = 2) + stat_smooth(method = glm, method.args = list(family = "binomial"))

如果不需要为拟合线绘制置信区间的话,置信将stat_smooth()函数中的参数se设为FALSE即可。
如果两个变量均是离散变量,该如何绘制散点图?实质上,这样的散点图我们称作气泡图。一般可以将这种图应用到价值转移中。
value1 <- rep(c('高价值','中价值','低价值'), each = 3)
value2 <- rep(c('高价值','中价值','低价值'), times = 3)
nums <- c(500,287,123,156,720,390,80,468,1200)
df <- data.frame(value1 = value1, value2 = value2, nums = nums)
df$value1 <- factor(df$value1, levels = c('高价值','中价值','低价值'), order = TRUE)
df$value2 <- factor(df$value2, levels = c('低价值','中价值','高价值'), order = TRUE)
ggplot(data = df, mapping = aes(x = value1, y = value2, size = nums)) + geom_point(colour = 'steelblue') + scale_size_area(max_size = 30, guide = FALSE) + geom_text(aes(label = nums), vjust = 0, colour = 'black', size = 5)

从图中可知,高价值用户中有80个流向了低价值,而低价值用户中又有128个流向高价值。
最后再介绍两种比较常用的种散点图,即Cleveland点图和散点图矩阵。
在《手把手教你使用ggplot2绘制条形图》我们向大家介绍了然后绘制各种各样的条形图,这里介绍另一种替代条形图的Cleveland点图。通过Cleveland点图可以减少图形造成的视觉混乱,同时图形更具可读性。
set.seed(1234)
names <- letters
Score <- runif(26, min = 55, max = 90)
df <- data.frame(names = names, Score = Score)
#条形图
ggplot(data = df, mapping = aes(x = reorder(names,Score), y = Score)) + geom_bar(stat = 'identity', fill = 'steelblue', colour = 'black') + xlab('Name') + geom_text(aes(label = round(Score)), vjust = 1)

#Cleveland点图
ggplot(data = df, mapping = aes(x = reorder(names,Score), y = Score)) + geom_point(size = 5, shape = 21, fill = 'steelblue', colour = 'black') + xlab('Name')

散点图矩阵是一种对多个变量两两之间关系进行可视化的有效方法,R中pairs()函数可以实现这样的需求。
#使用pairs()函数绘制散点图矩阵
data(tips, package = "reshape")
pairs(tips[,1:3])

#使用car包中的scatterplot.matrix()函数
library(car)
scatterplot.matrix(tips[,1:3])

#使用GGally包中的ggpairs()函数绘制散点图矩阵
library(GGally)
ggpairs(tips[, 1:3])

通过GGally包中的ggpairs()函数绘制散点图矩阵还是非常引入入目的,将连续变量和离散变量非常完美的结合在一起。
参考资料:
R语言_ggplot2:数据分析与图形艺术
R数据可视化手册