学习一门开源技术一般有两种入门方法,一种是去看官网文档,比如Getting Started - Spark 3.2.0 Documentation (apache.org),另一种是去看官网的例子,也就是%SPARK_HOME%\examples下面的代码。打开IDEA,选择File-Open...

跟前面文章中方法一样导入jars目录到classpath。
Spark解析json字符串
第一个例子是读取并解析Json。这个例子的结果让我有些震惊,先上代码:
-
public static void main(String[] args) {
-
SparkSession session = SparkSession.builder().master("local[1]").appName("SparkSqlApp").getOrCreate();
-
-
Dataset
json = session.read().json("spark-core/src/main/resources/people.json");
-
json.show();
-
}
让我惊讶的是文件的内容。例子里面的文件是三个大括号并列,文件扩展名是.json,由于没有中括号,所以格式是错的:
-
{"name":"Michael"}
-
{"name":"Andy", "age":30}
-
{"name":"Justin", "age":19}
但是spark解析出来了:

于是我把文件改成下面这样向看下结果
-
[{"name":"Michael"},
-
{"name":"Andy", "age":30},
-
{"name":"Justin", "age":19}
-
]
你猜输出是什么?

显然,spark没有解析出第一行,而且把第4行也解析了。这也说明了为什么样例的文件可以解析:首先跟文件扩展名是没啥关系的,另外spark是按行解析,只要考虑这一行是否符合解析要求就可以,行末可以有逗号。所以把文件改成下面也是可以的
-
{"name":"Michael"},
-
{"name":"Andy", "age":30},..
-
{"name":"Justin", "age":19}
第一行后面有逗号,第二行后面还有两个点。
SQL 查询
在之前的例子中,读取文件返回的是Dataset
DataFrame提供了一些好用的方法,用的最多的就是show()。它主要用于调试,可以把数据以表格形式打印。spark确实给DataFrame生成了表结构,可以通过printSchema()方法查看

不但有字段名,还有字段类型,还有是否可空(好像都能空)。
DF还提供了类似于sql查询的方法,比如select()/groupBy(),和where类似的filter()等:

这里我们首先给年龄字段+1,并通过别名(相等于SQL里的AS)让他覆盖之前的字段,然后查询比19大的记录,最后根据年龄分组汇总。
如果我们把新字段不覆盖原字段呢?你猜是执行报错还是啥结果?

That's all?当然不是,Spark提供了更强大的SQL操作:视图
View
视图分临时视图和全局视图。临时视图时会话级别的,会话结束了视图就没了;全局视图时应用级别的,只要Spark应用不停,视图就可以跨会话使用。

可见临时视图和全局视图可以叫一样的名字,它们的内容互不干扰。因为要访问全局视图需要通过global_temp库。不信你可以这样试一下
-
Dataset
group = json.select(col("name"), col("age").plus(1).alias("age1"))
-
.filter(col("age").gt(19))
-
.groupBy("age1")
-
.count();
-
-
group.createOrReplaceTempView("people");
-
json.createOrReplaceGlobalTempView("people");
-
Dataset
temp = session.sql("select * from people");
-
Dataset
global = session.sql("select * from global_temp.people");
-
Dataset
global1 = session.newSession().sql("select * from global_temp.people");
-
temp.show();
-
global.show();
-
global1.show();
Dataset
我们已经跟Dataset打过不少交道了,这里再稍晚多说一点点。实际上如果你是自己摸索而不是完全看我写的,下面这些内容估计都已经探索出来了。
1 转换自DF
DF是无类型的,Dataset是有类型的。如果要把无类型的转成有类型的,就需要提供一个类型定义,就像mysql表和Java的PO一样。
先来定义Java类:
-
public class Person implements Serializable {
-
private String name;
-
private long age;
-
-
public String getName() {
-
return name;
-
}
-
-
public void setName(String name) {
-
this.name = name;
-
}
-
-
public long getAge() {
-
return age;
-
}
-
-
public void setAge(long age) {
-
this.age = age;
-
}
-
}
这个类必须实现序列化接口,原因在前面也说过了。
接下来把读入json的DataFrame转成Dataset:

之前都是使用Encoders内置的编码器,这里通过bean()方法生成我们自定义类的编码器,然后传给DF的as()方法就转成了Dataset。
既然转成了强类型的Dataset,那能把每一个对象拿出来吗?给Person类增加toString方法,然后遍历Dataset:

结果报错了竟然:已经生成了集合,却不能访问元素?
报错原因很简单:我们类中的age是原始数据类型,但是实际数据有一个null。把long age改成Long age即可:

但是为什么会这样呢?!~我猜是因为as方法用的编码器(序列化工具)和foreach用到的解码器不匹配,spark的编码器不要求数据符合Java编译规则。
来自Java集合
目前我们掌握了通过读取文件(textFile(path))、转化其他Dataset(map/flatMap)和转换DF来生成Dataset,如果已经有一堆数据了,也可以直接创建。
SparkSession重载了大量根据数据集生成Dataset和DataFrame的方法,可以自由选择:

所以我们创建一个List来生成,只能是List,不能是Collection
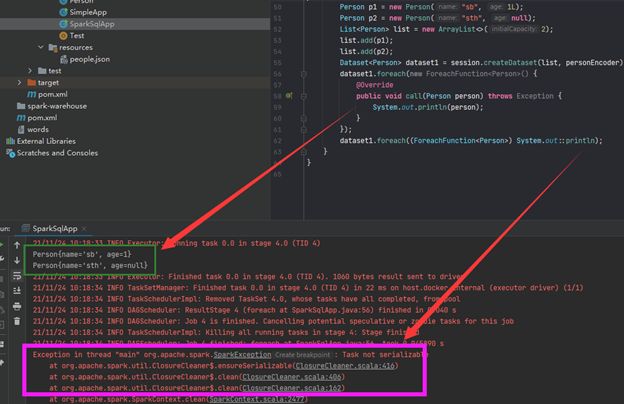
神奇的是原本应该一样的代码,执行的时候有一个报错。这个算Java实现的BUG吧,原因参考Java中普通lambda表达式和方法引用本质上有什么区别? - RednaxelaFX的回答 - 知乎
https://www.zhihu.com/question/51491241/answer/126232275
转自RDD
RDD 在Java环境下叫JavaRDD。它也是数据集,可以和Dataset/DataFrame互转。这里不说了,有兴趣可以探索。